论文笔记:《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks DeepLearning 》
一、Abstract综述
训练出一个CNN可以同时实现分类,定位和检测..,三个任务共用同一个CNN网络,只是在pool5之后有所不同
二、分类
这里CNN的结构是对ALEXNET做了一些改进,具体的在论文中都说了,就不再赘述了。说几个关键的地方。
1.之前在多尺度的情况下,Krizhevsky用的是multi—view的方法,也就是对给定的图片分别取四个角,中间以及翻转的图块输入到CNN中,得到的结果取均值。这个方法的缺陷在于有些区域的组合会被忽略(比如 ground truth在中间偏右,但是此方法并没有检测这个框),只关注了一个scale导致结果的置信度不高,而且重叠区域的计算很耗时。所以这里采用的方法是multi—scale。
传统的检测/定位算法是固定输入图像不变,采用不同大小的滑窗来支持不同尺度的物体。这里因为采用的是全卷积网络,训练时固定输入大小,使用的时候可以multi-scale,这个待会再详细讲,只要清楚每次输入的时候,滑窗的大小就是训练时输入图像的大小,是不可以改变的。那么,CNN支持多尺度的办法就是,固定滑窗的大小,改变输入图像的大小。具体来说,对于一幅给定的待处理的图像,将图像分别resize到对应的尺度上,然后,在每一个尺度上执行上述的密集采样的算法,最后,将所有尺度上的结果结合起来,得到最终的结果。
这样做的好处就是:1.速度快,卷积处理的速度当然快 2.预测时不用对图像做尺度处理。
但是固定slide window也有坏处,就是步长固定了, 整个网络的子采样比例=2*3*2*3=36,即当应用网络计算时,输入图像的每个维度上,每36个像素才能产生一个输出。文章采用的解决方法是使用模型前5层卷积层来提取特征,layer 5在 pooling 之前给定 x,y 一个偏移,,即对每个 feature map 滑窗从(0,0), (0,1), (0,2), (1,0), (1,1)...处分别开始滑动,得到9种不同的feature map,那么下一层的 feature map 总数为9*前一层的 num_output。这样的话就会把sampling从36降到了12.
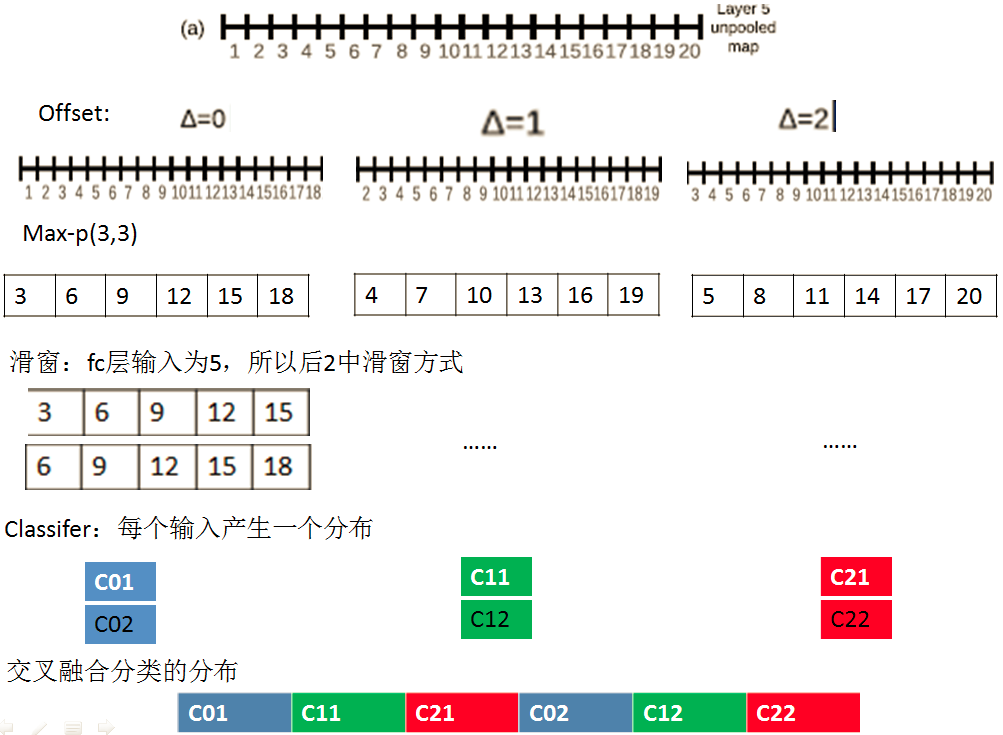
2.offset max-pooling
上面的方法是可以单独拉出来说一说的,以下图为例,这是一维的,classfilier的输入要求是1*5,我们先用offset max_pooling得到三个1*6的feature map(注意这里是non-overlapping regions的),然后对每个用1*5的滑动窗口计算,也就是放到分类器里面,会得到2*3=6个输出,然后融合以后就可以得到分类器的1*6的输出。
2.全卷积网络的好处
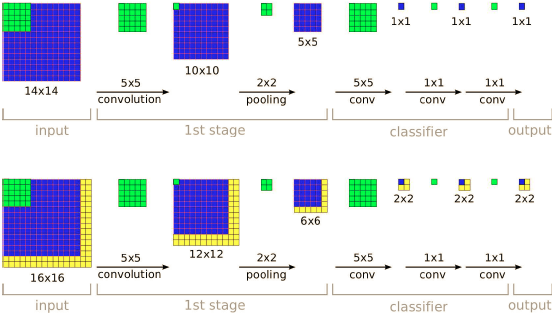
如上图所示,可以看到后面的全连接层被转换为卷积层了,本来训练的时候只有14*14的输入,最后得到1*1的输出,在predict的时候,如果输入时16*16,最后得到的结果是2*2的output,这个相当于四个滑动窗口在16*16的input上滑动的输出结果,但计算明显减轻了很多。
3.上面这样做还有一个问题,就是不同的scale输出的feature map大小不同,而最后的classifier要求固定的input,所以这里需要calssifier在feature map上做滑动窗口,这样最后就有了multi-scale的预测:最对某一个类别,分别对不同scale矩阵取最大值,然后取该类别中不同矩阵最大值的均值,最后输出所有类别的top-1 or top-5
三、定位
定位问题的模型也是一个CNN,1-5层作为特征提取层和分类问题完全一样,后面接两个全连接层,组成regressor network ,也就是用回归的方法来训练得到bounding box的四个角点的坐标,使用预测边界和真实边界之间的L2范数作为代价函数,来训练回归网络。对于每个class都要单独训练一个定位层,这样,假设类别数有1000,则这个 regressor network 输出1000个 bounding box ,每一个 bounding box对应一类。
1.算法流程
(1)初始化模型后,进来一张图片,利用滑动窗口技术提取出来多个patch。
(2)对于每个patch,用分类模型确定好类别,然后使用对用的定位模型来确定物体的位置。
(3)根据分类的分数可以选出k个候选的patch
(4)对patch进行合并
2.合并多框
因为论文里面使用的方法是重合率超过百分50就可以留下,所以会有很多的bounding box,所以最后需要做一个合并多框的方法,这里采用的是贪心策略
a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合放入B中,在进行循环计算。
最终的结果通过融合具有最高置信度的bounding box给出。
3.为什么训练定位的时候要用multi-scale的输入
是为了在predic的时候可以做到across—scale的预测,多尺度的训练会让后面的合并的可信度更高,当然这也有问题,就是只能在处理训练的时候这几个尺度上的图片有好的效果,其他的时候不行。
三、检测
同时跑上面两个,得到的结果就是的了...
四、总结
最大的亮点在于在pool层用小的滑动窗口代替input的大的滑动窗口吧,大大提高了计算效率,而且这样可以fix住feature提取的那部分,所以检测和定位就可以共用了,所以整个CNN的效率和精度都有了很大的提高.暂时了解的只有这么多了,以后有新的理解还要再来修改。
论文笔记:《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks DeepLearning 》的更多相关文章
- 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:<Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition> 论文作者:Qibin ...
- [place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466 abstract introduction method overview Dee ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
随机推荐
- 解决Postgresql服务启动又关闭的问题
查看日志发现如下错误消息:%t LOG: could not receive data from client: An operation was attempted on something tha ...
- Drupal的入门学习
1. 注意content中的区别 Article和Basic page的区别 a.输入字段不一样,Article内容多了两个字段:tag和图片. b.内容的默认设置不一样,Article默认允许评论, ...
- java基础面试题:java中实现多态的机制是什么?
靠的是父类或接口的引用指向子类或实现类的对象, 调用的方法是内存中正在运行的那个对象的方法.
- FILE对象线程安全
根据apue讲述: 标准的IO例程可能从它们各自的内部数据结构的角度出发,是以线程安全的方式实现的!但在线程中,如果标准 IO例程都获取它们各自的锁,那么在做一次一个字符的IO时就会出现严重的性能下降 ...
- ORA-04031: Unable To Allocate 32 Bytes Of Shared Memory
记录一次生产库遇到的4031错误,后来通过调整sga大小将问题解决了 报错信息: ORA-04031: 无法分配 32 字节的共享内存 ("shared pool","s ...
- 重置 nexus3 admin 密码
2 简单 3 重构,变化很大 如何处理nexus3忘记admin密码 - CSDN博客 https://blog.csdn.net/tianya6607/article/details/5330562 ...
- The Apache Tomcat Servlet/JSP Container
1.Tomcat部署的场景分析 通常,我们对tomcat单机部署需求可以分为几种: 单实例单应用 (一个tomcat 一个web应用) 单实例多应用 (一个tomcat多个应用) 多实例单应用 (多个 ...
- nginx的缓存服务
都知道缓存的目的是为了减小服务端的压力,可以在客户端直接取到数据 客户端---------------nginx(代理缓存)------------------服务端 代理缓存的描述: 就是客户端发送 ...
- 以太坊国内节点大全(ropsten)
admin.addPeer('enode://2d1e1f1242c3b54ea56046f74f15943f47ab410e3c0b82bffb501793ebb19e147f8f0e63d01c2 ...
- HDU 1423 Greatest Common Increasing Subsequence(LCIS)
Greatest Common Increasing Subsequenc Problem Description This is a problem from ZOJ 2432.To make it ...