instance norm
与Batch Norm加快计算收敛不同, IN是在[1]中提出的,目的是提高style transfer的表现。

计算如下:
\]
其中
\]
\]
可以看到,IN是对每个channel的计算。(感觉上跟layer norm很像。)
解释
关于为什么IN在style transfer和Image generation的任务上表现更好,有很多解释。这里只介绍[2]中的解释,因为实验比较充分。
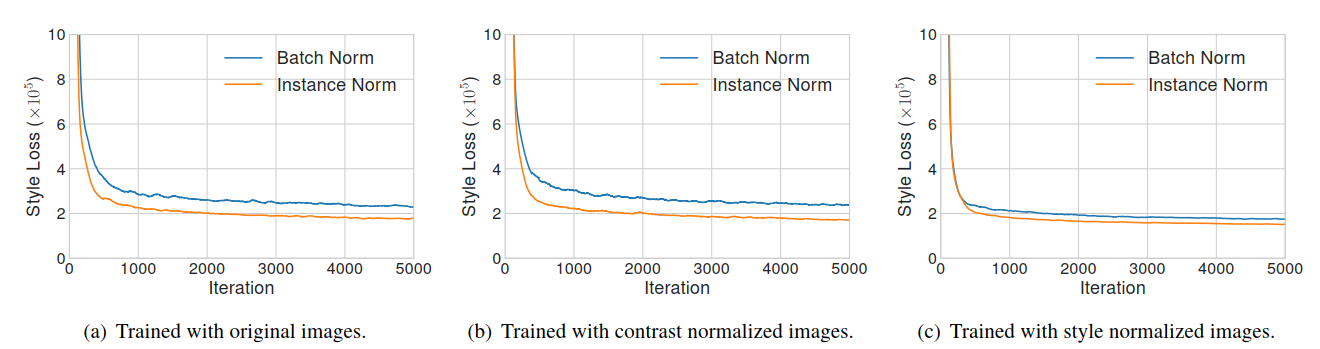
IN作者认为IN有效的原因在于IN是对图像的对比度进行了Norm,所以效果好,但是[2]的实验表明,并非如此,如图b所示,训练图像事先对比度归一化以后,IN的表现仍然好很多。但是在均统一为一个风格以后(图c),两者差别就很小了。
- IN 可以认为,是一种风格的norm。即可以通过IN将图像在feature space 转化到另一个style。
Our results indicate that IN does perform a kind of style normalization.
Since BN normalizes the feature statistics of a batch of samples instead of a single sample, it can be intuitively understood as normalizing a batch of samples to be centered around a single style. Each single sample, however, may still have different styles. This is undesirable when we want to transfer all images to the same style, as is the case in the original feed-forward style transfer algorithm [51].
Although the convolutional layers might learn to compensate the intra-batch style difference, it poses additional challenges for training. On the other hand, IN can normalize the style of each individual sample to the target style. Training is facilitated because the rest of the network can focus on content manipulation while discarding the original style information. The reason behind the success of CIN also becomes clear: different affine parameters can normalize the feature statistics to different values, thereby normalizing the output image to different styles.
ref
- Instance Normalization: The Missing Ingredient for Fast Stylization
- Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
instance norm的更多相关文章
- bn两个参数的计算以及layer norm、instance norm、group norm
bn一般就在conv之后并且后面再接relu 1.如果输入feature map channel是6,bn的gamma beta个数是多少个? 6个. 2.bn的缺点: BN会受到batchsize大 ...
- Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization、Switchable Normalization比较
深度神经网络难训练一个重要的原因就是深度神经网络涉及很多层的叠加,每一层的参数变化都会导致下一层输入数据分布的变化,随着层数的增加,高层输入数据分布变化会非常剧烈,这就使得高层需要不断适应低层的参数更 ...
- Norm比较
目录 Introduction BN LN IN GN SN Conclusion Introduction 输入图像shape记为[N, C, H, W] Batch Norm是在batch上,对N ...
- 【算法】Normalization
Normalization(归一化) 写这一篇的原因是以前只知道一个Batch Normalization,自以为懂了.结果最近看文章,又发现一个Layer Normalization,一下就懵逼了. ...
- 『计算机视觉』各种Normalization层辨析
『教程』Batch Normalization 层介绍 知乎:详解深度学习中的Normalization,BN/LN/WN 一.两个概念 独立同分布(independent and identical ...
- 原始的生成对抗网络GAN
论文地址:https://arxiv.org/pdf/1406.2661.pdf 1.简介: GAN的两个模型 判别模型:就是图中右半部分的网络,直观来看就是一个简单的神经网络结构,输入就是一副图像, ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- hello--GAN
GAN系列学习(1)——前生今世 DCGAN.WGAN.WGAN-GP.LSGAN.BEGAN原理总结及对比 [Learning Notes]变分自编码器(Variational Auto-Encod ...
- tflearn kears GAN官方demo代码——本质上GAN是先训练判别模型让你能够识别噪声,然后生成模型基于噪声生成数据,目标是让判别模型出错。GAN的过程就是训练这个生成模型参数!!!
GAN:通过 将 样本 特征 化 以后, 告诉 模型 哪些 样本 是 黑 哪些 是 白, 模型 通过 训练 后, 理解 了 黑白 样本 的 区别, 再输入 测试 样本 时, 模型 就可以 根据 以往 ...
随机推荐
- 多精度 simulator 中的 RL:一篇 14 年 ICRA 的古早论文
目录 全文快读 0 abstract 1 intro 2 related work 3 背景 & 假设 3.1 RL & KWIK(know what it knows)的背景 3.2 ...
- webrtc QOS笔记二 音频buffer数据不足生成很多gap的问题
webrtc QOS笔记二 音频buffer数据不足生成很多gap的问题 目录 webrtc QOS笔记二 音频buffer数据不足生成很多gap的问题 记录个iusse. 插入音频数据后,GetAu ...
- 图与网络分析—R实现(四)
三 最短路问题 最短路问题(short-path problem)是图论理论的一个经典问题.寻找最短路径就是在指定网络中两结点间找一条距离最小的路.最短路不仅仅指一般地理意义上的距离最短,还可以引申到 ...
- CentOS8 搭建zabbix监控系统
哈喽,有些时间没有更新公众号.今日更新一下. 安装MySQL数据库 # 安装wget [root@cby ~]# dnf install wget -y # 下载MySQL源 [root@cby ~] ...
- python程序,实现以管理员方式运行程序,也就是提升程序权限
quest UAC elevation from within a Python script? 我希望我的Python脚本能够在Vista上复制文件. 当我从普通的cmd.exe窗口运行它时,不会生 ...
- [Linux]常用命令之【mount/umount】
1 mount mount命令的作用是加载文件系统,它的用权限是超级用户或/etc/fstab中允许的使用者. 在Linux和Unix系统上,所有文件都是作为一个大型树(以/为根)的一部分访问的. 要 ...
- ThreadLocal实现原理和使用场景
ThreadLocal是线程本地变量,每个线程中都存在副本. 实现原理: 每个线程中都有一个ThreadLocalMap,而ThreadLocalMap中的key即是ThreadLocal. 内存泄 ...
- 重学C++ (一)基础回顾
由于C++基础非常重要,所以打算把平时重学C++的总结,抽时间上传到博客! 1.切勿乱用带符号类型和无符号类型 #include <iostream> using namespace st ...
- Python-faker的简单使用
前言: faker是一个开源的python库,安装完成后只需要调用Faker库,就可以帮助我们创建需要的数据. 一.安装 1.执行如下命令安装 pip3 install faker 2.进入File ...
- 做了个vscode 小插件,用于修改window 的颜色以区分同时打开的不同工作区,快用起来吧!
Coralize marketplace/coralize 以高效且便捷的方式自定义Visual Studio Code工作区窗口的状态栏.标题栏以及活动边栏等颜色!这将对那些需要同时打开多个vsco ...