ElasticSearch5.5.2常用命令
1、启动
转到elasticsearch-5.5.2\bin目录:
打开命令行输入:elasticsearch
2、ELasticsearch集群已经启动并且正常运行
curl http://127.0.0.1:9200/?pretty
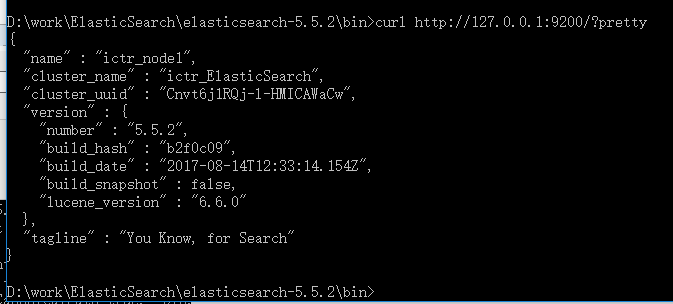
这说明你的ELasticsearch集群已经启动并且正常运行,接下来我们可以开始各种实验了。
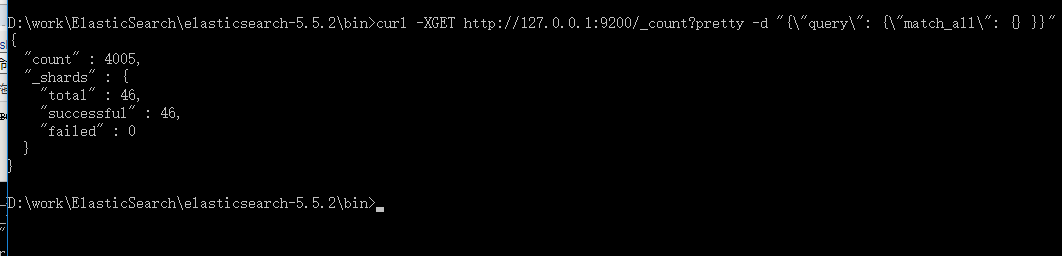
3、计算集群中的文档数量
curl -XGET http://127.0.0.1:9200/_count?pretty -d "{\"query\": {\"match_all\": {} }}"
我们看不到HTTP头是因为我们没有让curl显示它们,如果要显示,使用curl命令后跟-i参数:
curl -i -XGET localhost:9200/

4、查看集群健康状况
GET /_cat/health?v
curl -XGET http://127.0.0.1:9200/_cat/health?v


5、查看my_index的mapping和setting的相关信息
GET /index_china?pretty
curl -XGET http://127.0.0.1:9200/index_china?pretty


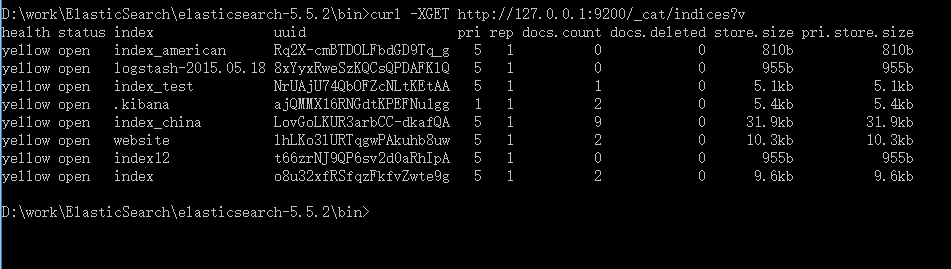
6、查看所有的index
GET /_cat/indices?v
curl -XGET http://127.0.0.1:9200/_cat/indices?v

7、空查询
GET /_search
8、分页搜索
GET /_search?from=0&size=5 从0页开始搜索,每页大小是5个记录
GET /_search?from=1&size=5 从1页开始搜索,每页大小是5个记录
POST /_search // 从1页开始搜索,每页大小是5个记录,和上面的效果一样
{
"from": 1,
"size": 5
}
9、range查询
range 查询找出那些落在指定区间内的数字或者时间:
被允许的操作符如下:
gt:大于
gte:大于等于
lt:小于-
lte:小于等于
GET /index_china/fulltext/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lt": 50
}
}
}
}
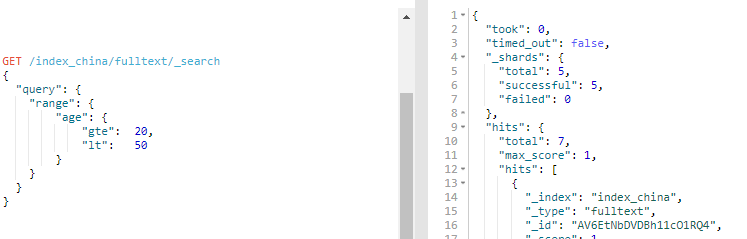
10、组合查询
现实的查询需求从来都没有那么简单;它们需要在多个字段上查询多种多样的文本,并且根据一系列的标准来过滤。为了构建类似的高级查询,你需要一种能够将多查询组合成单一查询的查询方法。
你可以用 bool 查询来实现你的需求。这种查询将多查询组合在一起,成为用户自己想要的布尔查询。它接收以下参数:
must:文档 必须 匹配这些条件才能被包含进来。must_not:文档 必须不 匹配这些条件才能被包含进来。should:如果满足这些语句中的任意语句,将增加_score,否则,无任何影响。它们主要用于修正每个文档的相关性得分。filter:必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
GET /index_china/fulltext/_search
{
"query": {
"bool": {
"must": { "match": { "name": "小张" }},
"must_not": { "match": { "age": }} }
}
}
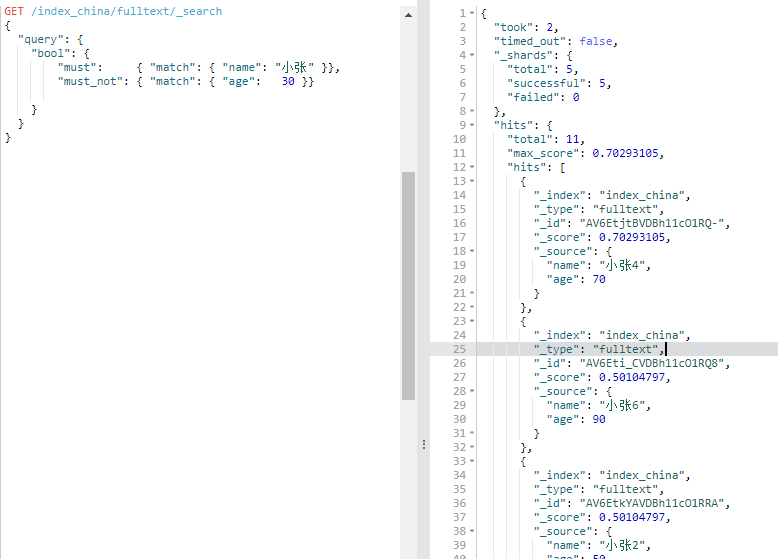
11、带过滤器的查询
GET /index_china/fulltext/_search
{
"query": {
"bool": {
"must": { "match": { "name": "小张" }},
"must_not": { "match": { "age": }},
"filter": {
"range": { "age": { "gte": "" }}
} }
}
}

通过将 range 查询移到 filter 语句中,我们将它转成不评分的查询,将不再影响文档的相关性排名。由于它现在是一个不评分的查询,可以使用各种对 filter 查询有效的优化手段来提升性能。
所有查询都可以借鉴这种方式。将查询移到 bool 查询的 filter 语句中,这样它就自动的转成一个不评分的 filter 了。
如果你需要通过多个不同的标准来过滤你的文档,bool 查询本身也可以被用做不评分的查询。简单地将它放置到 filter 语句中并在内部构建布尔逻辑:
GET /index_china/fulltext/_search
{
"query": {
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}
}
}
12、验证查询
查询可以变得非常的复杂,尤其 和不同的分析器与不同的字段映射结合时,理解起来就有点困难了。不过 validate-query API 可以用来验证查询是否合法。
GET /index_china/fulltext/_validate/query
{
"query": {
"fulltext" : {
"match" : "really powerful"
}
}
}

说明以上 validate 请求的应答告诉我们这个查询是不合法的
理解错误信息
GET /index_china/fulltext/_validate/query?explain
{
"query": {
"fulltext" : {
"match" : "really powerful"
}
}
}
explain参数可以提供更多关于查询不合法的信息

很明显,我们将查询类型(match)与字段名称 (fulltext)搞混了:
理解查询语句
对于合法查询,使用 explain 参数将返回可读的描述,这对准确理解 Elasticsearch 是如何解析你的 query 是非常有用的
GET /_validate/query?explain
{
"query": {
"match" : {
"fulltext" : "really powerful"
}
}
}
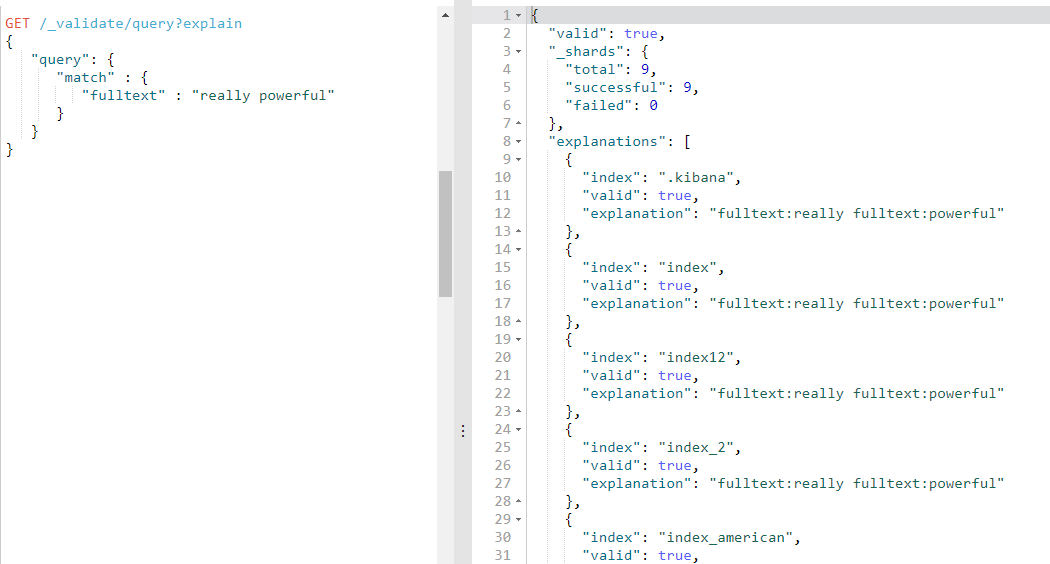
我们查询的每一个 index 都会返回对应的 explanation ,因为每一个 index 都有自己的映射和分析器:
13、删除索引
用以下的请求来 删除索引:
DELETE /my_index
你也可以这样删除多个索引:
DELETE /index_one,index_two
DELETE /index_*
你甚至可以这样删除 全部 索引:
DELETE /_all
DELETE /*
对一些人来说,能够用单个命令来删除所有数据可能会导致可怕的后果。如果你想要避免意外的大量删除, 你可以在你的 elasticsearch.yml 做如下配置:
action.destructive_requires_name: true
这个设置使删除只限于特定名称指向的数据, 而不允许通过指定 _all 或通配符来删除指定索引库。你同样可以通过 Cluster State API 动态的更新这个设置。
14、只查询部分字段
在一个搜索请求里,你可以通过在请求体中指定 _source 参数,来达到只获取特定的字段的效果:
查询所有字段


GET /ott_test/ott_type/_search
{
"query": {"match_all": {}}
} #只查询title和date两个字段的数据 GET /ott_test/ott_type/_search
{
"query": {"match_all": {}},
"_source": ["title","date"]
}
15、修改密码
假设用户名:ctr,密码elastic1, 登录后修改如下
POST _xpack/security/user/ctr/_password
{
"password": "elastic"
}

16、其它命令
集群健康:GET _cluster/health
监控单个节点:GET _nodes/stats
集群统计:GET _cluster/stats
索引统计:GET ott_test/_stats;GET ott_test,ott/_stats;GET _all/_stats
xpack模块命令:GET /_xpack

ElasticSearch5.5.2常用命令的更多相关文章
- Linux 常用命令(持续补充)
常用命令: command &:将进程放在后台执行 ctrl + z:暂停当前进程 并放入后台 jobs:查看当前后台任务 bg( %id):将任务转为后台执行 fg( %id):将任务调回前 ...
- LVM基本介绍与常用命令
一.LVM介绍LVM是 Logical Volume Manager(逻辑卷管理)的简写,它是Linux环境下对磁盘分区进行管理的一种机制LVM - 优点:LVM通常用于装备大量磁盘的系统,但它同样适 ...
- Linux学习笔记(一):常用命令
经过统计Linux中能够识别的命令超过3000种,当然常用的命令就远远没有这么多了,按照我的习惯,我把已经学过的Linux常用命令做了以下几个方面的分割: 1.文件处理命令 2.文件搜索命令 3.帮助 ...
- git常用命令(持续更新中)
git常用命令(持续更新中) 本地仓库操作git int 初始化本地仓库git add . ...
- 【原】npm 常用命令详解
今年上半年在学习gulp的使用,对npm的掌握是必不可少的,经常到npm官网查询文档让我感到不爽,还不如整理了一些常用的命令到自己博客上,于是根据自己的理解简单翻译过来,终于有点输出,想学习npm这块 ...
- npm常用命令
npm常用命令 环境:win7 npm 是什么 NPM(node package manager),通常称为node包管理器.顾名思义,它的主要功能就是管理node包,包括:安装.卸载.更新.查看.搜 ...
- Git 常用命令
一.初始環境配置 git config --global user.name "John Doe"git config --global user.email johndoe@ex ...
- linux iptables常用命令之配置生产环境iptables及优化
在了解iptables的详细原理之前,我们先来看下如何使用iptables,以终为始,有可能会让你对iptables了解更深 所以接下来我们以配置一个生产环境下的iptables为例来讲讲它的常用命令 ...
- Linux常用命令(一)
Linux常用命令 1. pwd查看当前路径(Print Working Directory) [root@CentOS ~]# pwd/root 2. cd .. 返回上一级 .. 表示上一级 ...
随机推荐
- POJ 3041 Asteroids | 匈牙利算法模板
emmmmm 让你敲个匈牙利 #include<cstdio> #include<algorithm> #include<cstring> #define N 51 ...
- java的struts2整理
readbook:struts2 先说一下struts1: struts1使用model II 模式开发,即jsp+java bean+servlet 再说它的缺陷: 1.表现层支持 ...
- JAVA中GC时finalize()方法是不是一定会被执行?
在回答上面问题之前,我们一定要了解JVM在进行垃圾回收时的机制,首先: 一.可达性算法 要知道对象什么时候死亡,我们需要先知道JVM的GC是如何判断对象是可以回收的.JAVA是通过可达性算法来来判断 ...
- 转 linux下cat命令详解
linux下cat命令详解 http://www.cnblogs.com/perfy/archive/2012/07/23/2605550.html 简略版: cat主要有三大功能:1.一次显示整个文 ...
- Sqlite插入、修改、删除表里面的数据
转载 2014年05月10日 10:38:21 标签: sqlite3 / 数据库 8688 转自:http://www.cnblogs.com/myqiao/archive/2011/07/13/2 ...
- C++ MFC std::string转为 std::wstring
std::string转为 std::wstring std::wstring UTF8_To_UTF16(const std::string& source) { unsigned long ...
- Linux中断(interrupt)子系统之五:软件中断(softIRQ)【转】
转自:http://blog.csdn.net/droidphone/article/details/7518428 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 软件中 ...
- JavaWeb响应下载(包含工具类)
纸上得来终觉浅,绝知此事要躬行!今天博主分享是关于javaweb的响应(response)下载 以下是我的Demo: 页面我就粘主要部分的代码 <a href = "${pageCon ...
- sql多对多探讨
--用sql语句探讨一对多 多对多关系 /**** 你有3个表 学生表(学生id 学生姓名) 课程表(课程id 课程名) 成绩表 (学生id 课程id 分数) 班级表(班级id 学生id) 这里的班 ...
- 顺序栈操作--数据结构(C++)版
最近学习数据结构,一开始接触感觉好难,颓废了一段时间,后来又重新翻开学习,突然感觉到很大的兴趣.对这些代码的运用都有了 一些新的认识.下面简单的讲述下最新学到的顺序栈,不知道大家学习的时候会不会有感觉 ...