将onnx的静态batch改为动态batch及修改输入输出层的名称
背景
在模型的部署中,为了高效利用硬件算力,常常会需要将多个输入组成一个batch同时输入网络进行推理,这个batch的大小根据系统的负载或者摄像头的路数时刻在变化,因此网络的输入batch是在动态变化的。对于pytorch等框架来说,我们并不会感受到这个问题,因为整个网络在pytorch中都是动态的。而在实际的工程化部署中,为了运行效率,却并不能有这样的灵活性。可能会有人说,那我就把batch固定在一个最大值,然后输入实际的batch,这样实际上网络是以最大batch在推理的,浪费了算力。所以我们需要能支持动态的batch,能够根据输入的batch数来运行。
一个常见的训练到部署的路径是:pytorch→onnx→tensorrt。在pytorch导出onnx时,我们可以指定输出为动态的输入:
torch_out = torch.onnx.export(model, inp,
save_path,input_names=["data"],output_names=["fc1"],dynamic_axes={
"data":{0:'batch_size'},"fc1":{0:'batch_size'}
})
而另一些时候,我们部署的模型来源于他人或开源模型,已经失去了原始的pytorch模型,此时如果onnx是静态batch的,在移植到tensorrt时,其输入就为静态输入了。想要动态输入,就需要对onnx模型本身进行修改了。另一方面,算法工程师在导模型的时候,如果没有指定输入层输出层的名称,导出的模型的层名有时候可读性比较差,比如输出是batchnorm_274这类名称,为了方便维护,也有需要对onnx的输入输出层名称进行修改。
操作
修改输入输出层
def change_input_output_dim(model):
# Use some symbolic name not used for any other dimension
sym_batch_dim = "batch"
# The following code changes the first dimension of every input to be batch-dim
# Modify as appropriate ... note that this requires all inputs to
# have the same batch_dim
inputs = model.graph.input
for input in inputs:
# Checks omitted.This assumes that all inputs are tensors and have a shape with first dim.
# Add checks as needed.
dim1 = input.type.tensor_type.shape.dim[0]
# update dim to be a symbolic value
dim1.dim_param = sym_batch_dim
# or update it to be an actual value:
# dim1.dim_value = actual_batch_dim
outputs = model.graph.output
for output in outputs:
# Checks omitted.This assumes that all inputs are tensors and have a shape with first dim.
# Add checks as needed.
dim1 = output.type.tensor_type.shape.dim[0]
# update dim to be a symbolic value
dim1.dim_param = sym_batch_dim
model = onnx.load(onnx_path)
change_input_output_dim(model)
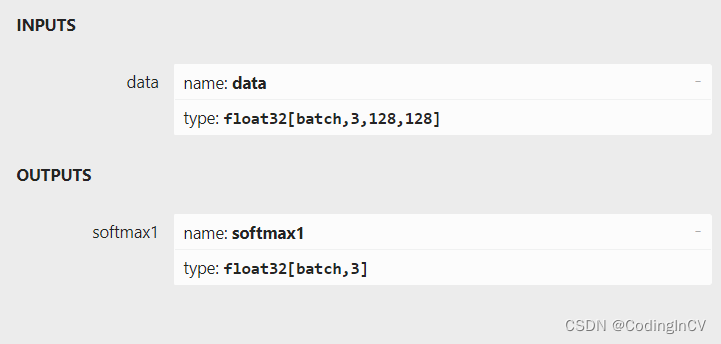
通过将输入层和输出层的shape的第一维修改为非数字,就可以将onnx模型改为动态batch。
修改输入输出层名称
def change_input_node_name(model, input_names):
for i,input in enumerate(model.graph.input):
input_name = input_names[i]
for node in model.graph.node:
for i, name in enumerate(node.input):
if name == input.name:
node.input[i] = input_name
input.name = input_name
def change_output_node_name(model, output_names):
for i,output in enumerate(model.graph.output):
output_name = output_names[i]
for node in model.graph.node:
for i, name in enumerate(node.output):
if name == output.name:
node.output[i] = output_name
output.name = output_name
代码中input_names和output_names是我们希望改到的名称,做法是遍历网络,若有node的输入层名与要修改的输入层名称相同,则改成新的输入层名。输出层类似。
完整代码
import onnx
def change_input_output_dim(model):
# Use some symbolic name not used for any other dimension
sym_batch_dim = "batch"
# The following code changes the first dimension of every input to be batch-dim
# Modify as appropriate ... note that this requires all inputs to
# have the same batch_dim
inputs = model.graph.input
for input in inputs:
# Checks omitted.This assumes that all inputs are tensors and have a shape with first dim.
# Add checks as needed.
dim1 = input.type.tensor_type.shape.dim[0]
# update dim to be a symbolic value
dim1.dim_param = sym_batch_dim
# or update it to be an actual value:
# dim1.dim_value = actual_batch_dim
outputs = model.graph.output
for output in outputs:
# Checks omitted.This assumes that all inputs are tensors and have a shape with first dim.
# Add checks as needed.
dim1 = output.type.tensor_type.shape.dim[0]
# update dim to be a symbolic value
dim1.dim_param = sym_batch_dim
def change_input_node_name(model, input_names):
for i,input in enumerate(model.graph.input):
input_name = input_names[i]
for node in model.graph.node:
for i, name in enumerate(node.input):
if name == input.name:
node.input[i] = input_name
input.name = input_name
def change_output_node_name(model, output_names):
for i,output in enumerate(model.graph.output):
output_name = output_names[i]
for node in model.graph.node:
for i, name in enumerate(node.output):
if name == output.name:
node.output[i] = output_name
output.name = output_name
onnx_path = ""
save_path = ""
model = onnx.load(onnx_path)
change_input_output_dim(model)
change_input_node_name(model, ["data"])
change_output_node_name(model, ["fc1"])
onnx.save(model, save_path)
经过修改后的onnx模型输入输出将成为动态batch,可以方便的移植到tensorrt等框架以支持高效推理。
将onnx的静态batch改为动态batch及修改输入输出层的名称的更多相关文章
- Spark Streaming中动态Batch Size实现初探
本期内容 : BatchDuration与 Process Time 动态Batch Size Spark Streaming中有很多算子,是否每一个算子都是预期中的类似线性规律的时间消耗呢? 例如: ...
- 《CMake实践》笔记三:构建静态库(.a) 与 动态库(.so) 及 如何使用外部共享库和头文件
<CMake实践>笔记一:PROJECT/MESSAGE/ADD_EXECUTABLE <CMake实践>笔记二:INSTALL/CMAKE_INSTALL_PREFIX &l ...
- 浅谈在静态页面上使用动态参数,会造成spider多次和重复抓取的解决方案
原因: 早期由于搜索引擎蜘蛛的不完善,蜘蛛在爬行动态的url的时候很容易由于网站程序的不合理等原因造成蜘蛛迷路死循环. 所以蜘蛛为了避免之前现象就不读取动态的url,特别是带?的url 解决方案: 1 ...
- 在Linux中创建静态库.a和动态库.so
转自:http://www.cnblogs.com/laojie4321/archive/2012/03/28/2421056.html 在Linux中创建静态库.a和动态库.so 我们通常把一些公用 ...
- Spark Streaming揭秘 Day21 动态Batch size实现初探(下)
Spark Streaming揭秘 Day21 动态Batch size实现初探(下) 接昨天的描述,今天继续解析动态Batch size调整的实现. 算法 动态调整采用了Fix-point迭代算法, ...
- Spark Streaming揭秘 Day20 动态Batch size实现初探(上)
Spark Streaming揭秘 Day20 动态Batch size实现初探(上) 今天开始,主要是通过对动态Batch size调整的论文的解析,来进一步了解SparkStreaming的处理机 ...
- 动态库DLL加载方式-静态加载和动态加载
静态加载: 如果你有a.dll和a.lib,两个文件都有的话可以用静态加载的方式: message函数的声明你应该知道吧,把它的声明和下面的语句写到一个头文件中 #pragma comment(lib ...
- WPF中静态引用资源与动态引用资源的区别
WPF中静态引用资源与动态引用资源的区别 WPF中引用资源分为静态引用与动态引用,两者的区别在哪里呢?我们通过一个小的例子来理解. 点击“Update”按钮,第2个按钮的文字会变成“更上一层楼”, ...
- 解决在静态页面上使用动态参数,造成spider多次和重复抓取的问题
我们在使用百度统计中的SEO建议检查网站时,总是发现“静态页参数”一项被扣了18分,扣分原因是“在静态页面上使用动态参数,会造成spider多次和重复抓取”.一般来说静态页面上使用少量的动态参数的话并 ...
- C++的静态联编和动态联编
联编的概念 联编是指一个计算机程序自身彼此关联的过程,在这个联编过程中,需要确定程序中的操作调用(函数调用)与执行该操作(函数)的代码段之间的映射关系. 意思就是这个函数的实现有多种,联编就是把调用和 ...
随机推荐
- 系统建模之UML用例视图
<用例视图> 1 用例图的目标 who「参与者」:确定谁要使用系统 what「功能」:他们使用系统做什么? 2 用例图-四大主要组件 2.1 参与者 参与者:与应用程序或系统进行交互的用户 ...
- [数据库]MYSQL之存储过程
一 存储过程的特点 MySQL 5.0 版本开始支持存储过程 1.1 定义 存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象. 存储过程是为了 ...
- CentOS7---部署Tomcat和安装Jpress
总览需求 1. 简述静态网页和动态网页的区别. 2. 简述 Webl.0 和 Web2.0 的区别. 3. 安装tomcat8,配置服务启动脚本,部署jpress应用. 1.简述静态网页和动态网页的区 ...
- 基于Python的爬虫案例
案例1:使用爬虫爬取京东华为手机用户评论 本案例借鉴哔哩哔哩博客主视频教程,感谢其教程为我开启了爬虫之旅:https://www.bilibili.com/video/BV1Yt4y1Y7nt?t=3 ...
- 使用vue-cli创建第一个vue项目
命令提示符切换至需要创建项目的目录: 直接在路径输入cmd在按键盘的enter键打开的终端就直接切换到该目录下 (1)输入以下命令: vue create 项目名称 (2)我这里选手动选择,键盘上下按 ...
- Java读取数据库表(二)
Java读取数据库表(二) application.properties db.driver.name=com.mysql.cj.jdbc.Driver db.url=jdbc:mysql://loc ...
- 如何在 🤗 Space 上托管 Unity 游戏
你知道吗?Hugging Face Space 可以托管自己开发的 Unity 游戏!惊不惊喜,意不意外?来了解一下吧! Hugging Face Space 是一个能够以简单的方式来构建.托管和分享 ...
- 【python爬虫】对于微博用户发表文章内容和评论的爬取
此博客仅作为交流学习 对于喜爱的微博用户文章内容进行爬取 (此部分在于app页面进行爬取,比较方便) 分析页面 在这里进行json方法进行,点击Network进行抓包 发现数据加载是由这个页面发出的, ...
- 把ChatGPT调教成机器学习专家,以逻辑回归模型的学习为例
大家好我是章北海mlpy 看到一个蛮有意思的项目,可以把ChatGPT调教成导师 https://github.com/JushBJJ/Mr.-Ranedeer-AI-Tutor 可以根据你选择的学习 ...
- 2022-11-21:第N高的薪水。表结构和数据的sql语句如下。请问sql语句如何写? DROP TABLE IF EXISTS employee; CREATE TABLE employee (
2022-11-21:第N高的薪水.表结构和数据的sql语句如下.请问sql语句如何写? DROP TABLE IF EXISTS employee; CREATE TABLE employee ( ...