千卡利用率超98%,详解JuiceFS在权威AI测试中的实现策略
2023 年 9 月,AI 领域的权威基准评测 MLPerf 推出了 Storage Benchmark。该基准测试通过模拟机器学习 I/O 负载的方法,在不需要 GPU 的情况下就能进行大规模的性能压测,用以评估存储系统的在 AI 模型训练场景的适用性。
目前支持两种模型训练:BERT (自然语言模型) 和 Unet3D(3D医学成像)。虽然目前不支持大语言模型如 GPT、LLaMA,但 BERT 与大语言模型同为多层 transformer 结构,大语言模型的用户仍可从 BERT 训练结果获得一定的参考。
高性能存储产品厂商 DDN、Nutanix、Weka 和 Argonne National Laboratory(简称 ANL)发布了 MLPerf 的测试结果作为行业参考,我们也使用 JuiceFS 企业版进行了测试,让用户了解它在模型训练中的表现。
测试中最直观的指标是 GPU 利用率,大于 90% 为测试通过,表示存储系统能够满足训练业务的性能需求。JuiceFS 在 Unet3D 的 500 卡规模测试中,GPU 利用率保持在 97% 以上;在 BERT 的1000 卡规模测试中,GPU 利用率保持在 98% 以上。
01 测试准备
JuiceFS 企业版是基于对象存储的并行文件系统,相比社区版它提供了更强的元数据引擎和缓存管理能力,它的架构图如下:

我们在华为云上搭建了一套企业版 JuiceFS 文件系统,使用华为云 OBS 作为数据持久层,部署了 3 节点的元数据集群和多节点的分布式缓存集群,硬件规格如下:
元数据节点:m7.2xlarge.8 | 8vCPUs | 64GiB
对象存储:OBS,带宽上限 300 Gb/s
客户端节点:ir7.16xlarge.4 | 64vCPUs | 256GiB | Local SSD 2*1,600GiB | 网卡带宽 25 Gbps (以太网)
准备好文件系统后,我们使用 mlperf 的脚本生成后续模拟训练所需要的数据集,所有的测试中 batch size 和 steps 均采用默认设置。目前仅支持模拟 NVIDIA v100 GPU,后文中提到的 GPU 均是模拟 v100。
02 BERT 模型
MLPerf 为 BERT 模型生成数据集时,会按照每个数据集文件包含 313,532 个样本的规则来生成,每个样本大小为 2.5 KB。训练过程中每个模拟 v100 GPU 每秒能处理 50 个样本,即每个 GPU 的 IO 吞吐需求为 125 KB/s,绝大部分存储系统都能轻松满足它的模型训练需要,JuiceFS 也是一样的,能够满足 1000 卡规模的模型训练需要。
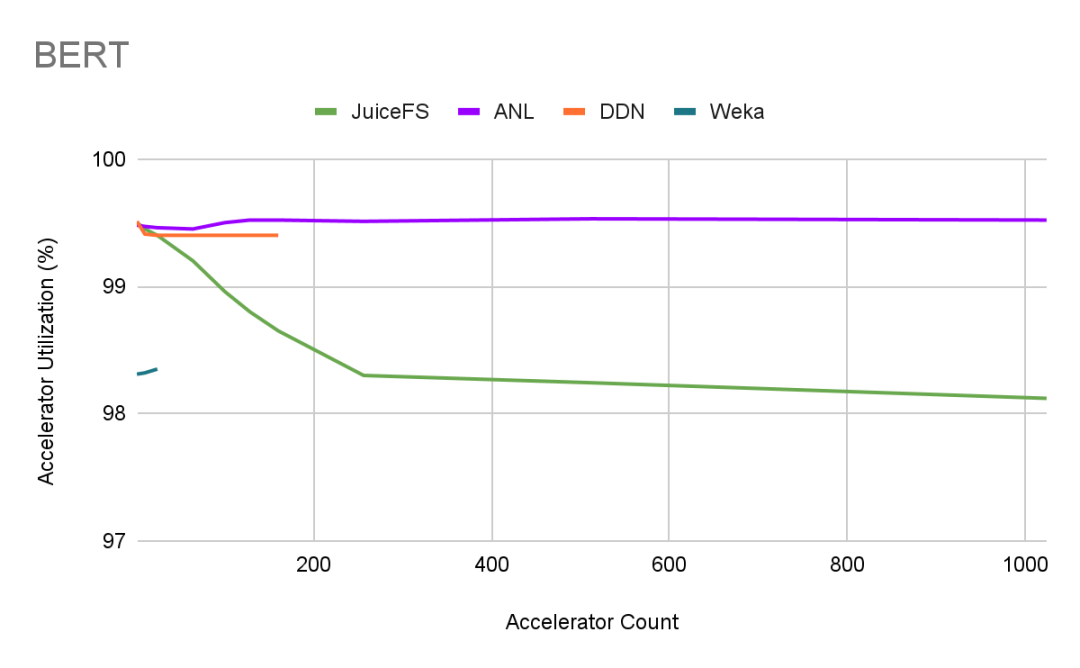
我们汇集了 MLPerf 的主要公开结果,包括 ANL、DDN、Weka 的数据,并新增了本次测试中 JuiceFS 的结果。
JuiceFS 在 1000 GPU 规模下保持 98% 以上 GPU 利用率。
ANL 的结果依然非常优秀,考虑到 ANL 测试的网络条件是高带宽低延迟的 Slingshot 网络,能有这样的成绩也是意料之中的。
03 Unet3D 模型
Unet3D 模型的训练对带宽的需求高于 BERT 模型。我们首先在没有任何缓存(包括分布式缓存和单机缓存)的条件下测试了训练 Unet3D 模型的情况。在这种设置下,JuiceFS客户端将直接从对象存储中读取数据。
无缓存测试
如下图所示,随着节点数的增加,GPU 利用率(图中的绿色线条)会缓慢下降。当 GPU 增至 98 卡时,它出现了一个明显的拐点,随后 GPU 利用率随节点数的增加而急剧降低。
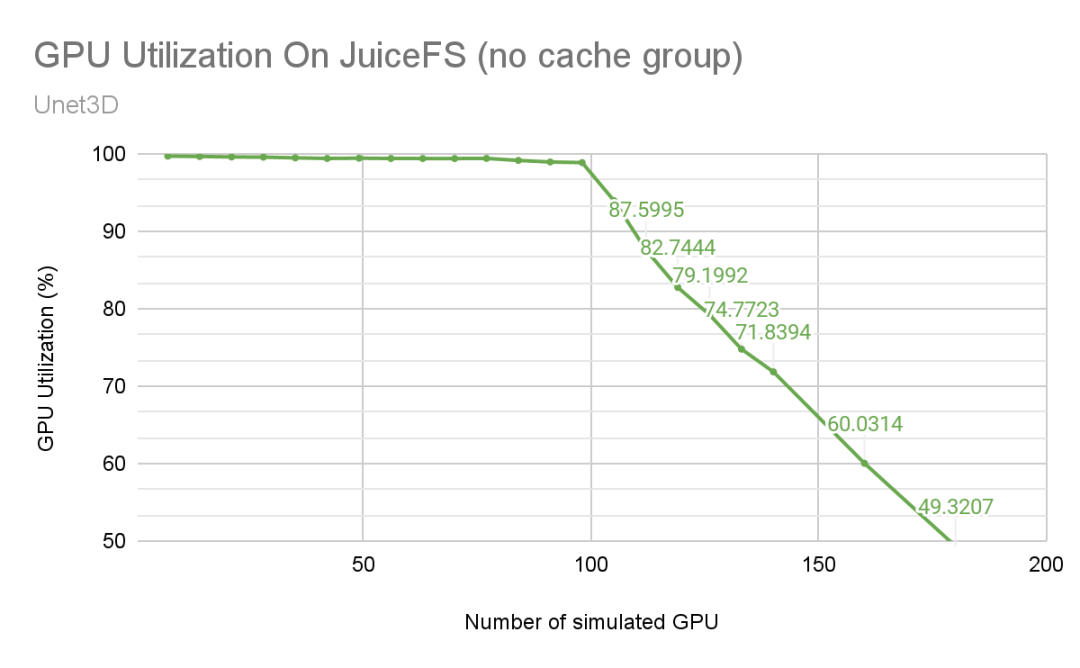
下图是根据 OBS 监控数据和 MLPerf 的结果绘制出来的曲线图,可以看到 OBS 带宽在 98 卡及更大规模的训练中已经不再增加,成为性能瓶颈。
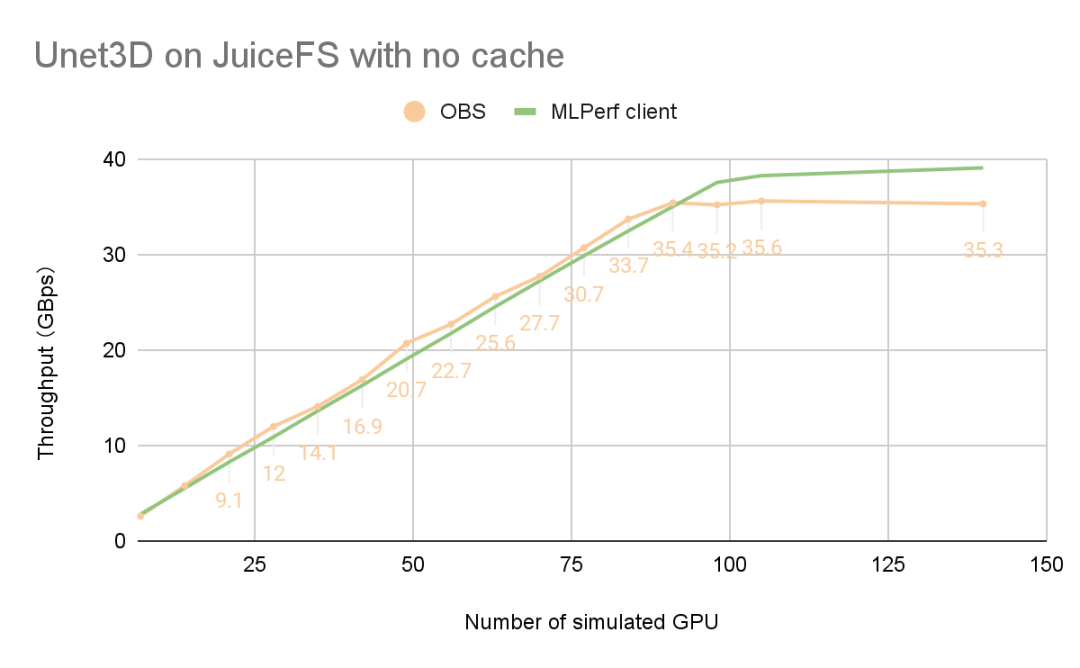
因此,在没有缓存的情况下,OBS 提供的 300Gb/s 带宽在 98 卡同时训练时就已经满载。根据 MLPerf 90% 的测试通过标准来看,可以满足最多 110 卡同时训练 Unet3D 模型。
在对大型数据集进行多机多卡训练时,单机缓存由于其空间限制仅能缓存数据集的一小部分;同时,由于训练过程中数据访问的随机性,缓存命中率较低。因此,这种情况下,单机缓存对于提升整体 I/O 性能的贡献有限(如上图绿线,能看到单机的内核缓存对读带宽有提升作用,虽然内核缓存空间多达 200GB ,但效果有限),因此我们没有进行单机缓存的针对性测试。
开启分布式缓存
相比本地缓存,分布式缓存可以提供更大的缓存容量以支撑更大的训练集和更高的缓存命中率,从而提升整个 JuiceFS 集群的读带宽。
JuiceFS 的分布式缓存架构如下图所示,机器学习训练集群和 JuiceFS 的缓存集群可以是两批独立的机器组成的集群,它们通过高速网络连接。这两个集群都挂载了JuiceFS 客户端。训练任务通过 JuiceFS 在本地的挂载点访问数据。当本地挂载点需要数据时,它会首先从缓存集群请求数据;如果缓存集群中缺失所需数据,系统则会从对象存储中获取数据并更新到缓存中。如果训练集群中的 GPU 节点自身也配置了充足的 SSD 存储,那么它们可以直接用作 JuiceFS 的缓存盘并组成缓存集群,无需部署独立的缓存集群。这种配置实际上是将训练集群和缓存集群的功能合并在一起。在本次测试中,我们采用了这种混合部署方式。
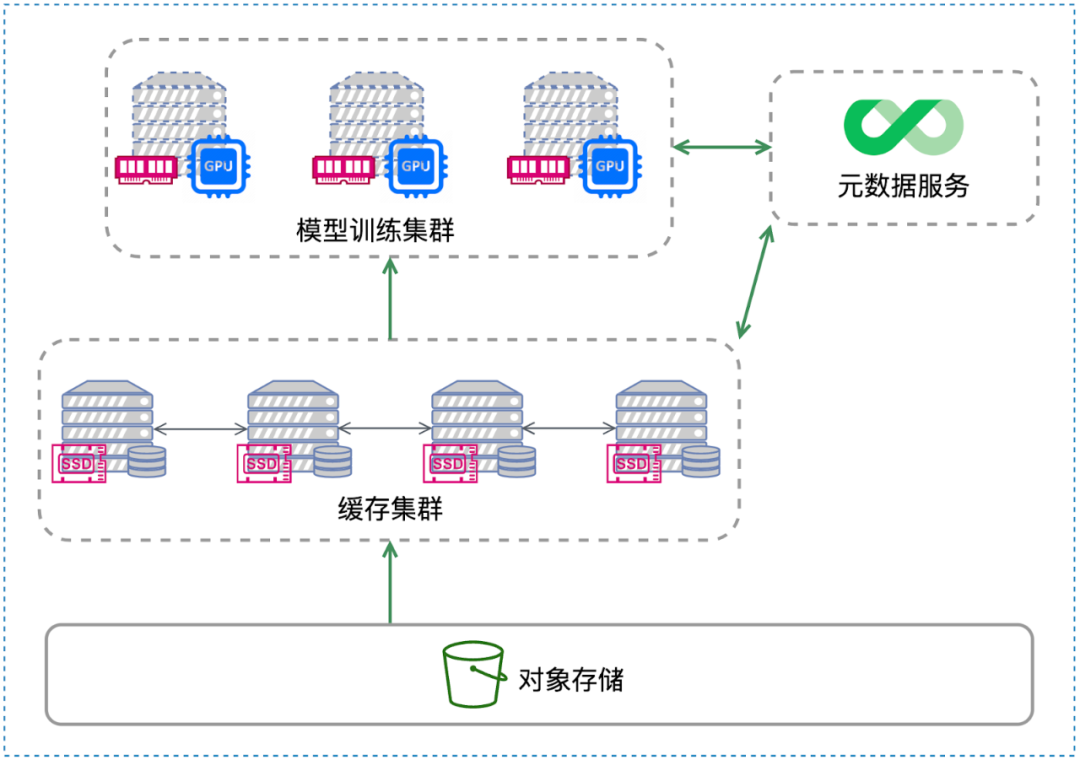
分布式缓存及其容量对 GPU 利用率的影响
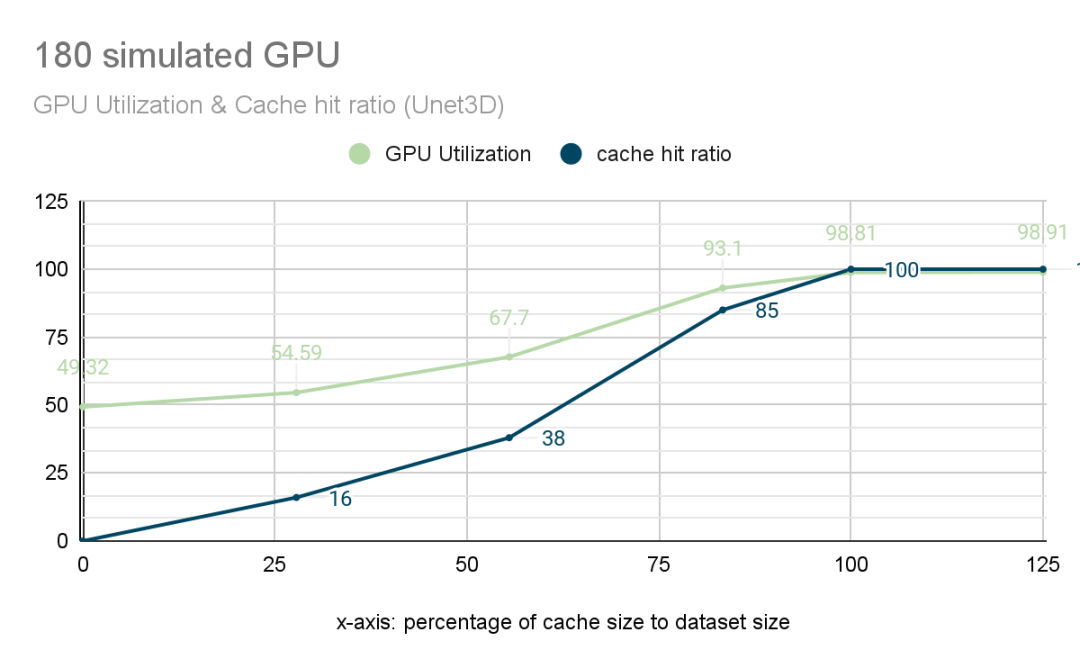
之前的测试表明,未开启缓存时,110 卡时的 GPU 利用率不足 90%。为了直观展示分布式缓存对性能的影响,我们对 JuiceFS 进行了进一步的测试。我们选择 180 卡 GPU 规模的集群作为测试对象进行新一轮的测试,以评估 JuiceFS 的缓存命中率时跟 GPU 利用率关系。
下图中,横坐标表示缓存空间与数据集大小的比例,纵坐标表示缓存命中率和 GPU 使用率。当完全没有缓存时,GPU 的使用率只有 49%。随着缓存空间比例的增加,缓存命中率(蓝色线条)逐渐提高,进而带动 GPU 利用率(绿色线条)上升,当缓存命中率到 85% 时, GPU 利用率到了 93.1%, 已经能够满足 180 卡的训练使用。当缓存命中率达到 100% 时,GPU 利用率达到最高的 98.8%,几乎满载运行。
为了验证 JuiceFS 的缓存系统的扩展能力,我们按照数据集的大小调整了缓存集群的容量,确保了缓存命中率达到 100%。这样,所有训练所需数据均可直接从缓存中读取,而不必从速度较慢的对象存储中读取。在这种配置下,我们测试了最多约 500 卡规模的训练任务,随着测试规模的增大,GPU 利用率的变化如下图所示。
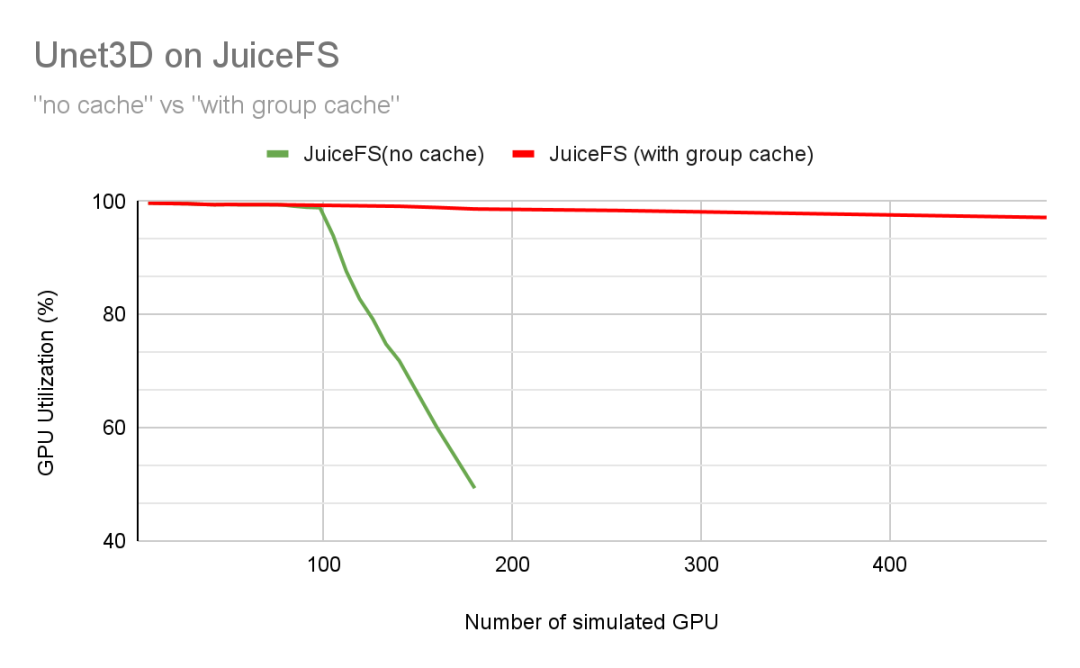
从图中红色线条可以看到,开启分布式缓存的 JuiceFS 突破了带宽瓶颈的限制, GPU 利用率会随着集群规模变大仅缓慢线性下降。按照上图的变化趋势估计,在当期的网络配置 (25Gbps) 下,JuiceFS 可以支撑约 1500 卡训练 Unet3D 时保持 GPU 利用率在 90% 以上。
对比 Unet3D 的测试结果:JuiceFS/ANL/DDN/Weka
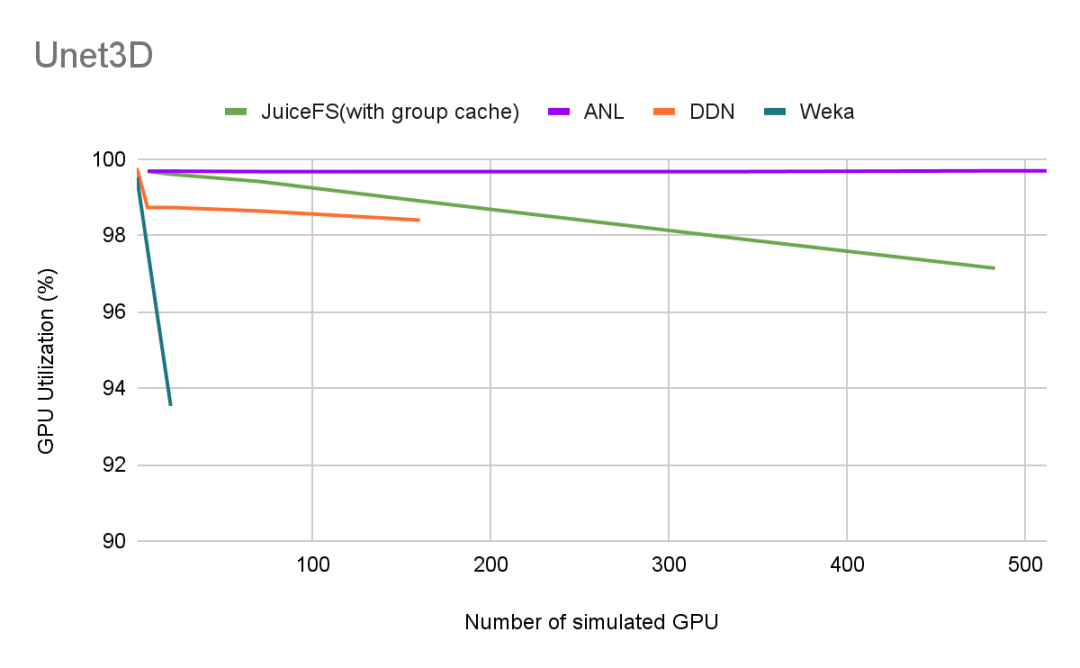
DDN、Weka 公布的数据中最大规模的模拟 GPU 总数低于 200。
ANL 在 512 卡的规模下依然没有明显衰减,GPU 利用率能够达到 99.5%。ANL 的读写带宽为 650 GBps,理论上最多能支撑 1500 卡训练 Unet3D, 它的出色表现与充足的硬件配置密切相关,具体内容可以前往 ANL 的文章了解。
JuiceFS 的 GPU 利用率随着集群规模变大,缓慢线性下降,在 500 卡规模时保持 97% 以上。JuiceFS 遇到的性能瓶颈主要来自于缓存节点的网络带宽。由于缓存节点的机型数量和网络带宽有限,本次测试达到的最大规模为 483 卡。在这种规模下,JuiceFS 集群的聚合带宽为 1.7 Tb,而 ANL 集群的带宽是 5.2 Tb 。
04 小结
在 BERT 测试中,JuiceFS 在 1000 GPU 规模的训练中能保持 98% 以上 GPU 利用率;
在 Unet3D 测试中,随着集群规模变大,JuiceFS 在接近 500 GPU 训练中保持 97% 以上 GPU 利用率。若云服务商可以提供更高的网络带宽或更多的机器,这一规模还可进一步提高;
分布式缓存的优势在于极强的扩展性,可以利用更多节点上的 SSD 存储聚合更大的缓存空间,提高整个存储系统的读带宽;当然它也会带来一些 CPU 开销,但在 AI 训练场景中,使用闲置的 CPU 资源提升系统带宽是值得,甚至必要的。
在云上进行机器学习训练时,高性能 GPU 机型通常都具有高性能的 SSD 和高带宽的网卡,这些设备还可以作为分布式缓存节点。因此,相比于专有的高性能存储产品,使用 JuiceFS ,更具性价比,更易扩展。
大规模的 AI 训练场景中,通常都需要专有高性能存储,或是基于全闪架构和内核态的并行文件系统才能满足性能需求。但随着计算负载增加、集群增大,全闪的高昂成本和内核客户端的运维复杂度会成为用户面临的一大挑战。而 JuiceFS ,作为一款全用户态的的云原生分布式文件系统,借助分布式缓存来大幅提升系统的 IO 吞吐量,使用便宜的对象存储完成数据存储,更适合大规模 AI 业务的整体需要。
关于 MLPerf
MLPerf 是一套基准测试套件,它主要用于评估机器学习在本地和云平台上的训练及推理性能,为软件框架、硬件平台和机器学习的云平台提供了一个独立且客观的性能评估标准。该套件的测试包括测量机器学习模型训练到目标准确度所需的时间以及训练完成的神经网络在新数据上执行推理任务的速度。这个套件是由 30 多个与 AI 相关的组织共同创建的。点击此处了解详情。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。
千卡利用率超98%,详解JuiceFS在权威AI测试中的实现策略的更多相关文章
- 超全详解Java开发环境搭建
摘自:https://www.cnblogs.com/wangjiming/p/11278577.html 超全详解Java开发环境搭建 在项目产品开发中,开发环境搭建是软件开发的首要阶段,也是必 ...
- Day17:稀疏数组的超细详解
稀疏数组的超细详解 一个含有大量重复元素的二维数组,我们可以提取其有效元素,压缩空间,整合为一个稀疏数组. 例如一个五子棋棋盘,我们将棋盘看作为一个二维数组,没有棋子的位置为0:黑棋为1:白棋为2: ...
- .NET DLL 保护措施详解(二)关于性能的测试
先说结果: 加了缓存的结果与C#原生代码差异不大了 我对三种方式进行了测试: 第一种,每次调用均动态编译 第二种,缓存编译好的对象 第三种,直接调用原生C#代码 .net dll保护系列 ------ ...
- 详解如何将MathType嵌入word中
将MathType嵌入word中的过程就是word插入对象的过程,插入对象是word软件中最常见的操作,MathType公式编辑器与所有的Office程序(OLE技术)都有很好的兼容性,本教程将详解如 ...
- Java网络编程和NIO详解7:浅谈 Linux 中NIO Selector 的实现原理
Java网络编程和NIO详解7:浅谈 Linux 中NIO Selector 的实现原理 转自:https://www.jianshu.com/p/2b71ea919d49 本系列文章首发于我的个人博 ...
- Java网络编程和NIO详解4:浅析NIO包中的Buffer、Channel 和 Selector
Java网络编程与NIO详解4:浅析NIO包中的Buffer.Channel 和 Selector 转自https://www.javadoop.com/post/nio-and-aio 本系列文章首 ...
- Android菜单详解(一)——理解android中的Menu
前言 今天看了pro android 3中menu这一章,对Android的整个menu体系有了进一步的了解,故整理下笔记与大家分享. PS:强烈推荐<Pro Android 3>,是我至 ...
- PHP header函数设置http报文头示例详解以及解决http返回头中content-length与Transfer-Encoding: chunked的问题
最近在服务器上,多媒体与设备(摄像头)对接的时候,总是发生错误导致设备崩溃,抓包发现响应头不对,没有返回length,使得摄像头立即崩溃.找了一下资料,改了一下响应头就好了. //定义编码 heade ...
- HTTP头部信息和错误代码详解-《HTTP权威指南》
最近在调试 前后端分离的请求测试,遇到了一个405错误, 无法接受,于是开始了人肉搜索405. 最后 还是HTTP头部信息里的Accept:application/json 这个Accept 导致的, ...
- 40+倍提升,详解 JuiceFS 元数据备份恢复性能优化之路
JuiceFS 支持多种元数据存储引擎,且各引擎内部的数据管理格式各有不同.为了便于管理,JuiceFS 自 0.15.2 版本提供了 dump 命令允许将所有元数据以统一格式写入到 JSON 文件进 ...
随机推荐
- 一招轻松解决node内存溢出问题
node启动项目造成内存溢出的解决办法 我们在使用node启动项目的时在项目较大的时候,可能会造成内存溢出.为什么会造成内存溢出呢? 要回答上面这个问题,我们要了解node中是如何分配内存的. Nod ...
- dispaly结合背景图片会提升加载性能
1.display的常见现象 我们很多人都知道,display可以让元素实现隐藏或者显示. 或者让行级元素变成块级元素. 对它的认识也是比较准确的. 如果一个元素使用了display:none; 那么 ...
- 【0基础学爬虫】爬虫基础之自动化工具 Selenium 的使用
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶.逆向相关文章,为实现从易到难全方位覆盖,特设[0基础学爬 ...
- HarmonyOS实战[三]—可编辑的卡片交互
相关文章: HarmonyOS实战[一]--原理概念介绍安装:基础篇 HarmonyOS实战[二]-超级详细的原子化服务体验[可编辑的卡片交互]快来尝试吧 [本文正在参与"有奖征文|Harm ...
- 【技能篇】解决vs编译器scanf等函数不安全问题【手把手操作-一分钟解决】
[技能篇]解决Vs编译器scanf等函数不安全问题 文章目录 说在前面 博主给大家的福利 解决方案 解决过程 尾声 说在前面 大家刚开始学习编程的时候,使用vs编译器.使用scanf等函数的时候遇到的 ...
- 【双指针】双指针算法详解两道经典OJ【力扣27,力扣26,力扣38】超详细算法教程
[双指针]双指针算法详解两道经典OJ[力扣27,力扣26,力扣38]超详细算法教程 今天又又到了我们刷力扣题的时间啦! 今天博主给大家带来的三道题是: 27. 移除元素 26. 删除有序数组中的重复项 ...
- .NET 云原生架构师训练营(RGCA 四步架构法)--学习笔记
RGCA Requirement:从利益相关者获取需求 Goal:将需求转化为目标(功能意图) Concept:将目标扩展为完整概念 Architecture:将概念扩展为架构 目录 从利益相关者获取 ...
- BeginCTF 2024(自由赛道)MISC
real check in 题目: 从catf1y的笔记本中发现了这个神秘的代码 MJSWO2LOPNLUKTCDJ5GWKX3UN5PUEM2HNFXEGVCGL4ZDAMRUL5EDAUDFL5M ...
- MySQL 幻象行
当同一个查询在不同的时间产生不同的行集时,就会出现所谓的幻像问题.例如,如果执行了两次SELECT,但是第二次返回了第一次没有返回的行,那么该行就是一个"幻象"行. 假设在表chi ...
- 使用V2R做反向代理内网穿透
环境 内网服务器Prob1位于内网LAN1, 内网服务器Prob2位于内网LAN2, 外网服务器Serv1位于IP 123.123.123.123 内网节点配置 内网节点没有inbound,只需要配置 ...