Flink WordCount入门
下面通过一个单词统计的案例,快速上手应用 Flink,进行流处理(Streaming)和批处理(Batch)
单词统计(批处理)
- 引入依赖
<!--flink核心包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.2</version>
</dependency>
<!--flink流处理包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.7.2</version>
</dependency>
- 代码实现
public class WordCountBatch {
public static void main(String[] args) throws Exception {
String inputFile= "E:\\data\\word.txt";
String outPutFile= "E:\\data\\wordResult.txt";
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
//1. 读取数据
DataSource<String> dataSource = executionEnvironment.readTextFile(inputFile);
//2. 对数据进行处理,转成word,1的格式
FlatMapOperator<String, Tuple2<String, Integer>> flatMapOperator = dataSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
});
//3. 对数据分组,相同word的一个组
UnsortedGrouping<Tuple2<String, Integer>> tuple2UnsortedGrouping = flatMapOperator.groupBy(0);
//4. 对分组后的数据求和
AggregateOperator<Tuple2<String, Integer>> sum = tuple2UnsortedGrouping.sum(1);
//5. 写出数据
sum.writeAsCsv(outPutFile).setParallelism(1);
//执行
executionEnvironment.execute("wordcount batch process");
}
}
执行 main 方法,得出结果。我测试的 word.txt 内容如下:
ni hao hi
wang mei mei
liu mei
ni hao
wo hen hao
this is a good idea
Apache Flink
输出的文件结果:
a,1
mei,3
Apache,1
Flink,1
good,1
hen,1
hi,1
idea,1
ni,2
is,1
liu,1
this,1
wo,1
hao,3
wang,1
单词统计(流数据)
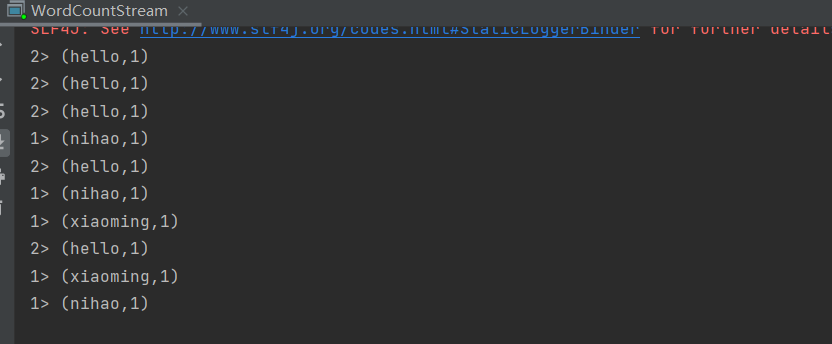
需求:Socket 模拟实时发送单词,使用 Flink 实时接收数据,对指定时间窗口内(如 5s)的数据进行聚合统计,每隔 1s 汇总计算一次,并且把时间窗口内计算结果打印出来
public class WordCountStream {
public static void main(String[] args) throws Exception {
int port = 7000;
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> textStream = executionEnvironment.socketTextStream("192.168.56.103", port, "\n");
SingleOutputStreamOperator<Tuple2<String, Integer>> tuple2SingleOutputStreamOperator = textStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = s.split("\\s");
for (String word : split) {
collector.collect(Tuple2.of(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> word = tuple2SingleOutputStreamOperator.keyBy(0)
.timeWindow(Time.seconds(5),Time.seconds(1)).sum(1);
word.print();
executionEnvironment.execute("wordcount stream process");
}
}
运行起来之后,我们就可以开始发送 socket 请求过去。我们测试可以使用 netcat 工具。
在 linux 上安装好后,使用下面的命令:
nc -lk 7000
然后发送数据即可。

Flink WordCount入门的更多相关文章
- [转帖]Flink(一)Flink的入门简介
Flink(一)Flink的入门简介 https://www.cnblogs.com/frankdeng/p/9400622.html 一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的 ...
- Flink从入门到放弃(入门篇2)-本地环境搭建&构建第一个Flink应用
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到放弃(入门篇3)-DataSetAPI
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到放弃(入门篇1)-Flink是什么
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到放弃(入门篇4) DataStreamAPI
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到精通系列文章
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink快速入门--安装与示例运行
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行. 首先要想运行Flin ...
- 「Flink」使用Java lambda表达式实现Flink WordCount
本篇我们将使用Java语言来实现Flink的单词统计. 代码开发 环境准备 导入Flink 1.9 pom依赖 <dependencies> <dependency> < ...
- Flink(一)Flink的入门简介
一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河 ...
随机推荐
- Linux 的常用基本命令
一.Linux 的常用基本命令..................................................................................... ...
- Redis 定长队列的探索和实践
vivo 互联网服务器团队 - Wang Zhi 一.业务背景 从技术的角度来说,技术方案的选型都是受限于实际的业务场景,都以解决实际业务场景为目标. 在我们的实际业务场景中,需要以游戏的维度收集和上 ...
- Java Script的认识
JavaScript的诞生 1.Java Script诞生于1995年.由Netscape(网景公司)的程序员Brendan Eich(布兰登)与Sun公司联手开发一门脚本语言, 最初名字叫做Mo ...
- 基于 .NET 6 的轻量级 Webapi 框架 FastEndpoints
大家好,我是等天黑. FastEndpoints 是一个基于 .NET 6 开发的开源 webapi 框架,它可以很好地替代 .NET Minimal APIs 和 MVC ,专门为开发效率而生,带来 ...
- 痞子衡嵌入式:在i.MXRT启动头FDCB里使能串行NOR Flash的QPI/OPI模式
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是在FDCB里使能串行NOR Flash的QPI/OPI模式. 我们知道 Flash 读时序里有五大子序列 CMD + ADDR + MO ...
- MyBatis快速上手与知识点总结
目录 1.MyBatis概述 1.1 MyBatis概述 1.2 JDBC缺点 1.3 MyBatis优化 2.MyBatis快速入门 3.Mapper代理开发 3.1 Mapper代理开发概述 3. ...
- NetCore性能优化
NetCore性能优化2.非跟踪查询在只读方案中使用结果时,非跟踪查询十分有用,可以更快速地执行.增加AsNoTracking()表示非跟踪,如:var users = context.User.As ...
- django_day02
django_day02 外键 表示一对多 多对一 class Book(models.Model): name = models.CharField(max_length=32) publisher ...
- 监控linux多个cpu的负载情况
监控linux多个cpu的负载情况 top然后按数字键1
- Windows Powershell安装错误
今天需要更新一下VMware的 powercli.使用命令install-module -Name VMware.PowerCLI -AllowClobber但是遇到一个错误. Unable to r ...