基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)
基于深度学习和迁移学习的识花实践(转)
深度学习是人工智能领域近年来最火热的话题之一,但是对于个人来说,以往想要玩转深度学习除了要具备高超的编程技巧,还需要有海量的数据和强劲的硬件。不过 TensorFlow 和 Keras 等框架的出现大大降低了编程的复杂度,而迁移学习的思想也允许我们利用现有的模型加上少量数据和训练时间,取得不俗的效果。
这篇文章将示范如何利用迁移学习训练一个能从图片中分类不同种类的花的模型,它在五种花中能达到 80% 以上的准确度(比瞎蒙高了 60% 哦),而且只需要普通的家用电脑就可以完成训练过程。

什么是迁移学习
人类的思维可以将一个领域学习到的知识和经验,应用到其他相似的领域中去。所以当面临新的情景时,如果该情景与之前的经验越相似,那么人就能越快掌握该领域的知识。而传统的机器学习方法则会把不同的任务看成是完全独立的,比如一个识别猫的模型,如果训练集中的图片都是白天的,那么训练出来的模型对于识别夜晚的猫这个任务就可能表现得非常差。迁移学习便是受此启发,试图将模型从源任务上训练到的知识迁移到目标任务的应用上。
举例说,源任务可以是识别图片中车辆,而目标任务可以是识别卡车,识别轿车,识别公交车等。合理的使用迁移学习可以避免针对每个目标任务单独训练模型,从而极大的节约了计算资源。

此外,迁移学习并不是一种特定的机器学习模型,它更像是一种优化技巧。通常来说,机器学习任务要求测试集和训练集有相同的概率分布,然而在一些情况下往往会缺乏足够大的有针对性的数据集来满足一个特定的训练任务。迁移学习提出我们可以在一个通用的大数据集上进行一定量的训练后,再用针对性的小数据集进一步强化训练。
接下来的例子中将示范如何将一个图像识别的深度卷积网络,VGG,迁移到识别花朵类型的新任务上,在原先的任务中,VGG 只能识别花,但是迁移学习可以让模型不但能识别花,还能识别花的具体品种。
VGG 介绍
VGG 是视觉领域竞赛 ILSVRC 在 2014 年的获胜模型,以 7.3% 的错误率在 ImageNet 数据集上大幅刷新了前一年 11.7% 的世界纪录。VGG16 基本上继承了 AlexNet 深的思想,并且发扬光大,做到了更深。AlexNet 只用到了 8 层网络,而 VGG 的两个版本分别是 16 层网络版和 19 层网络版。在接下来的迁移学习实践中,我们会采用稍微简单的一些的 VGG16,他和 VGG19 有几乎完全一样的准确度,但是运算起来更快一些。
VGG 的结构图如下:
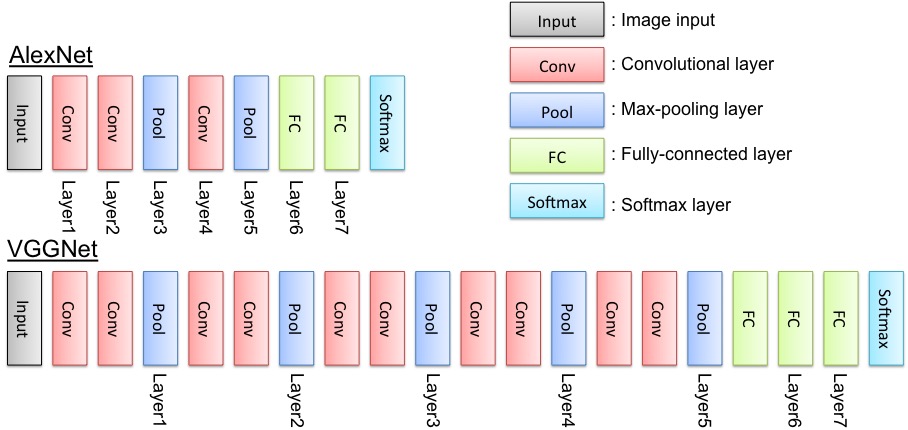
VGG 的输入数据格式是 244 * 224 * 3 的像素数据,经过一系列的卷积神经网络和池化网络处理之后,输出的是一个 4096 维的特征数据,然后再通过 3 层全连接的神经网络处理,最终由 softmax 规范化得到分类结果。

VGG16 模型可以通过这里下载(密码 78g9),模型是一个. npy 文件,本质上是一个巨大的 numpy 对象,包含了 VGG16 模型中的所有参数,该文件大约有 500M,所以可见如果是从头训练这样一个模型是非常耗时的,借助于迁移学习的思想,我们可以直接在这个模型的基础上进行训练。
识花数据集
我们要使用的花数据集可以在这里下载。
该数据集有包含如下数据:
| 花的种类 | 图片数量(张) |
|---|---|
| daisy | 633 |
| dandelion | 898 |
| roses | 641 |
| sunflowers | 699 |
| tulips | 799 |
迁移学习实践
有了预备知识之后,我们可以开始搭建属于自己的识花网络了。
首先我们会将所有的图片交给 VGG16,利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练。
因此本质上,我们是将 VGG16 作为一个图片特征提取器,然后在此基础上再进行一次普通的神经网络学习,这样就将原先的 244 * 224 * 3 维度的数据转化为了 4096 维的,而每一维度的信息量大大提高,从而大大降低了计算资源的消耗,实现了把学习物体识别中得到的知识应用到特殊的花朵分类问题上。
文件结构
为了更加方便的使用 VGG 网络,我们可以直接使用 tensorflow 提供的 VGG 加载模块,该模块可以在这里下载。
首先保证代码或者 jupyter notebook 运行的工作目录下有 flowerphotos,tensorflowvgg 这两个文件夹,分别是花朵数据集和 tensorflowvgg,然后将之前下载的 VGG16 拷贝到 tensorflowvgg 文件夹中。
├── transfer_learning.py(运行代码)
├── flower_phtots
│ ├── daisy
│ ├── dandelion
│ ├── roses
│ └── ...
└── tensorflow_vgg
├── vgg16.py
├── vgg16.npy
└── ...
然后导入需要用的 python 模块
import os
import numpy as np
import tensorflow as tf
from tensorflow_vgg import vgg16
from tensorflow_vgg import utils
加载识花数据集
接下来我们将 flower_photos 文件夹中的花朵图片都载入到进来,并且用图片所在的子文件夹作为标签值。
data_dir = 'flower_photos/'
contents = os.listdir(data_dir)
classes = [each for each in contents if os.path.isdir(data_dir + each)]
利用 VGG16 计算得到特征值
# 首先设置计算batch的值,如果运算平台的内存越大,这个值可以设置得越高
batch_size = 10
# 用codes_list来存储特征值
codes_list = []
# 用labels来存储花的类别
labels = []
# batch数组用来临时存储图片数据
batch = []
codes = None
with tf.Session() as sess:
# 构建VGG16模型对象
vgg = vgg16.Vgg16()
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
with tf.name_scope("content_vgg"):
# 载入VGG16模型
vgg.build(input_)
# 对每个不同种类的花分别用VGG16计算特征值
for each in classes:
print("Starting {} images".format(each))
class_path = data_dir + each
files = os.listdir(class_path)
for ii, file in enumerate(files, 1):
# 载入图片并放入batch数组中
img = utils.load_image(os.path.join(class_path, file))
batch.append(img.reshape((1, 224, 224, 3)))
labels.append(each)
# 如果图片数量到了batch_size则开始具体的运算
if ii % batch_size == 0 or ii == len(files):
images = np.concatenate(batch)
feed_dict = {input_: images}
# 计算特征值
codes_batch = sess.run(vgg.relu6, feed_dict=feed_dict)
# 将结果放入到codes数组中
if codes is None:
codes = codes_batch
else:
codes = np.concatenate((codes, codes_batch))
# 清空数组准备下一个batch的计算
batch = []
print('{} images processed'.format(ii))
这样我们就可以得到一个 codes 数组,和一个 labels 数组,分别存储了所有花朵的特征值和类别。
可以用如下的代码将这两个数组保存到硬盘上:
with open('codes', 'w') as f:
codes.tofile(f)
import csv
with open('labels', 'w') as f:
writer = csv.writer(f, delimiter='\n')
writer.writerow(labels)
准备训练集,验证集和测试集
一次严谨的模型训练一定是要包含验证和测试这两个部分的。首先我把 labels 数组中的分类标签用 One Hot Encode 的方式替换。
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
lb.fit(labels)
labels_vecs = lb.transform(labels)
接下来就是抽取数据,因为不同类型的花的数据数量并不是完全一样的,而且 labels 数组中的数据也还没有被打乱,所以最合适的方法是使用 StratifiedShuffleSplit 方法来进行分层随机划分。假设我们使用训练集:验证集:测试集 = 8:1:1,那么代码如下:
from sklearn.model_selection import StratifiedShuffleSplit
ss = StratifiedShuffleSplit(n_splits=1, test_size=0.2)
train_idx, val_idx = next(ss.split(codes, labels))
half_val_len = int(len(val_idx)/2)
val_idx, test_idx = val_idx[:half_val_len], val_idx[half_val_len:]
train_x, train_y = codes[train_idx], labels_vecs[train_idx]
val_x, val_y = codes[val_idx], labels_vecs[val_idx]
test_x, test_y = codes[test_idx], labels_vecs[test_idx]
print("Train shapes (x, y):", train_x.shape, train_y.shape)
print("Validation shapes (x, y):", val_x.shape, val_y.shape)
print("Test shapes (x, y):", test_x.shape, test_y.shape)
这时如果我们输出数据的维度,应该会得到如下结果:
Train shapes (x, y): (2936, 4096) (2936, 5)
Validation shapes (x, y): (367, 4096) (367, 5)
Test shapes (x, y): (367, 4096) (367, 5)
训练网络
分好了数据集之后,就可以开始对数据集进行训练了,假设我们使用一个 256 维的全连接层,一个 5 维的全连接层(因为我们要分类五种不同类的花朵),和一个 softmax 层。当然,这里的网络结构可以任意修改,你可以不断尝试其他的结构以找到合适的结构。
# 输入数据的维度
inputs_ = tf.placeholder(tf.float32, shape=[None, codes.shape[1]])
# 标签数据的维度
labels_ = tf.placeholder(tf.int64, shape=[None, labels_vecs.shape[1]])
# 加入一个256维的全连接的层
fc = tf.contrib.layers.fully_connected(inputs_, 256)
# 加入一个5维的全连接层
logits = tf.contrib.layers.fully_connected(fc, labels_vecs.shape[1], activation_fn=None)
# 计算cross entropy值
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=labels_, logits=logits)
# 计算损失函数
cost = tf.reduce_mean(cross_entropy)
# 采用用得最广泛的AdamOptimizer优化器
optimizer = tf.train.AdamOptimizer().minimize(cost)
# 得到最后的预测分布
predicted = tf.nn.softmax(logits)
# 计算准确度
correct_pred = tf.equal(tf.argmax(predicted, 1), tf.argmax(labels_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
为了方便把数据分成一个个 batch 以降低内存的使用,还可以再用一个函数专门用来生成 batch。
def get_batches(x, y, n_batches=10):
""" 这是一个生成器函数,按照n_batches的大小将数据划分了小块 """
batch_size = len(x)//n_batches
for ii in range(0, n_batches*batch_size, batch_size):
# 如果不是最后一个batch,那么这个batch中应该有batch_size个数据
if ii != (n_batches-1)*batch_size:
X, Y = x[ii: ii+batch_size], y[ii: ii+batch_size]
# 否则的话,那剩余的不够batch_size的数据都凑入到一个batch中
else:
X, Y = x[ii:], y[ii:]
# 生成器语法,返回X和Y
yield X, Y
现在可以运行训练了,
# 运行多少轮次
epochs = 20
# 统计训练效果的频率
iteration = 0
# 保存模型的保存器
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for x, y in get_batches(train_x, train_y):
feed = {inputs_: x,
labels_: y}
# 训练模型
loss, _ = sess.run([cost, optimizer], feed_dict=feed)
print("Epoch: {}/{}".format(e+1, epochs),
"Iteration: {}".format(iteration),
"Training loss: {:.5f}".format(loss))
iteration += 1
if iteration % 5 == 0:
feed = {inputs_: val_x,
labels_: val_y}
val_acc = sess.run(accuracy, feed_dict=feed)
# 输出用验证机验证训练进度
print("Epoch: {}/{}".format(e, epochs),
"Iteration: {}".format(iteration),
"Validation Acc: {:.4f}".format(val_acc))
# 保存模型
saver.save(sess, "checkpoints/flowers.ckpt")
测试网络
接下来就是用测试集来测试模型效果
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
feed = {inputs_: test_x,
labels_: test_y}
test_acc = sess.run(accuracy, feed_dict=feed)
print("Test accuracy: {:.4f}".format(test_acc))
最终我在自己电脑上得到了 88.83% 的准确度,你可以继续调整 batch 的大小,或者模型的结构以得到一个更好的结果。
对这张有一个七星瓢虫的蒲公英图

模型给出的预测值如下

可以看出模型的效果还是相当稳定的,而且整个过程中我们的计算时间不过超过 30 分钟,这就是迁移学习的魅力。
P.S
当然,其他的深度学习框架也可以很方便的实现迁移学习,比如这里的 Keras 代码用大约 20 行实现了一个 VGG 迁移识别狗的品种的分类器。
参考资料
- A Survey on Transfer Learning[http://ieeexplore.ieee.org/document/5288526/]
- Tensorflow 的识花迁移学习 https://www.tensorflow.org/tutorials/image_retraining
- VGG 网络 https://arxiv.org/pdf/1409.1556.pdf
- 卷积神经网络的可视化 http://www.matthewzeiler.com/pubs/arxive2013/eccv2014.pdf
- Udaicty 深度学习 https://cn.udacity.com/course/deep-learning-nanodegree-foundation–nd101
基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)的更多相关文章
- 【深度学习篇】--神经网络中的池化层和CNN架构模型
一.前述 本文讲述池化层和经典神经网络中的架构模型. 二.池化Pooling 1.目标 降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)减少输 ...
- 学习笔记TF014:卷积层、激活函数、池化层、归一化层、高级层
CNN神经网络架构至少包含一个卷积层 (tf.nn.conv2d).单层CNN检测边缘.图像识别分类,使用不同层类型支持卷积层,减少过拟合,加速训练过程,降低内存占用率. TensorFlow加速所有 ...
- [PyTorch 学习笔记] 3.3 池化层、线性层和激活函数层
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson3/nn_layers_others.py 这篇文章主要介绍 ...
- CNN学习笔记:池化层
CNN学习笔记:池化层 池化 池化(Pooling)是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样.有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见 ...
- CNN-卷积层和池化层学习
卷积神经网络(CNN)由输入层.卷积层.激活函数.池化层.全连接层组成,即INPUT-CONV-RELU-POOL-FC (1)卷积层:用它来进行特征提取,如下: 输入图像是32*32*3,3是它的深 ...
- Keras深度神经网络算法模型构建【输入层、卷积层、池化层】
一.输入层 1.用途 构建深度神经网络输入层,确定输入数据的类型和样式. 2.应用代码 input_data = Input(name='the_input', shape=(1600, 200, 1 ...
- 深度学习原理与框架-卷积神经网络基本原理 1.卷积层的前向传播 2.卷积参数共享 3. 卷积后的维度计算 4. max池化操作 5.卷积流程图 6.卷积层的反向传播 7.池化层的反向传播
卷积神经网络的应用:卷积神经网络使用卷积提取图像的特征来进行图像的分类和识别 分类 相似图像搜索 ...
- tensorflow 1.0 学习:池化层(pooling)和全连接层(dense)
池化层定义在 tensorflow/python/layers/pooling.py. 有最大值池化和均值池化. 1.tf.layers.max_pooling2d max_pooling2d( in ...
- 【深度学习系列】迁移学习Transfer Learning
在前面的文章中,我们通常是拿到一个任务,譬如图像分类.识别等,搜集好数据后就开始直接用模型进行训练,但是现实情况中,由于设备的局限性.时间的紧迫性等导致我们无法从头开始训练,迭代一两百万次来收敛模型, ...
随机推荐
- Linux 在VMware中搭建CentOS6.5虚拟机
原文:http://www.cnblogs.com/PurpleDream/p/4263465.html Linux 在VMware中搭建CentOS6.5虚拟机 前言: 本文主要是我在大家 ...
- ios 6.0模拟器页面调出pop窗口消失后无法使用键盘
ios 6模拟器上,点击事件调用出pop窗口,这个窗口新创建了window,在pop窗口消失的函数中使用了makeKeyWindow,这个是将要显示的window放到最前端.发现 屏蔽这个方法后可以了 ...
- PHP网站http替换https
PHP网站http替换https
- 【Android归纳】阿里笔试题之Android网络优化
记得这是阿里校招笔试的一道问答题 答案是小伙伴们之后一起拼出来的,不乏有些飘忽的东西,须要的朋友能够做个參考(详细细节能够自行百度).欢迎提出更好的建议. 在client方面: 1.降低网络请求的数量 ...
- EasyUI datagrid border处理,加边框,去边框,都可以,easyuidatagrid
下面是EasyUI 官网上处理datagrid border的demo: 主要是这句: $('#dg').datagrid('getPanel').removeClass('lines-both li ...
- python的多线程问题
在对文件进行预处理的时候,由于有的文件有太大,处理很慢,用python处理是先分割文件,然后每个文件起一个线程处理,启了10个线程,结果还比不起线程慢一些,改成多进程之后就好了. 使用multipro ...
- vs 编译错误 The name 'InitializeComponent' does not exist in the current context in WPF application
1:文件命名空间的问题 xaml文件和model.cs文件的命名空间 2:csproj 那么它究竟是给谁用的呢?那是给开发工具用的,例如我们在熟悉不过的Visual Studio,以及大家可以没有接触 ...
- Arduino关于旋转编码器程序的介绍(Reading Rotary Encoders)--by Markdown
介绍 旋转或编码器是一个角度測量装置. 他用作精确測量电机的旋转角度或者用来控制控制轮子(能够无限旋转,而电位器只能旋转到特定位置).其中有一些还安装了一个能够在轴上按的button,就像音乐播放器的 ...
- ffmpeg编码常见问题排查方法
播放问题排查: 一旦我们遇到视频播放不了,第一件事,就是要找几个别的播放器也播放看看,做一下对比测试,或者对码流做一些基础分析,以便更好的定位问题的源头,而各个平台比较常见的播放/分析工具有如下几个: ...
- 第 1 章 第 2 题 空间敏感排序问题 位向量实现( bitset位向量 )
问题分析 在上篇文章中,给出了使用C语言中经典位运算符来实现位向量的方法.而本文,将介绍使用C++中的bitset容器来实现位向量的方法. 实现 // 请包含bitset头文件 #include &l ...