【Basic Knowledge】Self-Attention Generative Adversarial Networks

Note
这是一篇将Self-Attention应用到GAN中的paper,Self-Attention模块是卷积模块的补充,能够有助于建模跨图像区域的长范围、多层次依赖关系。文中主要提到4点:
- 在生成的过程中,可以使用所有的特征来生成高分辨率的细节,每个位置的精细细节都与图像远处部分的精细细节仔细协调;
- 在判别的过程中,判别器可以检查图像中较远部分的高度详细的特征是否彼此一致,还可以更准确地在全局图像结构上执行复杂的几何约束;
- 将谱归一化(Spectral Normalization)应用于GAN生成器和判别器,能够改善训练动态;
- 在对生成器和判别器进行更新时,使用不一致的学习率。
Paper Details
1. Self-Attention Generative Adversarial Networks
在图像生成任务中,大多数基于GAN的模型使用卷积层对网络进行构建,卷积处理局部邻域中的信息,但是单独使用卷积层对图像中的长期依赖性建模在计算上是低效的。在paper中,采用非局部模型,将自注意力机制引入GAN框架,使生成器和判别器能够有效地建模广泛分离的空间区域之间的关系。网络框架如下图:
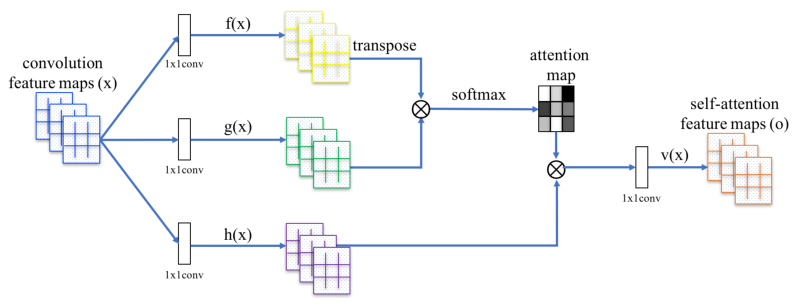
具体实现如下:
Self-Attention层的输入为前一层的输出 x∈
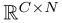 (C为通道数,N为上一隐藏层特征数),经过1 x 1的卷积后,形成 f(x) 和 g(x) 两个特征空间 ( f(x) =
(C为通道数,N为上一隐藏层特征数),经过1 x 1的卷积后,形成 f(x) 和 g(x) 两个特征空间 ( f(x) = 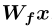 ,g(x) =
,g(x) = 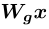 ),用来计算注意力
),用来计算注意力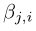 (表示在合成第j个区域时,模型关注第i个位置的程度),计算方式如下:
(表示在合成第j个区域时,模型关注第i个位置的程度),计算方式如下:

Self-Attention层的输出为
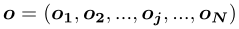 ∈,其中,
∈,其中,
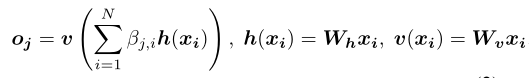
对于以上的计算公式,四个W都是网络训练过程中学习到的权重,具体实现为上边提到的1 x 1卷积。最后,将Self-Attention层的输出乘以一个比例参数,再添加回输入的特征图,形成最后的输出 (γ是一个可学习的标量,它初始化为0) :
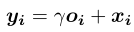
Note:引入可学习γ允许网络首先依赖于局部邻域的线索,因为这更容易,然后逐渐学会给非局部证据分配更多的权重。即:先学习简单的任务,然后逐步增加任务的复杂性。
2. Techniques to Stabilize the Training of GANs
Paper还研究了两种技术来稳定GANs在具有挑战性的数据集上的训练。
- 生成器和判别器中使用谱归一化 (Spectral Normalization) ;
- 确认两时间尺度更新规则(TTUR)是有效的,主张专门使用它来解决正则化鉴别器中的缓慢学习。
2.1 Spectral normalization for both generator and discriminator
Paper认为生成器也可以受益于谱归一化,使用在判别器上的谱归一化亦可使用在生成器,如下:
- 谱归一化在生成器中可以防止参数幅度的上升和避免异常梯度;
- 生成器和判别器的谱归一化使得每次生成器的更新使用更少的判别器更新,从而显著降低了训练的计算成本;
- 该方法还显示出更稳定的训练行为。
2.2 Imbalanced learning rate for generator and discriminator updates
在实践中,使用正则化鉴别器的方法在训练过程中,每个生成器更新步骤通常需要多个(例如5个)判别器更新步骤,会减慢GANs的学习过程。Paper中建议专门使用TTUR来弥补正则化判别器中学习缓慢的问题,使得每个生成器步骤使用更少的判别器步骤。使用这种方法,能够在相同的时间下产生更好的结果。
两种改进的效果如下图:
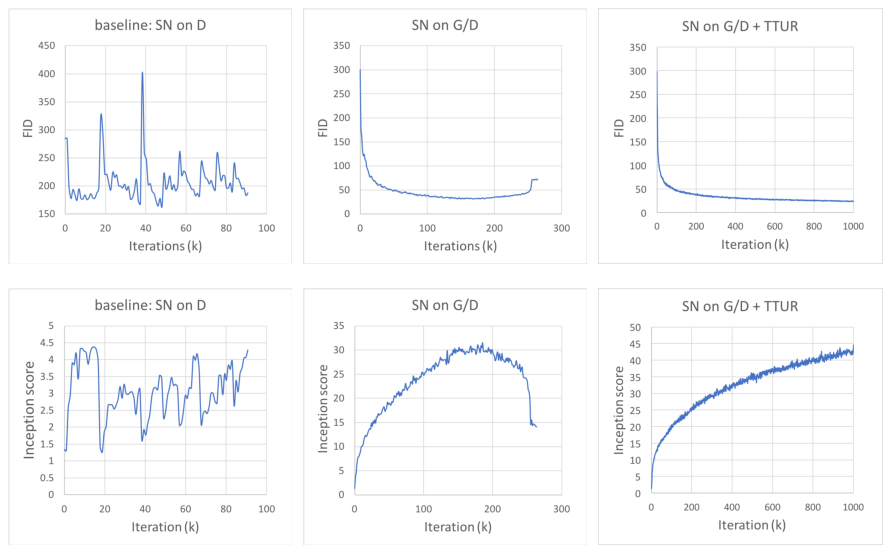

3. Experiments Details
训练的所有SAGAN模型都是用来生成128×128图像的。默认情况下:
- 谱归一化用于生成器和鉴别器中的层;
- SAGAN在生成器中使用有条件批处理归一化,在判别器中进行判别推测;
- 对于所有模型,我们使用β1 = 0和β2 = 0.9的Adam优化器进行训练;
- 缺省情况下,判别器的学习率为0.0004,生成器的学习率为0.0001;
- 在较深的层次中使用Self-Attention效果比在较浅的层中使用效果好。如图:

4. Visualization of attention maps

如上的图像是由SAGAN生成的,Paper中将使用Attention的最后一个生成器层的注意力映射可视化,因为这一层最接近输出像素,最直接地投射到像素空间中。
在每个单元格中,第一张图像用彩色点显示了三个具有代表性的查询位置。其他三张图片是这些查询位置的注意力图,对应的彩色箭头总结了最受关注的区域。可以观察到,网络学会根据颜色和纹理的相似性来分配注意力,而不仅仅是空间邻接 (见左上角的单元格) 。
我们还发现,虽然一些查询点在空间位置上非常接近,但它们的注意力图可能有很大的不同,如左下角单元格所示。如右上单元格所示,SAGAN能够画出腿明显分开的狗。蓝色查询点表示注意有助于正确获得关节区域的结构。
5. Comparison with the state-of-the-art
SAGAN与最先进的GAN模型的比较如下图所示。(Inception Score越高,图像质量越好; FID表示真实图像与生成图像之间的距离,FID越低,越准确)

另外,SAGAN在合成具有复杂几何或结构模式(如金鱼和圣伯纳)的图像类时,比最先进的GAN模型获得了更好的性能(即更低的内部FID)。对于结构约束较少的类(例如,山谷、石墙和珊瑚真菌,它们更多地是通过纹理而不是几何来区分),我们的SAGAN与基线模型相比表现出较少的优势。原因是SAGAN中的自注意力是对捕获在几何或结构模式中一致出现的远距离全局级依赖的卷积的补充,但在为简单纹理建模依赖时,它与局部卷积起着类似的作用。实验结果如下图所示:

【Basic Knowledge】Self-Attention Generative Adversarial Networks的更多相关文章
- 【文献阅读】Perceptual Generative Adversarial Networks for Small Object Detection –CVPR-2017
Perceptual Generative Adversarial Networks for Small Object Detection 2017CVPR 新鲜出炉的paper,这是针对small ...
- 论文笔记之:Semi-Supervised Learning with Generative Adversarial Networks
Semi-Supervised Learning with Generative Adversarial Networks 引言:本文将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 论文解读(GAN)《Generative Adversarial Networks》
Paper Information Title:<Generative Adversarial Networks>Authors:Ian J. Goodfellow, Jean Pouge ...
- 《Self-Attention Generative Adversarial Networks》里的注意力计算
前天看了 criss-cross 里的注意力模型 仔细理解了 在: https://www.cnblogs.com/yjphhw/p/10750797.html 今天又看了一个注意力模型 < ...
- (转)Introductory guide to Generative Adversarial Networks (GANs) and their promise!
Introductory guide to Generative Adversarial Networks (GANs) and their promise! Introduction Neural ...
- SAGAN:Self-Attention Generative Adversarial Networks - 1 - 论文学习
Abstract 在这篇论文中,我们提出了自注意生成对抗网络(SAGAN),它是用于图像生成任务的允许注意力驱动的.长距离依赖的建模.传统的卷积GANs只根据低分辨率图上的空间局部点生成高分辨率细节. ...
- GD-GAN: Generative Adversarial Networks for Trajectory Prediction and Group Detection in Crowds
GD-GAN: Generative Adversarial Networks for Trajectory Prediction and Group Detection in Crowds 2019 ...
- AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记 这 ...
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 本文将利 ...
随机推荐
- 44.drf缓存
DRF原有缓存 Django缓存.配置:https://www.cnblogs.com/Mickey-7/p/15792083.html Django为基于类的视图提供了一个 method_dec ...
- nginx.conf指令注释
nginx.conf指令注释 ######Nginx配置文件nginx.conf中文详解##### #定义Nginx运行的用户和用户组 user www www; #nginx进程数,建议设置为等于C ...
- PMM实现监控Mysql-MGR
一.docker安装PMM服务端 1.安装yum配置单元 # 如果已安装,略过此步 yum install -y yum-utils #yum配置单元 2.配置docker阿里云yum源 #配置doc ...
- Windows骚操作
电脑常用的快捷键 键盘功能健:Tab.Shift.Ctrl.Alt.Windows.Enter.空格.上下左右健.CapsLock(大小写转换).NumLock(对小键盘控制开/关) 键盘快捷键:全选 ...
- 远程桌面报错credssp
远程桌面连接的时候有时出现"出现身份验证错误.要求的函数不受支持:这可能是由于CredSSP 加密 Oracle 修正"的提示, 针对这种情况有以下两种版本的操作系统解决方案: w ...
- Redis系列11:内存淘汰策略
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 Redis系列3:高可用之主从架构 Redis系列4:高可用之Sentinel(哨兵模式) Redis系列5: ...
- nginx压力测试及限速
测试工具:Apache ab windows安装教程:https://www.cnblogs.com/laijinquan/p/14694655.html 64位下载地址:https://www.ap ...
- 论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》
论文信息 论文标题:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation论文作者:Tongkun Xu, Weihu ...
- 线上服务异常的定位、处理与优化的探索 - 第三章 Java虚拟机
Java虚拟机 之所以引入关于JVM的篇章,是发现多数项目发生的线上问题很大的几率源自JVM调优配置不当引起.对JVM的内存模型.GC垃圾回收机制.调优方式有一个系统化的了解后,可以快速处理或避免 ...
- Java手写一个批量获取数据工具类
1. 背景 偶尔会在公司的项目里看到这样的代码 List<Info> infoList = new ArrayList<Info>(); if (infoidList.size ...