hadoop学习笔记——环境搭建
基础环境准备:
系统:(VirtualBox) ubuntu-12.04.2-desktop-i386.iso
hadoop版本:hadoop-0.20.203.0rc1.tar.gz
jdk版本:jdk-6u26-linux-i586.bin
安装ssh服务
sudo apt-get install openssh-server
在Ubuntu下创建hadoop用户组和用户
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hadoop
编辑/etc/sudoers文件,为hadoop用户添加权限
$ sudo vim /etc/sudoers
给hadoop用户赋予root相同的权限
hadoop ALL=(ALL:ALL) ALL
================================================================================
hadoop实战之安装与单机模式
--------------------------------------------------------------------------------
1. 下载最新的hadoop安装包,这里我使用的是hadoop-0.20.203.0rc1.tar.gz版本。
下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-0.20.203.0/hadoop-0.20.203.0rc1.tar.gz
2. 解压压缩包到自己的目录,比如解压到/home/hadoop/data目录下(tar –zxvf hadoop-0.20.203.orc1.tar.gz),为了后面说明方便,这里把/home/hadoop/data/hadoop-0.20.203.0定义为$HADOOP_HOME;
3. 修改$HADOOP_HOME/conf/hadoop-env.sh文件,将JAVA_HOME指定到正确的jdk路径上(echo $JAVA_HOME查看);
4. 进入$HADOOP_HOME目录下执行以下命令,将会得到hadoop命令的帮助;
$ bin/hadoop
5. 进入$HADOOP_HOME目录下执行以下命令来测试安装是否成功
$ mkdir input
$ cp conf/*.xml input
$ bin/hadoop jar hadoop-examples-*.jar grep input output 'dfs[a-z.]+'
$ cat output/*
输出:
hadoop@ubuntu-V01:~/data/hadoop-0.20.203.0$ cat output/*
1 dfsadmin
经过上面的步骤,如果没有出现错误就算安装成功了。
================================================================================
hadoop实战之伪分布式模式
--------------------------------------------------------------------------------
Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行,这种运行方式的配置和操作如下:
关于hadoop的安装和测试可以参考...
这里仍假定${HADOOP_HOME}为位置是/home/hadoop/data/hadoop-0.20.203.0
1. 修改hadoop配置
1.1 编辑${HADOOP_HOME}/conf/core-site.xml文件,内容修改如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
1.2 编辑${HADOOP_HOME}/conf/hdfs-site.xml文件,内如修改如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
1.3 编辑${HADOOP_HOME}/conf/mapred-site.xml文件,内如修改如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
2. 设置linux上ssh是用户可以自动登录
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3. 格式化一个新的分布式文件系统:
$ bin/hadoop namenode -format
4. 执行hadoop
4.1 启动hadoop后台daemon
$ bin/start-all.sh
启动后可以通过网页方式查看NameNode和JobTracker状态
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
4.2 复制文件到分布式文件系统上
$ bin/hadoop fs -put conf input
4.3 运行测试
$ bin/hadoop jar hadoop-examples-*.jar grep input output 'dfs[a-z.]+'
4.4 获取测试程序的执行结果
$ bin/hadoop fs -cat output/*
输出:
hadoop@ubuntu-V01:~/data/hadoop-0.20.203.0$ bin/hadoop fs -cat output/*
2 dfs.replication
1 dfs.server.namenode.
1 dfsadmin
4.5 停止hadoop后台daemon
$ bin/stop-all.sh
================================================================================
hadoop实战之分布式模式
--------------------------------------------------------------------------------
1. 首先为hadoop的集群准备几台机器,这里机器名如下:
ubuntu-V01(master)
ubuntu-V02(slave1)
ubuntu-V03(slave2)
2. 修改每个机器的/etc/hosts文件,确保每个机器都可以通过机器名互相访问;
3. 在上面每个机器上的相同位置分别安装hadoop,这里安装的都是hadoop-0.20.203.0rc1.tar.gz包,并且假定安装路径都是/home/hadoop/data/hadoop-0.20.203.0;
4. 修改所有机器上的${HADOOP_HOME}/conf/hadoop-env.sh文件,将JAVA_HOME指定到正确的jdk路径上;
5. 修改master机器上的${HADOOP_HOME}/conf/slaves文件,修改后文件内容如下:
ubuntu-V02
ubuntu-V03
6. 修改和部署配置文件
6.1 编辑${HADOOP_HOME}/conf/core-site.xml文件,内容修改如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://ubuntu-V01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoop-0.20.203.0/hadoop-${user.name}</value>
</property>
</configuration>
6.2 编辑${HADOOP_HOME}/conf/hdfs-site.xml文件,内如修改如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6.3 编辑${HADOOP_HOME}/conf/mapred-site.xml文件,内如修改如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>ubuntu-V01:9001</value>
</property>
</configuration>
6.4 将以上三个配置文件分别部署在每个节点上;
7. 格式化一个新的分布式文件系统:
$ bin/hadoop namenode -format
8. 执行hadoop
8.1 启动hadoop后台daemon
$ bin/start-all.sh
启动后可以通过以下网页方式查看NameNode和JobTracker状态,此时可以从NameNode状态网页上看到"Live Nodes"的数量变成了两个,此时表示已经部署成功
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
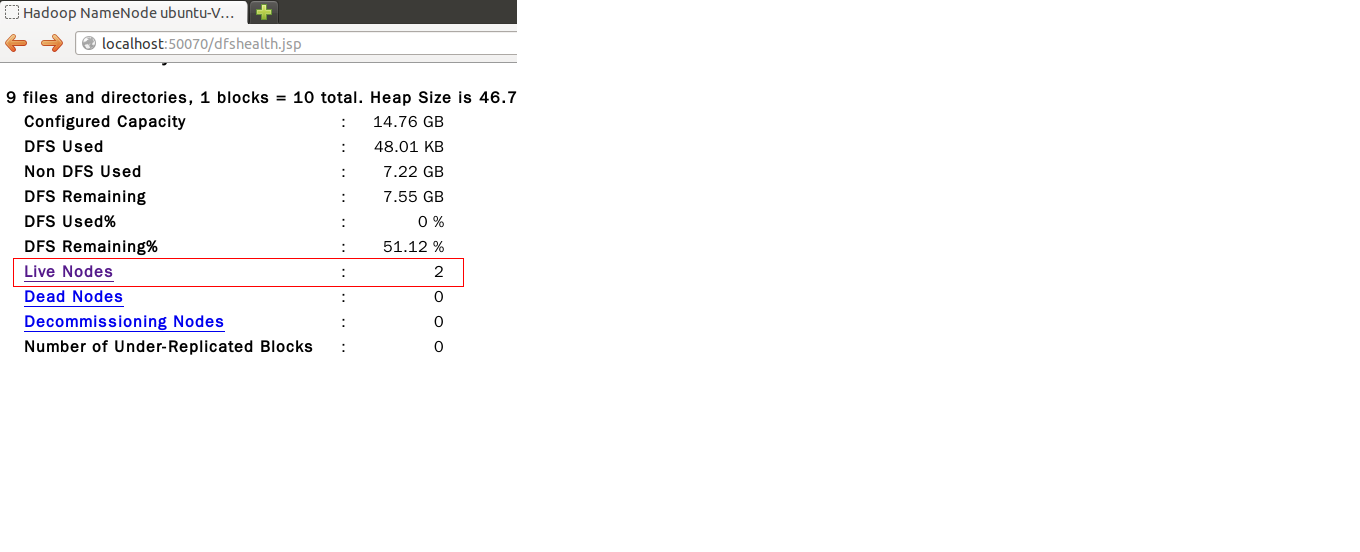

8.2 运行测试
在hadoop默认提供了一些可以运行的测试工具在安装包目录下,下面就用这些测试程序来验证分布式模式是否成功
8.2.1 测试一
运行下面的命令将从本地复制一个文件到hdfs文件系统的/test/目录下
$ bin/hadoop fs -copyFromLocal /home/hadoop/data/hadoop-0.20.203.0/hadoop-examples-0.20.203.0.jar /test/hadoop-examples-0.20.203.0.jar
运行下面的命令将显示hdfs文件系统上/test/目录下的文件
$ bin/hadoop fs -ls /test/
输出结果如下:
Found 1 items
-rw-r--r-- 1 hadoop supergroup 142469 2014-01-25 16:22 /test/hadoop-examples-0.20.203.0.jar
运行完上面的命令以后,可以通过http://localhost:50070/来查看hdfs上的文件,此时可以看到slave节点上已经有刚才命令上传的文件存在了。
8.2.2 测试二
运行下面的命令
$ bin/hadoop jar hadoop-examples-0.20.203.0.jar sleep 300
然后访问http://localhost:50030/,可以看到会有job在cluster里运行
8.2.3 测试三
首先准备数据,下面两个命令是在hdfs上创建一个/test/input目录,然后从本地复制一下文件到此目录下
$ bin/hadoop fs -mkdir /test/input
$ bin/hadoop fs -copyFromLocal /home/hadoop/data/hadoop-0.20.203.0/conf/*.xml /test/input
运行测试来查找一些字符串
$ bin/hadoop jar hadoop-examples-*.jar grep /test/input /test/output 'dfs[a-z.]+'
查看测试结果
$ bin/hadoop fs -ls /test/output/
$ bin/hadoop fs -cat /test/output/part-00000
8.3 停止hadoop后台daemon
$ bin/stop-all.sh
================================================================================
hadoop实战之动态添加节点
--------------------------------------------------------------------------------
假定已经有了一个hadoop cluster环境,并且已经有了两个slave节点ubuntu-V02和ubuntu-V03,这里需要动态添加一个新的节点ubuntu-V04.
1. 修改${HADOOP_HOME}/conf/slaves文件,在其中添加一个新的slave节点,比如
ubuntu-V02
ubuntu-V03
ubuntu-V04(新节点)
2. 登录到新添加的slave节点上,进入${HADOOP_HOME}目录并运行以下命令:
$ bin/hadoop-daemon.sh start datanode
$ bin/hadoop-daemon.sh start tasktracker
3. 验证添加是否成功
3.1 访问http://localhost:50070/可以看到"Live Nodes"的数量就从2变成了3;
3.2 也可以通过以下命令行来验证是否成功
$ bin/hadoop dfsadmin -report
================================================================================
备注:
进行分布式环境配置时,注意 /etc/hosts中ip与主机名的映射
如ubuntu-01机器上:
hadoop@ubuntu-V01:~$ cat /etc/hosts
127.0.0.1 localhost
192.168.1.109 ubuntu-V01
192.168.1.110 ubuntu-V02
192.168.1.111 ubuntu-V03
192.168.1.112 ubuntu-V04
参考:
http://hadoop.apache.org/docs/r0.19.1/cn/index.html
http://hadoop.apache.org/docs/r1.0.4/cn/index.html
http://blog.csdn.net/greatelite/article/details/17690239 Hadoop 2.2.0 分布式集群搭建
http://www.infoq.com/cn/articles/hadoop-intro 分布式计算开源框架Hadoop入门实践(一)分布式计算开源框架Hadoop介绍
http://www.infoq.com/cn/articles/hadoop-config-tip 分布式计算开源框架Hadoop入门实践(二)Hadoop中的集群配置和使用技巧
http://www.infoq.com/cn/articles/hadoop-process-develop 分布式计算开源框架Hadoop入门实践(三)Hadoop基本流程与应用开发
hadoop学习笔记——环境搭建的更多相关文章
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- Hadoop学习笔记(4) ——搭建开发环境及编写Hello World
Hadoop学习笔记(4) ——搭建开发环境及编写Hello World 整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA.在linux下开发JAVA还数eclip ...
- Hadoop学习笔记01_Hadoop搭建
想往大数据方向转, 难度肯定是有的. 基础知识肯定是要有的,如果是熟悉JAVA开发的人,转向应该优势大. 像我这样的,只有Linux基础以及简单的PHP基础的人,转向难度很大.但是事在人为,努力学习多 ...
- MongoDB学习笔记~环境搭建
回到目录 Redis学习笔记已经告一段落,Redis仓储也已经实现了,对于key/value结构的redis我更愿意使用它来实现数据集的缓存机制,而对于结构灵活,查询效率高的时候使用redis就有点不 ...
- 0.react学习笔记-环境搭建与脚手架
0.环境搭建 笔者使用的是deepin/mac两种系统,因为两个电脑经常切换用.环境搭建没什么区别. 0.1 node安装 按照node官网叙述安装 # Using Debian, as root c ...
- VS2013中Python学习笔记[环境搭建]
前言 Python是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色 ...
- Spring学习笔记--环境搭建和初步理解IOC
Spring框架是一个轻量级的框架,不依赖容器就能够运行,像重量级的框架EJB框架就必须运行在JBoss等支持EJB的容器中,核心思想是IOC,AOP,Spring能够协同Struts,hiberna ...
- DVWA学习笔记-----环境搭建
DVWA是一款渗透测试的演练系统,在圈子里是很出名的.如果你需要入门,那么就选它了. 我们通常将演练系统称为靶机,下面请跟着我一起搭建DVWA测试环境. 安装PHP集成环境 我这里用的是phpstu ...
- ESP32 学习笔记 - 环境搭建
打开终端 输入命令 sudo apt-get install gcc git wget make libncurses-dev flex bison gperf python python-seria ...
随机推荐
- LoadRunner 11破解方法
名称:HP Loadrunner Software 11.00 版本号:11.00.0.0 安装环境:Win 7 软件安装成功后,会弹出提示告知license的有效期为10天. 破解方法: 1.下载破 ...
- 前端PS切图技巧
先选择“编辑”-“首选项” 打开,找到“参考线” 设置一下每格网格 100像素 5个细块 确定后 ctrl+‘ 出现网格.(通过网格对齐切图比用参考线切图更好). 如果使用PS cc的软件的话, ...
- [python][oldboy]strip
- [python 测试框架学习篇] 分享 uiautomator测试框架
uiautomator测试框架 :https://testerhome.com/topics/4194
- [Android Studio篇][1] AS开发中遇到问题汇总
1 在android新建文件,提示权限不够,增加权限 修改工程下 main/AndroidMainfest.xml增加 <uses-permission android:name="a ...
- Android强制更新
代码改变世界 Android版本强制更新 package com.lianpos.util; import android.content.Context; import android.conten ...
- Welcome-to-Swift-23访问控制(Access Control)
访问控制可以限定你在源文件或模块中访问代码的级别,也就是说可以控制哪些代码你可以访问,哪些代码你不能访问.这个特性可以让我们隐藏功能实现的一些细节,并且可以明确的指定我们提供给其他人的接口中哪些部分是 ...
- iOS学习笔记28-系统服务(一)短信和邮件
一.系统应用 在开发某些应用时,我们可能希望能够调用iOS系统内置的电话.短信.邮件.浏览器应用,或者直接调用安装的第三方应用,这个要怎么实现呢? 这里统一使用UIApplication的一个对象方法 ...
- 【Luogu】U16325小奇的花园(树链剖分)
题目链接 学了学动态开点的树链剖分,其实跟动态开点的线段树差不多啦 查询的时候别ssbb地动态开点,如果没这个点果断返回0就行 只要注意花的种类能到intmax就行qwq!!!! #include&l ...
- [USACO08DEC] 秘密消息Secret Message (Trie树)
题目链接 Solution Trie 树水题. 直接将前面所有字符串压入Trie 中. 在查询统计路上所有有单词的地方和最后一个地方以下的单词数即可. Code #include<bits/st ...