【可视化大屏】用Python开发「淄博烧烤」微博热评舆情分析大屏
一、开发背景
您好,我是@马哥python说 ,一枚10年程序猿。
自从2023.3月以来,"淄博烧烤"现象持续占领热搜流量,体现了后疫情时代众多网友对人间烟火气的美好向往,本现象级事件存在一定的数据分析实践意义。
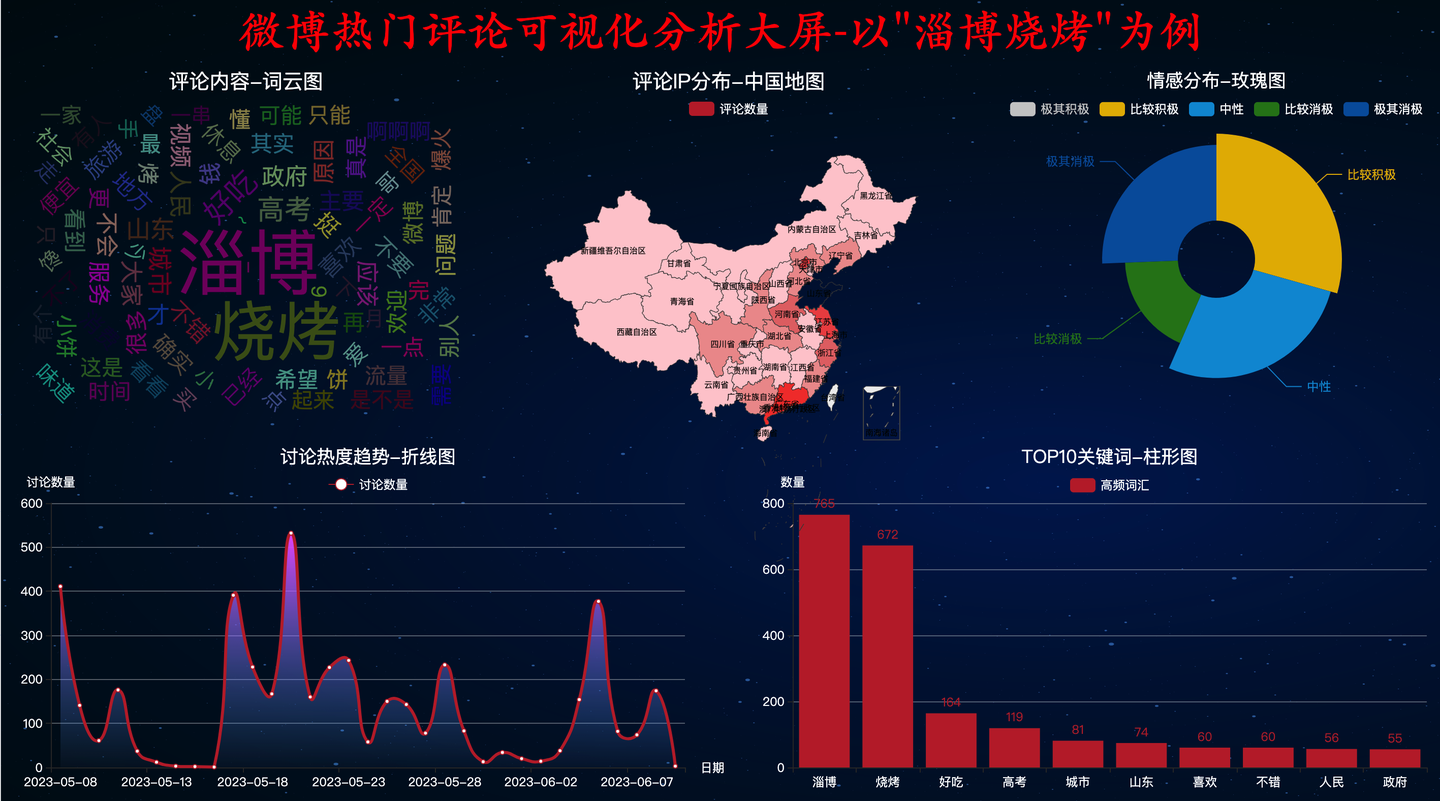
静态截图:
动态演示:
【大屏演示】Python可视化舆情大屏「淄博烧烤」
二、爬虫代码
2.1 爬微博列表
通过m端的搜索页面,爬取以"淄博烧烤"为关键词的微博id,获取到微博id的目的,是传给评论爬虫。
发送请求部分:
# 请求地址
url = 'https://m.weibo.cn/api/container/getIndex'
# 请求参数
params = {
"containerid": "100103type=60&q={}".format(v_keyword),
"page_type": "searchall",
"page": page
}
# 发送请求
r = requests.get(url, headers=headers, params=params)
注意,type=60代表"热门",如下:

解析数据部分:
# 解析json数据
cards = r.json()["data"]["cards"]
print('微博数量:', len(cards))
for card in cards:
# 微博id
id_list = card['mblog']['id']
id_list_list.append(id_list)
至此,已经获取到以「淄博烧烤」为关键词的微博id列表 id_list_list 了。
2.2 爬微博评论
从2.1章节获取到微博id列表之后,传入爬取微博评论函数 get_comments
这部分爬虫讲解可移步:
【2023微博评论爬虫】用python爬上千条微博评论,突破15页限制!
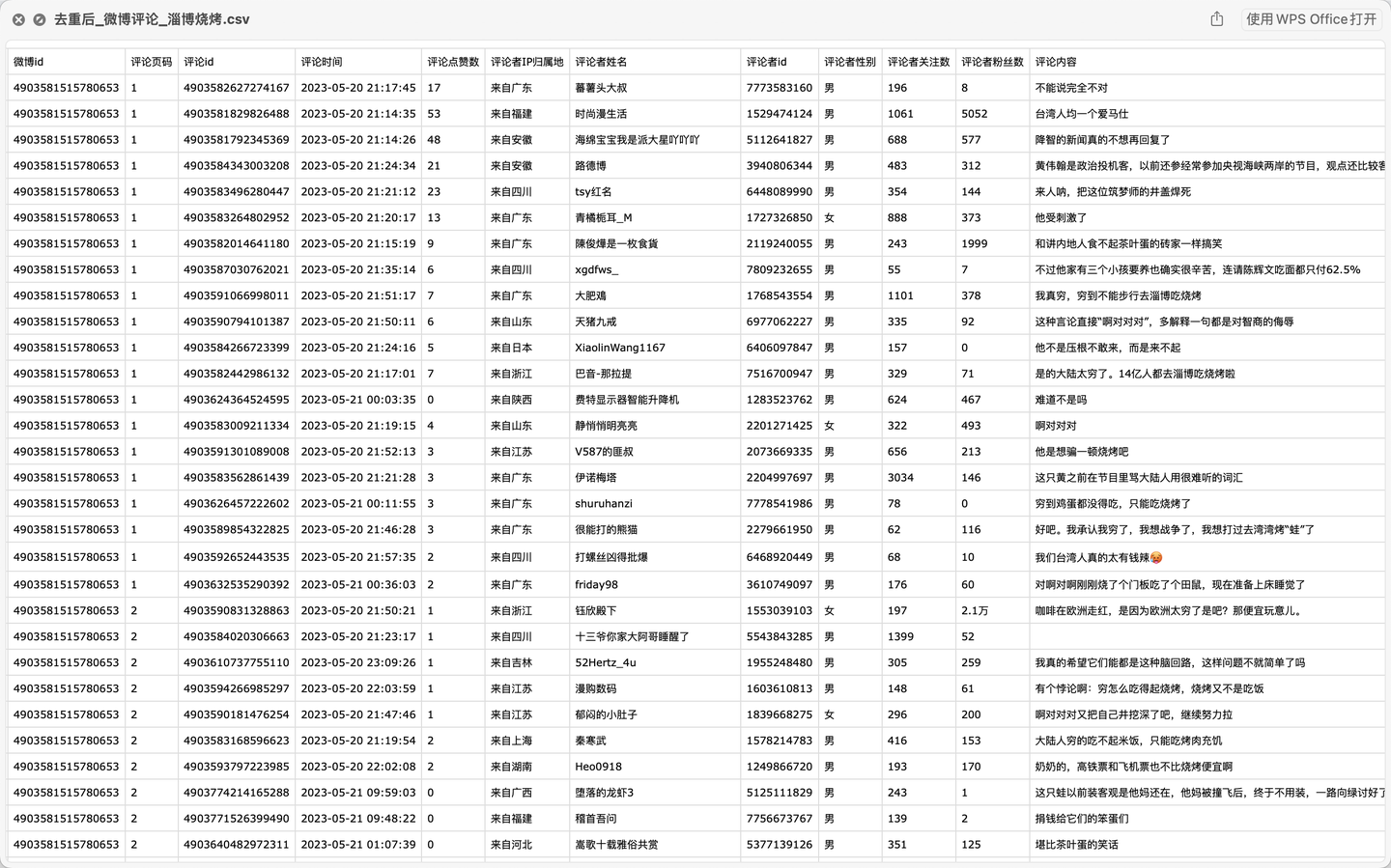
最终,爬取到的微博评论数据,示例如下:
说明:无论微博搜索页,还是微博评论页,都可以自定义设置max_page,满足自己的个性化数据量要求。
2.3 导入MySQL数据库
最核心的三行代码:
# 读取csv数据
df = pd.read_csv('去重后_' + comment_file)
# 把csv数据导入MySQL数据库
df.to_sql(name='t_zbsk', con=engine, chunksize=1000, if_exists='replace', index=False)
print('导入数据库完成!')
用create_engine创建数据库连接,格式为:
create_engine('数据库类型+数据库驱动://用户名:密码@数据库IP地址/数据库名称')
这样,数据库连接就创建好了。
然后,用pandas的read_csv函数读取csv文件。
最后,用pandas的to_sql函数,把数据存入MySQL数据库:
- name='college_t2' #mysql数据库中的表名
- con=engine # 数据库连接
- index=False #不包含索引字段
- if_exists='replace' #如果表中存在数据,就替换掉
非常方便地完成了反向导入,即:从csv向数据库的导入。
这个部分的讲解视频:
仅用Python三行代码,实现数据库和excel之间的导入导出!
三、可视化代码
3.1 大标题
由于pyecharts组件没有专门用作标题的图表,我决定灵活运用Line组件实现大标题。
首先,找到一张星空图作为大屏背景图:

然后,在Line组件中加入js代码,加载背景图:
# 设置背景图片
line3.add_js_funcs(
"""
var img = new Image(); img.src = './static/bg2.png';
"""
)
大标题效果如下:

3.2 词云图(含:加载停用词)
绘制词云图,需要先进行中文分词。既然分词,就要先设置停用词,避免干扰词影响分析结果。
这里采用哈工大停用词作为停用词词典。
# 停用词列表
with open('hit_stopwords.txt', 'r') as f:
stopwords_list = f.readlines()
stopwords_list = [i.strip() for i in stopwords_list]
这样,所有停用词就存入stopwords_list这个列表里了。
如果哈工大停用词仍然无法满足需求,再加入一些自定义停用词,extend到这个列表里:
# 加入自定义停用词
stopwords_list.extend(
['3', '5', '不', '都', '好', '人', '吃', '都', '去', '想', '说', '还', '很', '…', 'nan', '真的', '不是',
'没', '会', '看', '现在', '觉得', ' ', '没有', '上', '感觉', '大', '太', '真', '哈哈哈', '火', '挖', '做',
'一下', '不能', '知道', '这种', '快'])
现在就可以愉快的绘制词云图了,部分核心代码:
wc = WordCloud(init_opts=opts.InitOpts(width='600px', height=chart_height, theme=theme_config, chart_id='wc1'))
wc.add(series_name="评论内容",
data_pair=data300,
word_gap=1,
word_size_range=[20, 70],
) # 增加数据
wc.set_global_opts(
title_opts=opts.TitleOpts(pos_left='center',
pos_top='0%',
title=v_title,
title_textstyle_opts=opts.TextStyleOpts(font_size=20, color=title_color) # 设置标题
),
tooltip_opts=opts.TooltipOpts(is_show=True), # 显示提示
)
词云图效果:

3.3 玫瑰图(含:snownlp情感分析)
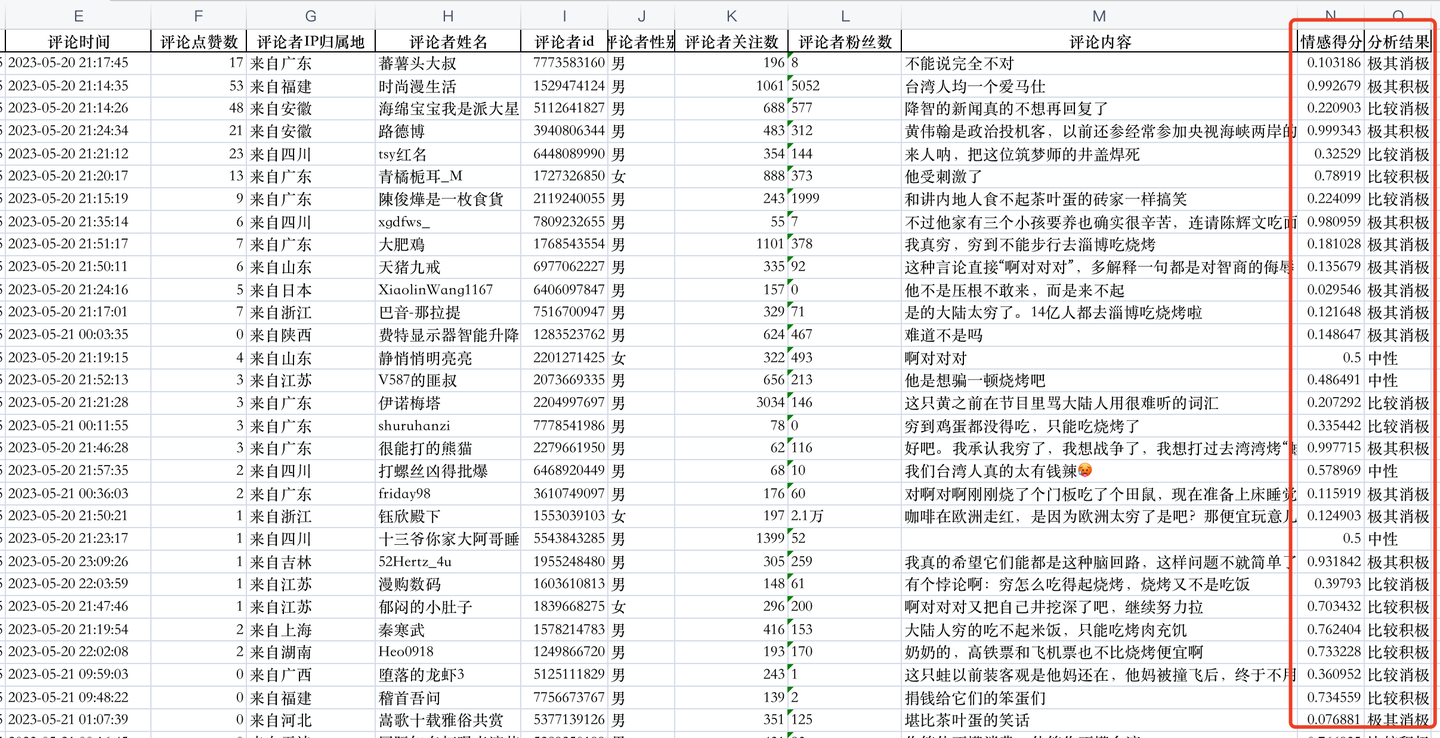
先对评论数据进行情感判定,采用snownlp技术进行情感打分及判定结果:
for comment in cmt_list:
sentiments_score = SnowNLP(comment).sentiments
if 0 <= sentiments_score < 0.2: # 情感分小于0.2,判定为极其消极
tag = '极其消极'
neg_very_count += 1
elif 0.2 <= sentiments_score < 0.4: # 情感分在0.2和0.4之间,判定为比较消极
tag = '比较消极'
neg_count += 1
elif 0.4 <= sentiments_score < 0.6: # 情感分在0.4和0.6之间,判定为中性
tag = '中性'
mid_count += 1
elif 0.6 <= sentiments_score < 0.9: # 情感分在0.6和0.9之间,判定为比较积极
tag = '比较积极'
pos_count += 1
else: # 情感分大于0.9,判定为极其积极
tag = '极其积极'
pos_very_count += 1
将情感分析结果用pandas保存到一个Excel文件里,如下:
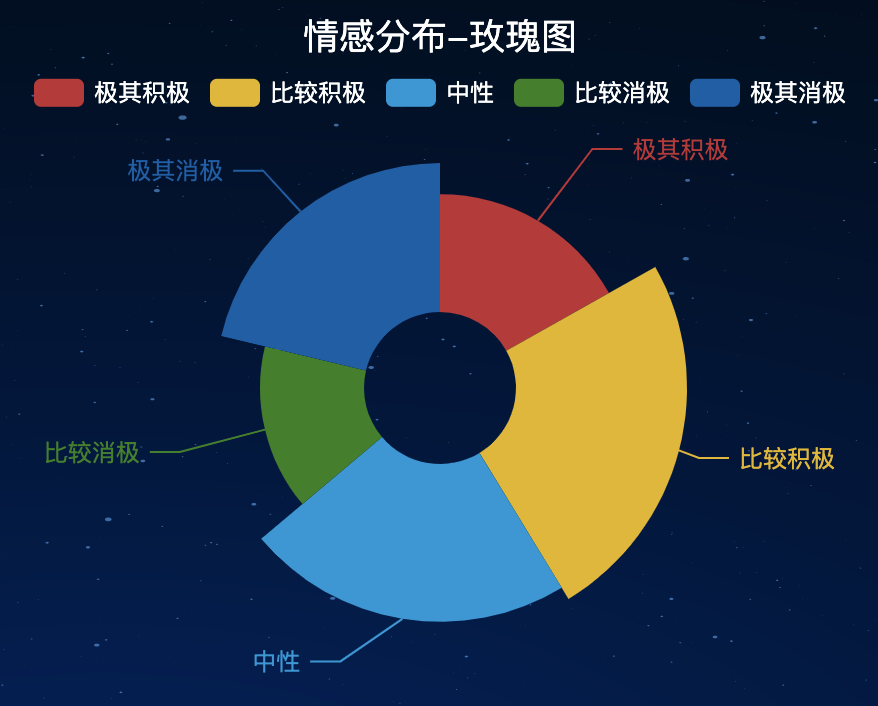
绘制玫瑰图,部分核心代码:
# 画饼图
pie = (
Pie(init_opts=opts.InitOpts(theme=theme_config, width=chart_width, height=chart_height, chart_id='pie1'))
.add(series_name="情感分类", # 系列名称
data_pair=[ # 添加数据
['极其积极', pos_very_count],
['比较积极', pos_count],
['中性', mid_count],
['比较消极', neg_count],
['极其消极', neg_very_count],
],
rosetype="radius", # 是否展示成南丁格尔图
radius=["20%", "65%"], # 扇区圆心角展现数据的百分比
) # 加入数据
.set_global_opts( # 全局设置项
title_opts=opts.TitleOpts(title=v_title,
pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(color=title_color, ), ), # 标题
legend_opts=opts.LegendOpts(pos_left='center', pos_top='8%', orient='horizontal',
textstyle_opts=opts.TextStyleOpts(color='white', )) # 图例字体颜色
)
)
玫瑰图效果:
3.4 柱形图-TOP10关键词
先根据词云图部分提取出TOP10高频词(过滤掉停用词之后的):
data10 = collections.Counter(result).most_common(10)
然后带入柱形图,部分核心代码:
# 画柱形图
bar = Bar(
init_opts=opts.InitOpts(theme=theme_config, width='780px', height=chart_height,
chart_id='bar1')) # 初始化条形图
bar.add_xaxis(x_data) # 增加x轴数据
bar.add_yaxis("高频词汇", y_data) # 增加y轴数据
bar.set_series_opts(label_opts=opts.LabelOpts(position="top")) # Label出现位置
bar.set_global_opts(。。。)
柱形图效果:
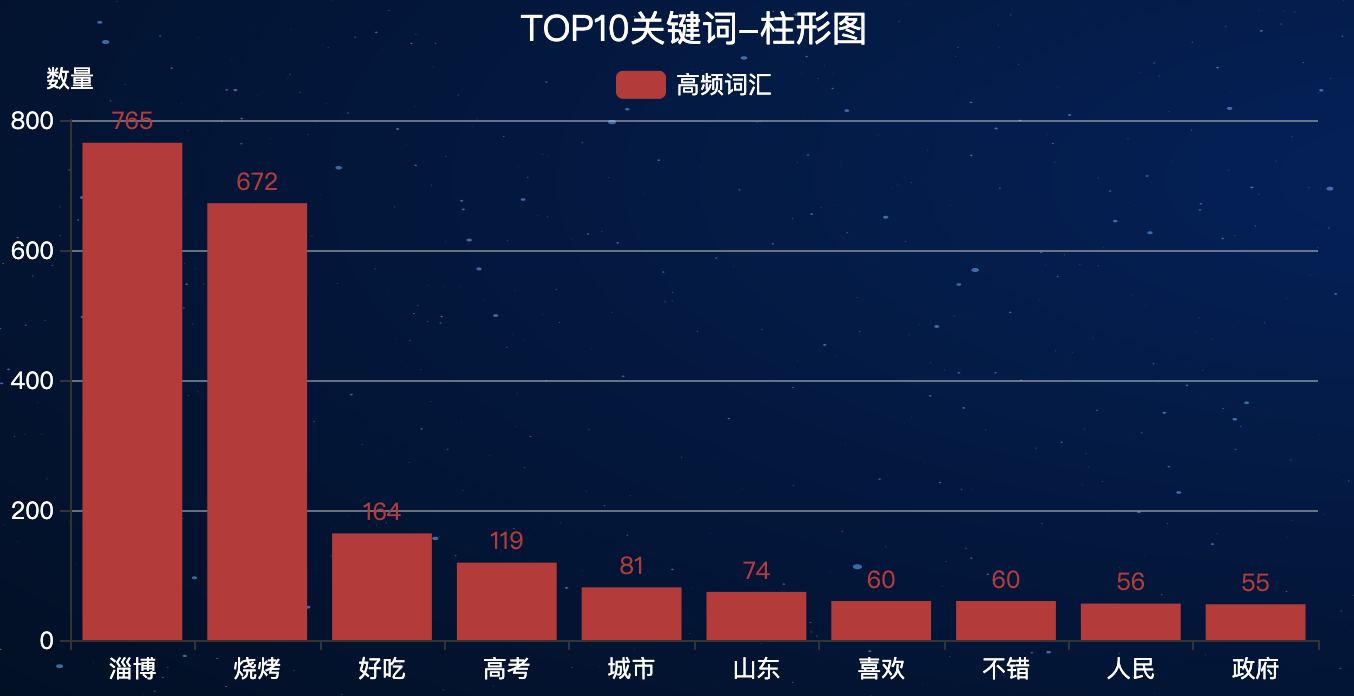
3.5 折线图-讨论热度趋势
首先,根据评论时间统计出每天的微博评论数量:
# 按日期分组统计评论数量
df_comments['评论日期'] = df_comments['评论时间'].astype(str).str[:10] # 提取日期
grp = df_comments.groupby('评论日期')['评论内容'].count()
然后,根据统计数据画出折线图,部分核心代码:
line = Line(
init_opts=opts.InitOpts(width='780px', height=chart_height, theme=theme_config, chart_id='line1')) # 实例化
line.add_xaxis(x_data) # 加入X轴数据
line.add_yaxis('讨论数量', y_data, is_smooth=True,
areastyle_opts=opts.AreaStyleOpts(color=JsCode(area_color_js), opacity=1), ) # 加入Y轴数据
line.set_global_opts(。。。)
折线图效果:
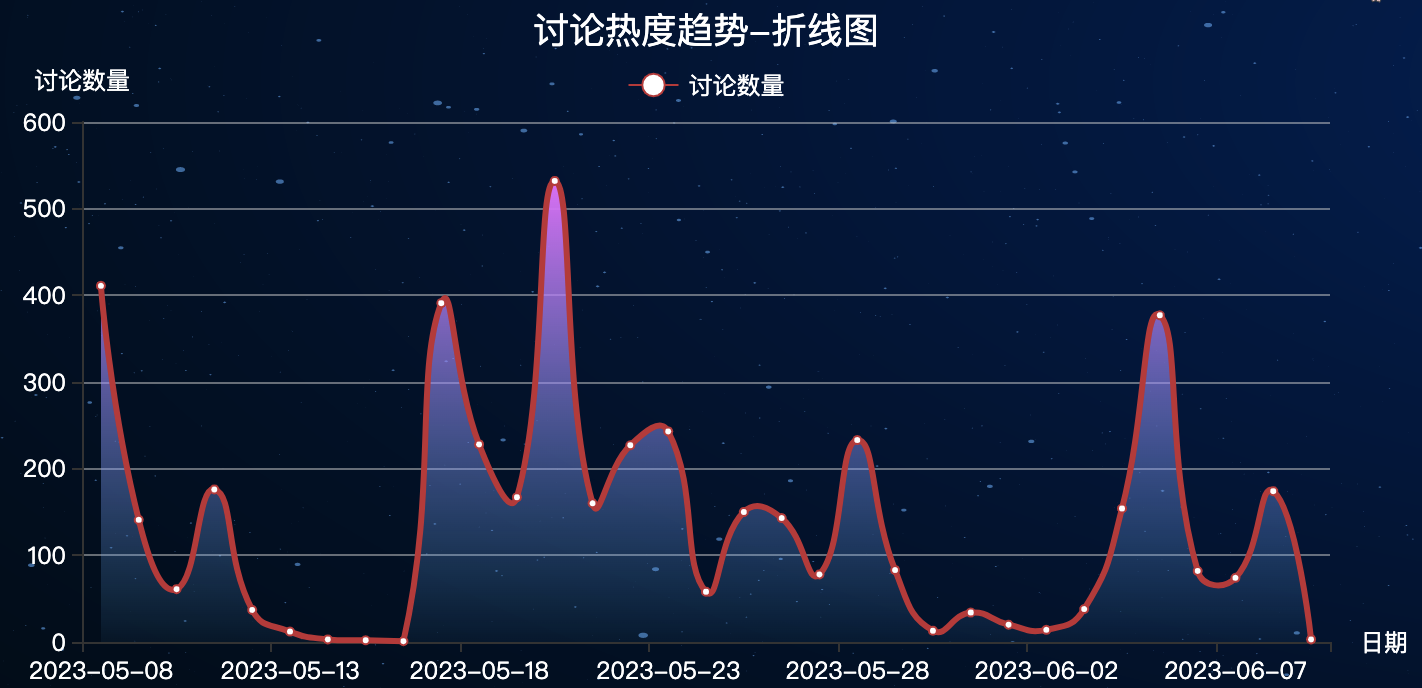
3.6 地图-IP分布
由于IP属地字段都包含"来自"两字,先进行数据清洗,将"来自"去掉:
# 数据清洗-ip属地
ip_count = df_comments['评论者IP归属地'].str.replace('来自', '')
然后统计各个IP属地的数量,方便后续带入地图可视化:
# 统计各IP数量
ip_count = ip_count.value_counts()
下面开始绘制地图,部分核心代码:
f_map = (
Map(init_opts=opts.InitOpts(width='600px',
height='600px',
theme=theme_config,
page_title=v_title,
chart_id='map1',
bg_color=None))
.add(series_name="评论数量",
data_pair=list(zip(loc_list, value_list)),
maptype="china", # 地图类型
is_map_symbol_show=False)
.set_global_opts(。。。)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, font_size=8, ),
markpoint_opts=opts.MarkPointOpts(
symbol_size=[90, 90], symbol='circle'),
effect_opts=opts.EffectOpts(is_show='True', )
)
)
地图效果,如下:
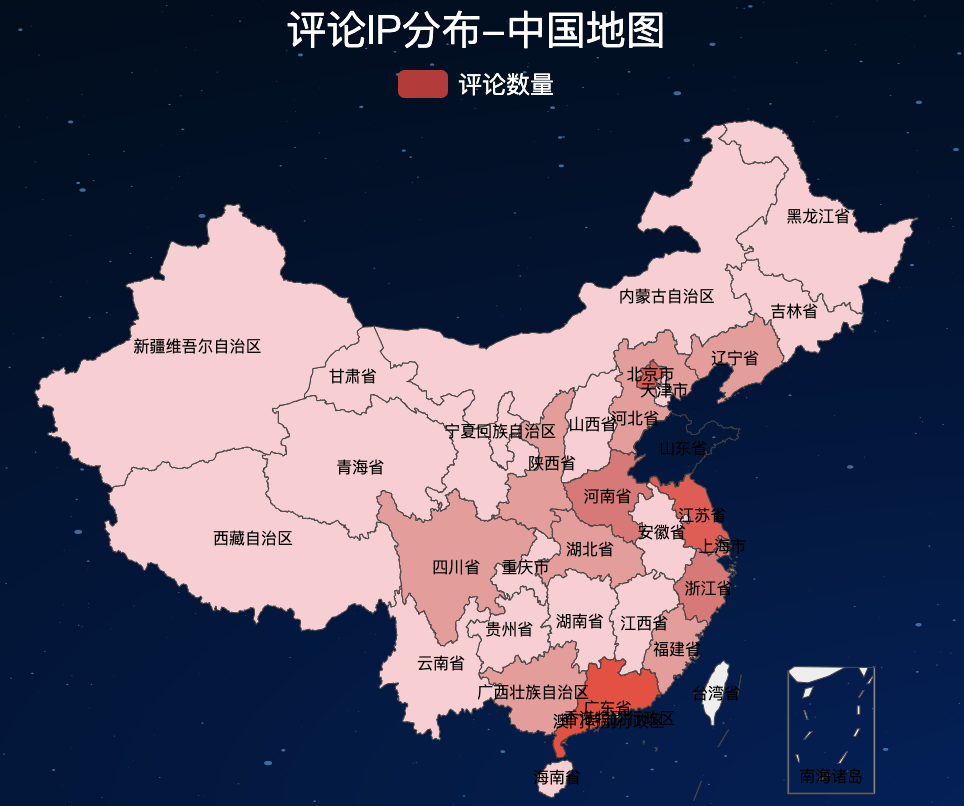
当然,地图中的颜色,都是自己设置的十六进制颜色,可以根据自己的喜好更改。
3.7 Page组合大屏
最后,也是最关键的一步,把以上所有图表组合到一起,用Page组件,并且选用DraggablePageLayout方法,即拖拽的方式,组合图表:
# 绘制:整个页面
page = Page(
page_title='微博热门评论可视化分析大屏-以"淄博烧烤"为例',
layout=Page.DraggablePageLayout,
)
page.add(
# 绘制:大标题
make_title(v_title='微博热门评论可视化分析大屏-以"淄博烧烤"为例'),
# 绘制:词云图
make_wordcloud(v_title='评论内容-词云图'),
# 绘制:饼图
make_analyse_pie(v_title='情感分布-玫瑰图'),
# 绘制:柱形图
make_bar(v_title='TOP10关键词-柱形图'),
# 绘制:折线图
make_line(v_title='讨论热度趋势-折线图'),
# 绘制:地图
make_map(v_title='评论IP分布-中国地图'),
)
page.render('大屏_临时.html')
本代码执行完毕后,打开临时html并排版,排版完点击Save Config,把json文件放到本目录下。
再执行最后一步,调用json配置文件,生成最终大屏文件。
Page.save_resize_html(
source="大屏_临时.html", # 源html文件
cfg_file="chart_config.json", # 配置文件
dest="大屏_最终.html" # 目标html文件
)
至此,所有代码执行完毕,生成了最终大屏html文件。
四、彩蛋-多种颜色主题
分享一个小技巧,我设置了一键更换颜色主题:
# 整体主题颜色
theme_config = ThemeType.SHINE
只需更换ThemeType参数,即可实现一键更换主题!
4.1 INFOGRAPHIC主题
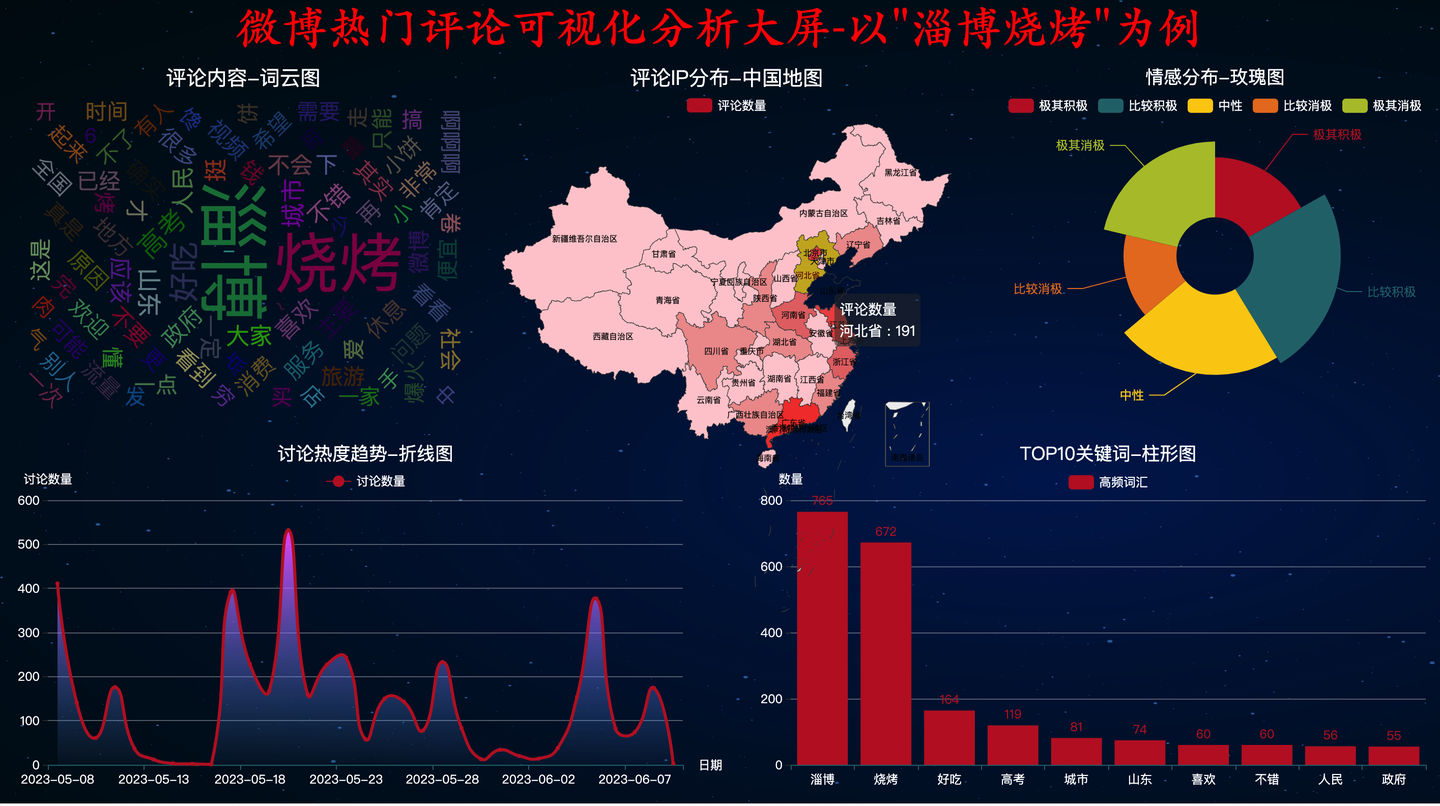
4.2 MACARONS主题
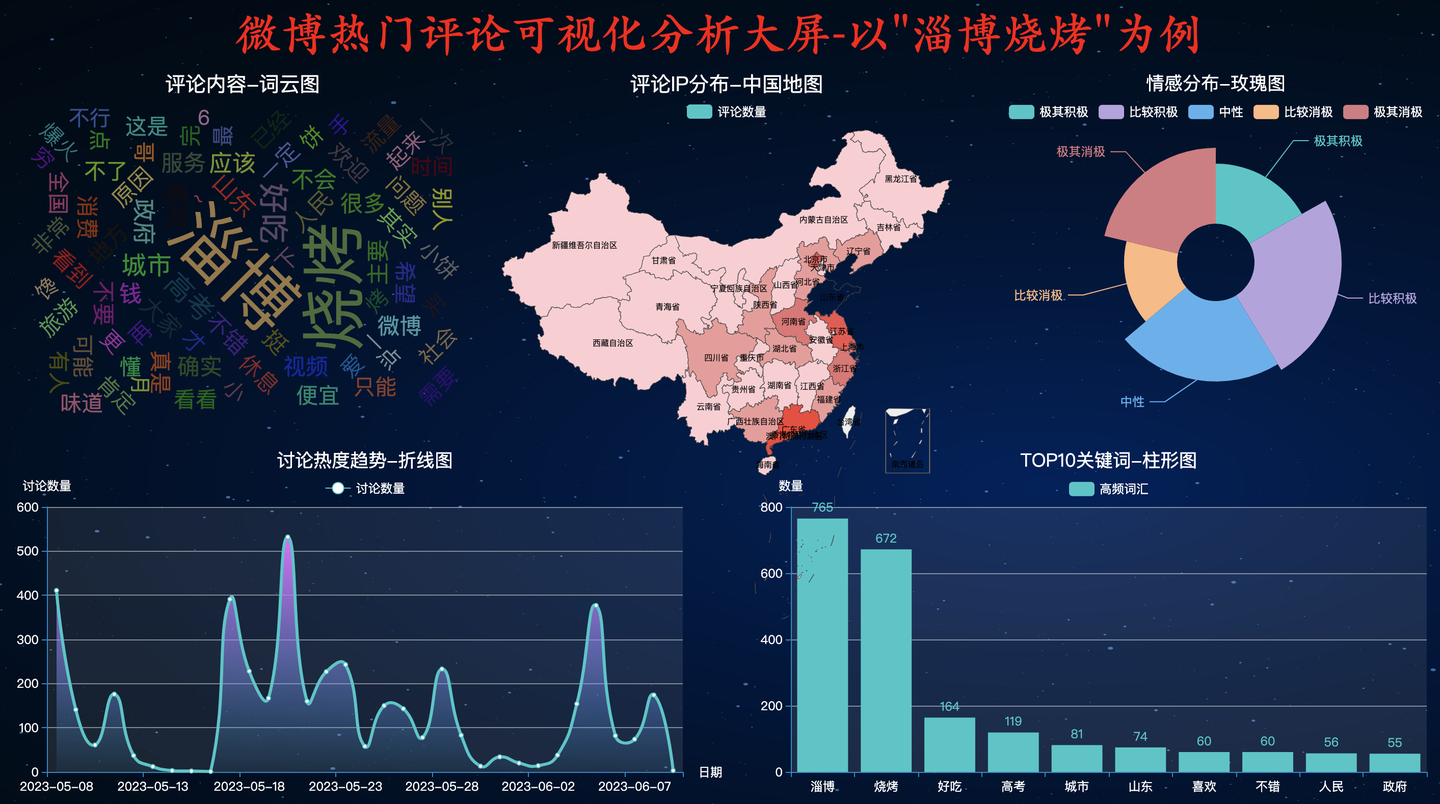
4.3 SHINE主题
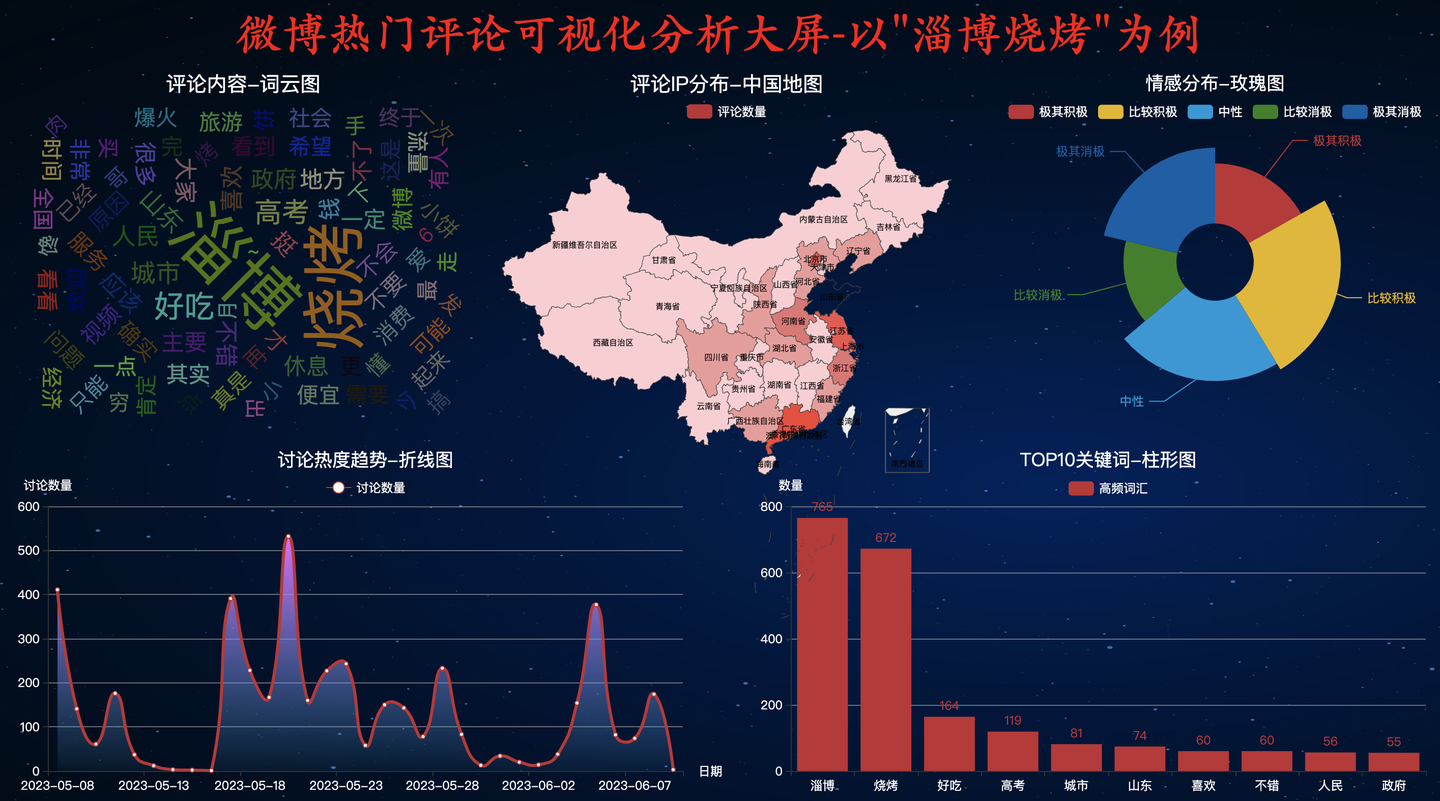
4.4 WALDEN主题
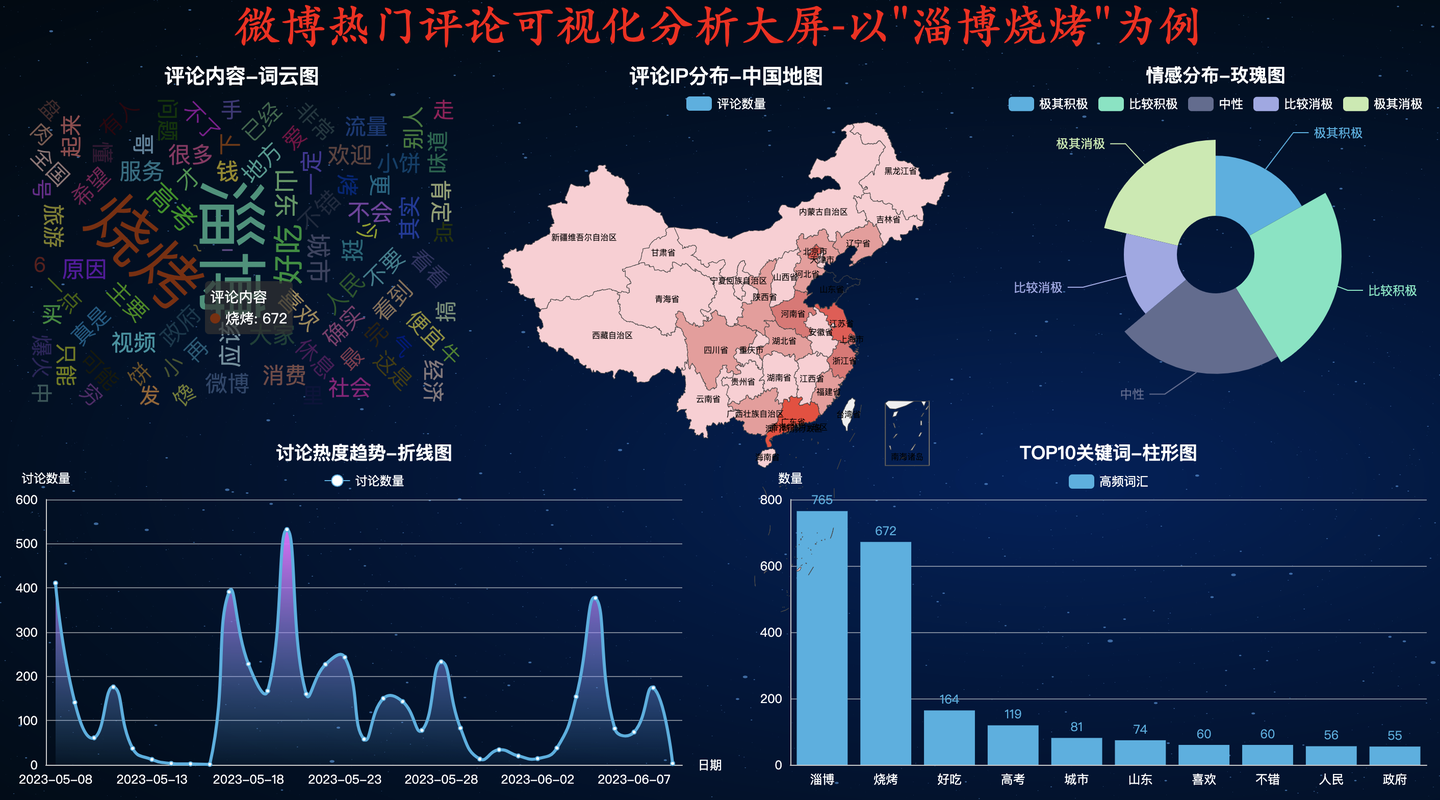
4.5 WESTEROS主题
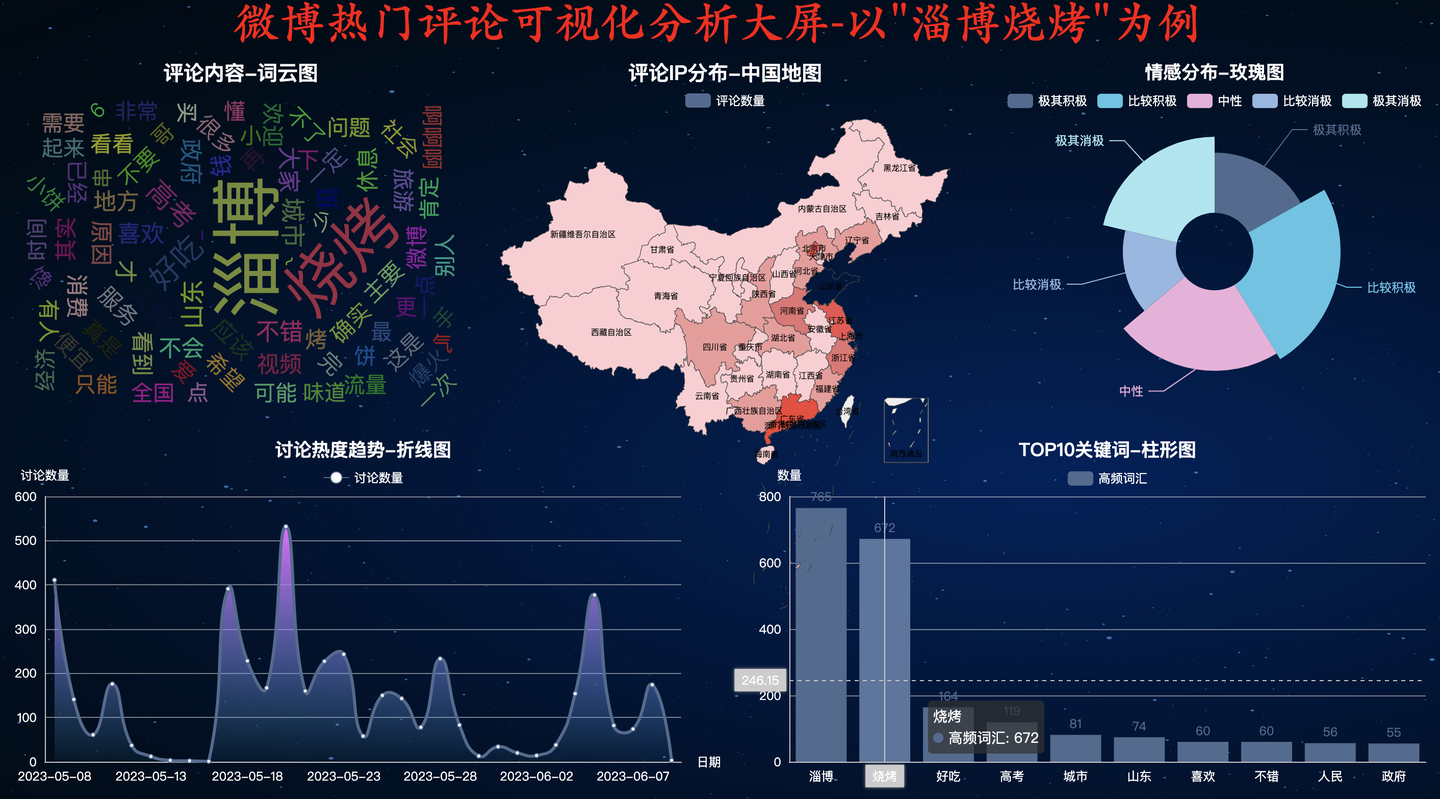
4.6 WHITE主题
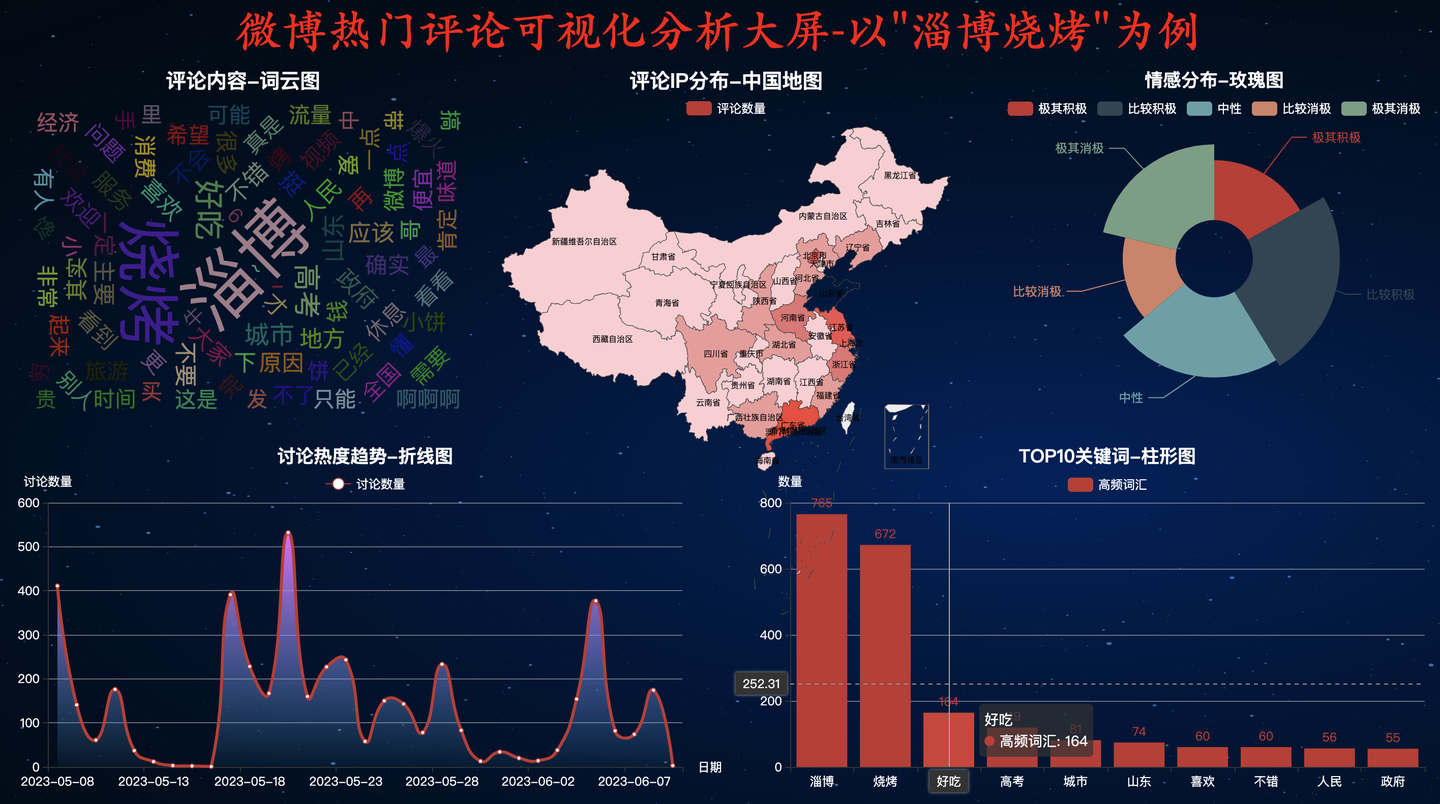
4.7 WONDERLAND主题
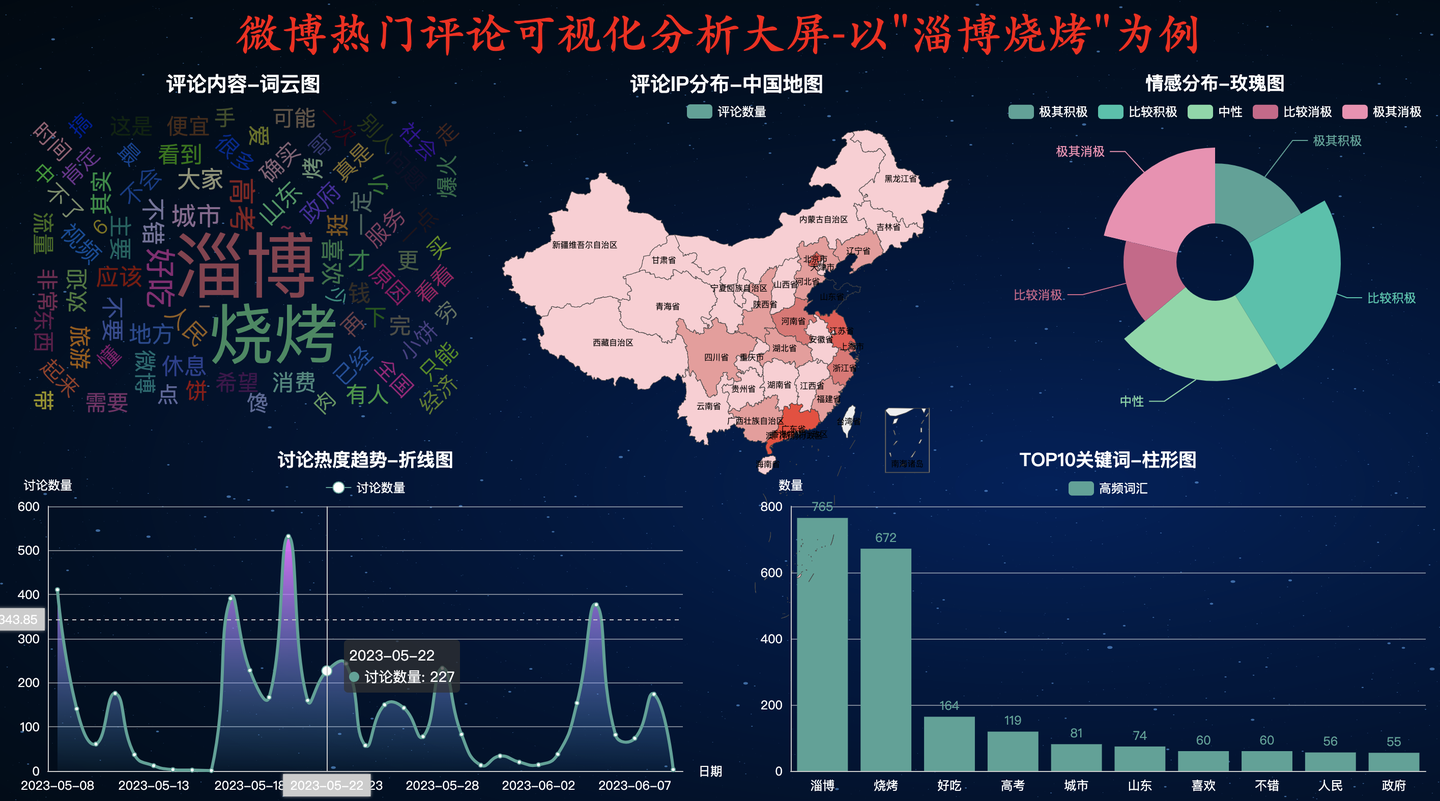
更多颜色主题等待小伙伴去发掘!
五、技术总结
技术开发流程:
- requests 爬虫发送请求
- json 解析返回数据
- re 正则表达式清洗文本
- pandas保存csv文件
- sqlalchemy 保存MySQL数据
- pyecharts 可视化开发
- snownlp 情感分析
- jieba 中文分词
- pyecharts+page 组合大屏
- flask 启动网页服务
六、在线体验
为了方便大家体验可视化动态交互效果,我把此大屏部署到了服务器,请移步:
马哥python说 - 效果演示
七、演示视频
效果演示视频:
【大屏演示】Python可视化舆情大屏「淄博烧烤」
八、获取完整源码
附完整源码:【可视化大屏】“淄博烧烤”热评舆情分析大屏
我是 @马哥python说 ,持续分享python源码干货中!
【可视化大屏】用Python开发「淄博烧烤」微博热评舆情分析大屏的更多相关文章
- 数据可视化开源系统(python开发)
Caravel 是 Airbnb (知名在线房屋短租公司)开源的数据探查与可视化平台(曾用名Panoramix),该工具在可视化.易用性和交互性上非常有特色,用户可以轻松对数据进行可视化分析. 核心功 ...
- Android 性能优化(2)性能工具之「Hierarchy Viewer 」Optimizing Your UI:分析哪个view有性能问题,查看屏幕上某像素点的坐标,颜色等
Optimizing Your UI In this document Using Hierarchy Viewer Running Hierarchy Viewer and choosing a w ...
- Mditor 发布「桌面版」了 - http://mditor.com
简单说明 Mditor 最早只有「组件版」,随着「桌面版」的发布,Mditor 目前有两个版本: 可嵌入到任意 Web 应用的 Embed 版本,这是一桌面版的基础,Repo: https://git ...
- 分享开源 Markdown 编辑器 Mditor 的「桌面版」
简单说明 Mditor 最早只有「组件版」,随着「桌面版」的发布,Mditor 目前有两个版本: 可嵌入到任意 Web 应用的 Embed 版本,这是一桌面版的基础,Repo: https://git ...
- 【可视化大屏教程】用Python开发智慧城市数据分析大屏!
目录 一.开发背景 二.讲解代码 2.1 大标题+背景图 2.2 各区县交通事故统计图-系列柱形图 2.3 图书馆建设率-水球图 2.4 当年城市空气质量aqi指数-面积图 2.5 近7年人均生产总值 ...
- 【Python开发】Python 适合大数据量的处理吗?
Python 适合大数据量的处理吗? python 能处理数据库中百万行级的数据吗? 处理大规模数据时有那些常用的python库,他们有什么优缺点?适用范围如何? 需要澄清两点之后才可以比较全面的看这 ...
- 常用的十大Python开发工具
据权威机构统计,Python人才需求量每日高达5000+,但目前市场上会 Python 的程序员少之又少, 竞争小,很容易快速高薪就业.可能你并不太了解常用的十大Python开发工具都有哪些,现在告诉 ...
- Web 开发和数据科学家仍是 Python 开发的两大主力
由于 Python 2 即将退役,使用 Python 3 的开发者大约为 90%,Python 2 的使用量正在迅速减少.而去年仍有 1/4 的人使用 Python 2. Web 开发和数据科学家仍是 ...
- 手把手教你快速使用数据可视化BI软件创建全球经济贸易分析大屏
灯果数据可视化BI软件是新一代人工智能数据可视化大屏软件,内置丰富的大屏模板,可视化编辑操作,无需任何经验就可以创建属于你自己的大屏.大家可以在他们的官网下载软件. 本文以全球经济贸易分析大屏为例 ...
- 【Python 04】Python开发环境概述
1.Python概述 Python是一种计算机程序设计语言,一个python环境中需要有一个解释器和一个包集合. (1)Python解释器 使用python语言编写程序之前需要下载一个python解释 ...
随机推荐
- Java 安全指南
Java 安全指南 后台类 I. 代码实现 1.1 数据持久化 1.1.1[必须]SQL语句默认使用预编译并绑定变量 Web后台系统应默认使用预编译绑定变量的形式创建sql语句,保持查询语句和数据相分 ...
- 记一次在forEach中使用aynac/await中的坑
1.背景 在写一个对齐脚本时 发现下列问题 const timeList = await imageList.map( (item,index)=>{ return item.identify_ ...
- 监听watch踏坑之旅!!!vuex中如果数组发生变换但是用watch你监听不到
vuex: SET_INFO(state,info) { console.log('info',info) state.info.unshift(info) state.info.pop() cons ...
- 搭建react的架手架
1.回顾 cnpm i @vue/cli -g ----- 4的脚手架 ------ webpack 4 cnpm i @vue/cli@3 -g ----- 3的脚手架 ------ webpack ...
- AIGC时代:未来已来
摘要:人工智能的快速发展使得我们进入了AIGC时代.AIGC时代的到来,将会带来巨大的机遇和挑战. 本文分享自华为云社区<GPT-4发布,AIGC时代的多模态还能走多远?系列之一: AIGC时代 ...
- 导致sql注入的根本原因
导致sql注入的根本原因 1.sql注入的定义 SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在 ...
- PVE Cloud-INIT 模板配置
PVE Cloud-INIT 模板配置 Cloud-init是什么 Cloud-init是开源的云初始化程序,能够对新创建弹性云服务器中指定的自定义信息(主机名.密钥和用户数据等)进行初始化配置.通过 ...
- 如何在Java中做基准测试?JMH使用初体验
大家好,我是王有志,欢迎和我聊技术,聊漂泊在外的生活.快来加入我们的Java提桶跑路群:共同富裕的Java人. 最近公司在搞新项目,由于是实验性质,且不会直接面对客户的项目,这次的技术选型非常激进,如 ...
- [大数据]Hadoop HDFS文件系统命令集
基本格式: hadoop fs -cmd [args] 1 Query 显示命令的帮助信息 # hadoop fs -help [cmd] 查看hadoop/hdfs的用户 # hdfs dfs -l ...
- 【实践篇】基于CAS的单点登录实践之路
作者:京东物流 赵勇萍 前言 上个月我负责的系统SSO升级,对接京东ERP系统,这也让我想起了之前我做过一个单点登录的项目.想来单点登录有很多实现方案,不过最主流的还是基于CAS的方案,所以我也就分享 ...