哈希表(hash)
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存储存位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。 (来自维基百科)
其中前边说到的离散化也是一种特殊的哈希方式,只不过离散化注重保序性,因此使用二分查找的方法。
其中存在问题就是:可能会把不同的数映射成相同的数,这就是哈希冲突,则我们处理冲突的方法就是将一组关键字映射到一个有限的连续的地址集(区间)上,到时候我们查找的时候就可以顺着这个地址依次查找。
而处理冲突的两种方法:拉链法和开放寻址法
拉链法:
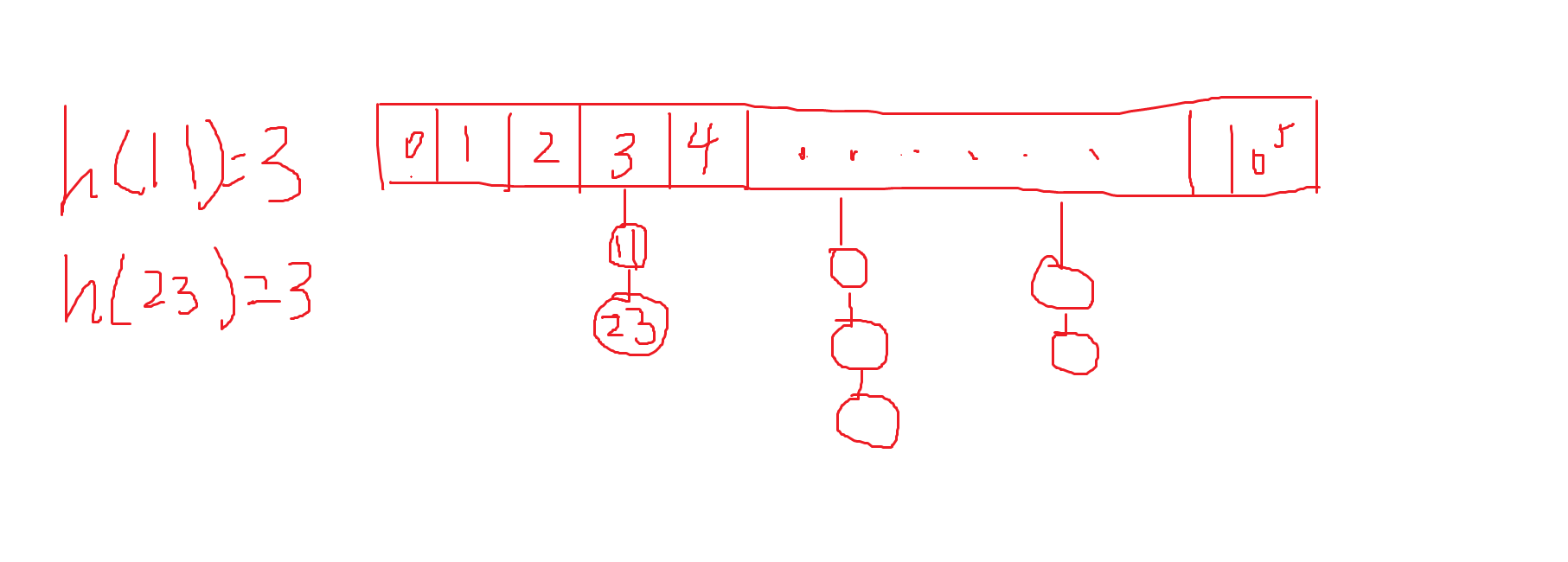
这种方法就是把映射值相同的点像链表一样挂在同一个地址上,当我们寻找的时候就可以通过地址来直接索引。
而寻找这个地址或者说映射的方法就是取模(mod),而mod的数最好就是大于映射范围的第一个质数,这样会更大的减少冲突(数学推理不清楚,听大佬说的)。
取模的方法: k = (x % N + N) % N (N是映射后的范围,这样取模是为了防止负数)
开放寻址法
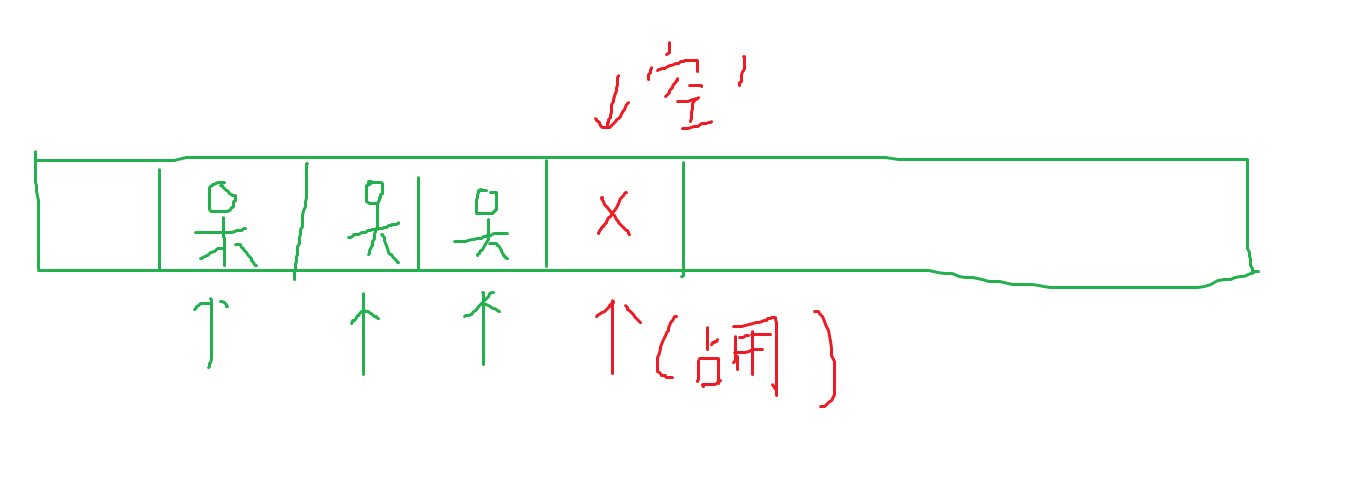
这种方法只需要开一个数组,不过这个数组的大小最好是映射后范围的2~3倍,那是因为这种方法再寻找映射后结果如果被占用则它顺着这个结果继续向下找直到找到空位。
说的形象一点就好比上厕所:这个坑位有人,咱就必须取下一个坑位,直到找到一个空的坑位。
例题
模拟散列表
维护一个集合,支持如下几种操作:
“I x”,插入一个数x;
“Q x”,询问数x是否在集合中出现过;
现在要进行N次操作,对于每个询问操作输出对应的结果。
输入格式
第一行包含整数N,表示操作数量。
接下来N行,每行包含一个操作指令,操作指令为”I x”,”Q x”中的一种。
输出格式
对于每个询问指令“Q x”,输出一个询问结果,如果x在集合中出现过,则输出“Yes”,否则输出“No”。
每个结果占一行。
数据范围
1 ≤ N ≤ 10^5
−10^9 ≤ x ≤ 10^9
输入样例:
5
I 1
I 2
I 3
Q 2
Q 5
输出样例:
Yes
No
拉链法Code:
#include <iostream>
#include <cstring>
using namespace std;
const int N = 100003; //寻找一个大于映射范围的第一个质数 最好用质数取模
int e[N], ne[N], idx, h[N];
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx;
idx++;
}
bool query(int x)
{
int k = (x % N + N) %N;
for(int i = h[k]; i != -1; i = ne[i])
{
if(e[i] == x)
{
return true;
}
}
return false;
}
int main()
{
int n;
scanf("%d", &n);
memset(h, -1, sizeof(h));
while(n--)
{
int x;
char op[2];
scanf("%s%d", op, &x);
if(*op == 'I') insert(x);
else
{
if(query(x)) printf("Yes\n");
else printf("No\n");
}
}
system("pause");
return 0;
}
开放寻址法Code:
#include <iostream>
#include <cstring>
using namespace std;
const int N = 200003, null = 0x3f3f3f3f; //数组开到个数上限的2~3倍, null表示为空
int h[N];
int finds(int x) //两个作用:1.寻找可以插入的位置 2.寻找哈希表中是否存在要查找的数字
{
int t = (x % N + N) % N;
while(h[t] != null && h[t] != x)
{
t++;
if(t == N) t = 0; //如果找到尾则从头寻找
}
return t;
}
int main()
{
memset(h, 0x3f, sizeof(h)); //寻找一个标志 这个标志大于x的范围
int n;
scanf("%d", &n);
while(n--)
{
char op[2];
int x;
scanf("%s%d", op, &x);
if(*op == 'I') h[finds(x)] = x;
else
{
if(h[finds(x)] != null) puts("Yes");
else puts("No");
}
}
return 0;
}
字符串哈希
字符串哈希就是把一个字符串哈希为整数,具体方法就是把一个字符串具体看成一个P进制数(P不确定),然后我们把他换算成十进制数字,这样就可以直接通过数字来判断两个字符串是否相等。(相当厉害并且好用的一种方法)。
给定一个长度为n的字符串,再给定m个询问,每个询问包含四个整数l1,r1,l2,r2,请你判断[l1,r1]和[l2,r2]这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数n和m,表示字符串长度和询问次数。
第二行包含一个长度为n的字符串,字符串中只包含大小写英文字母和数字。
接下来m行,每行包含四个整数l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从1开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出“Yes”,否则输出“No”。
每个结果占一行。
数据范围
1 ≤ n,m ≤ 10^5
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
思路:直接把每个字符串的哈希值存入一个数组,然后对数组排序后进行判断即可。
进制P,一般取为131,1331..(同样有数学证明)。
字符串换算为10进制范围会很大,所以我们使用 unsigned long long ,溢出会自动对2^64取模。
代码:
1 #include <iostream>
2 #include <algorithm>
3 #include <cstring>
4 #include <cstdio>
5
6 using namespace std;
7
8 typedef unsigned long long ULL;
9
10 const int N = 10010, P = 131;
11 char str[N];
12 ULL a[N];
13
14 ULL hashGet(char str[])
15 {
16 int len = strlen(str);
17 ULL res = 0;
18 for(int i = 0; i < len; i++) //将P进制换算为10进制
19 {
20 res = res*P + str[i];
21 }
22
23 return res;
24 }
25
26 int main()
27 {
28 int n, res = 1;
29
30 scanf("%d", &n);
31 for(int i = 0; i < n; i++)
32 {
33 scanf("%s", str);
34 a[i] = hashGet(str);
35 }
36
37 sort(a, a+n);
38
39 for(int i = 1; i < n; i++)
40 {
41 if(a[i] != a[i-1]) res++;
42 }
43
44 printf("%d\n", res);
45
46 return 0;
47 }
字符串前缀哈希法
前缀和与字符串哈希相结合,可以直接判断出一个字符串中某两段字符串是否相等,不再需要用kmp。
S = "ABCDEFG"
h[0] = 0
h[1] = "A" 的哈希值
h[2] = "AB" 的哈希值
h[3] = "ABC" 的哈希值
h[4] = "ABCD" 的哈希值
.......
利用前缀哈希,就可以计算出所有字符串字段的哈希值,如图求L~R的哈希值,我们已经有了hash[R],hash[L-1]的哈希值。
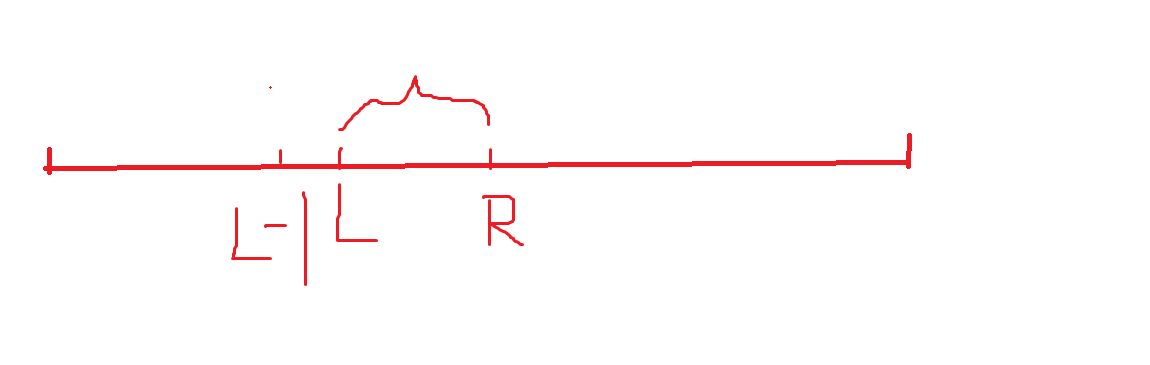
同样把字符串看作P进制数,则左边就是高位 右边就是低位,要求出L~R的哈希值我们要做的就是把h[L-1]的P进制左移与R的高位对齐,相减即可。
假设进制P为2:两个字符串分别是,求hash
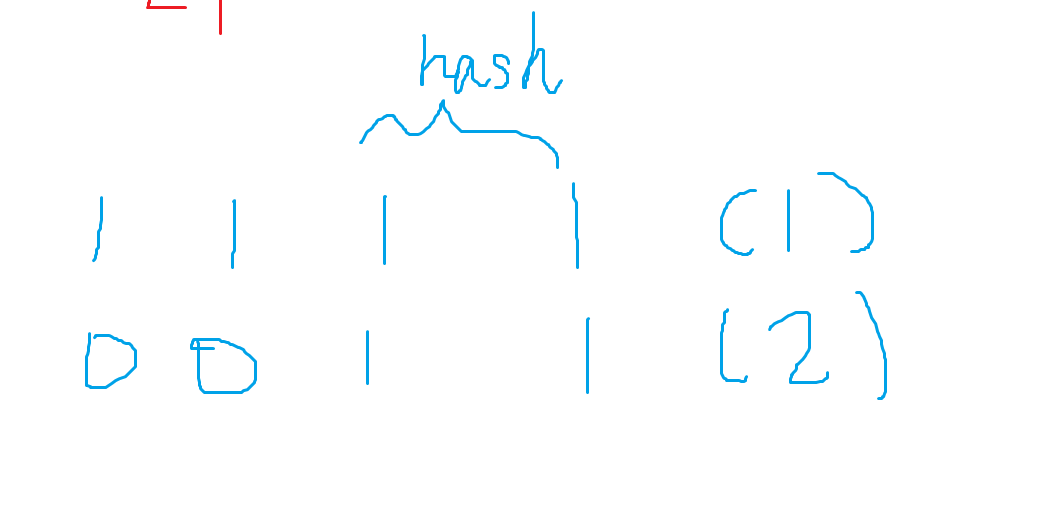
现在要做的就是把2左移两位,然后相减,得出hash,所以这里的P进制数也是这个道理。
L~R计算哈希值计算公式:\(h[R] - h[L-1]*P^{L-R+1}\)
所以再判断两个字串是否相等时可以直接通过两个字符串的左右边界得出两个字符串的哈希值来判断。
例题
给定一个长度为n的字符串,再给定m个询问,每个询问包含四个整数l1,r1,l2,r2,请你判断[l1,r1]和[l2,r2]这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数n和m,表示字符串长度和询问次数。
第二行包含一个长度为n的字符串,字符串中只包含大小写英文字母和数字。
接下来m行,每行包含四个整数l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从1开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出“Yes”,否则输出“No”。
每个结果占一行。
数据范围
1 ≤ n,m ≤ 10^5
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
#include <iostream>
using namespace std;
typedef unsigned long long ULL;
const int N = 100010, P = 131;
int p[N], h[N];
char str[N];
ULL get(int l, int r)
{
return h[r] - h[l-1]*p[r-l+1];
}
int main()
{
int n, m;
scanf("%d%d", &n, &m);
scanf("%s", str+1);
p[0] = 1;
for(int i = 1; i <= n; i++)
{
h[i] = h[i-1]*P + str[i];
p[i] = p[i-1]*P;
}
while(m--)
{
int l1, r1, l2, r2;
scanf("%d%d%d%d", &l1, &r1, &l2, &r2);
if(get(l1, r1) == get(l2, r2)) puts("Yes");
else puts("No");
}
system("pause");
return 0;
}
哈希表(hash)的更多相关文章
- 算法与数据结构基础 - 哈希表(Hash Table)
Hash Table基础 哈希表(Hash Table)是常用的数据结构,其运用哈希函数(hash function)实现映射,内部使用开放定址.拉链法等方式解决哈希冲突,使得读写时间复杂度平均为O( ...
- 哈希表(Hash)的应用
$hs=@() #定义数组 $hs=@{} #定义Hash表,使用哈希表的键可以直接访问对应的值,如 $hs["王五"] 或者 $hs.王五 的值为 75 $hs=@''@ #定义 ...
- PHP关联数组和哈希表(hash table) 未指定
PHP有数据的一个非常重要的一类,就是关联数组.又称为哈希表(hash table),是一种很好用的数据结构. 在程序中.我们可能会遇到须要消重的问题,举一个最简单的模型: 有一份username列表 ...
- (四)Redis哈希表Hash操作
Hash全部命令如下: hset key field value # 将哈希表key中的字段field的值设为value hget key field # 返回哈希表key中的字段field的值val ...
- 词典(二) 哈希表(Hash table)
散列表(hashtable)是一种高效的词典结构,可以在期望的常数时间内实现对词典的所有接口的操作.散列完全摒弃了关键码有序的条件,所以可以突破CBA式算法的复杂度界限. 散列表 逻辑上,有一系列可以 ...
- 数据结构,哈希表hash设计实验
数据结构实验,hash表 采用链地址法处理hash冲突 代码全部自己写,转载请留本文连接, 附上代码 #include<stdlib.h> #include<stdio.h> ...
- Redis原理再学习04:数据结构-哈希表hash表(dict字典)
哈希函数简介 哈希函数(hash function),又叫散列函数,哈希算法.散列函数把数据"压缩"成摘要,有的也叫"指纹",它使数据量变小且数据格式大小也固定 ...
- 什么叫哈希表(Hash Table)
散列表(也叫哈希表),是根据关键码值直接进行访问的数据结构,也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度.这个映射函数叫做散列函数,存放记录的数组叫做散列表. - 数据结构 ...
- 数据结构 哈希表(Hash Table)_哈希概述
哈希表支持一种最有效的检索方法:散列. 从根来上说,一个哈希表包含一个数组,通过特殊的索引值(键)来访问数组中的元素. 哈希表的主要思想是通过一个哈希函数,在所有可能的键与槽位之间建立一张映射表.哈希 ...
- golang数据结构之散哈希表(Hash)
hash.go package hash import ( "fmt" ) type Emp struct { ID int Name string Next *Emp } //第 ...
随机推荐
- React报错:Module not found: Error: Can't resolve 'react-router-dom'
解决方案 npm install -S react-router-dom@5 参考链接 https://stackoverflow.com/questions/53914013/failed-to-c ...
- [django]数据的导入和导出
除了使用mysqldump或者MySQL客户端进行数据导出,django也提供了类似的功能. 导出 # 导出整个数据库并保存为json文件 python manage.py dumpdata > ...
- xss-labs靶场
在线XSS-labs靶场:https://xssaq.com/yx/ 靶场搭建 靶场是直接使用docker搭建的 docker pull vulfocus/xss-labs 启动靶场 docker r ...
- 《代码整洁之道 Clean Code》学习笔记 Part 1
前段时间在看<架构整洁之道>,里面提到了:构建一个好的软件系统,应该从写整洁代码做起.毕竟,如果建筑使用的砖头质量不佳,再好的架构也无法造就高质量的建筑.趁热打铁,翻出<代码整洁之道 ...
- 《CTFshow-Web入门》03. Web 21~30
@ 目录 web21 题解 原理 web22 题解 原理 web23 题解 原理 web24 题解 原理 web25 题解 原理 web26 题解 web27 题解 web28 题解 web29 题解 ...
- ELK环境部署-基础环境安装(一)
ELK简介 ElasticSearch工作原理以及专用名词 ELK是Elasticsearch(ES) , Logstash, Kibana的结合,是一个开源日志收集软件. Elasticsearch ...
- 我的 Kafka 旅程 - 基于账号密码的 SASL+PLAIN 认证授权 · 配置 · 创建账号 · 用户授权 · .NET接入
本文基于 Kafka 3.0+ 的 KRaft 模式来阐述 默认的 Kafka 不受认证约束,可不用账号就可以连接到服务,也就是默认的 PLAIN 方式,不需要认证:配置了 SASL 认证之后,连接K ...
- 「atcoder - abc246h」01? Queries
link. 平时基本打不到 ex,这个 ex 还是比较 ez 的,但也有些需要注意的地方. 考虑 dp 规划前缀,设 \(f[i][0/1]\) 表示前缀 \([1, i]\) 否是选 \(i\) 的 ...
- nginx ServerName匹配规则
1.同一个主机配置不同端口,访问不同资源 worker_processes 1; events { worker_connections 1024; } http { include mime.typ ...
- 4款免费且实用的.NET反编译工具
反编译工具的作用 .NET反编译工具能够将已经编译好的.NET程序集转换为易于理解的源代码,它们可以帮助开发人员恢复丢失的源代码.理解和分析第三方组件dll.学习其他人的代码.更好的查找修复 bug ...