2022-08-30:给你一个字符串化学式 formula ,返回 每种原子的数量 。 原子总是以一个大写字母开始,接着跟随 0 个或任意个小写字母,表示原子的名字。 如果数量大于 1,原子后会跟着数
2022-08-30:给你一个字符串化学式 formula ,返回 每种原子的数量 。
原子总是以一个大写字母开始,接着跟随 0 个或任意个小写字母,表示原子的名字。
如果数量大于 1,原子后会跟着数字表示原子的数量。如果数量等于 1 则不会跟数字。
例如,“H2O” 和 “H2O2” 是可行的,但 “H1O2” 这个表达是不可行的。
两个化学式连在一起可以构成新的化学式。
例如 “H2O2He3Mg4” 也是化学式。
由括号括起的化学式并佐以数字(可选择性添加)也是化学式。
例如 “(H2O2)” 和 “(H2O2)3” 是化学式。
返回所有原子的数量,格式为:第一个(按字典序)原子的名字,跟着它的数量(如果数量大于 1),
然后是第二个原子的名字(按字典序),跟着它的数量(如果数量大于 1),以此类推。
示例 1:
输入:formula = “H2O”
输出:“H2O”
解释:原子的数量是 {‘H’: 2, ‘O’: 1}。
示例 2:
输入:formula = “Mg(OH)2”
输出:“H2MgO2”
解释:原子的数量是 {‘H’: 2, ‘Mg’: 1, ‘O’: 2}。
示例 3:
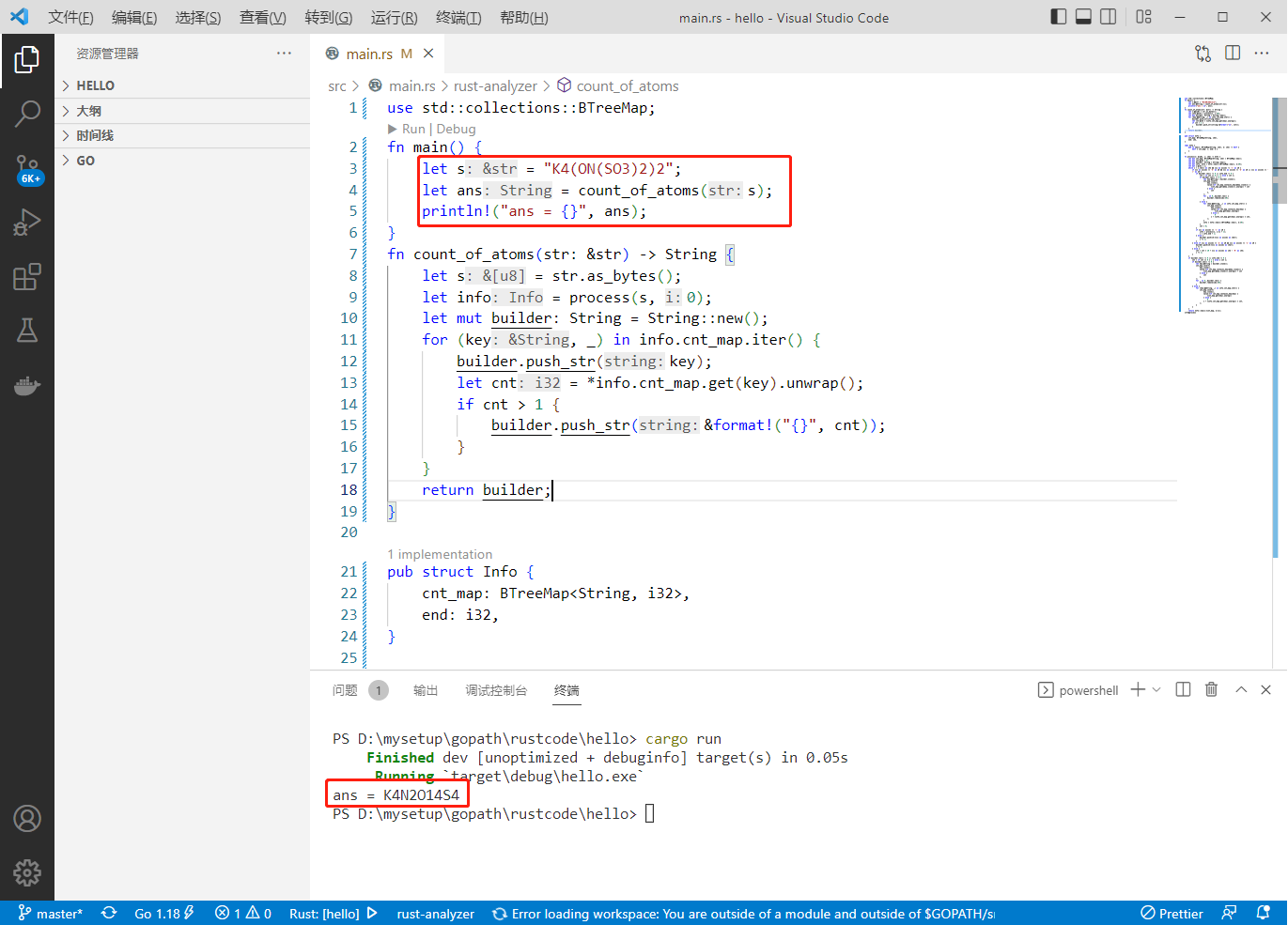
输入:formula = “K4(ON(SO3)2)2”
输出:“K4N2O14S4”
解释:原子的数量是 {‘K’: 4, ‘N’: 2, ‘O’: 14, ‘S’: 4}。
答案2022-08-30:
递归。遇到左括号,进入递归;遇到右括号,退出递归。要用到TreeMap,rust里是std::collections::BTreeMap。
代码用rust编写。代码如下:
use std::collections::BTreeMap;
fn main() {
let s = "K4(ON(SO3)2)2";
let ans = count_of_atoms(s);
println!("ans = {}", ans);
}
fn count_of_atoms(str: &str) -> String {
let s = str.as_bytes();
let info = process(s, 0);
let mut builder: String = String::new();
for (key, _) in info.cnt_map.iter() {
builder.push_str(key);
let cnt = *info.cnt_map.get(key).unwrap();
if cnt > 1 {
builder.push_str(&format!("{}", cnt));
}
}
return builder;
}
pub struct Info {
cnt_map: BTreeMap<String, i32>,
end: i32,
}
impl Info {
pub fn new(c: BTreeMap<String, i32>, e: i32) -> Self {
Self { cnt_map: c, end: e }
}
}
fn process(s: &[u8], i: i32) -> Info {
let mut cnt_map: BTreeMap<String, i32> = BTreeMap::new();
let mut cnt = 0;
let mut builder: String = String::new();
let mut info: Info = Info::new(BTreeMap::new(), 0);
let mut i = i;
while i < s.len() as i32 && s[i as usize] != ')' as u8 {
if s[i as usize] >= 'A' as u8 && s[i as usize] <= 'Z' as u8 || s[i as usize] == '(' as u8 {
if builder.len() != 0 || info.end != 0 {
cnt = if cnt == 0 { 1 } else { cnt };
if builder.len() != 0 {
let key = builder.clone();
cnt_map.insert(
key.clone(),
if cnt_map.contains_key(&key.clone()) {
*cnt_map.get(&key.clone()).unwrap() + cnt
} else {
cnt
},
);
for _ in 0..builder.len() {
builder.remove(0);
}
} else {
for (key, _) in info.cnt_map.iter() {
cnt_map.insert(
key.clone(),
if cnt_map.contains_key(key) {
*cnt_map.get(key).unwrap()
} else {
0
} + *info.cnt_map.get(key).unwrap() * cnt,
);
}
info = Info::new(BTreeMap::new(), 0);
}
cnt = 0;
}
if s[i as usize] == '(' as u8 {
info = process(s, i + 1);
i = info.end + 1;
} else {
builder.push(s[i as usize] as char);
i += 1;
}
} else if s[i as usize] >= 'a' as u8 && s[i as usize] <= 'z' as u8 {
builder.push(s[i as usize] as char);
i += 1;
} else {
cnt = cnt * 10 + s[i as usize] as i32 - '0' as i32;
i += 1;
}
}
if builder.len() != 0 || info.end != 0 {
cnt = if cnt == 0 { 1 } else { cnt };
if builder.len() != 0 {
let key = builder.clone();
cnt_map.insert(
key.clone(),
if cnt_map.contains_key(&key.clone()) {
*cnt_map.get(&key.clone()).unwrap() + cnt
} else {
cnt
},
);
for _ in 0..builder.len() {
builder.remove(0);
}
} else {
for (key, _) in info.cnt_map.iter() {
cnt_map.insert(
key.clone(),
if cnt_map.contains_key(key) {
*cnt_map.get(key).unwrap()
} else {
0
} + *info.cnt_map.get(key).unwrap() * cnt,
);
}
}
}
return Info::new(cnt_map, i);
}
执行结果如下:
2022-08-30:给你一个字符串化学式 formula ,返回 每种原子的数量 。 原子总是以一个大写字母开始,接着跟随 0 个或任意个小写字母,表示原子的名字。 如果数量大于 1,原子后会跟着数的更多相关文章
- 字串符相关 split() 字串符分隔 substring() 提取字符串 substr()提取指定数目的字符 parseInt() 函数可解析一个字符串,并返回一个整数。
split() 方法将字符串分割为字符串数组,并返回此数组. stringObject.split(separator,limit) 我们将按照不同的方式来分割字符串: 使用指定符号分割字符串,代码如 ...
- 已知一个字符串S 以及长度为n的字符数组a,编写一个函数,统计a中每个字符在字符串中的出现次数
import java.util.Scanner; /** * @author:(LiberHome) * @date:Created in 2019/3/6 21:04 * @description ...
- Java中将一个字符串传入数组的几种方法
String Str="abnckdjgdag"; char a[]=new char[Str.length()]; -------------------方法1 用于取出字符串的 ...
- 给定一种 pattern(模式) 和一个字符串 str ,判断 str 是否遵循相同的模式。 这里的遵循指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向连接的对应模式。
这个是LeetCode上的一道题目.本机上运行时正确的,但是LeetCode上显示是错误的,所以没有办法了只能记录在博客上了. 我的想法是先把pattern和str都转化成数组.例如"abb ...
- (转)sscanf() - 从一个字符串中读进与指定格式相符的数据
(转)sscanf() - 从一个字符串中读进与指定格式相符的数据 sscanf() - 从一个字符串中读进与指定格式相符的数据. 函数原型: Int sscanf( string str, stri ...
- 查找常用字符(给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表。例如,如果一个字符在每个字符串中出现 3 次,但不是 4 次,则需要在最终答案中包含该字符 3 次。)
给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表. 例如,如果一个字符在每个字符串中出现 3 次,但不是 4 次,则需要在最终答案中包含该字符 ...
- 290.单词模式。给定一种 pattern(模式) 和一个字符串 str ,判断 str 是否遵循相同的模式。(c++方法)
题目描述: 给定一种 pattern(模式) 和一个字符串 str ,判断 str 是否遵循相同的模式. 这里的遵循指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非空单词之 ...
- js中如何判断一个字符串包含另外一个字符串?
js中判断一个字符串包含另外一个字符串的方式比较多? 比如indexOf()方法,注意O是大写. var test="this is a test"; if(test.indexO ...
- JavaScript确定一个字符串是否包含在另一个字符串中的四种方法
一.indexOf() 1.定义 indexOf()方法返回String对象第一次出现指定字符串的索引,若未找到指定值,返回-1.(数组同一个概念) 2.语法 str.indexOf(searchVa ...
- JAVA经典题--计算一个字符串中每个字符出现的次数
需求: 计算一个字符串中每个字符出现的次数 思路: 通过toCharArray()拿到一个字符数组--> 遍历数组,将数组元素作为key,数值1作为value存入map容器--> 如果k ...
随机推荐
- beast加密
Beast: https://github.com/liexusong/php-beast?tdsourcetag=s_pctim_aiomsgbeast-安裝到/root------------- ...
- spring-service.xml
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...
- windows2003 的安装以及安装时遇到的问题
windows2003 的安装以及安装时遇到的问题 简介:Windows Server 2003是微软于2003年3月28日发布的基于Windows XP/NT5.1开发的服务器操作系统,并在同年4月 ...
- 【AI 全栈 SOTA 综述 】这些你都不知道,怎么敢说会 AI?【语音识别原理 + 实战】
章目录 前言语音识别原理 信号处理,声学特征提取 识别字符,组成文本 声学模型 语言模型 词汇模型语音声学特征提取:MFCC和LogFBank算法的原理实战一 ASR语音识别模型 ...
- SpringBoot 启动类的原理
SpringBoot启动类上使用 @SpringBootApplication注解,该注解是一个组合注解,包含多个其它注解.和类定义(SpringApplication.run)要揭开 SpringB ...
- CSAPP-Shell Lab
提供的工具: parseline:获取参数列表char **argv,返回是否为后台运行命令(true). clearjob:清除job结构. initjobs:初始化jobs链表. maxjid:返 ...
- requests发送post请求
post请求 语法结构 requests.post(url,data = None,json = None) 参数说明 url:需要爬取的网站的网址 data:请求数据 json:json格式的数据 ...
- 实现⼀个简洁版的promise
// 三个常量⽤于表示状态 const PENDING = 'pending' const RESOLVED = 'resolved' const REJECTED = 'rejected' func ...
- Hive 和 Spark 分区策略剖析
作者:vivo 互联网搜索团队- Deng Jie 随着技术的不断的发展,大数据领域对于海量数据的存储和处理的技术框架越来越多.在离线数据处理生态系统最具代表性的分布式处理引擎当属Hive和Spark ...
- Ubuntu 通过 Netplan 配置网络教程
Ubuntu 通过 Netplan 配置网络教程 Ubuntu through Netplan configuration network tutorial 一.Netplan 配置流程 1. Net ...