[转帖]RocksDB 简介
https://docs.pingcap.com/zh/tidb/stable/rocksdb-overview
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),然后再写入内存中的跳表(SkipList,这部分结构又被称作 MemTable)。LSM-tree 引擎由于将用户的随机修改(插入)转化为了对 WAL 文件的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。
内存中的数据达到一定阈值后,会刷到磁盘上生成 SST 文件 (Sorted String Table),SST 又分为多层(默认至多 6 层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层,每一层的数据是上一层的 10 倍(因此 90% 的数据存储在最后一层)。
RocksDB 允许用户创建多个 ColumnFamily,这些 ColumnFamily 各自拥有独立的内存跳表以及 SST 文件,但是共享同一个 WAL 文件,这样的好处是可以根据应用特点为不同的 ColumnFamily 选择不同的配置,但是又没有增加对 WAL 的写次数。
TiKV 架构
TiKV 的系统架构如下图所示:
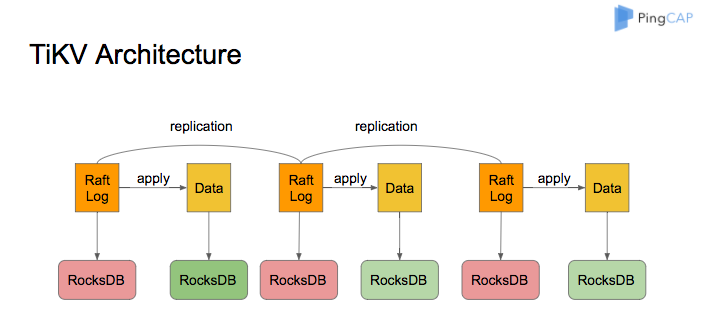
RocksDB 作为 TiKV 的核心存储引擎,用于存储 Raft 日志以及用户数据。每个 TiKV 实例中有两个 RocksDB 实例,一个用于存储 Raft 日志(通常被称为 raftdb),另一个用于存储用户数据以及 MVCC 信息(通常被称为 kvdb)。kvdb 中有四个 ColumnFamily:raft、lock、default 和 write:
- raft 列:用于存储各个 Region 的元信息。仅占极少量空间,用户可以不必关注。
- lock 列:用于存储悲观事务的悲观锁以及分布式事务的一阶段 Prewrite 锁。当用户的事务提交之后,lock cf 中对应的数据会很快删除掉,因此大部分情况下 lock cf 中的数据也很少(少于 1GB)。如果 lock cf 中的数据大量增加,说明有大量事务等待提交,系统出现了 bug 或者故障。
- write 列:用于存储用户真实的写入数据以及 MVCC 信息(该数据所属事务的开始时间以及提交时间)。当用户写入了一行数据时,如果该行数据长度小于 255 字节,那么会被存储 write 列中,否则的话该行数据会被存入到 default 列中。由于 TiDB 的非 unique 索引存储的 value 为空,unique 索引存储的 value 为主键索引,因此二级索引只会占用 writecf 的空间。
- default 列:用于存储超过 255 字节长度的数据。
RocksDB 的内存占用
为了提高读取性能以及减少对磁盘的读取,RocksDB 将存储在磁盘上的文件都按照一定大小切分成 block(默认是 64KB),读取 block 时先去内存中的 BlockCache 中查看该块数据是否存在,存在的话则可以直接从内存中读取而不必访问磁盘。
BlockCache 按照 LRU 算法淘汰低频访问的数据,TiKV 默认将系统总内存大小的 45% 用于 BlockCache,用户也可以自行修改 storage.block-cache.capacity 配置设置为合适的值,但是不建议超过系统总内存的 60%。
写入 RocksDB 中的数据会写入 MemTable,当一个 MemTable 的大小超过 128MB 时,会切换到一个新的 MemTable 来提供写入。TiKV 中一共有 2 个 RocksDB 实例,合计 4 个 ColumnFamily,每个 ColumnFamily 的单个 MemTable 大小限制是 128MB,最多允许 5 个 MemTable 存在,否则会阻塞前台写入,因此这部分占用的内存最多为 4 x 5 x 128MB = 2.5GB。这部分占用内存较少,不建议用户自行更改。
RocksDB 的空间占用
- 多版本:RocksDB 作为一个 LSM-tree 结构的键值存储引擎,MemTable 中的数据会首先被刷到 L0。L0 层的 SST 之间的范围可能存在重叠(因为文件顺序是按照生成的顺序排列),因此同一个 key 在 L0 中可能存在多个版本。当文件从 L0 合并到 L1 的时候,会按照一定大小(默认是 8MB)切割为多个文件,同一层的文件的范围互不重叠,所以 L1 及其以后的层每一层的 key 都只有一个版本。
- 空间放大:RocksDB 的每一层文件总大小都是上一层的 x 倍,在 TiKV 中这个配置默认是 10,因此 90% 的数据存储在最后一层,这也意味着 RocksDB 的空间放大不超过 1.11(L0 层的数据较少,可以忽略不计)。
- TiKV 的空间放大:TiKV 在 RocksDB 之上还有一层自己的 MVCC,当用户写入一个 key 的时候,实际上写入到 RocksDB 的是 key + commit_ts,也就是说,用户的更新和删除都是会写入新的 key 到 RocksDB。TiKV 每隔一段时间会删除旧版本的数据(通过 RocksDB 的 Delete 接口),因此可以认为用户存储在 TiKV 上的数据的实际空间放大为,1.11 加最近 10 分钟内写入的数据(假设 TiKV 回收旧版本数据足够及时)。详情见《TiDB in Action》。
RocksDB 后台线程与 Compact
RocksDB 中,将内存中的 MemTable 转化为磁盘上的 SST 文件,以及合并各个层级的 SST 文件等操作都是在后台线程池中执行的。后台线程池的默认大小是 8,当机器 CPU 数量小于等于 8 时,则后台线程池默认大小为 CPU 数量减一。通常来说,用户不需要更改这个配置。如果用户在一个机器上部署了多个 TiKV 实例,或者机器的读负载比较高而写负载比较低,那么可以适当调低 rocksdb/max-background-jobs 至 3 或者 4。
WriteStall
RocksDB 的 L0 与其他层不同,L0 的各个 SST 是按照生成顺序排列,各个 SST 之间的 key 范围存在重叠,因此查询的时候必须依次查询 L0 中的每一个 SST。为了不影响查询性能,当 L0 中的文件数量过多时,会触发 WriteStall 阻塞写入。
如果用户遇到了写延迟突然大幅度上涨,可以先查看 Grafana RocksDB KV 面板 WriteStall Reason 指标,如果是 L0 文件数量过多引起的 WriteStall,可以调整下面几个配置到 64,详细见《TiDB in Action》。
[转帖]RocksDB 简介的更多相关文章
- [转帖]rsync简介
rsync用法详细解释 https://www.cnblogs.com/noxy/p/8986164.html 之前一直使用 scp 现在发现这个命令更好一些. 提要 熟悉 rsync 的功能及其特点 ...
- [转帖]Kerberos简介
1. Kerberos简介 https://www.cnblogs.com/wukenaihe/p/3732141.html 1.1. 功能 一个安全认证协议 用tickets验证 避免本地保存密码 ...
- [转帖]BurpSuite简介
BurpSuite简介 https://bbs.ichunqiu.com/thread-54760-1-1.html BurpSuite ,这是一个辅助渗透的工具,可以给我们带来许多便利.Burp 给 ...
- [转帖]Keccak简介
Keccak简介 https://blog.csdn.net/chengqiuming/article/details/82819769 2018年09月23日 08:04:40 cakincqm 阅 ...
- [转帖]SPARC简介
https://www.cnblogs.com/chaohm/p/5674886.html 1. 概述 SPARC(Scalable Processor ARChitecture,可扩展处理器架 ...
- [转帖]phoronix-test-suite 简介
<工作杂记>之phoronix-test-suite 2017年10月30日 14:32:52 打雷下雨 阅读数 2078更多 分类专栏: # linux 版权声明:本文为博主原创文章 ...
- [转帖]可能是东半球最好的 Curl 学习指南,强烈建议收藏!
可能是东半球最好的 Curl 学习指南,强烈建议收藏! http://www.itpub.net/2019/09/30/3302/ 记得转帖过.. 简介 curl 是常用的命令行工具,用来请求 Web ...
- 「Flink」RocksDB介绍以及Flink对RocksDB的支持
RocksDB介绍 RocksDB简介 RocksDB是基于C++语言编写的嵌入式KV存储引擎,它不是一个分布式的DB,而是一个高效.高性能.单点的数据库引擎.它是由Facebook基于Google开 ...
- 【转帖】LSM树 和 TSM存储引擎 简介
LSM树 和 TSM存储引擎 简介 2019-03-08 11:45:23 长烟慢慢 阅读数 461 收藏 更多 分类专栏: 时序数据库 版权声明:本文为博主原创文章,遵循CC 4.0 BY-S ...
- [转帖]influxdb和boltDB简介——MVCC+B+树,Go写成,Bolt类似于LMDB,这个被认为是在现代kye/value存储中最好的,influxdb后端存储有LevelDB换成了BoltDB
influxdb和boltDB简介——MVCC+B+树,Go写成,Bolt类似于LMDB,这个被认为是在现代kye/value存储中最好的,influxdb后端存储有LevelDB换成了BoltDB ...
随机推荐
- bash命令的使用
bash的工作特性之命令执行状态返回值和命令展开所涉及的内容及其示例演出 !脚本执行与调试 1.绝对路径执行,要求文件有执行权限 2.以sh命令执行,不要求文件有执行权限 3..加空格或source命 ...
- Redis的五大数据类型(简单使用)
1:Redis的简单介绍? Redis(Remote Dictionary Server ):即远程字典服务 是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型Key-Val ...
- certbot申请泛域名证书并自动续签保姆级教程
certbot申请泛域名证书并自动续签(使用docker进行部署) 一.涉及到的资源及文档 1.云解析 - OpenAPI 概览:https://next.api.aliyun.com/documen ...
- UE5:相机震动CameraShake源码分析
本文将会分析UE5中相机震动的调用流程,会简要地分析UCameraModifier_CameraShake.UCameraShakeBase等相关类的调用过程. 阅读本文,你至少需要使用或者了解过Ca ...
- 文心一言 VS 讯飞星火 VS chatgpt (18)-- 算法导论4.1 5题
五.使用如下思想为最大子数组问题设计一个非递归的.线性时间的算法.从数组的左边界开始,由左至右处理,记录到目前为止已经处理过的最大子数组.若已知 A[1..j]门的最大子数组,基于如下性质将解扩展为 ...
- JavaScript异步编程3——Promise的链式使用
目录 概述 详论 1️⃣回调地狱 2️⃣Promise实现 参考 概述 在上一篇文章<JavaScript异步编程2--结合XMLHttpRequest使用Promise>中,简要介绍了A ...
- MySQL思维导图:MySQL的架构介绍
MySQL的架构介绍(思维导图形式) MySQL简介 概述 MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性. ...
- 第四部分_Shell脚本数组和其他变量
数组定义 ㈠ 数组分类 普通数组:只能使用整数作为数组索引(元素的下标) 关联数组:可以使用字符串作为数组索引(元素的下标) ㈡ 普通数组定义 可以切片 一次赋予一个值 #数组名[索引下标]=值 ar ...
- 手把手带你玩转HetuEngine:资源规划与数据源对接
本文分享自华为云社区<[手把手带你玩转HetuEngine](三)HetuEngine资源规划>,作者: HetuEngine九级代言 . HetuEngine支持在服务层角色实例和计算实 ...
- 小白必看!JS中循环语句大集合
摘要:JavaScript中,一共给开发者提供了一下几种循环语句,分别是while循环,do-while循环,for循环,for Each,for-in循环和for-of循环. 本文分享自华为云社区& ...