用C实现HashTable
简述HashTable的原理
HashTable是一种数据结构,通过key可以直接的到value,查找值时间总为常数级别O(1)。
原理
HashTable底层是使用了数组实现的。数组只要知道了索引,查找值的速度是很快的,为常数级别O(1)。数组的索引为数组,HashTable通过一个Hash函数,把key(字符串、数字等可哈希的对象)变成数组的索引。然后就像操作数组一样来查值和找值。
我使用的是time33哈希函数,这个函数的原理在这里我就不再叙述了。
用C代码实现为:
unsigned int time33(char *key){
unsigned int hash = 5381;
while(*key){
hash += (hash << 5 ) + (*key++);
}
return (hash & 0x7FFFFFFF) % MAX_SIZE;
}
值得注意的是:return (hash & 0x7FFFFFFF) % MAX_SIZE;。正常情况下(hash & 0x7FFFFFFF)输出的数字范围是非常广的,这就会导致HashTable底层的数组需要非常大的长度。(如果Hash函数输出范围是0-10,那么底层数组的长度就需要10,如果数组长度不够则会导致溢出。比如,你输入某个值,计算的索引为8,但你的数组长度只有5,很明显你无法对数组索引为8的值合法的操作。)
所以,这里使用了求余%,限定了输出值的大小必定小于MAX_SIZE。
其次,还需要注意的是哈希冲突。比如对于两个不相同的key计算出了相同的hash。这种事情是绝对会发生的,因为你将一个大的集合映射到小的集合上。解决冲突的方法有很多,这里使用的是链表法。也就是,数组上没一个索引下的值实际上存储的是一个链表。链表的节点才是真正的记录了key和value的容器。
使用图来说明就是:
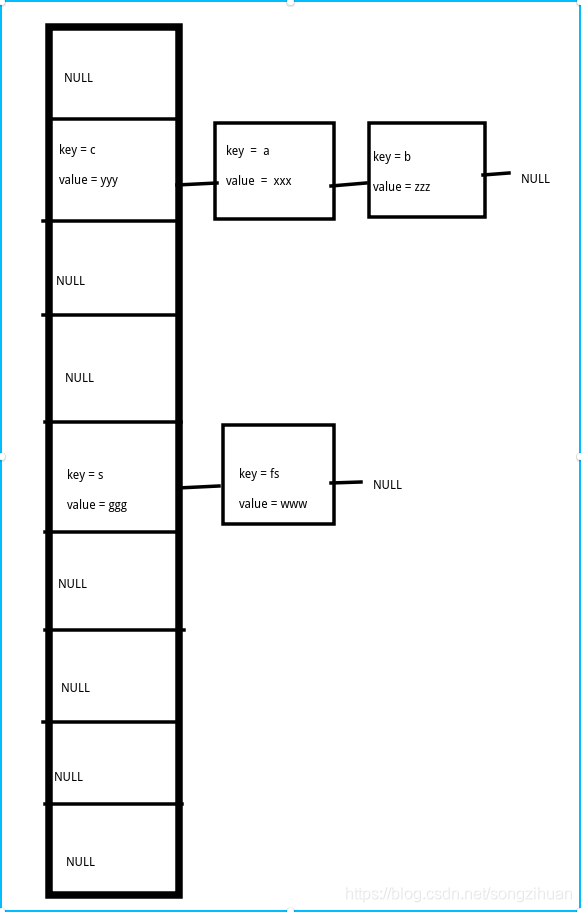
使用C语言的实现
“table.h”
#ifndef MAX_SIZE
#define MAX_SIZE (1024 ^ 2)
// 定义哈系表的范围(也就是通过time_33哈系后的值在跟MAX_SIZE整除,从而限定了范围)
// 一个捅,由key和value组成,同时next为链表所用[解决哈系冲突]
typedef struct HashNode
{
char *key;
char *value;
struct HashNode *next; // Hash冲突
} HashNode;
// 一张哈希表,由一个指针组成,该指针起数组作用,内部存储捅的指针
typedef struct HashTable{
struct HashNode **HashNode; // 这是一个指针数组
} HashTable;
HashTable *make_HashTable();
HashNode *make_HashNode(char *key, char *value);
int login_node(HashTable *ht, HashNode *hn);
HashNode *find_node(HashTable *ht, char *key);
#endif
在头文件中,我定义了HashNode,也就是链表的节点。以及HashTable,本质上是存储一个以HashNode的指针为值的数组。
HashNode也就是前文所属的桶,或者称他为链表的节点。HashTable也就是前文所属的哈希表,底层由一个数组实现。
“main.c”
#include <stdio.h>
#include "table.h"
#include <stdlib.h>
int main(){
HashTable *ht = make_HashTable();
HashNode *tmp1 = make_HashNode("YY","Hello"), *tmp2 = make_HashNode("ZZ","World");
login_node(ht, tmp1);
login_node(ht, tmp2);
printf("YY = %s, ZZ = %s\n", find_node(ht, "YY")->value, find_node(ht, "ZZ")->value);
return 0;
}
HashTable *make_HashTable(){ // 生成并初始化
HashTable *tmp = NULL;
size_t size = sizeof(HashNode) * MAX_SIZE;
tmp = malloc(sizeof(HashTable));
tmp->HashNode = malloc(size);
for(int i = 0; i < MAX_SIZE; i++){
tmp->HashNode[i] = NULL; // 初始化
}
return tmp;
}
HashNode *make_HashNode(char *key, char *value){ // 生成并初始化
HashNode *tmp = NULL;
tmp = malloc(sizeof(HashNode));
tmp->key = key;
tmp->value = value;
tmp->next = NULL;
return tmp;
}
// 使用time33算法,把key换算成为索引,生成索引的范围在0-MAX_SIZE上[因为有 % MAX_SIZE]
unsigned int time33(char *key){
unsigned int hash = 5381;
while(*key){
hash += (hash << 5 ) + (*key++);
}
return (hash & 0x7FFFFFFF) % MAX_SIZE;
}
// 添加一个桶
int login_node(HashTable *ht, HashNode *hn){
// 检查数据是否合法
if(hn == NULL){
return 1;
}
else if(ht == NULL){
return 1;
}
// 计算下标
unsigned int index = time33(hn->key);
HashNode *base_node = ht->HashNode[index]; // 根据下标拿base节点
if(base_node == NULL){
ht->HashNode[index] = hn; // 无冲突
}
else{
// 有冲突
while(1){
if(base_node->next == NULL){ // 迭代找到最后一个节点
break;
}
base_node = base_node->next; // 迭代
}
base_node->next = hn; // 给链表赋值
}
return 0;
}
HashNode *find_node(HashTable *ht, char *key){
// 检查数据是否合法
if(ht == NULL){
return NULL;
}
// 计算索引
unsigned int index = time33(key);
HashNode *base_node = ht->HashNode[index]; // 根据下标拿base节点
if(base_node == NULL){ // 没有节点
return NULL; // 返回NULL表示无数据
}
else{
while(1){
if(!strcmp(base_node->key, key)){ // 比较字符串的值,不可以直接使用 == [char *是指针,==只是比较俩字符串的指针是否一致]
return base_node;
}
else if(base_node->next == NULL){ // 迭代找到最后一个节点,依然没有节点
return NULL;
}
base_node = base_node->next;
}
}
return NULL;
}
make_HashTable和make_HashNode用于初始化HashNode和HashTable。先请求内存,然后赋默认值。知道注意的是,HashTable需要提前向分配好数组大小。注意,MAX_SIZE一旦改变,所有的值都需要重新hash。也就是HashTable在扩张的时候,首先要申请一个更大的内存,然后把原本数组上的值重新计算hash,然后填入新的数组中。最后记得要是释放原来的数组。
login_node是往HashTable中添加一个HashNode,首先计算HashNode的key的索引。如果数组该索引下的值为NULL,则把HashNode作为链表根节点,把它的地址保存在数组中。否则,则迭代整个链表到末尾,再追加这个节点。
find_node是从HashTable中根据key读取HashNode。原理其实同login_node一样,先计算key的hash,然后读取数组索引下的值。若为NULL,则表示这个key不存在,否则就迭代链表,对比每个节点的key是否为目标key。
Hash函数
一个好的Hash函数应该具有:运算快速、并且分布均匀的特点。
何为分布均匀?就是输出值要尽量均匀分布,从而减短链表的长度。[如果说,我输入1w个值,输出值总是在100-200的这个范围,而0-100这个范围却很少,那么就说明这个Hash函数可能不是很好的Hash函数]
这里使用了time33算法,是一个不错的Hash函数。
特别提示:这个Demo没有实现删除功能也没有释放内存,不建议直接使用。
用C实现HashTable的更多相关文章
- HashSet HashTable 与 TreeSet
HashSet<T>类 HashSet<T>类主要是设计用来做高性能集运算的,例如对两个集合求交集.并集.差集等.集合中包含一组不重复出现且无特性顺序的元素. HashSet& ...
- Javascript实现HashTable类
散列算法可以尽快在数据结构中找出指定的一个值,因为可以通过Hash算法求出值的所在位置,存储和插入的时候都按照Hash算法放到指定位置. <script> function HashTab ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- java面试题——HashMap和Hashtable 的区别
一.HashMap 和Hashtable 的区别 我们先看2个类的定义 public class Hashtable extends Dictionary implements Map, Clonea ...
- Map集合及与Collection的区别、HashMap和HashTable的区别、Collections、
特点:将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值. Map集合和Collection集合的区别 Map集合:成对出现 (情侣) ...
- HashTable初次体验
用惯了数组.ArryList,初次接触到HashTable.Dictionary这种字典储存对于我来说简直就是高大上. 1.到底什么是HashTable HashTable就是哈希表,和数组一样,是一 ...
- HashMap和 Hashtable的比较
Hashtable 和 HashMap的比较 1. HashMap可以接受null(HashMap可以接受为null的键值(key)和值(value), HashTable不可以接受为null的键( ...
- hashMap和hashTable的区别
每日总结,每天进步一点点 hashMap和hashTable的区别 1.父类:hashMap=>AbstractMap hashTable=>Dictionary 2.性能:hashMap ...
- SortedList和HashTable
都是集合类,C#中同属命名空间System.Collections,“用于处理和表现类似keyvalue的键值对,其中key通常可用来快速查找,同时key是区分大小写:value用于存储对应于key的 ...
- Java Hashtable的实现
先附源码: package java.util; import java.io.*; /** * This class implements a hash table, which maps keys ...
随机推荐
- windows上U盘格式化失败提示系统找不到指定文件
某天同事拿来几个U盘,问需不需要,我随便看了眼还挺新的,于是插上电脑看看能否正常使用,果然无法识别,因为没有使用需求了也就放着没管了. 突然有一天要去客户现场搞私有化交付了,自己带物料,这下就派上用场 ...
- CefSharp自定义滚动条样式
在WinForm/WPF中使用CefSharp混合开发时,通常需要自定义滚动条样式,以保证应用的整体风格统一.本文将给出一个简单的示例介绍如何自定义CefSharp中滚动条的样式. 基本思路 在前端开 ...
- ESP32-MicroPython without Thonny
why witout Thonny? 最近闲来在ESP32上用MicroPython捣鼓些小玩具,见很多教程推荐使用Thonny.欣然往之,竟是个这,实在不能认同.Thonny esp32-Micro ...
- Chromium CC渲染层工作流详解
1. Chromium 的渲染流水线 Blink -> Paint -> Commit -> (Tiling ->) Raster -> Activate -> D ...
- windows上时间项目时间正常,Ubuntu16.04上时间错误
项目本次测试时间正常,放到服务器上时间差8个小时 1.查看Ubuntu系统时间,发现时间设置错误 date -R 该命令会把我们系统的时间还有时区显示出来,我们是属于东八区,如下图: 如果不是 +08 ...
- 监控报警体系:Prometheus和Grafana
总体 prometheus全链路监控报警,在当今云原生时代可观测领域,Prometheus + Grafana 成为可观测性事实标准. 采集数据:运维团队可以使用 Prometheus 监控云原生 K ...
- Redis Functions 介绍之二
首先,让我们先回顾一下上一篇讲的在Redis Functions中关于将key的名字作为参数和非key名字作为参数的区别,先看下面的例子.首先,我们先在一个Lua脚本文件mylib.lua中定义如下的 ...
- 数据泄露成LLM应用最大障碍,如何用RPA Agent智能体破解谜题?
大语言模型数据泄露堪忧,超自动化Agent成解决之道 数据泄露成LLM应用最大障碍,如何用RPA Agent智能体破解谜题? 从RPA Agent智能体安全机制,看AI Agent如何破解LLM应用安 ...
- 三维形体的表面积(3.25leetcode每日打卡)
在 N * N 的网格上,我们放置一些 1 * 1 * 1 的立方体. 每个值 v = grid[i][j] 表示 v 个正方体叠放在对应单元格 (i, j) 上. 请你返回最终形体的表面积. ...
- 数据结构与算法 | 图(Graph)
在这之前已经写了数组.链表.二叉树.栈.队列等数据结构,本篇一起探究一个新的数据结构:图(Graphs ).在二叉树里面有着节点(node)的概念,每个节点里面包含左.右两个子节点指针:比对于图来说同 ...