kafka详解(04) - kafka监控 可视化工具
kafka详解(04) - kafka监控 可视化工具
Kafka监控Eagle
1)修改kafka启动命令
修改kafka-server-start.sh命令中
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
fi
修改之后分发到其他节点
[hadoop@hadoop102 bin]$ scp kafka-server-start.sh hadoop103:/opt/module/kafka/bin/
[hadoop@hadoop102 bin]$ scp kafka-server-start.sh hadoop104:/opt/module/kafka/bin/
重启kafka集群
[hadoop@hadoop102 ~]$ mykafka.sh stop
[hadoop@hadoop102 ~]$ mykafka.sh start
2)上传压缩包kafka-eagle-bin-1.4.5.tar.gz到集群/opt/software目录
3)解压
[hadoop@hadoop102 software]$ tar -zxvf kafka-eagle-bin-1.4.5.tar.gz -C /opt/module/
4)进入到解压目录
[hadoop@hadoop102 software]$ cd /opt/module/kafka-eagle-bin-1.4.5/
[hadoop@hadoop102 kafka-eagle-bin-1.4.5]$ ll
total 73952
-rw-rw-r--. 1 hadoop hadoop 75722791 Mar 21 2020 kafka-eagle-web-1.4.5-bin.tar.gz
5)将kafka-eagle-web-1.4.5-bin.tar.gz解压至/opt/module
[hadoop@hadoop102 kafka-eagle-bin-1.4.5]$ tar -zxvf kafka-eagle-web-1.4.5-bin.tar.gz -C /opt/module/
6)修改名称
[hadoop@hadoop102 kafka-eagle-bin-1.4.5]$ cd /opt/module/
[hadoop@hadoop102 module]$ mv kafka-eagle-web-1.4.5/ eagle
7)给启动文件执行权限
[hadoop@hadoop102 module]$ cd eagle/bin/
[hadoop@hadoop102 bin]$ chmod 777 ke.sh
8)修改配置文件 conf/system-config.properties
[hadoop@hadoop102 bin]$ cd /opt/module/eagle/conf/
[hadoop@hadoop102 conf]$ vi system-config.properties
修改内容如下
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=123456
9)添加环境变量
[hadoop@hadoop102 conf]$ sudo vi /etc/profile
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
使环境变量生效source /etc/profile
10)启动
注意:启动之前需要先启动ZK以及KAFKA
[hadoop@hadoop102 eagle]$ bin/ke.sh start
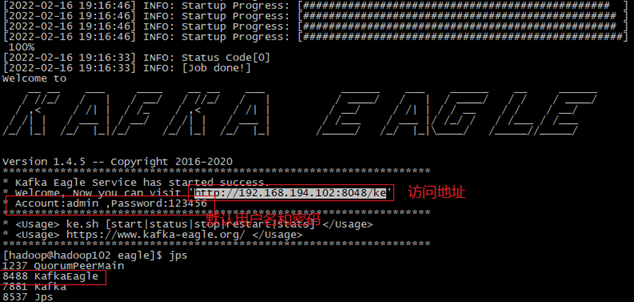
11)登录页面查看监控数据
浏览器中输入如下地址进入到登录界面:http://192.168.194.102:8048/ke
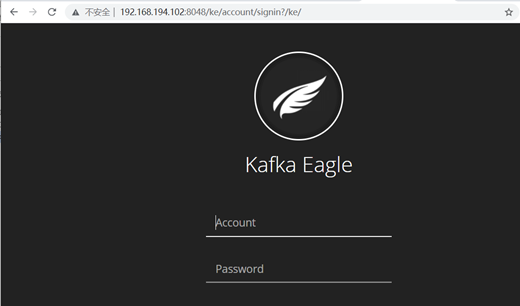
使用默认的用户名/密码(admin/123456)登录
kafka可视化管理平台kafka-console-ui
kafka-console-ui 是一款轻量级的kafka可视化管理平台,安装、配置特别简单,一般来说只需要配置一个kafka集群地址启动即可。
不是一个企业级的平台,目前看来只适合中、小型集群的管理,功能非常简单,没有国际化支持,全是中文展示。页面布局类似rocketmq-console。
这个工具目前主要是以管理功能为主,尽量摆脱繁琐的命令操作,所以没有相关监控指标数据的展示。
github地址:https://github.com/xxd763795151/kafka-console-ui
安装包下载:https://github.com/xxd763795151/kafka-console-ui/releases/download/v1.0.3/kafka-console-ui.zip
Windows中快速启动
解压缩下载好的zip安装包
进入bin目录(必须在bin目录下),双击执行start.bat启动
停止:直接关闭启动的命令行窗口即可
Linux中快速启动
将下载好的安装包上传到服务器中
# 解压缩
unzip kafka-console-ui.zip
# 进入解压缩后的目录
cd kafka-console-ui
# 启动
bin/start.sh
# 停止
bin/shutdown.sh
配置kafka集群并使用
启动完成后通过浏览器访问:http://hadoop102:7766
第一次启动,打开浏览器后,因为还没有配置kafka集群信息,所以页面右上角会有错误信息,比如:No Cluster Info或者是没有集群信息,请先切换集群之类的提示。
集群配置如下:
点击页面上方导航栏的 [运维] 菜单
点击集群管理下的 [集群切换] 按钮
在弹框里点击 [新增集群]
然后输入kafka集群名称(随便起个名字)和地址(IP:PORT),多个地址用逗号分隔
点击提交便增加成功了
增加成功可以看到会话框已经有这个集群信息,然后点击右侧的 [切换] 按钮,便切换该集群为当前集群
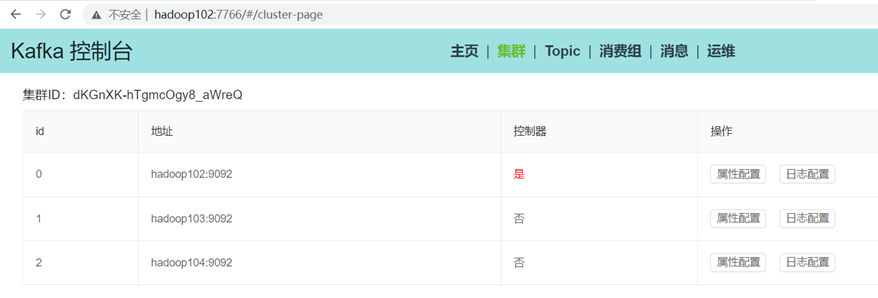
后续如果再增加其它集群,就可以按上面这个流程,如果想切换到哪个集群,点击切换按钮,便会切换到对应的集群,页面的右上角会显示当前是使用的哪个集群。
在新增集群的时候,除了集群地址还可以输入集群的其它属性配置,比如请求超时,ACL配置等。如果开启了ACL,切换到该集群的时候,导航栏上便会出现ACL菜单,支持进行相关操作
kafka详解(04) - kafka监控 可视化工具的更多相关文章
- kafka详解(一)--kafka是什么及怎么用
kafka是什么 在回答这个问题之前,我们需要先了解另一个东西--event streaming. 什么是event streaming 我觉得,event streaming 是一个动态的概念,它描 ...
- kafka详解(二)--kafka为什么快
前言 Kafka 有多快呢?我们可以使用 OpenMessaging Benchmark Framework 测试框架方便地对 RocketMQ.Pulsar.Kafka.RabbitMQ 等消息系统 ...
- 实例详解 DB2 排序监控和调优
实例详解 DB2 排序监控和调优http://automationqa.com/forum.php?mod=viewthread&tid=2882&fromuid=2
- Kafka 详解(二)------集群搭建
这里通过 VMware ,我们安装了三台虚拟机,用来搭建 kafka集群,虚拟机网络地址如下: hostname ipaddress ...
- [转]kafka详解
一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设 ...
- kafka详解
一.基本概念 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计. 这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语:Kafk ...
- (转)kafka 详解
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建(转) 问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的 ...
- Kafka详解二:如何配置Kafka集群
问题导读1.Kafka有哪几种配制方法?2.如何启动一个Consumer实例来消费消息? Kafka集群配置比较简单,为了更好的让大家理解,在这里要分别介绍下面三种配置 单节点:一个broker的集群 ...
- Kafka 详解(转)
转载自:https://blog.csdn.net/lingbo229/article/details/80761778 Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区 ...
- 图文详解:Kafka到底有哪些秘密让我对它情有独钟呢?
随机推荐
- vue实现功能 单选 取消单选 全选 取消全选
vue实现功能 单选 取消单选 全选 取消全选 代码部分 <template> <div class=""> <h1>全选框</h1> ...
- Java注解(2):实现自己的ORM
搞过Java的码农都知道,在J2EE开发中一个(确切地说,应该是一类)很重要的框架,那就是ORM(Object Relational Mapping,对象关系映射).它把Java中的类和数据库中的表关 ...
- HDFS追加数据报错解决办法
主要的两个错误,今天晚上一直轮着报: 第一个 2022-10-25 21:37:11,901 WARN hdfs.DataStreamer: DataStreamer Exception java.i ...
- JAVA系列之JVM内存调优
一.前提 JVM性能调优牵扯到各方面的取舍与平衡,往往是牵一发而动全身,需要全盘考虑各方面的影响.在优化时候,切勿凭感觉或经验主义进行调整,而是需要通过系统运行的客观数据指标,不断找到最优解.同时,在 ...
- DQL-模糊查询
DQL-模糊查询 模糊查询即模糊检索,是指搜索系统自动按照用户输入关键词的同义词进行模糊检索,从而得出较多的检索结果.与之相反的是"精准搜索".模糊检索也可以说是同义词检索,这里的 ...
- 安装nvm 和 yarn
安装nvm curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash 执行上面的命令 如果出现问题 ...
- JS 学习笔记(二)Ajax的简单使用
使用Ajax访问本地TXT文件 ajax.js // 创建请求对象 var ajax = new XMLHttpRequest(); // 建立连接 ajax.open('get', 'test.tx ...
- 【Bluetooth|蓝牙开发】二、蓝牙开发入门
个人主页:董哥聊技术 我是董哥,嵌入式领域新星创作者 创作理念:专注分享高质量嵌入式文章,让大家读有所得! [所有文章汇总] 1.蓝牙基础概念 蓝牙,是一种利用低功率无线电,支持设备短距离通信的无线电 ...
- 论文笔记 - GRAD-MATCH: A Gradient Matching Based Data Subset Selection For Efficient Learning
Analysis Coreset 是带有权重的数据子集,目的是在某个方面模拟完整数据的表现(例如损失函数的梯度,既可以是在训练数据上的损失,也可以是在验证数据上的损失): 给出优化目标的定义: $w^ ...
- Codeforces Round #828 (Div. 3) E2. Divisible Numbers (分解质因子,dfs判断x,y)
题目链接 题目大意 给定a,b,c,d四个数,其中a<c,b<c,现在让你寻找一对数(x,y),满足一下条件: 1. a<x<c,b<y<d 2. (x*y)%(a ...