【赵渝强老师】搭建Hadoop环境
说明:这里我们以本地模式和伪分布模式伪列,为大家介绍如何搭建Hadoop环境。有了这个基础,大家可以自行搭建Hadoop的全分布模式。
需要使用的安装介质:
- hadoop-2.7.3.tar.gz
- jdk-8u181-linux-x64.tar.gz
- rhel-server-7.4-x86_64-dvd.iso
一、安装前的准备工作
- 安装好Redhat Linux 7.4(安装包rhel-server-7.4-x86_64-dvd.iso),并在Linux上创建tools和training两个目录

- 关闭防火墙,执行下面的命令
systemctl stop firewalld.service
systemctl disable firewalld.service
- 配置主机名,使用vi编辑器编辑文件/etc/hosts,输入以下内容
bigdata111 192.168.157.111
- 配置免密码登录,在命令行中输入下面的命令
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata111
二、安装JDK
- 通过FTP工具将jdk-8u181-linux-x64.tar.gz和hadoop-2.7.3.tar.gz上传到Linux的/root/tools目录
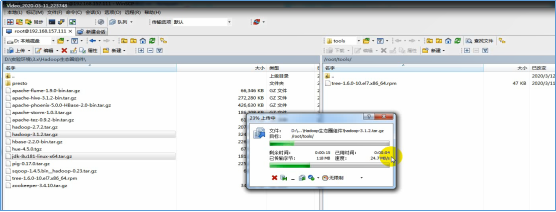
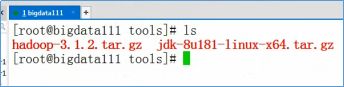
- 在xshell中,解压jdk-8u181-linux-x64.tar.gz,执行下面的命令
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /root/training/
- 设置Java的环境变量,使用vi编辑器编辑~/.bash_profile文件。执行下面的命令
vi /root/.bash_profile
- 在vi编辑器中,输入以下内容
JAVA_HOME=/root/training/jdk1.8.0_181
export JAVA_HOME PATH=$JAVA_HOME/bin:$PATH
export PATH
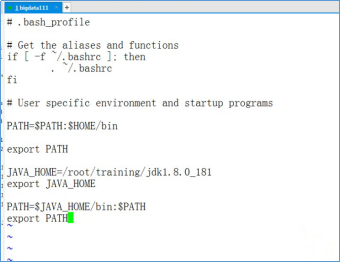
- 生效环境变量,执行下面的命令
source /root/.bash_profile

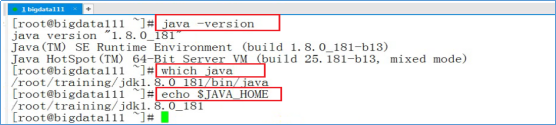
- 输入下图中,红框中的命令验证Java环境
三、解压Hadoop,并设置环境变量
- 执行下面的命令,解压hadoop-2.7.3.tar.gz
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
- 设置Hadoop的环境变量,编辑~/.bash_profile文件,并输入以下内容
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
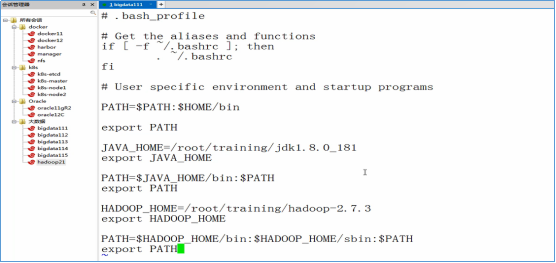
- 生效环境变量
source ~/.bash_profile
四、搭建Hadoop的本地模式
- 进入目录/root/training/hadoop-2.7.3/etc/hadoop
- 使用vi编辑器编辑文件:hadoop-env.sh
- 修改JAVA_HOME
export JAVA_HOME=/root/training/jdk1.8.0_181

- 测试Hadoop的本地模式,执行MapReduce程序。准备测试数据:vi ~/temp/data.txt
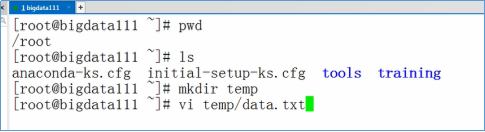
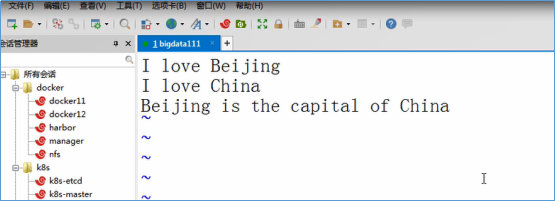
- 输入下面的数据,并保存退出
- 进入目录:/root/training/hadoop-2.7.3/share/hadoop/mapreduce

- 执行WordCount任务
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /root/temp /root/output/wc
- 根据下图的命令,查看输出结果
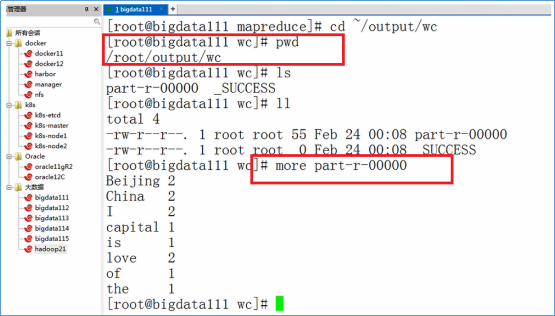
五、搭建Hadoop的伪分布模式
- 首先,搭建好Hadoop的本地模式
- 创建目录:/root/training/hadoop-2.7.3/tmp
mkdir /root/training/hadoop-2.7.3/tmp
- 进入目录:/root/training/hadoop-2.7.3/etc/hadoop
cd /root/training/hadoop-2.7.3/etc/hadoop
- 修改hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
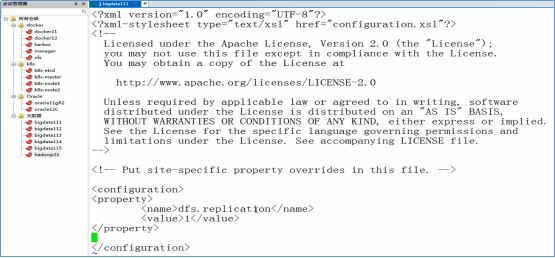
- 修改core-site.xml
<!--配置NameNode的地址-->
<!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property> <!--HDFS对应的操作系统目录-->
<!--默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
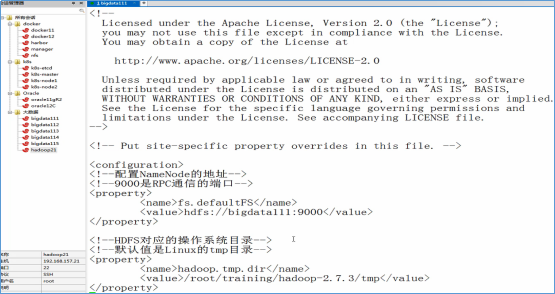
- 修改mapred-site.xml(注意:这个文件默认没有)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

- 修改yarn-site.xml
<!--配置ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property> <!--MapReduce运行的方式是洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

- 格式化NameNode
hdfs namenode -format

- 启动Hadoop
start-all.sh

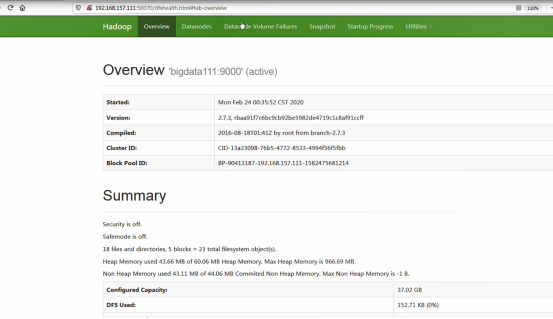
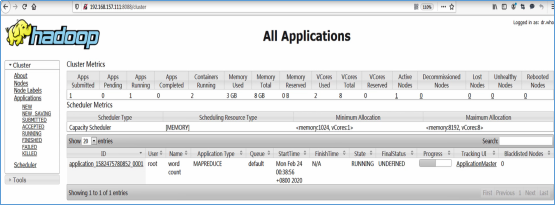
- 访问Web Console
http://192.168.157.111:50070
http://192.168.157.111:8088

【赵渝强老师】搭建Hadoop环境的更多相关文章
- 【一】、搭建Hadoop环境----本地、伪分布式
## 前期准备 1.搭建Hadoop环境需要Java的开发环境,所以需要先在LInux上安装java 2.将 jdk1.7.tar.gz 和hadoop 通过工具上传到Linux服务器上 3. ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- (转)超详细单机版搭建hadoop环境图文解析
超详细单机版搭建hadoop环境图文解析 安装过程: 一.安装Linux操作系统 二.在Ubuntu下创建hadoop用户组和用户 三.在Ubuntu下安装 ...
- 基于CentOS与VmwareStation10搭建hadoop环境
基于CentOS与VmwareStation10搭建hadoop环境 目 录 1. 概述.... 1 1.1. 软件准备.... 1 1.2. 硬件准备.... 1 2. 安装与配置虚拟机.. ...
- 基于《Hadoop权威指南 第三版》在Windows搭建Hadoop环境及运行第一个例子
在Windows环境上搭建Hadoop环境需要安装jdk1.7或以上版本.有了jdk之后,就可以进行Hadoop的搭建. 首先下载所需要的包: 1. Hadoop包: hadoop-2.5.2.tar ...
- Docker搭建Hadoop环境
文章目录 Docker搭建Hadoop环境 Docker的安装与使用 拉取镜像 克隆配置脚本 创建网桥 执行脚本 Docker命令补充 更换镜像源 安装vim 启动Hadoop 测试Word Coun ...
- Linux 下搭建 Hadoop 环境
Linux 下搭建 Hadoop 环境 作者:Grey 原文地址: 博客园:Linux 下搭建 Hadoop 环境 CSDN:Linux 下搭建 Hadoop 环境 环境要求 操作系统:CentOS ...
- 虚拟机搭建hadoop环境
这里简单用三台虚拟机,搭建了一个两个数据节点的hadoop机群,仅供新人学习.零零碎碎,花了大概一天时间,总算完成了. 环境 Linux版本:CentOS 6.5 VMware虚拟机 jdk1.6.0 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- 使用docker搭建hadoop环境,并配置伪分布式模式
docker 1.下载docker镜像 docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop:latest 注:此镜像为阿里云个人上传镜 ...
随机推荐
- Known框架实战演练——进销存基础数据
本文介绍如何实现进销存管理系统的基础数据模块,基础数据模块包括商品信息.供应商管理和客户管理3个菜单页面.供应商和客户字段相同,因此可共用一个页面组件类. 项目代码:JxcLite 开源地址: htt ...
- 5/15课下作业:评价一下steam软件
用户界面: 登录后会弹出特惠广告,广告内容可能不常用.主界面简洁方便,启动游戏,购买游戏,浏览社区,浏览自己内容一目了然 记住用户选择: 登录一次后会记住用户的账户密码,可以直接进行用户间的切换,会记 ...
- ssh 转发 和 切换图形化
适用环境 宿主机连接到一台服务器是,服务器系统里面的浏览器点击http网页卡顿,那么这时可以通过ssh将端口转发到宿主机 使用宿主机的浏览器点击,则不会很卡顿. [root@foundation1 ~ ...
- RHCA rh442 003 系统资源 查看硬件 tuned调优
监控工具 zabbix 监控具体业务,列如数据库.触发式事件(断网 硬盘坏一个) 普罗米修斯 给容器做监控 管理人员,如何知道几千台服务器哪些出了问题,这得需要zabbix 系统硬件资源 cpu [r ...
- python面向对象游戏练习:好人坏人手枪手榴弹
python面向对象游戏练习:好人坏人手枪手榴弹 主要是多态的练习,对象作为参数传给方法使用 1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 ...
- 【DataBase】MySQL 28 流程控制
一.分支结构 1.IF函数 语法: IF(表达式1, 表达式2, 表达式3) 类似三元运算符,表达式1返回True Or False True执行表达式2,False执行表达式3 IF实现多分枝结构 ...
- cdq分治 基础篇
简介 前置芝士:归并排序. \(cdq\) 分治是个离线算法,可以解决三维偏序或者优化 \(dp\). 陌上花开 维护三维偏序有个口诀:一维排序,二维归并,三维数据结构. 考虑第一维直接排序解决掉,然 ...
- OpenPCDet复现过程记录
0.前言 OpenPCDet项目之前我就复现过,一个很优秀的项目,这几天又需要用到这个项目,再次复现遇到了不少问题,特此记录复现的流程 1.环境准备 1.1.前置条件 以下是我安装的版本 CUDA 1 ...
- 推荐2款实用的持续集成与部署(CI&CD)自动化工具
前言 最近DotNetGuide技术社区交流群有不少同学在咨询:持续集成与部署(CI&CD)自动化工具有什么好用的推荐?今天大姚给大家推荐2款实用且免费的持续集成与部署(CI&CD)自 ...
- springboot 大文件切片上传
1. 前端(vue element ui & 原生) 初始变量声明: currentFile: {}, // 当前上传的文件 bigFileSliceCount: 20, // 大文件切片后的 ...