用Python写一个小爬虫吧!
学习了一段时间的web前端,感觉有点看不清前进的方向,于是就写了一个小爬虫,爬了51job上前端相关的岗位,看看招聘方对技术方面的需求,再有针对性的学习。
我在此之前接触过Python,也写过一些小脚本,于是决定用Python来完成这个小项目。
首先说说一个爬虫的组成部分:
1.目标连接,就是我需要爬取信息的网页的链接;
2.目标信息,就是网页上我需要抓取的信息;
3.信息梳理,就是对爬取的信息进行整理。
下面我来说说整个爬虫的设计思路:
总体思路:以“前端”关键字进行搜索,把搜索结果上面每一个招聘信息的链接爬取下来,再通过这些招聘职位的链接去抓取相应页面上的具体要求。
1.先在51job上以“前端”为关键字进行搜索,从搜索结果来看,跟我的目标职位相似度还是很高的,所以用“前端”作为关键字是没问题的。
2.获取搜索结果的链接,通过比较1,2两页的链接,发现只有一个数字的差别,所以我可以直接更改这个数字来获取每一页的链接
3.在搜索结果页面按F12可以看到网页结构,按下左上角的鼠标按钮,再去点网页上的元素,网页结构会自动展现相应的标签
4.按下左上角的鼠标按钮,再去点招聘信息的岗位链接,可以在网页结构中看到,我们需要的每一个岗位的具体链接是放在一个a标签里面的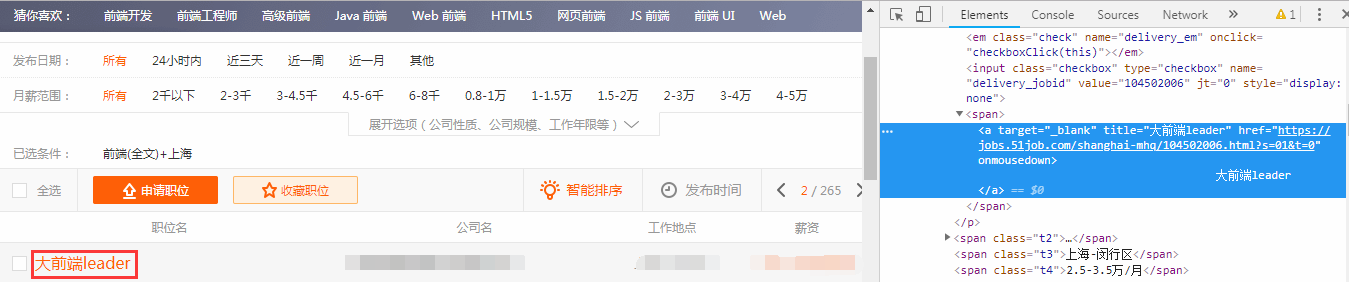
5.再点进这个职位的详情页面,按F12查看网页结构,再按左上角鼠标按钮,之后点击网页上的职位信息,我发现职位信息都是放在一个div标签里面,这个div有一个样式类属性class="bmsg job_msg inbox",具体的信息是放在这个div下的p标签中,我查看了其他几个招聘页面,也是相同的结构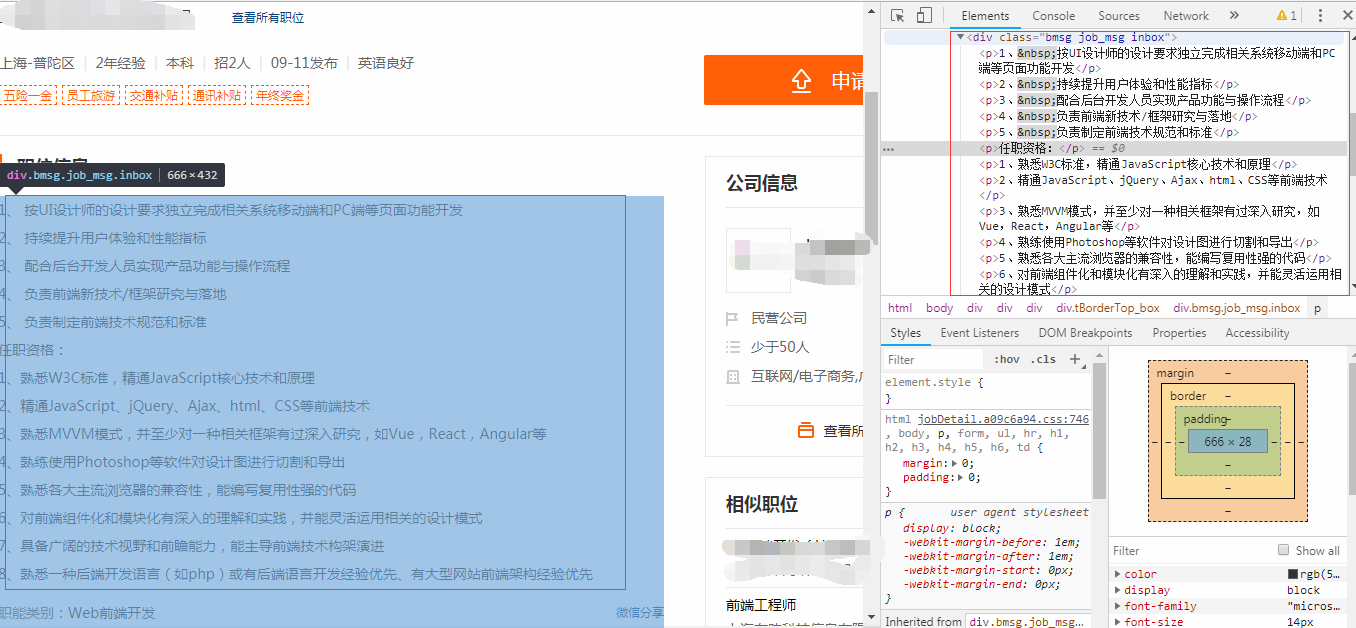
所以我的爬虫要先爬取搜索结果页面中的职位链接,再进到相应的链接爬取div标签下p标签的内容,最后对这些内容做一个词频分析。
为了简化这个小项目的结构,我决定把这3个任务分成3个小脚本来执行。
首先是爬取搜索结果页面中的职位链接。代码如下
#爬取职位链接这一步用到了3个库
import requests
from bs4 import BeautifulSoup
import chardet f = open('info.txt', 'a') # f是我存储爬取信息的文本文件,使用追加模式,就是说后面写入的信息会放在已有的信息后面,这样就不会把之前的信息覆盖掉
url = 'https://search.51job.com/list/020000,000000,0000,00,9,99,%25E5%2589%258D%25E7%25AB%25AF,2,{}.html?' \
'lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&' \
'lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=4&dibiaoid=0&address=&line=&' \
'specialarea=00&from=&welfare=#top' # url里面关乎页面跳转的数字我用{}占位,后面可以通过format函数动态替换
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 '
'Safari/537.36',
'Connection': 'keep-alive',
}# header是为了把爬虫伪装的像是正常的访问。 #for循环结构,循环10次,也就是说爬取10页上面的职位链接
for i in range(11):
# 用requests库的get方法与服务器进行链接,返回一个requests.models.Response的类
pageConnect = requests.get(url.format(i), headers=header)
#用chardet库的detect方法获取网页编码格式,返回的是dict字典,具体的编码格式在encoding这个键对应的值中
pageConnect.encoding = chardet.detect(pageConnect.content)['encoding']
#设置好编码格式后,用text方法把Response这个类转化为字符串供beautifulSoup处理
page = pageConnect.text
#使用BeautifulSoup函数把page字符串转化为一个BeautifulSoup对象,lxml是解析器的类型
soup = BeautifulSoup(page, 'lxml')
#使用BeautifulSoup对象的select方法,可以用css选择器把存放有职位链接的a标签选出来
#每一个a标签都是放在class=el的div标签下class=t1的p标签下
aLabel = soup.select('div.el > p.t1 a')
#每一个搜索结果页有50个职位,也就有50个a标签,通过for循环,获取每个a标签的title属性,href属性
#title属性存放了职位名称,我可以通过职位名称把不是我需要的职位链接筛选出去
#href属性存放了每一个职位的链接
for each in aLabel:
#把这些信息存放到f也就是info.txt这个文本中
print(each['title'], each['href'], file=f)
接着要做的就是爬取每一个链接页面上的职位要求了
代码如下
import requests
from bs4 import BeautifulSoup
import chardet #打开我存放链接的文本,使用readlines方法读取文本内容,返回的是一个list列表,每一行为列表中的一项
with open('info.txt') as info:
link = info.readlines()
#打开一个文本文件,存放抓取到的职位要求,编码格式设为utf-8
job = open('job.txt', 'a', encoding='UTF-8')
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 '
'Safari/537.36',
'Connection': 'keep-alive',
} for each in link:
#info.txt中存放的信息是职位名 + 链接:Web前端开发工程师 https://*****
#所以先对列表中的每一项,也就是说一个字符串调用find方法,搜索关键字http,返回的是一个整数,表示的是字符串中http开头h的索引值
index = each.find('http')
#利用这个索引值,可以获取字符串中链接的部分
url = each[index:]
pageConnect = requests.get(url, headers=header)
pageConnect.encoding = chardet.detect(pageConnect.content)['encoding']
page = pageConnect.text
soup = BeautifulSoup(page, 'lxml')
#所有的职位要求是放在一个div中,它的样式类为class=bmsg job_msg inbox,div中的p标签包含具体的信息,返回的是一个list列表
div = soup.select('div.bmsg.job_msg.inbox p')
#经过测试发现,最后2个p标签存放着关键字,所以去掉
jobInfo = div[:-2]
for eachInfo in jobInfo:
#每个列表项存放着如<p>***</P>的bs4.element.Tag,要获取其中文字部分,要使用.string方法
print(eachInfo.string, file=job)
最后job.txt中存放着我抓取到的所有职位要求,但是我不可能一条一条的去看,所以借助jieba这个库进行分词
import jieba
with open('job.txt', encoding='utf-8') as job:
info = job.readlines()
for eachLine in info:
for eachWord in jieba.cut(eachLine):
print(eachWord)
为了节省时间,分词结果直接打印出来,然后复制到excel表中,使用数据透视表统计一下,最后整理结果如下
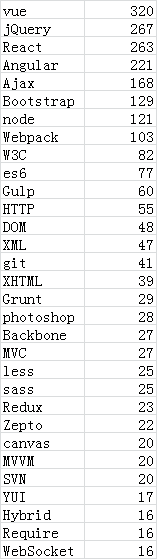
这是一个非常简陋的小项目,不过它也实现了我的目标。
用Python写一个小爬虫吧!的更多相关文章
- Python之小测试:用正则表达式写一个小爬虫用于保存贴吧里的所有图片
很简单的两步: 1.获取网页源代码 2.利用正则表达式提取出图片地址 3.下载 #!/usr/bin/python #coding=utf8 import re # 正则表达式 import urll ...
- Python编程-一个小爬虫工具的实现过程
需求描述: 1,打开网站: 2,获取网站的文件内容: 3,返回保存到文件中: 这里的就用到了多线程的方法 import requests,threading,time def write_html(u ...
- 十行代码--用python写一个USB病毒 (知乎 DeepWeaver)
昨天在上厕所的时候突发奇想,当你把usb插进去的时候,能不能自动执行usb上的程序.查了一下,发现只有windows上可以,具体的大家也可以搜索(搜索关键词usb autorun)到.但是,如果我想, ...
- Python写一个自动点餐程序
Python写一个自动点餐程序 为什么要写这个 公司现在用meican作为点餐渠道,每天规定的时间是早7:00-9:40点餐,有时候我经常容易忘记,或者是在地铁/公交上没办法点餐,所以总是没饭吃,只有 ...
- 用Python写一个简单的Web框架
一.概述 二.从demo_app开始 三.WSGI中的application 四.区分URL 五.重构 1.正则匹配URL 2.DRY 3.抽象出框架 六.参考 一.概述 在Python中,WSGI( ...
- [py]python写一个通讯录step by step V3.0
python写一个通讯录step by step V3.0 参考: http://blog.51cto.com/lovelace/1631831 更新功能: 数据库进行数据存入和读取操作 字典配合函数 ...
- 【Python】如何基于Python写一个TCP反向连接后门
首发安全客 如何基于Python写一个TCP反向连接后门 https://www.anquanke.com/post/id/92401 0x0 介绍 在Linux系统做未授权测试,我们须准备一个安全的 ...
- 用python写一个自动化盲注脚本
前言 当我们进行SQL注入攻击时,当发现无法进行union注入或者报错等注入,那么,就需要考虑盲注了,当我们进行盲注时,需要通过页面的反馈(布尔盲注)或者相应时间(时间盲注),来一个字符一个字符的进行 ...
- python写一个能变身电光耗子的贪吃蛇
python写一个不同的贪吃蛇 写这篇文章是因为最近课太多,没有精力去挖洞,记录一下学习中的收获,python那么好玩就写一个大一没有完成的贪吃蛇(主要还是跟课程有关o(╥﹏╥)o,课太多好烦) 第一 ...
随机推荐
- [Xcode 实际操作]七、文件与数据-(16)解析XML文档
目录:[Swift]Xcode实际操作 本文将演示如何解析XML文档. 项目中已添加一份XML文档:worker.xml <?xml version="1.0" encodi ...
- J - 吉哥系列故事――恨7不成妻
#include "cstdio" #include "math.h" #include "cstring" #define mod 100 ...
- [筆記]catalan卡特蘭數
前言:希望自己每個星期能發一篇文章,提升一下寫文章的能力?雖然對語文作文毫無幫助但是總比玩遊戲強 所以不務正業的東西就不放在首頁了,有興趣的可以點分類去看 來源:https://www.cnblogs ...
- iphone、ipad等网页中电话号码呈蓝色的解决方案
iPhone手机.ipad上的浏览器(如Safari),在解析网页的时候会自动给 像是电话号码的数字 加上link样式,所以号码呈蓝色. 可以添加下面的meta禁用掉这个功能. <meta na ...
- Codeforces 1142E(图、交互)
题目传送 官方题解说的很好了,剩下的就是读大佬代码了,前面是tarjan求SCC缩点图.我图论没学过,接下来删点是怎么操作看得有点头秃,直到我看到了%%%安德鲁何神仙的代码. 按照题面连通紫线以后,我 ...
- I/O————File对象
File文件对象 文件和文件夹都是用File代表 创建一个文件对象,(并不会有真正的文件或文件夹被创建) File f1 = new File("d:/lolfilder"); S ...
- phpmyadmin解决“高级功能尚未完全设置,部分功能未激活”
首先在点击主页中的导入, 在“从计算机中上传:”选择/usr/share/doc/phpmyadmin/examples的“create_tables.sql.gz”文件 点击执行 但是我的电脑上还是 ...
- GCD 使用说明
GCD提供的一些操作队列的方法 名称 说明 dispatch_set_target_queue 将多个队列添加到目标队列中 dispatch_group 将多个队列放入组中,监听所有任务完成状 dis ...
- Azure Powershell blob中指定的vhd创建虚拟机
#此脚本用于 Azure 存储账户中已有 vhd 镜像文件创建虚拟机,一般用于做好镜像测试 #----------------------------------------------------- ...
- moment算本月开始日期和结束日期
moment算本月开始日期和结束日期 1.引入moment.js var vStartDate=new moment().add('month',addMonth).format("YYYY ...