Mysql InnoDB Buffer Pool
参考书籍《mysql是怎样运行的》
一丶为什么需要Buffer Pool
对于InnoDB存储引擎的表来说,无论是用于存储用户数据的索引,还是各种系统数据,都是以页的形式存放再表空间中,归根结底还是存储再磁盘上。因此InnoDB存储引擎处理客户端的请求是,如果需要访问某个页的数据,需要把完整的页数据加载到内存中,即便是只需要一条数据,也需要把整个页的数据加载到内存后进行读写访问。如果没用缓存那么一条sql需要进行多次的磁盘IO操作,如果在读写页后将其缓存在内存中,便可以减少这种磁盘IO提高mysql性能。
二丶InnoDB Buffer Pool及其内部组成
InnoDB 会在mysql服务器起到是就向操作系统申请一块连续的内存,(innodb_buffer_pool_size可以控制大小,单位字节)用来对InnoDB的页做缓存操作。
Buffer Pool对应一片连续的内存被划分为若干个页面,页面的大小和InnoDB页面大小一致(16kb)每一个buffer pool 页都对应一些控制信息(表空间编号,页号等)这些控制信息被抽象为控制块(后文我们把buffer pool的页称为缓冲页,和表空间中页做区分)
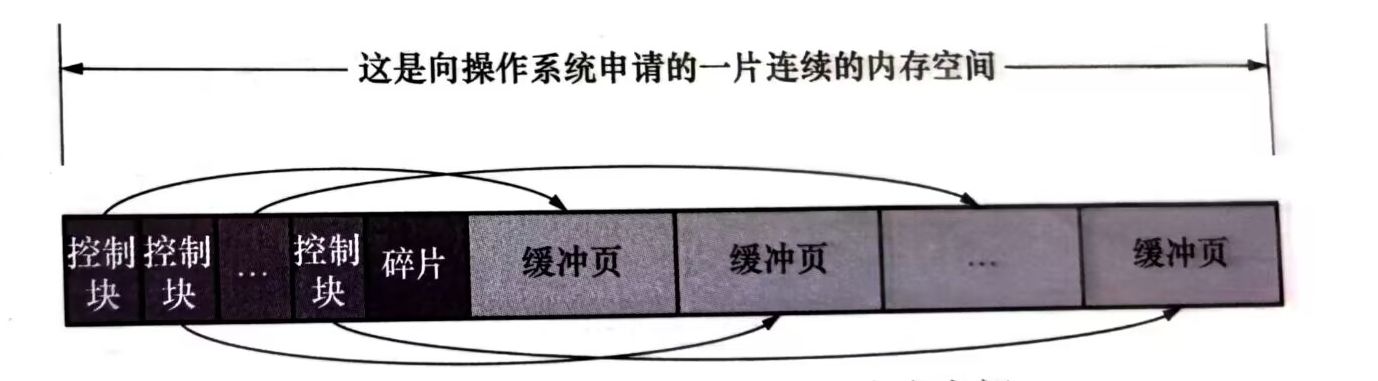
三丶空闲缓冲页管理——free 链表
从磁盘上读取一个页到buffer pool中时,应该把这个页缓存到哪儿昵。buffer pool的做法时将空闲的缓冲页对应的控制块作为一个节点放在链表中,这个链表称作free链表。
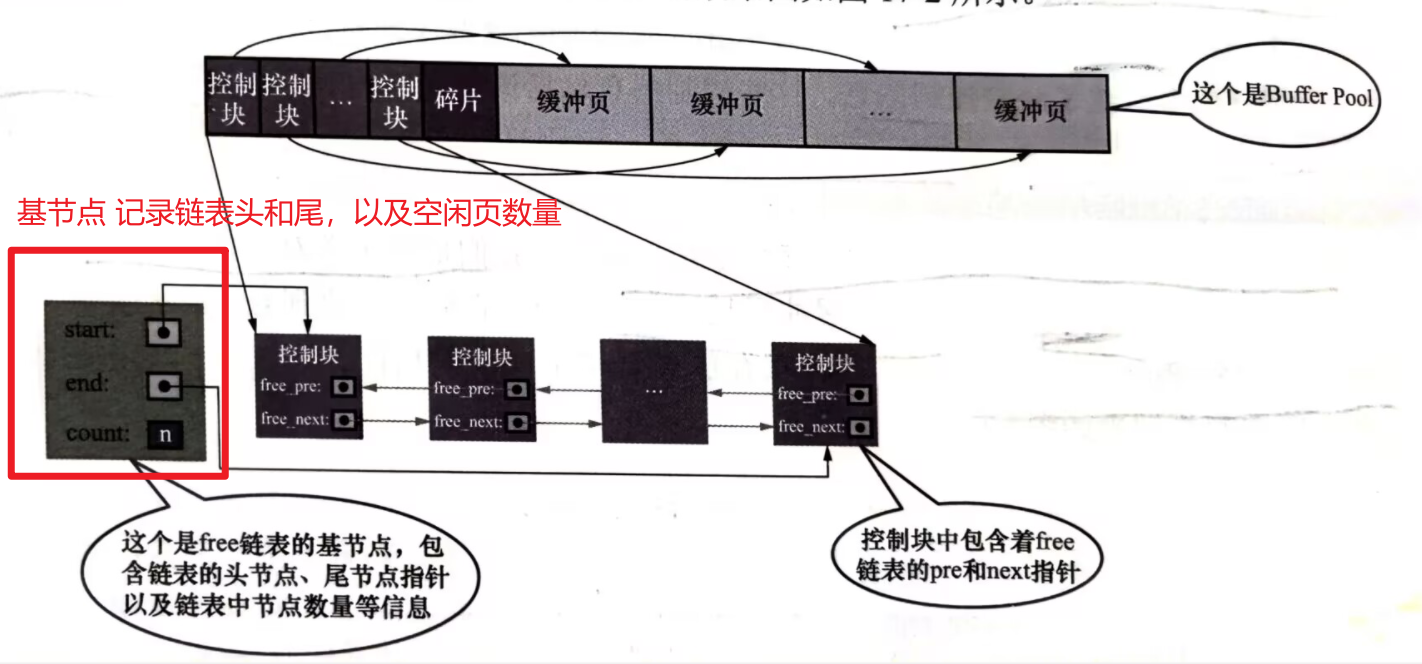
其中有一个基节点负责记录链表的头和尾,每一个空闲的页都将在free 链表中串联起来,每当innodb需要缓存一个页的时候,就通过基节点获取一个空闲的buffer pool 缓冲页,然后在这个缓冲页中记录下表空间,页号之类的信息。然后把缓冲页对应的free链表节点移除。
在缓存一个页的时候,还需要判断当前页是否已经被缓存,innodb 对已经缓存的页,根据其表空间和页号两个值作为hash的key,建立hash表,这样可以很快的进行判断。
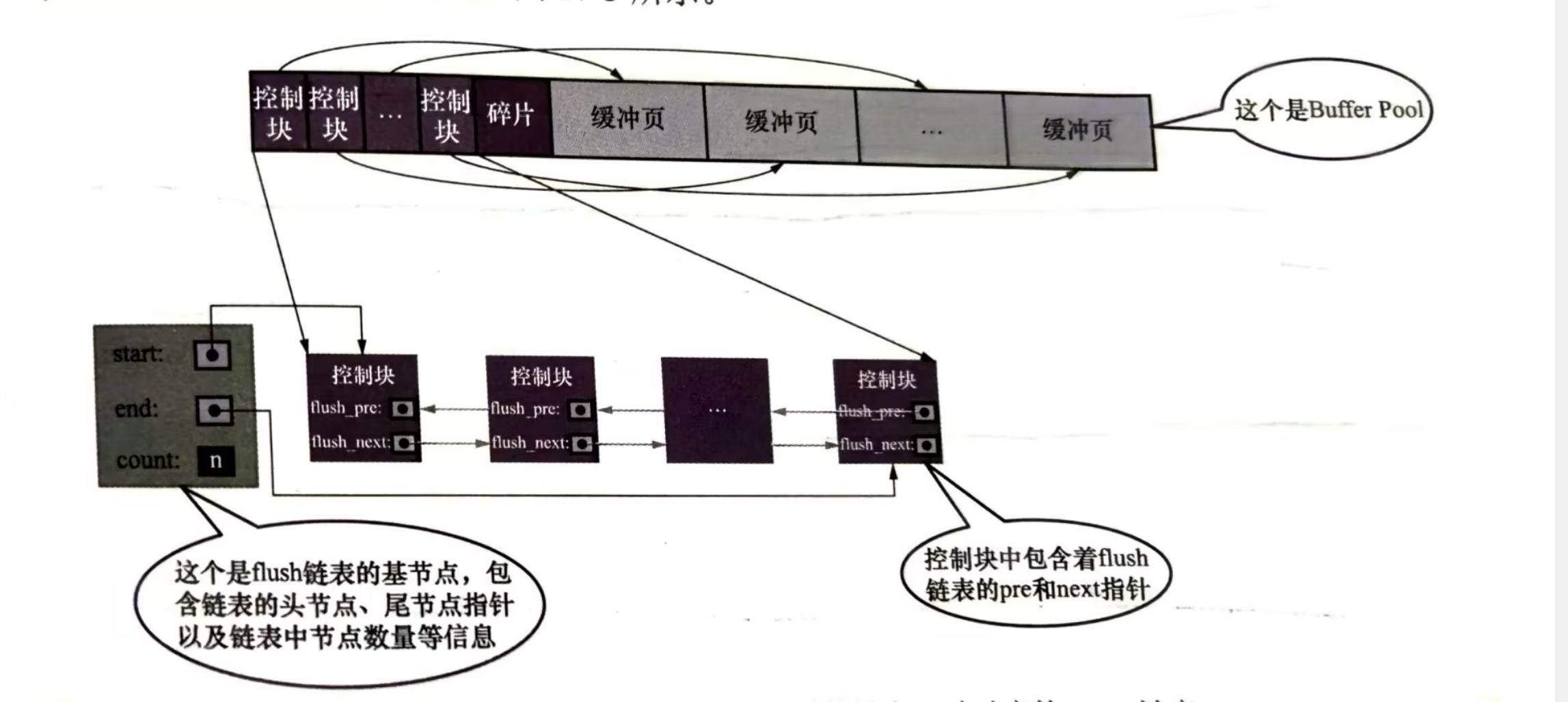
四丶缓冲页刷盘——flush链表
当innodb修改一个磁盘上的页并缓存到buffer pool中,这时候内存中缓存的数据和磁盘就不一致这种页称为脏页。如果每次执行完修改都立马将数据刷新到磁盘中的页会影响到程序的性能,所以innodb不会立马刷新到磁盘,而是使用flush链表将脏页对应的控制块串联起来
五丶缓冲空间不够怎么办——LRU链表管理
1.简单的LRU链表
buffer pool的大小毕竟是有限的,当free 链表中不存在更多空闲的缓冲页了,这时候就需要采取一些淘汰策略对一些无用的缓冲页进行淘汰。
这里就是涉及到两个问题:什么样的缓冲页是无用的,如何维护这些缓冲页来实现此淘汰策略。这时候自然是使用LRU算法(最近最少使用)淘汰最近最少使用到缓冲页。LRU算法使用一个链表来实现,当innodb访问某个页的时候:
- 如果该页不在buffer pool中,那么把该页从磁盘加载到buffer pool中的缓冲页是,就把该页的控制块放在LRU链表的头部
- 如果该页已经在buffer pool中,那么移动节点到LRU链表头部
这样可以实现,被使用到缓冲页,会尽量靠近LRU链表的头部,自然而然尾部便是最近最少使用到的数据。LRU算法基于——最近使用到的数据,后续也会到使用到的思想,使用LRU可以提高Buffer pool缓存的命中率。
2.简单LRU链表无法解决的问题
预读
innodb认为在执行当前请求的时候,后续可能会读取某些页面的时候,会把这些页面也加载到buffer pool
线性预读
如果顺序访问某个区的页面超过
innodb_read_ahead_threshold的值,那么会触发一次线性预读,异步的读取下一个区中全部的页面到buffer pool中。随机预读
如果某个区的13个连续的也都被加载到buffer pool中,无论是否是顺序读取的页面,都会异步读取本区中所有的其他页面到buffer pool中,
innodb_random_read_ahead设置为on可以开启随机预读
预读的目的是提高语句的执行效率,相当于innodb 认为你会用到,异步的帮你加载到缓存中,后续不需要继续读磁盘。但是在LRU的管理中,如果预读的页面很多没用用到的话,还将预读的页面放在链表头部,后续淘汰的页面反而是需要用到的,会极大的降低缓存命中率。
预读导致加载到buffer pool中页的不一定会使用到全表扫描语句
当一个sql没有合适的索引或者没用where限定条件的时候,innodb会扫描该表聚集索引所有的页。如果页非常多,buffer pool无法容纳的时候,就会把其他有用的缓冲页进行淘汰,降低缓存命中率。
全表扫描导致许多使用频率低的页被同时加载到buffer pool中,导致使用频率高的页从buffer pool中被移除(这里可以看出LFU算法的好处,哈哈哈)
3.innodb 如何解决预读和全表扫描导致缓存命中率降低的问题
innodb 根据一定比例将LRU链表分为两部分:
- 热数据区:使用频率很高的缓冲页构成,称为young区
- 冷数据区:使用频率不是很高的缓存页构成,称为old区
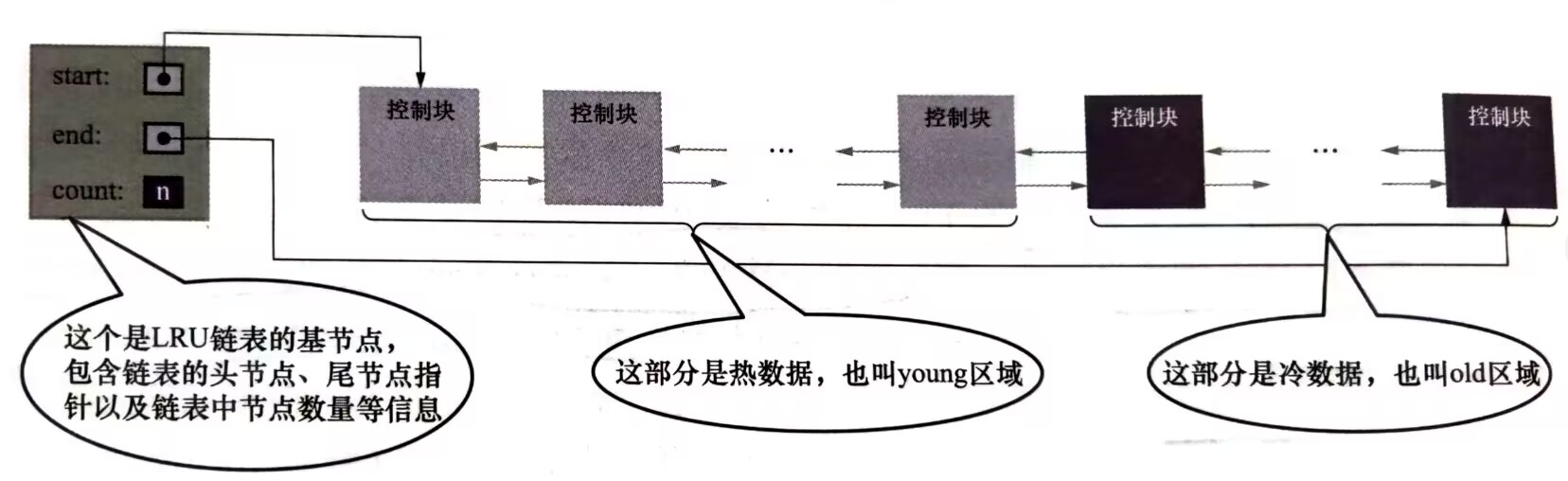
innodb_old_bolocks_pet可以设置old区占用的比列,默认是37%
3.1解决预读页面后续也许使用不到的问题
innodb规定当磁盘某个页面在初次加载到buffer pool中某个缓冲页时,该缓冲页对应的控制块会放在old区域的头部,这样预读到的且后续如果不进行后续访问的页面会逐渐从old区移除,而不影响young区使用频率高的缓冲页。
3.2解决全表扫描短时间访问大量使用频率低页面的问题
在进行全表扫描时,虽然首次访问放在old区头部,但是后续会马上被访问到,这时候会把该页放在young区域的头部,这样依旧会影响到使用频率高的页面。
为了解决这个问题,innodb规定对于某个处于old区的缓冲页第一次访问时,就在其控制块中记录下访问时间,如果后续访问的时间和第一次访问的时间,在某个时间访问间隔内(innodb_old_blocks_time可以进行设置)那么页面不会从old区移动到young区,反之移动到young区中。这个时间间隔默认时1000ms,基本上多次访问同一个页面中的多个记录的时间不会超过1s。
3.3 优化每次都需要移动young区节点到LRU链表头部的问题
如果每次访问一个缓冲页都需要移动到LRU链表的头部,像young区中这种热点数据,每次都需要更新链表头部,并且这还是一个高并发操作,需要CAS或者锁,开销也不小。为了解决这个问题 innodb规定只有被访问的缓冲页位于young区的前1/4范围外,才会进行移动,所以前1/4的高热度的数据,不会频繁移动
六丶脏页刷盘
innodb后台有专门的线程负责将脏页刷新到磁盘
从LRU链表中的冷数据刷新一部分页面到磁盘
后台线程定时从LRU链表尾部扫描一些页面,扫描的页面数量可以通过
innodb_lru_scan_depth指定,如果在LRU中发现脏页,那么刷新到磁盘从flush链表刷新一部分页面到磁盘
后台线程也会定时从flush链表中刷新一部分页面到磁盘,刷新速率取决于系统是否繁忙
如果后台线程刷新的很慢,且有新的页面需要进行缓存,这时候会从LRU链表尾部看看是否有可以直接释放的非脏页,如果不存在那么需要刷盘然后缓存新的页。
这里我们可以看到buffer pool没用保证修改的数据一定被磁盘持有化,那么事务的持久性如何实现昵,怎么保证mysql服务突然挂了,已经提交的事务不会丢失昵,这就得提到redo log了
七丶多个buffer pool实例
在并发量比较大的时候,多个线程操作同一个buffer pool,必然涉及到同步机制,影响到请求的处理速度,所以在buffer pool比较大的时候,会被拆分成多个小的buffer pool,独立进行使用,在高并发的时候不会相互影响(虽然也不能公用彼此的缓存内容)提高并发处理能力。只有在innodb_buffer_pool_size设置的buffer pool大小大于1g的时候,通过innodb_buffer_pool_instances设置的buffer pool实例个数才会生效
八丶动态的扩大缩小buffer pool
为了能够在运行的时候动态的扩大缩小buffer pool,innodb提出chunk的概念,innodb 不在一次申请为某一个buffer pool申请一大片连续的内存空间,而是以chunk作为单位进行申请。一个chunk就是一个连续的内存空间,其内部包含了若干缓冲页和其对应的控制块。
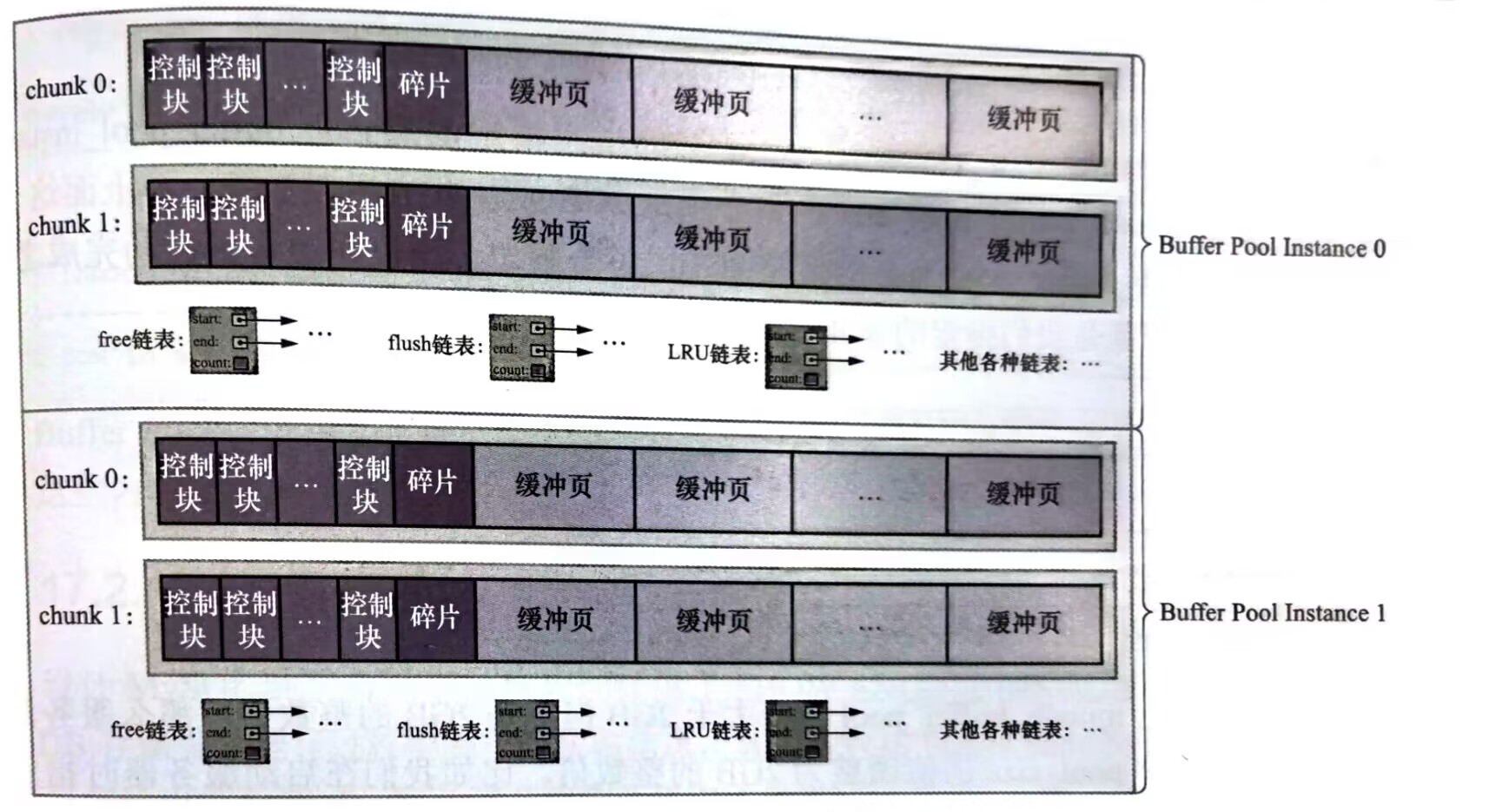
可以通过innodb_buffer_pool_chunk_size设置每一个chunk的大小,默认时128mb。
所以我们最好让innodb_buffer_pool_size = innodb_buffer_pool_chunk_size x innodb_buffer_pool_instances的若干倍保证每一个buffer pool实例中chunk数相同,如果innodb_buffer_pool_chunk_size x innodb_buffer_pool_instances大于innodb_buffer_pool_size ,innodb_buffer_pool_chunk_size 会自动被调整为innodb_buffer_pool_size / innodb_buffer_pool_instances的大小
Mysql InnoDB Buffer Pool的更多相关文章
- [转]MySQL innodb buffer pool
最近在对公司的 MySQL 服务器做性能优化, 一直对 innodb 的内存使用方式不是很清楚, 乘这机会做点总结. 在配置 MySQL 的时候, 一般都会需要设置 innodb_buffer_poo ...
- MySQL · 性能优化· InnoDB buffer pool flush策略漫谈
MySQL · 性能优化· InnoDB buffer pool flush策略漫谈 背景 我们知道InnoDB使用buffer pool来缓存从磁盘读取到内存的数据页.buffer pool通常由数 ...
- MySQL · 引擎特性 · InnoDB Buffer Pool
前言 用户对数据库的最基本要求就是能高效的读取和存储数据,但是读写数据都涉及到与低速的设备交互,为了弥补两者之间的速度差异,所有数据库都有缓存池,用来管理相应的数据页,提高数据库的效率,当然也因为引入 ...
- 理解innodb buffer pool
今天组里有个同事说可以查看innodb buffer pool每个表和索引占的大小,为此我搜了下,还真有方法,记录下. innodb buffer pool有几个目的: 缓存数据--众所周知,这个占了 ...
- innodb buffer pool小解
INNODB维护了一个缓存数据和索引信息到内存的存储区叫做buffer pool,他会将最近访问的数据缓存到缓冲区.通过配置各个buffer pool的参数,我们可以显著提高MySQL的性能. INN ...
- innodb buffer pool相关特性
背景 innodb buffer pool作为innodb最重要的缓存,其缓存命中率的高低会直接影响数据库的性能.因此在数据库发生变更,比如重启.主备切换实例迁移等等,innodb buffer po ...
- Innodb buffer pool/redo log_buffer 相关
InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理.在数据库系统中,由于CPU速度和磁盘速度之前的鸿沟,通常使用缓冲池技术来提高数据库的整体性能. 1. Innodb_buffe ...
- 14.6.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead) 配置InnoDB Buffer pool 预取
14.6.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead) 配置InnoDB Buffer pool 预取 一个预读请求是一个I/ ...
- 14.6.3.1 The InnoDB Buffer Pool
14.6.3.1 The InnoDB Buffer Pool InnoDB 保持一个存储区域被称为buffer pool 用于cache数据和索引在内存里, 知道InnoDB buffer pool ...
随机推荐
- 如何在Linux快速搭建一套ADB环境
一.ADB简介 1.什么是ADB Android Debug Bridge,安卓调试桥,它借助adb.exe(Android SDK安装目录platform-tools下),用于电脑端与模拟器或者真实 ...
- 大家都能看得懂的源码 - ahooks useSet 和 useMap
本文是深入浅出 ahooks 源码系列文章的第十篇,该系列已整理成文档-地址.觉得还不错,给个 star 支持一下哈,Thanks. 今天我们来聊聊 ahooks 中对 Map 和 Set 类型进行状 ...
- Linux驱动开发十六.input系统——3.系统自带的input驱动
前面两章我们通过input子系统构建了一个按键类型的输入设备的驱动,其实Linux的内核还提供了一套基于GPIO的按键驱动程序,和LED设备一样,我们只需要在编译内核的过程中进行配置然后在设备树中定义 ...
- 【python】一些python用法规律笔记
作为本科用了多年MATLAB的工科生,学起来python有些似曾相识但也有些不习惯的地方. 在这里总结一下,慢慢整理,希望能巩固python语法 一.前闭后开 这个是和MATLAB很大不同.不论是ra ...
- flutter系列之:移动端的手势基础GestureDetector
目录 简介 Pointers和Listener GestureDetector 手势冲突 总结 简介 移动的和PC端有什么不同呢?同样的H5可以运行在APP端,也可以运行在PC端.两者最大的区别就是移 ...
- SpringBoot集成Thymeleaf发送Html邮件报错
由于业务需求需要使用Thymeleaf作为模板发送Html邮件,开发调试过程中发生以下错误 org.thymeleaf.exceptions.TemplateInputException: Error ...
- openstack 搭建详细步骤
该博文转载于(https://www.cnblogs.com/whwh/p/16200004.html) 一.openstack单点部署 1.配置虚拟机NAT网络连接 查看vmware的NAT网络默认 ...
- docker commit镜像
commit镜像 docker commit 从容器创建一个新的镜像. docker commit 提交容器副本使之成为一个新的镜像 #语法 docker commit -m="提交的描述信 ...
- flex常用布局
公共样式: <style> * { margin: 0; padding: 0; } .has-flex { display: flex; } </style> 垂直居中 子元 ...
- CSS之垂直水平居中的背后
最开始,我想说,这个体系有点大,我写的并不好.就当作是一个思路吧,虽然这个思路有点乱.几乎每一个实现方案的背后都是该属性及其组合的原理,每一个都要剖析其规范细节的话,这篇文章绝不会是这样的篇幅,所以每 ...