「SOL」序列 (LOJ/NOI2019)
准备写新博客的时候发现自己草稿箱里还有一篇咕了十几天的题解
思路挂在了费用流之前……
题面
> Link LOJ #3158
解析
这道题的本质是一个二分图带权匹配的问题,一个经典的做法是直接做费用流。
考虑如何在流网络中体现限制。只能选择恰好 \(K\) 对非常简单,只需要控制总流量为 \(K\) 即可;主要是 \(L\) 的限制。网络流并不容易限制下界,所幸总流量固定为 \(K\),所以反过来考虑,「至少有 \(L\) 对 “A-A” 型的匹配」,则「至多有 \(K-L\) 对 “A-B” 型的匹配」。
考虑这样建图(以下「边权」指边的费用):
- \(a,b\) 两个序列各自作为二分图的一个部,\(a\) 部与源点 \(S\) 的边权为 \(a_i\),\(b\) 部与汇点同理;
- \(a_i\) 到 \(b_i\) 直接连边,表示一种 “A-A” 型的匹配;
- 新建两个特殊点 \(p,q\),边 \(p\to q\) 容量限制为 \(K-L\),用于处理 “A-B” 型:
- \(a_i\) 向 \(p\) 连边,\(q\) 向 \(b_j\) 连边;
- 这样 \(a_i\to p\to q\to b_j\) 即构成了 “A-B” 型匹配。
流网络大概长这样:

直接限制总流量为 \(K\) 跑最大费用流,可以获得不错的部分分。
既然是费用流,而且流网络比较规整,可以尝试模拟费用流 —— 简单的说就是快速找“\(S\) 到 \(T\) 的最长路”。考虑一条最长路会长什么样。
一个点「被选」指它的匹配方式是 A-B 匹配,一个 S 部的被选点 \(u\) 具有反向边 \(p\to u\),一个 T 部的被选点 \(v\) 具有反向边 \(v\to q\)。
一个点「为空」指它还没有被匹配。
一条路径开头一定是 \(S\to a\),结尾一定是 \(b'\to T\),其中 \(a,b'\) 均为空。大概会有以下四种情况:
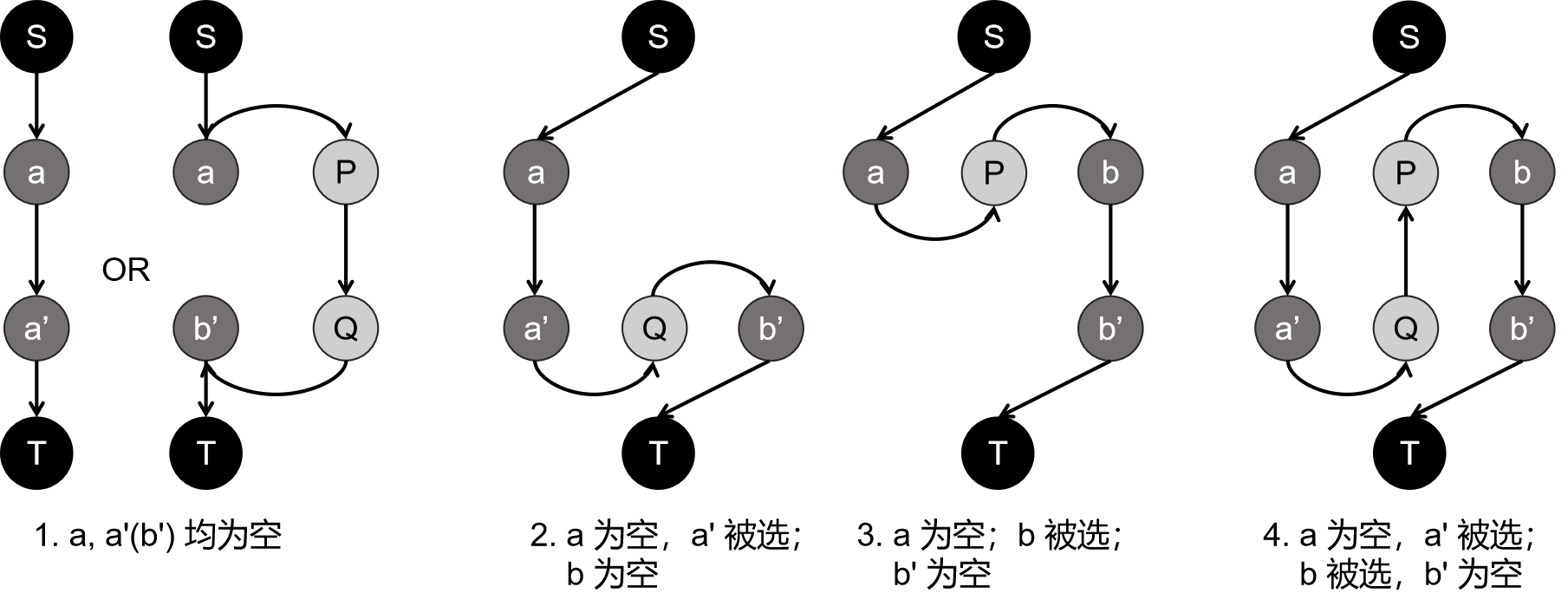
注意到只有 \(S\to a\) 和 \(b'\to T\) 这两种边有费用,所以决定路径长度的其实就只有开头和结尾。
于是我们发现我们需要维护以下信息:
- 空的 \(a\);
- 空的 \(b'\);
- \(a'\) 被选,且 \(a\) 为空的 \(a\);
- \(b\) 被选,且 \(b'\) 为空的 \(b'\);
这四类信息都可以用堆维护最大值。继续考虑如何模拟费用流——
我们每找一条最长路,就会把 \(S\to T\) 的总流量增加 \(1\),所以限制总流量为 \(K\) 则只需要找 \(K\) 次最长路即可。
然后这张流网络上还有一条特殊的边 \(P\to Q\),需要维护它的容量。在上图列出的四种情况中:
- 若为 \(a\to a'\),则容量不变;若为 \(a\to b'\),则容量 \(-1\);
- 容量不变;
- 容量不变;
- 容量 \(+1\)。
另外,我们有时会发现 \(a\) 和 \(a'\) 同时被选,显然是不优的。这种时候就可以把 \(a\) 和 \(a'\) 同时改为不被选,答案不变但是 \(P\to Q\) 容量 \(+1\)。
直接模拟即可。
源代码
/*Lucky_Glass*/
#include <queue>
#include <cstdio>
#include <cstring>
#include <cassert>
#include <algorithm>
inline int rin(int &r) {
int c = getchar(); r = 0;
while ( c < '0' || '9' < c ) c = getchar();
while ( '0' <= c && c <= '9' ) r = r * 10 + (c ^ '0'), c = getchar();
return r;
}
typedef long long llong;
typedef std::pair<int, int> pii;
#define CON(typ) const typ &
const int N = 2e5 + 10;
int ncas, n, nk, nl;
int num[N << 1];
std::priority_queue<pii> emp[2], opp[2], par;
bool cov[N << 1], used[N << 1];
void clean() {
while ( !emp[0].empty() ) emp[0].pop();
while ( !emp[1].empty() ) emp[1].pop();
while ( !opp[0].empty() ) opp[0].pop();
while ( !opp[1].empty() ) opp[1].pop();
while ( !par.empty() ) par.pop();
for ( int i = 1; i <= (n << 1); ++i )
cov[i] = used[i] = false;
}
int empTop(CON(bool) typ) {
while ( !emp[typ].empty() && used[emp[typ].top().second] ) emp[typ].pop();
return emp[typ].empty() ? -1 : emp[typ].top().second;
}
int oppTop(CON(bool) typ) {
#define OPPID(x) ((x) <= n ? (x) + n : (x) - n)
while ( !opp[typ].empty() && (used[opp[typ].top().second]
|| !cov[OPPID(opp[typ].top().second)]) )
opp[typ].pop();
return opp[typ].empty() ? -1 : opp[typ].top().second;
#undef OPPID
}
int parTop() {
while ( !par.empty() && (used[par.top().second]
|| used[par.top().second + n]) )
par.pop();
return par.empty() ? -1 : par.top().second;
}
void checkCross(CON(int) id, int &rem) {
#define OPPID(x) ((x) <= n ? (x) + n : (x) - n)
if ( cov[OPPID(id)] && cov[id] ) {
cov[OPPID(id)] = cov[id] = false;
++rem;
}
#undef OPPID
}
llong findPath(int &rem) {
#define GID(x) (std::make_pair(num[x], x))
llong ee = -1, eo = -1, oe = -1, oo = -1;
int etop[2] = {empTop(0), empTop(1)}, otop[2] = {oppTop(0), oppTop(1)},
ptop = parTop();
if ( rem && ~etop[0] && ~etop[1] ) ee = num[etop[0]] + num[etop[1]];
if ( !rem && ~ptop ) ee = num[ptop] + num[ptop + n];
if ( ~etop[0] && ~otop[1] ) eo = num[etop[0]] + num[otop[1]];
if ( ~otop[0] && ~etop[1] ) oe = num[otop[0]] + num[etop[1]];
if ( ~otop[0] && ~otop[1] ) oo = num[otop[0]] + num[otop[1]];
llong mx = std::max(std::max(ee, eo), std::max(oe, oo));
if ( mx == ee ) {
if ( rem ) {
--rem;
used[etop[0]] = used[etop[1]] = true;
cov[etop[0]] = cov[etop[1]] = true;
checkCross(etop[0], rem), checkCross(etop[1], rem);
opp[1].push(GID(etop[0] + n));
opp[0].push(GID(etop[1] - n));
}
else {
used[ptop] = used[ptop + n] = true;
}
} else if ( mx == eo ) {
used[etop[0]] = used[otop[1]] = true;
cov[etop[0]] = true, cov[otop[1] - n] = false;
checkCross(etop[0], rem);
opp[1].push(GID(etop[0] + n));
} else if ( mx == oe ) {
used[otop[0]] = used[etop[1]] = true;
cov[etop[1]] = true, cov[otop[0] + n] = false;
checkCross(etop[1], rem);
opp[0].push(GID(etop[1] - n));
} else {
++rem;
used[otop[0]] = used[otop[1]] = true;
cov[otop[0] + n] = cov[otop[1] - n] = false;
}
return mx;
}
void solve() {
rin(n), rin(nk), rin(nl);
clean();
for ( int i = 1; i <= n; ++i )
emp[0].push(std::make_pair(rin(num[i]), i));
for ( int i = 1; i <= n; ++i ) {
emp[1].push(std::make_pair(rin(num[i + n]), i + n));
par.push(std::make_pair(num[i] + num[i + n], i));
}
llong ans = 0;
int rem = nk - nl;
for ( int i = 0; i < nk; ++i )
ans += findPath(rem);
printf("%lld\n", ans);
}
int main() {
freopen("sequence.in", "r", stdin);
freopen("sequence.out", "w", stdout);
rin(ncas);
while ( ncas-- ) solve();
return 0;
}
THE END
Thanks for reading!
「SOL」序列 (LOJ/NOI2019)的更多相关文章
- Loj #3059. 「HNOI2019」序列
Loj #3059. 「HNOI2019」序列 给定一个长度为 \(n\) 的序列 \(A_1, \ldots , A_n\),以及 \(m\) 个操作,每个操作将一个 \(A_i\) 修改为 \(k ...
- loj #2051. 「HNOI2016」序列
#2051. 「HNOI2016」序列 题目描述 给定长度为 n nn 的序列:a1,a2,⋯,an a_1, a_2, \cdots , a_na1,a2,⋯,an,记为 a[1: ...
- 「HNOI2016」序列 解题报告
「HNOI2016」序列 有一些高妙的做法,懒得看 考虑莫队,考虑莫队咋移动区间 然后你在区间内部找一个最小值的位置,假设现在从右边加 最小值左边区间显然可以\(O(1)\),最小值右边的区间是断掉的 ...
- AC日记——「SDOI2017」序列计数 LibreOJ 2002
「SDOI2017」序列计数 思路: 矩阵快速幂: 代码: #include <bits/stdc++.h> using namespace std; #define mod 201704 ...
- 「JSOI2014」序列维护
「JSOI2014」序列维护 传送门 其实这题就是luogu的模板线段树2,之所以要发题解就是因为学到了一种比较NB的 \(\text{update}\) 的方式.(参见这题) 我们可以把修改操作统一 ...
- LOJ #2183「SDOI2015」序列统计
有好多好玩的知识点 LOJ 题意:在集合中选$ n$个元素(可重复选)使得乘积模$ m$为$ x$,求方案数对$ 1004535809$取模 $ n<=10^9,m<=8000且是质数,集 ...
- LOJ 3059 「HNOI2019」序列——贪心与前后缀的思路+线段树上二分
题目:https://loj.ac/problem/3059 一段 A 选一个 B 的话, B 是这段 A 的平均值.因为 \( \sum (A_i-B)^2 = \sum A_i^2 - 2*B \ ...
- loj#2002. 「SDOI2017」序列计数(dp 矩阵乘法)
题意 题目链接 Sol 质数的限制并没有什么卵用,直接容斥一下:答案 = 忽略质数总的方案 - 没有质数的方案 那么直接dp,设\(f[i][j]\)表示到第i个位置,当前和为j的方案数 \(f[i ...
- 【LOJ】#2183. 「SDOI2015」序列统计
题解 这个乘积比较麻烦,转换成原根的指数乘法就相当于指数加和了,可以NTT优化 注意判掉0 代码 #include <bits/stdc++.h> #define fi first #de ...
- 「BZOJ1251」序列终结者 (splay 区间操作)
题面: 1251: 序列终结者 Time Limit: 20 Sec Memory Limit: 162 MBSubmit: 5367 Solved: 2323[Submit][Status][D ...
随机推荐
- Pytorch之数据处理
使用TensorDataset和DataLoader来简化 from torch.utils.data import TensorDataset from torch.utils.data imp ...
- ECDSA签名验证
using System; using System.IO; using System.Text; using Org.BouncyCastle.Crypto; using Org.BouncyCas ...
- 公司官网百度搜素优化(www.curetech.cc)
1. 解读" 百度搜素引擎网页质量白皮书 " . 链接:https://pan.baidu.com/s/1fD7Cm93qsK01M0K1M1cIKw 提取码:9krx 2. ...
- webpack的加载器兼容配置一览
"devDependencies": { "css-loader": "^3.2.1", "file-loader": ...
- Hadoop完全分布式开发配置流程
完全分布式开发 整体流程 1.准备3台纯净虚拟机 2.修改每台ip,主机名,主机映射,关闭防火墙 3.安装jdk和hadoop,配置环境变量 4.集群分发脚本编写 5.集群配置 6.ssh免密登录 7 ...
- Day23:个人小结的撰写&&对coderunner的熟悉
今日完成的任务: 1.完成个人小结的撰写 2.阅读Moodle文档,了解Moodle平台以及Moodle出题格式 明日计划: 1.撰写总报告中的结论 2.将插件安装完成 每日小结: 为了研究题库,特 ...
- 文本超出换行添加white-space:wrap无效
场景描述: 在vue项目中,在Modal弹窗里面使用Form表单组件,然后在FormItem里面放一个div标签用来装文字内容.有时会出现内容超出Form表单宽度但是不换行的问题. 解决方法: 给di ...
- python日志篇-基础版
对常用python日志语法做记录,方便以后重复使用 print内容记录到文件: #!/usr/bin/env python # -*- coding: utf-8 -*- ##____________ ...
- golang 日志
package log import ( "NOONASN/global" "github.com/natefinch/lumberjack" "go ...
- 极米投影仪安装apk的方法
https://www.touying.com/t-37871-1.html 方法二:使用U盘安装:1.使用电脑下载软件apk,并将软件apk的后缀修改为"apk1": 2.然后将 ...