通过模仿学会Python爬虫(一):零基础上手
好家伙,爬虫来了
爬虫,这玩意,不会怎么办,
诶,先抄一份作业回来
1.别人的爬虫
Python爬虫史上超详细讲解(零基础入门,老年人都看的懂)_ChenBinBini的博客-CSDN博客
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的网页链接
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top250.xls" #当前目录新建XLS,存储进去
# dbpath = "movie.db" #当前目录新建数据库,存储进去
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容) request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存 if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_db("movietest.db")
print("爬取完毕!")
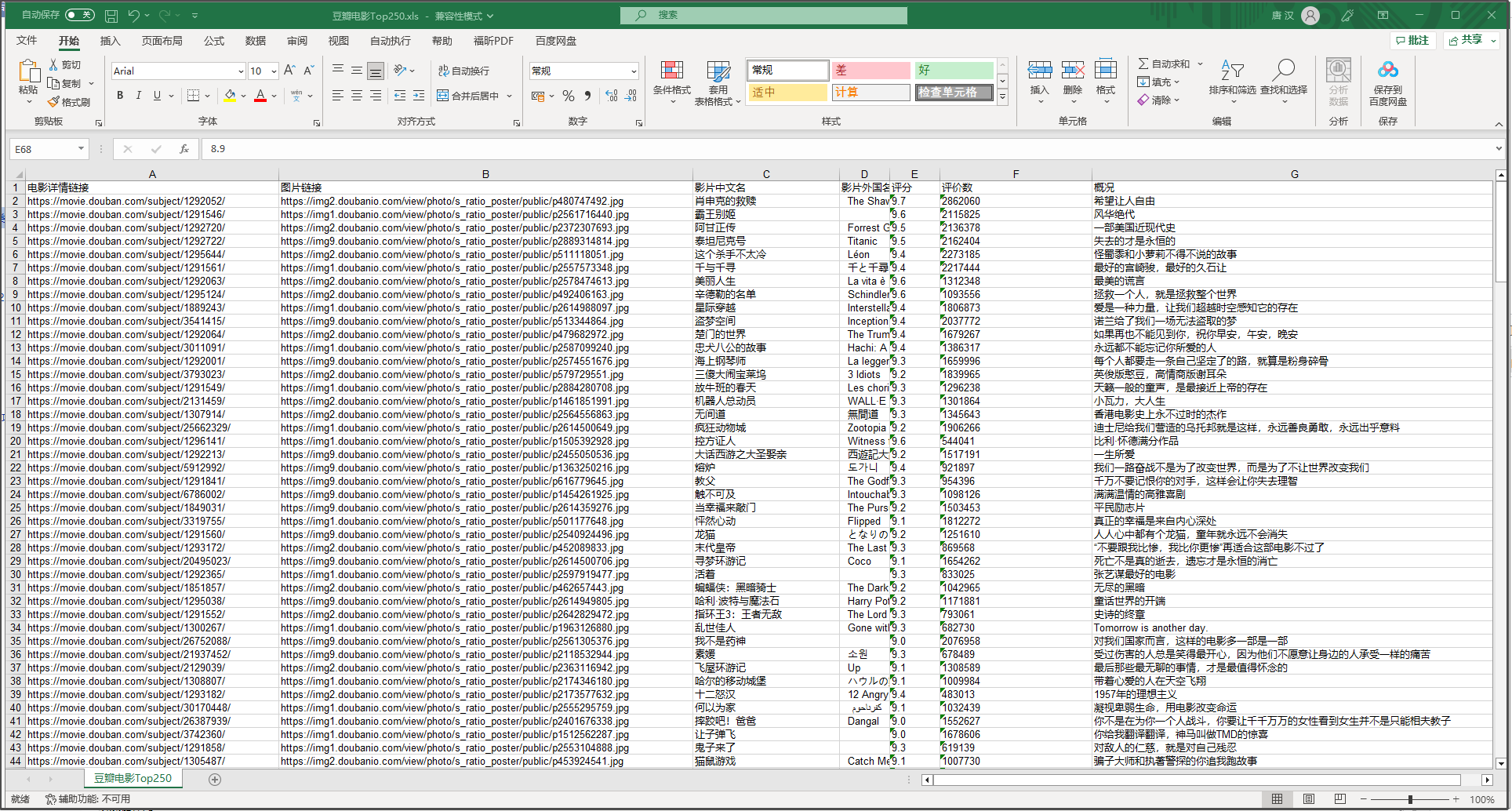
卧槽,有点东西
这东西看上去挺nb啊,
也很方便,把我想要的一些数据直接总结到一个excel表格中了
我们来看看这些字段是如何匹配的
.xls

代码:
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
<img>?<span>? 这不就专业对口了吗
网站的html:

将三个"表"都打开,再来看看对比

(诶都对上了)
此处,使用正则表达式去匹配对应标签
正则表达式 – 简介 | 菜鸟教程 (runoob.com)
于是看了这个案例之后,我们就可以大概去分析以下爬虫到底干了什么:
1.发请求,随后拿到服务器发过来的.html文件
2.用正则表达式去套对应的,我们需要的数据
3.处理数据,最后把他们以某种方式呈现
具体来说,爬虫通常会执行以下步骤:
发送HTTP请求:爬虫通过发送HTTP请求来获取目标网页的内容。
解析HTML页面:网页内容一般是HTML格式的,爬虫需要使用HTML解析器来将页面内容解析成Python对象。
提取数据:通过Python编程语言对解析出来的对象进行遍历和操作,找到需要的数据并保存下来。
存储数据:将提取的数据保存到文件中、数据库中或者内存中,以备后续的处理和分析。
处理异常:爬虫需要处理异常,例如:请求超时、解析错误等,以确保爬虫的稳定性和可靠性。
开干
2.我的爬虫
好了,我们自己写一个爬虫试试
import requests
from bs4 import BeautifulSoup
import xlwt
import re # 创建Excel文件
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet('kugou_rank')
# pattern = re.compile(r'(?<=- ).*') # 构造请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} # 定义排行榜页面的URL
url = 'https://www.kugou.com/yy/rank/home/1-6666.html?from=rank' # 发送请求并获取响应
r = requests.get(url, headers=headers) # 解析HTML
soup = BeautifulSoup(r.text, 'html.parser') # 定位歌曲排行榜列表
song_list = soup.find('div', {'class': 'pc_temp_songlist'}).find_all('li') # 将数据写入Excel文件
worksheet.write(0, 0, '排名') #写入对应的字段
worksheet.write(0, 1, '歌名')
worksheet.write(0, 2, '歌手')
worksheet.write(0, 3, '专辑')
worksheet.write(0, 4, '播放时长')
worksheet.write(0, 5, '链接地址') row = 1
for song in song_list:
song_name = song.find('a', {'class': 'pc_temp_songname'}).text.strip() #筛选出歌名
song_title = song.get('title')
singer_pattern = re.compile(r'.*(?= - )')
song_singer = singer_pattern.findall(song_title) song_title = song.get('title')
print(song_title)
album_pattern = re.compile(r'(?<=- ).*')
song_album = album_pattern.findall(song_title)
# song_album = pattern.findall(song)
song_time = song.find('span', {'class': 'pc_temp_time'}).text.strip() link_pattern = re.compile(r'href="(.*?)"') worksheet.write(row, 0, song['data-index']) #将排行写入excel表格
worksheet.write(row, 1, song_name) #将歌名写入excel表格
worksheet.write(row, 2, song_singer) #将歌手写入excel表格
worksheet.write(row, 3, song_album) #将歌曲专辑写入excel表格
worksheet.write(row, 4, song_time) #将歌曲时长写入excel表格
song =str(song)
song = song.split("javascript:")[0]
song_link = link_pattern.findall(song)
worksheet.write(row, 5, song_link) #将歌曲时长写入excel表格
row += 1 # 保存Excel文件 workbook.save('C:/Users/10722/Desktop/python答辩/kugou_rank.xls')
说明:
# 构造请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
带着请求头去请求,一个简单的"反爬"机制,模仿浏览器去发请求,非常实用
(其实没什么乱用,你能想到的,网站的开发者大概也能想到,所以你要是乱来还是会封你IP的)
没什么难度
这爬了酷狗的一个音乐榜单
然后记录了一些音乐数据,还有歌曲的地址。

还行,
通过模仿学会Python爬虫(一):零基础上手的更多相关文章
- Python学习课程零基础学Python
python学习课程,零基础Python初学者应该怎么去学习Python语言编程?python学习路线这里了解一下吧.想python学习课程?学习路线网免费下载海量python教程,上班族也能在家自学 ...
- python爬虫实战:基础爬虫(使用BeautifulSoup4等)
以前学习写爬虫程序时候,我没有系统地学习爬虫最基本的模块框架,只是实现自己的目标而写出来的,最近学习基础的爬虫,但含有完整的结构,大型爬虫含有的基础模块,此项目也有,“麻雀虽小,五脏俱全”,只是没有考 ...
- 【Python爬虫】HTTP基础和urllib库、requests库的使用
引言: 一个网络爬虫的编写主要可以分为三个部分: 1.获取网页 2.提取信息 3.分析信息 本文主要介绍第一部分,如何用Python内置的库urllib和第三方库requests库来完成网页的获取.阅 ...
- python爬虫——web前端基础(1)
1.HTML的基本结构 <html>内容</html>:HTML文档是由<html></html>包裹,这是HTML文档的文档标记,也称为HTML开始标 ...
- 【Python爬虫】selenium基础用法
selenium 基础用法 阅读目录 初识selenium 基本使用 查找元素 元素互交操作 执行JavaScript 获取元素信息 等待 前进后退 Cookies 选项卡管理 异常处理 初识sele ...
- Python爬虫 requests库基础
requests库简介 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支 ...
- Python爬虫----Beautiful Soup4 基础
1. Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyth ...
- 函数:Python的乐高积木 - 零基础入门学习Python017
函数:Python的乐高积木 让编程改变世界 Change the world by program 相信大家小时候应该都玩过神奇的乐高积木,只要通过想象和创意,我们可以用它拼凑出很多神奇的东西. 随 ...
- 闲聊之Python的数据类型 - 零基础入门学习Python005
闲聊之Python的数据类型 让编程改变世界 Change the world by program Python的数据类型 闲聊之Python的数据类型所谓闲聊,goosip,就是屁大点事可以咱聊上 ...
- python爬虫——web前端基础(4)
CSS,指层叠样式表,用来定义如何显示HTML元素,一般和HTML配合使用. 在HTML中使用CSS样式的方法: 内联样式表:CSS代码直接写在现有的HTML标记中,直接使用style属性改变样式.例 ...
随机推荐
- 【深入浅出 Yarn 架构与实现】6-2 NodeManager 状态机管理
一.简介 NodeManager(NM)中的状态机分为三类:Application.Container 和 LocalizedResource,它们均直接或者间接参与维护一个应用程序的生命周期. 当 ...
- 长达 1.7 万字的 explain 关键字指南!
当你的数据里只有几千几万,那么 SQL 优化并不会发挥太大价值,但当你的数据里去到了几百上千万,SQL 优化的价值就体现出来了!因此稍微有些经验的同学都知道,怎么让 MySQL 查询语句又快又好是一件 ...
- day02-搭建微服务基础环境01
搭建微服务基础环境01 1.创建父工程,用于聚合其他微服务模块 1.1创建父项目 说明:我们先创建一个父项目,该父项目会去管理多个微服务模块(module),如下: (1)File-New-Proje ...
- [MyBatis]问题:ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
错误信息 ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging onl ...
- 逍遥自在学C语言 | 位运算符^的高级用法
前言 在上一篇文章中,我们介绍了|运算符的高级用法,本篇文章,我们将介绍^ 运算符的一些高级用法. 一.人物简介 第一位闪亮登场,有请今后会一直教我们C语言的老师 -- 自在. 第二位上场的是和我们一 ...
- php 中文地址伪静态,.htaccess实现含中文的url伪静态跳转
Tags伪静态 RewriteRule ^tags.html/tags.php RewriteRule ^tags/(.)(??.))*.html$ tags.php?/$1 RewriteRule ...
- 实现声明式锁,支持分布式锁自定义锁、SpEL和结合事务
目录 2.实现 2.1 定义注解 2.2 定义锁接口 2.3 锁的实现 2.3.1 什么是SPI 2.3.2 通过SPI实现锁的多个实现类 2.3.3 通过SPI自定义实现锁 3.定义切面 3.1 切 ...
- odoo 开发入门教程系列-QWeb简史
QWeb简史 到目前为止,我们的房地产模块的界面设计相当有限.构建列表视图很简单,因为只需要字段列表.表单视图也是如此:尽管使用了一些标记,如<group>或<page>,但在 ...
- 设计模式之[构建者模式(Builder)]-C#
说明:构建一个大对象时,可以分解成一个部分一个部分的构建,比如一台电脑由CUP.内存.主板.屏幕等,这些配件本身就是一个复杂的制造过程,一个一个构建后然后才组装成一台新的电脑. 步骤 1.定义要构建的 ...
- 数据分析04-pandas(apply函数、排序、数据合、分组聚合、透视表、交叉表及项目分析)
数据分析-04 排序 按标签(行)排序 按标签(列)排序 按某列值排序 数据合并 concat merge & join 分组聚合 分组 聚合 透视表与交叉表 透视表 交叉表 项目:分析影响学 ...