数据标注工具 Label-Studio
文档抽取任务Label Studio使用指南
目录
1. 安装
以下标注示例用到的环境配置:
- Python 3.8+
- label-studio == 1.6.0
- paddleocr >= 2.6.0.1
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.6.0 -i https://pypi.tuna.tsinghua.edu.cn/simplelabel
安装完成后,运行以下命令行:
label-studio start
如报:[sqlite3.OperationalError: no such function: JSON_VALID](https://www.cnblogs.com/vipsoft/p/17562196.html)
在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。
用邮箱注册一个帐号
2. 文档抽取任务标注
2.1 项目创建
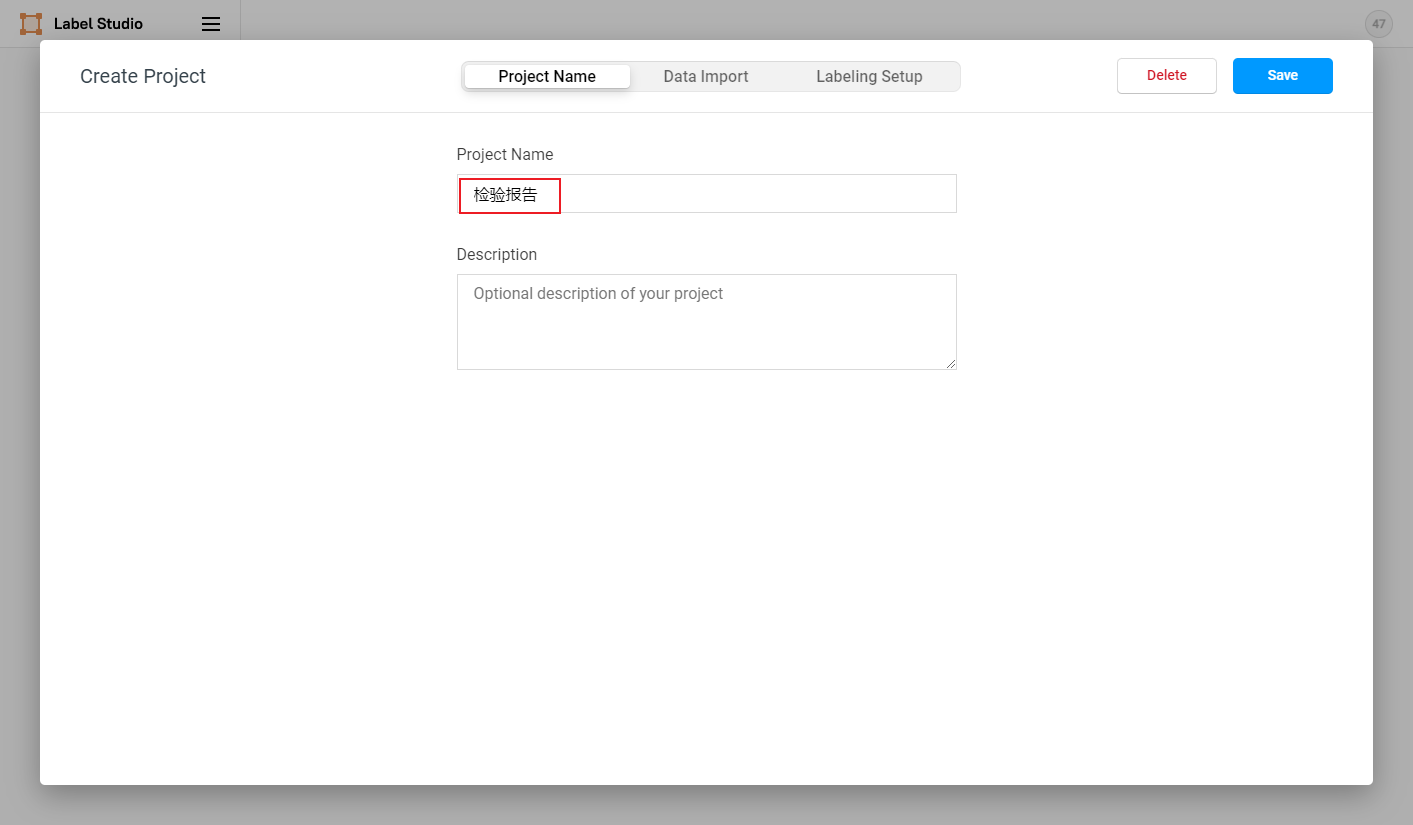
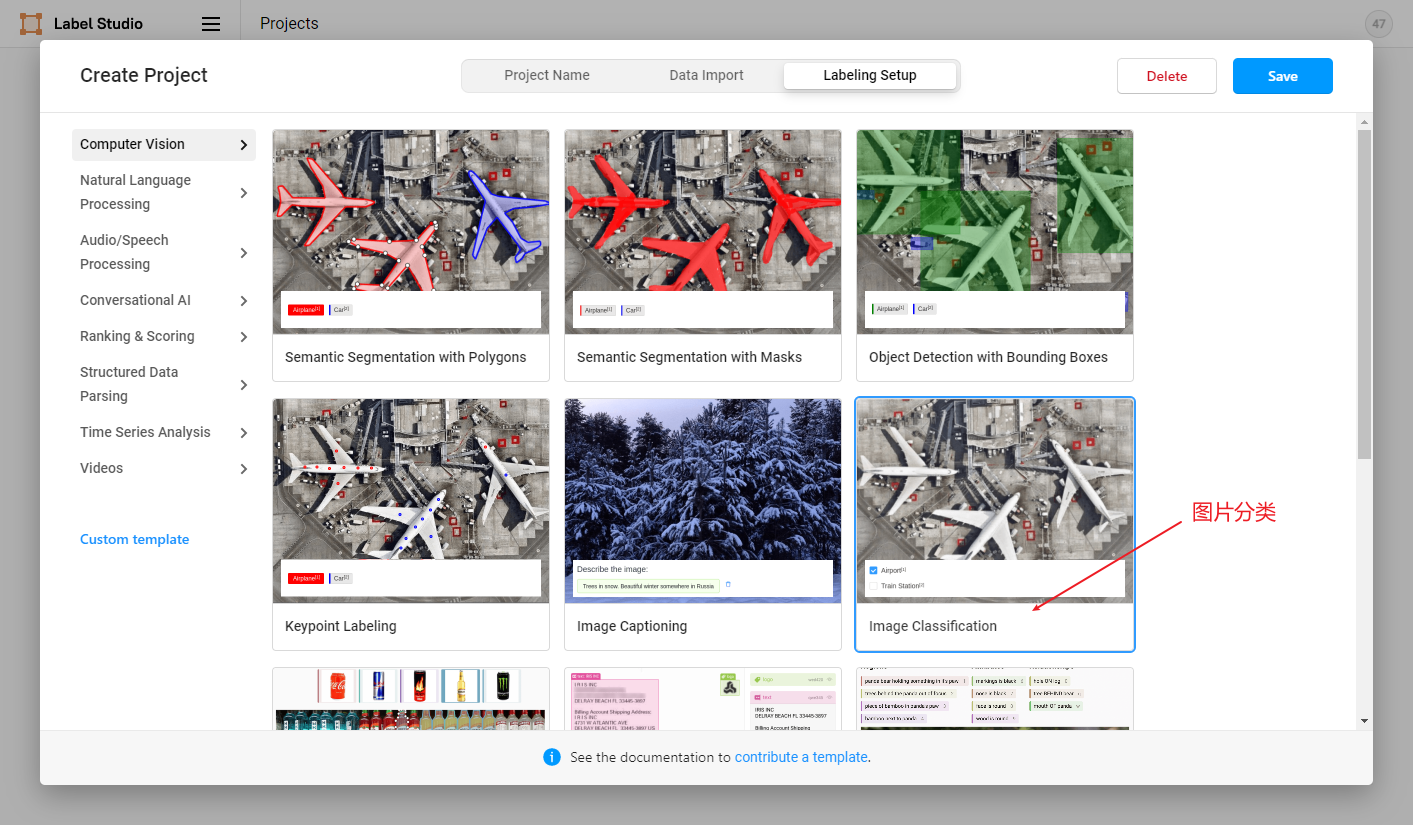
点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。
- 填写项目名称、描述
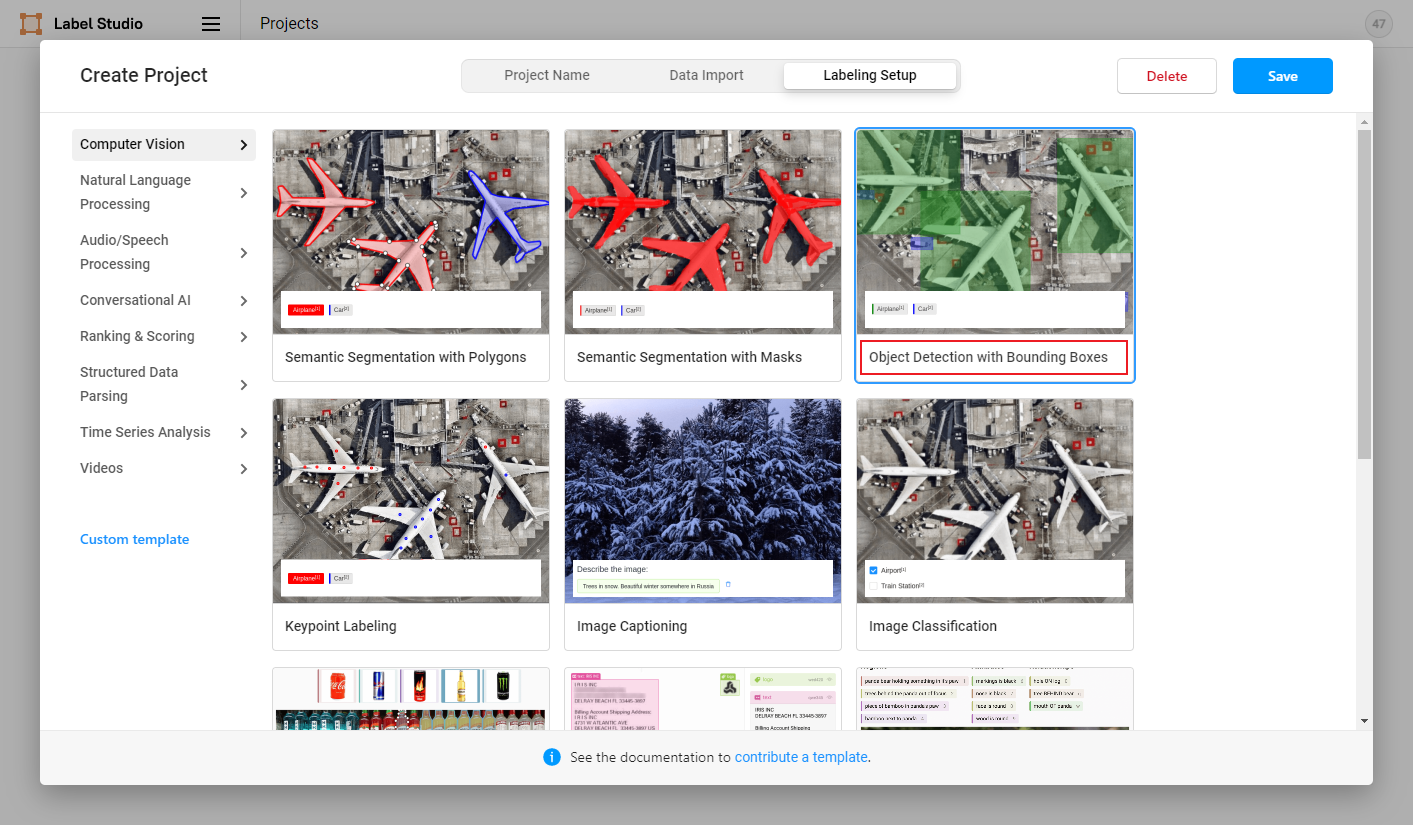
- 命名实体识别、关系抽取、事件抽取、实体/评价维度分类任务选择``Object Detection with Bounding Boxes`
- 文档分类任务选择``Image Classification`
- 添加标签(也可跳过后续在Setting/Labeling Interface中添加)
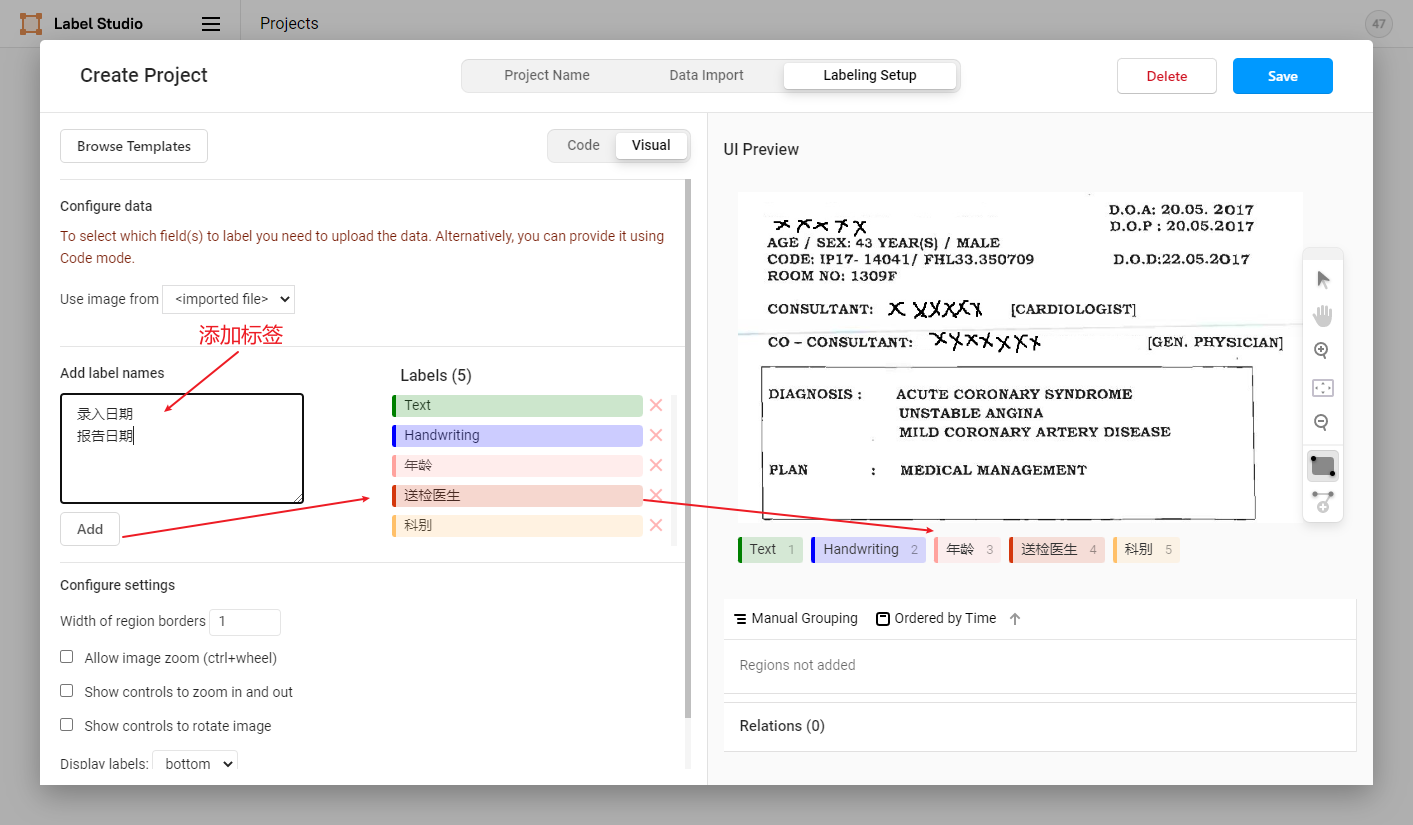
图中展示了Span实体类型标签的构建,其他类型标签的构建可参考2.3标签构建
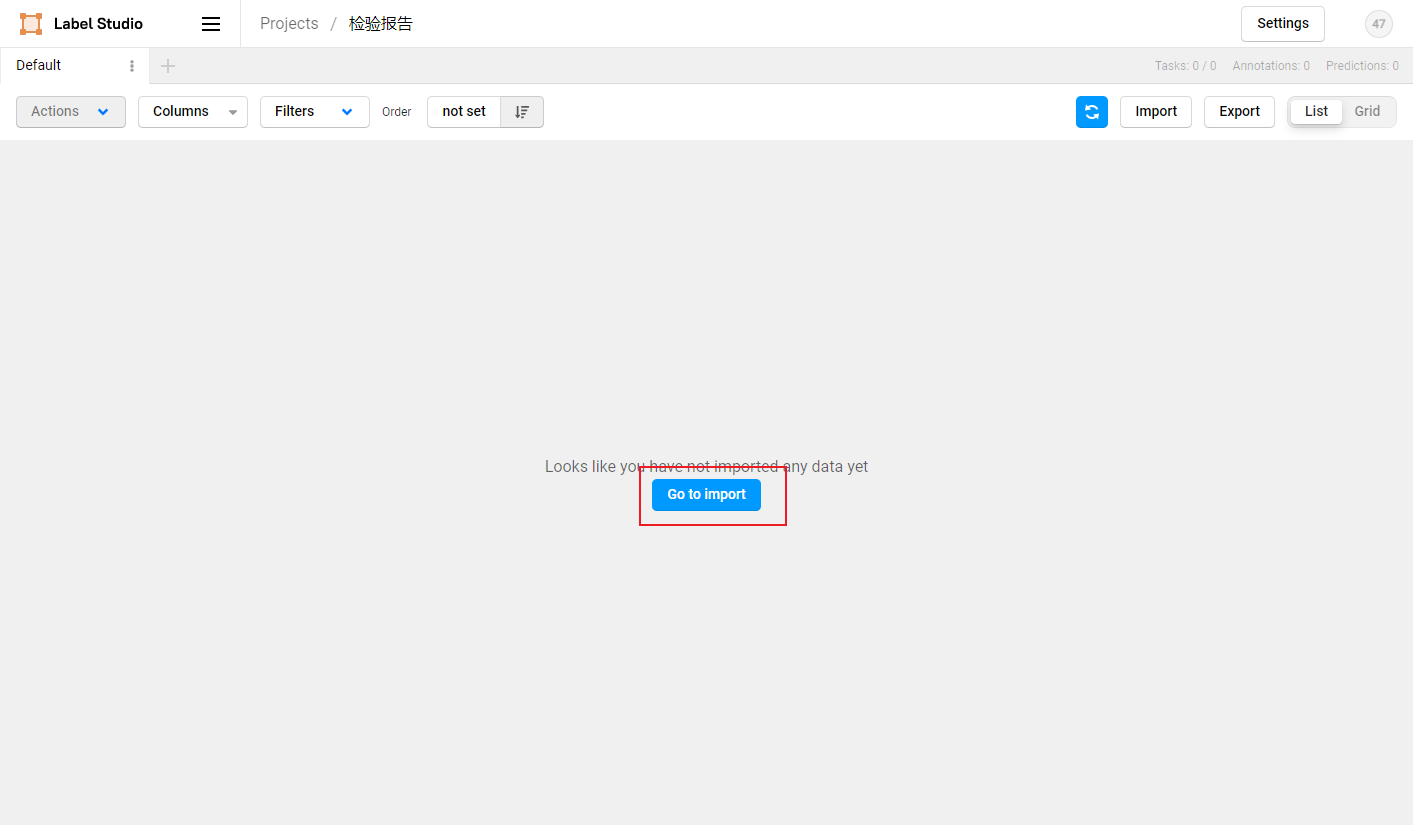
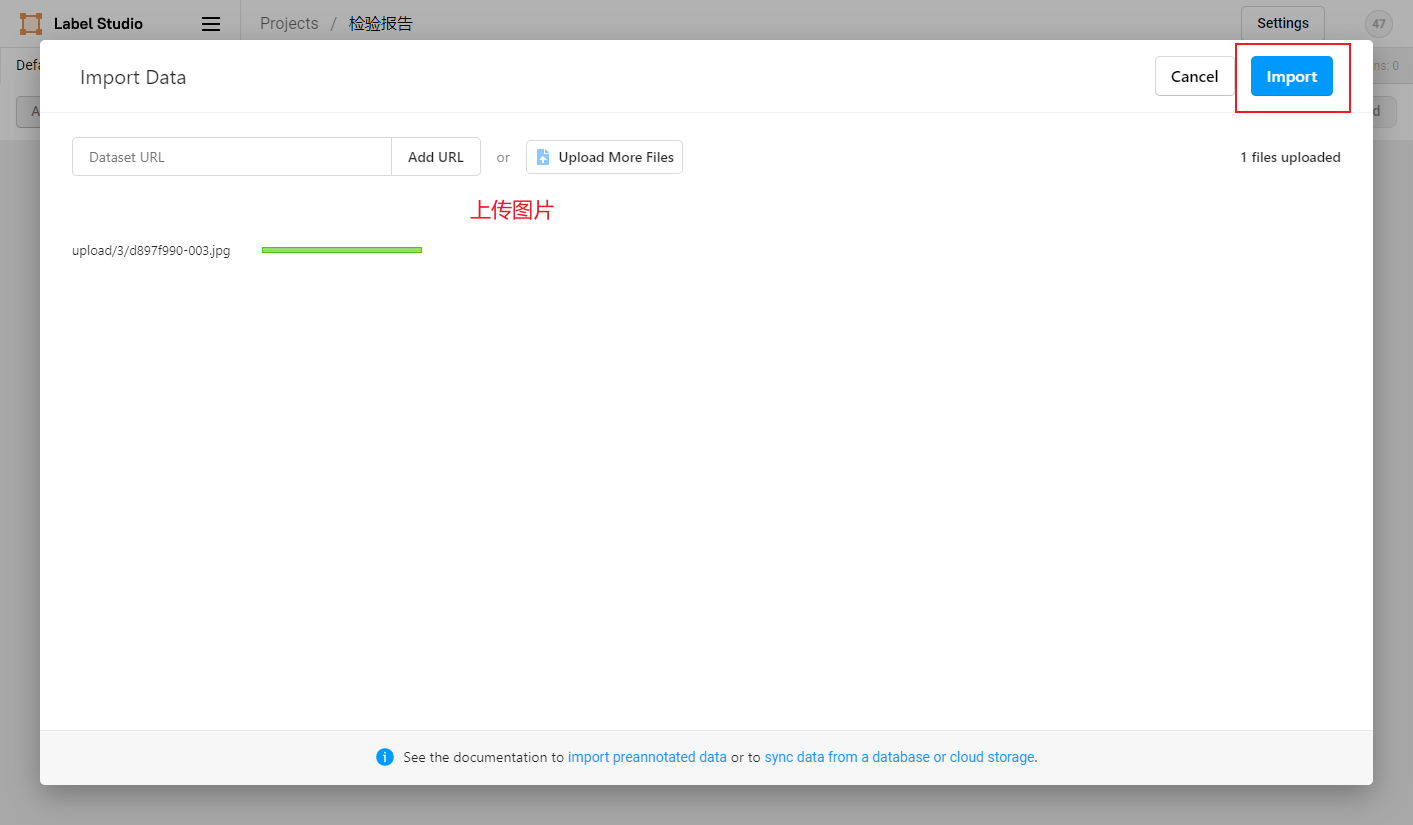
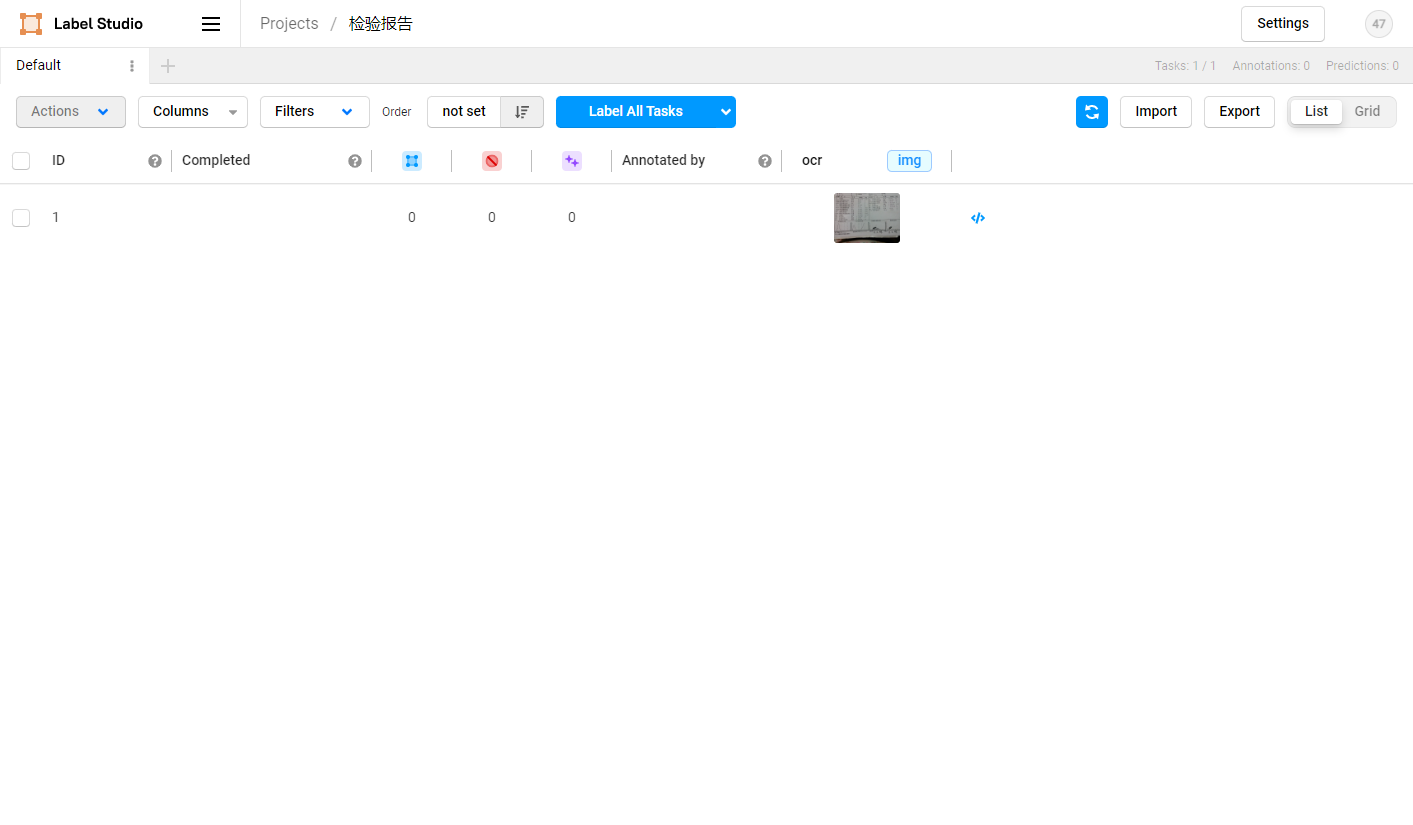
2.2 数据上传
先从本地或HTTP链接上传图片,然后选择导入本项目。
2.3 标签构建
- Span实体类型标签
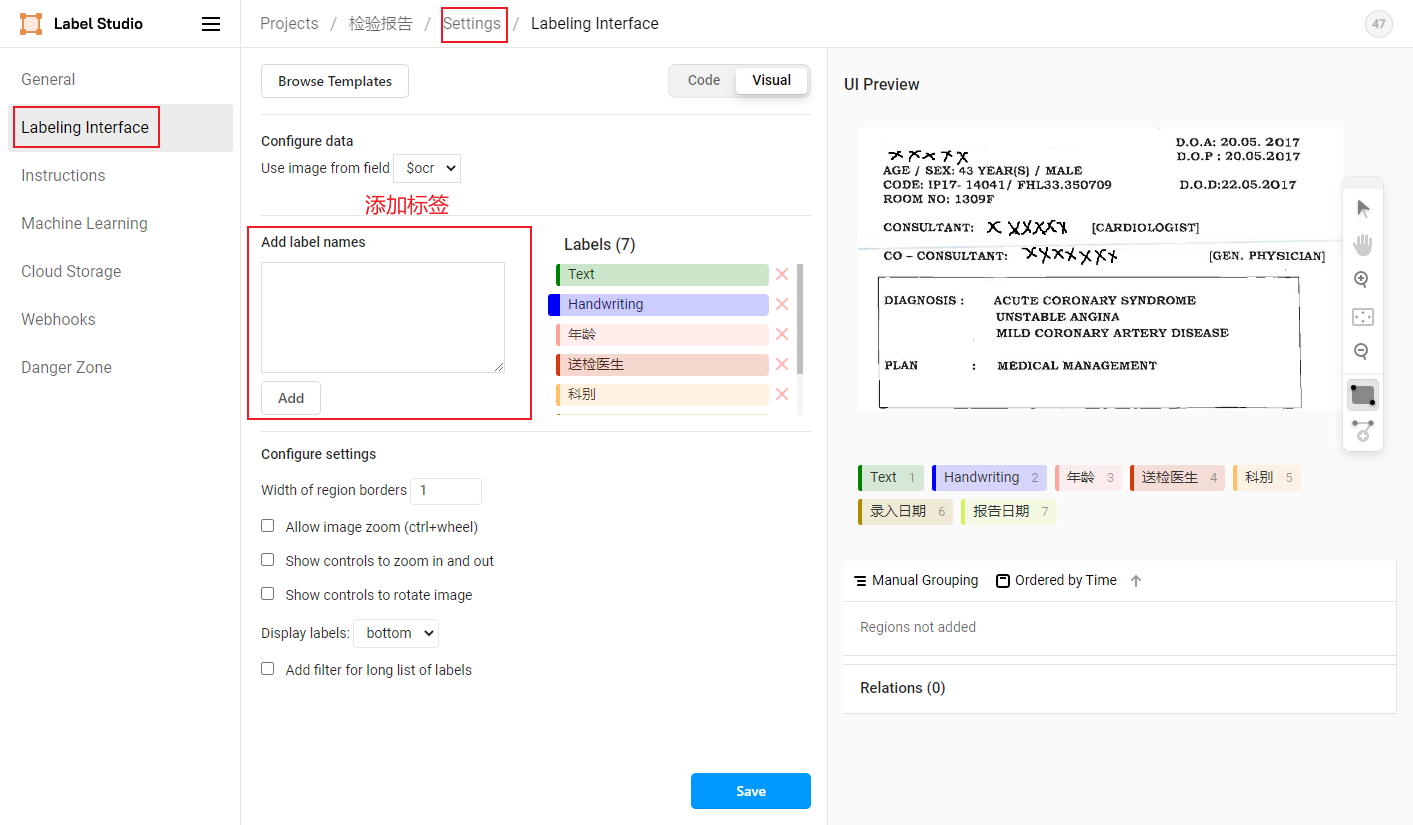
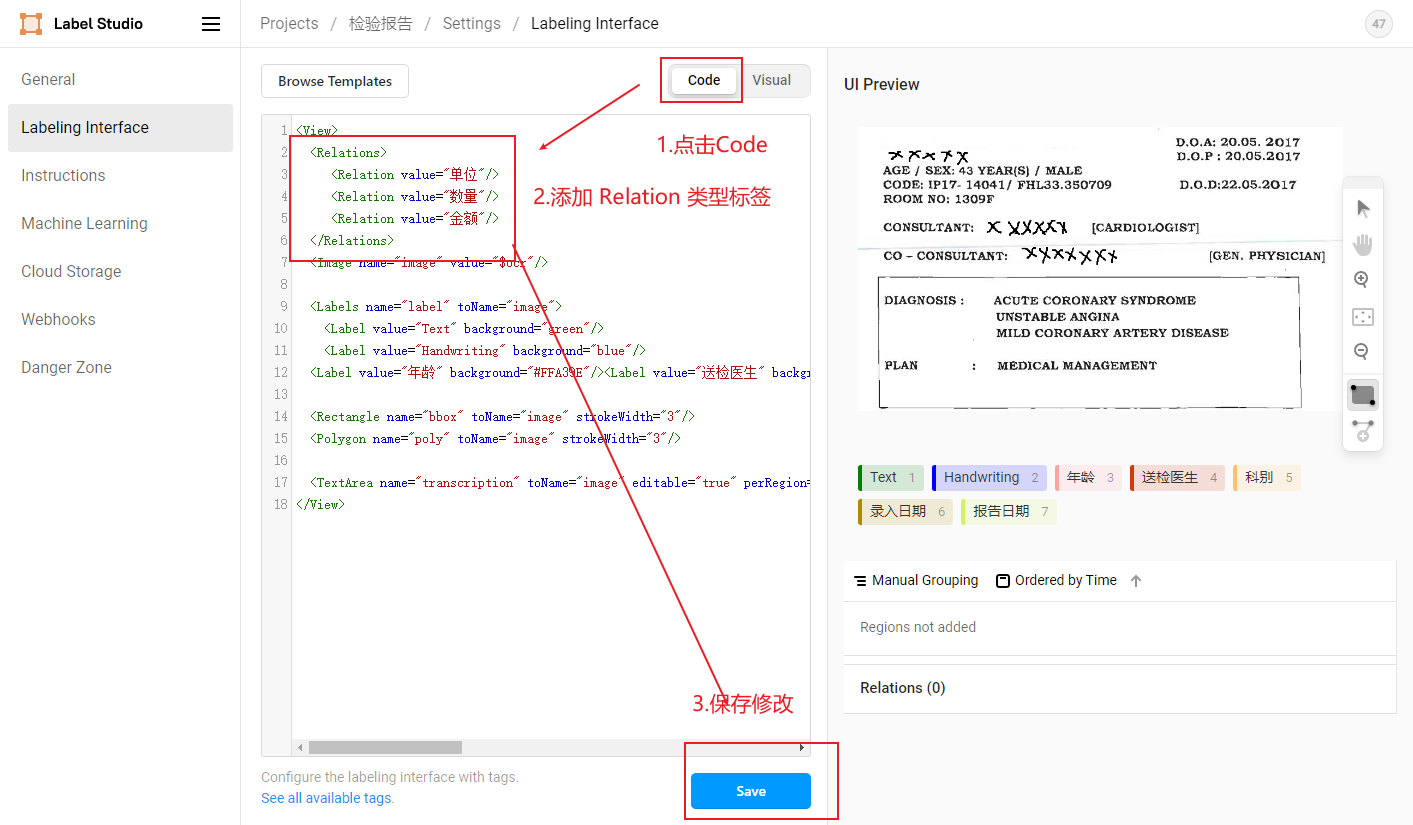
- Relation关系类型标签
Relation XML模板:
<Relations>
<Relation value="单位"/>
<Relation value="数量"/>
<Relation value="金额"/>
</Relations>
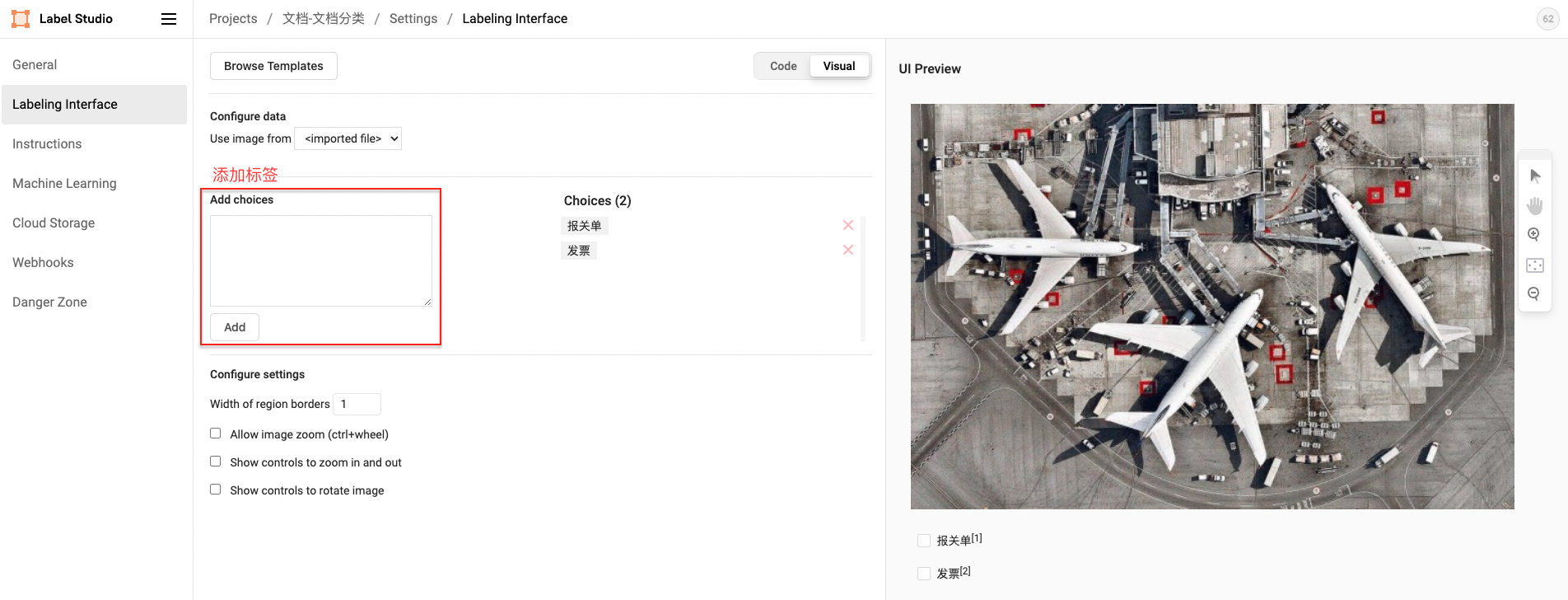
- 分类类别标签
2.4 任务标注
实体抽取
标注示例:

该标注示例对应的schema为:
schema = ['开票日期', '名称', '纳税人识别号', '地址、电话', '开户行及账号', '金额', '税额', '价税合计', 'No', '税率']
关系抽取
Step 1. 标注主体(Subject)及客体(Object)
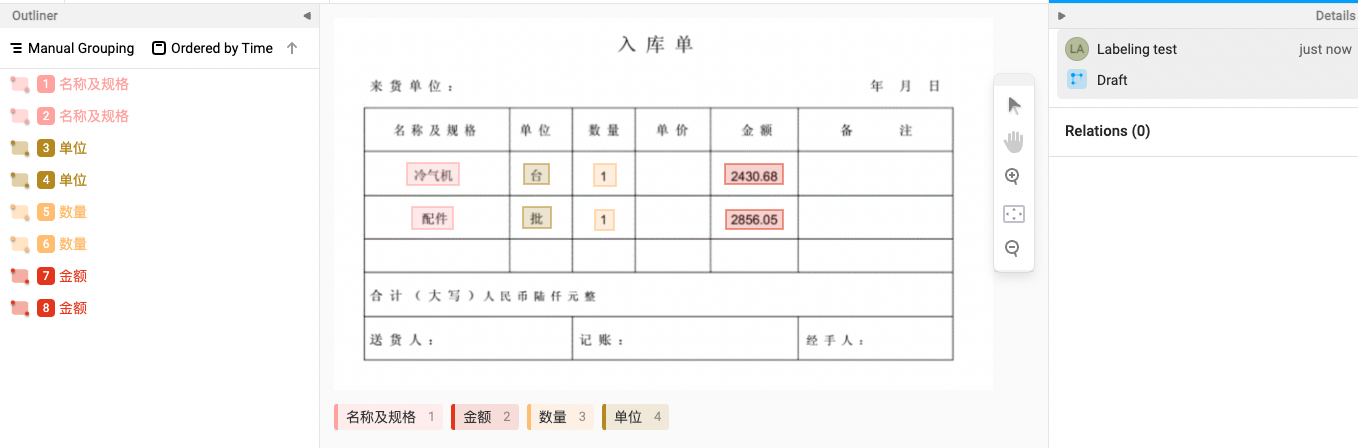
Step 2. 关系连线,箭头方向由主体(Subject)指向客体(Object)
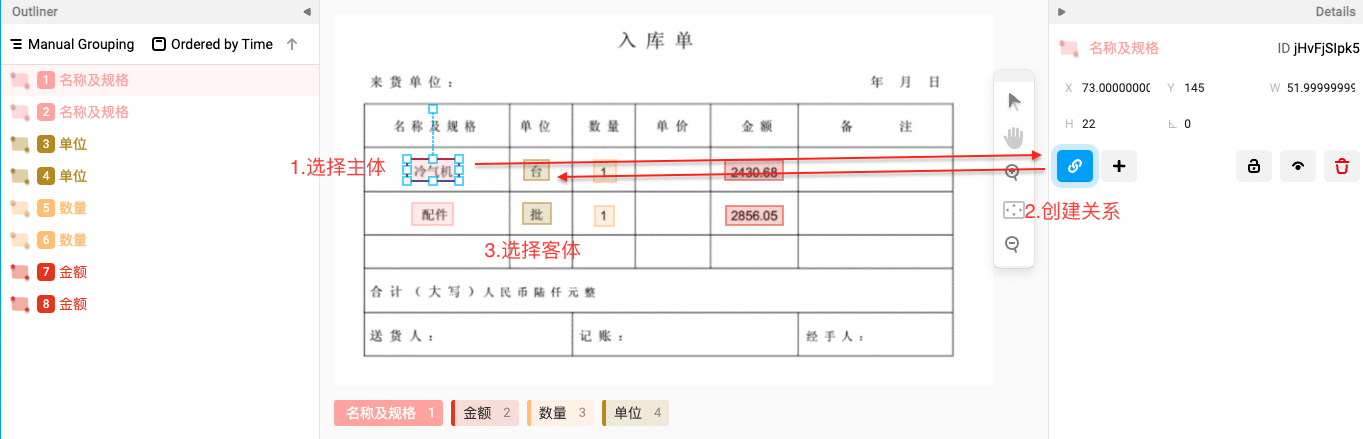
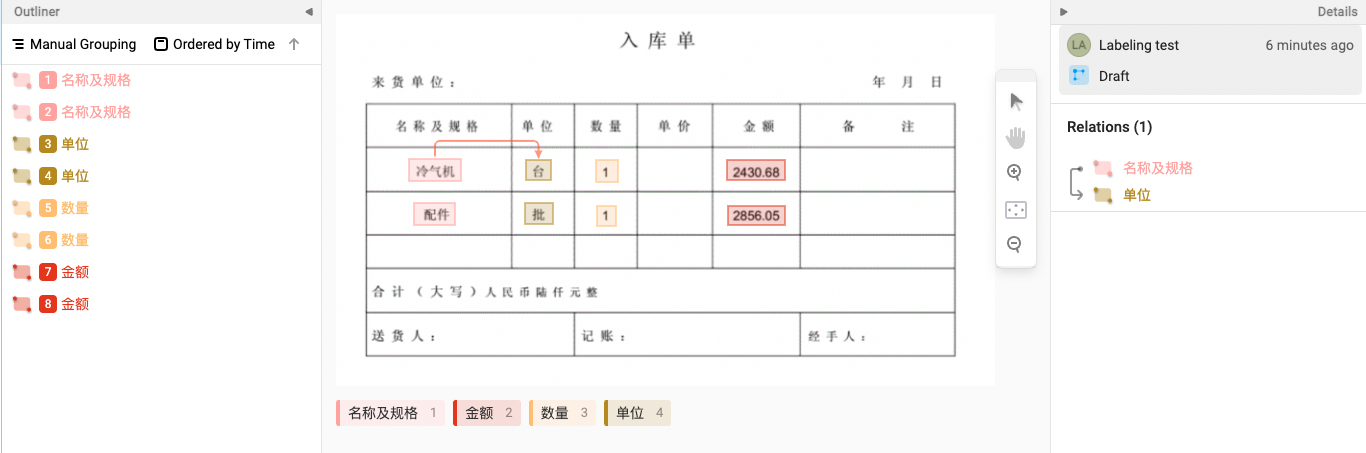
Step 3. 添加对应关系类型标签

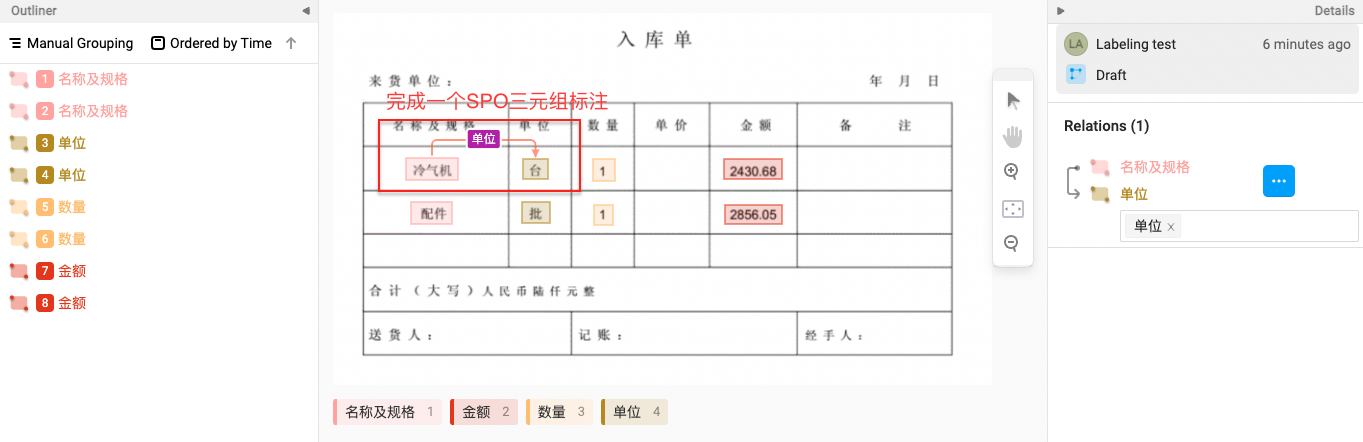
Step 4. 完成标注
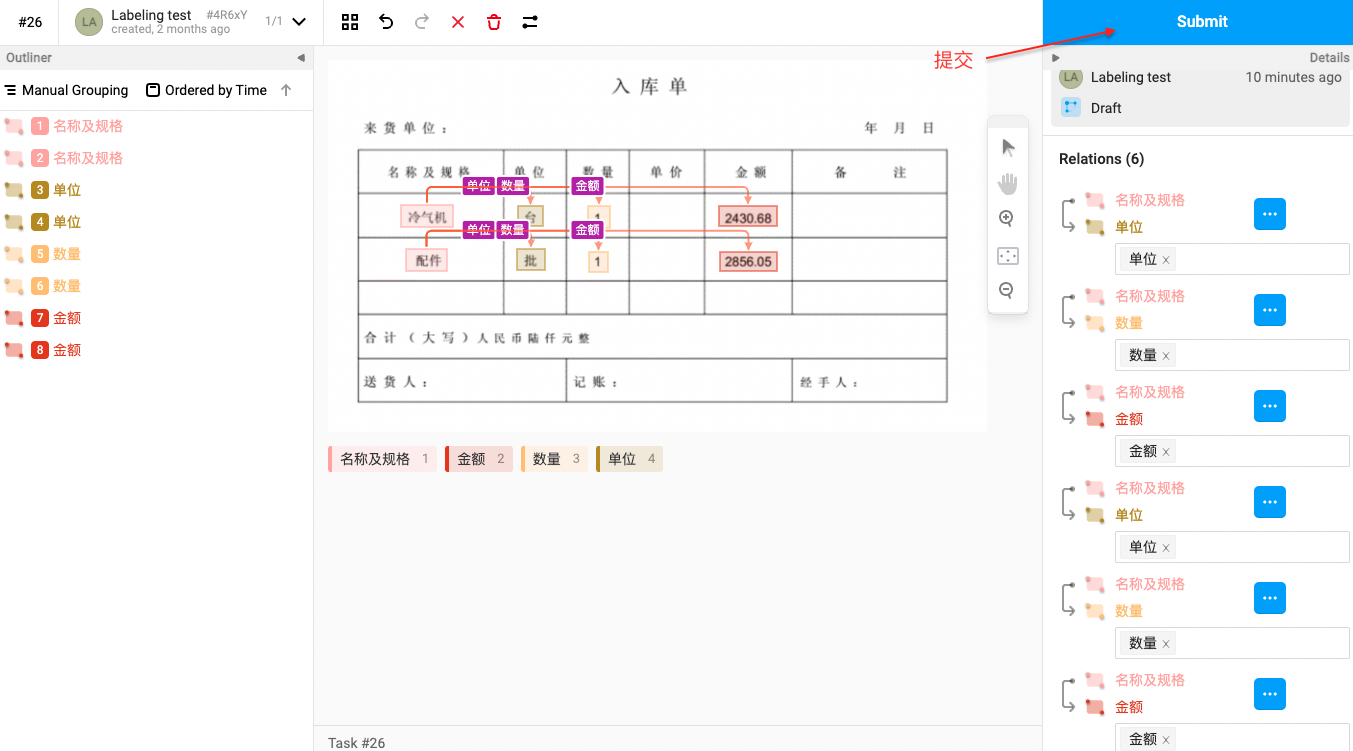
该标注示例对应的schema为:
schema = {
'名称及规格': [
'金额',
'单位',
'数量'
]
}
文档分类
标注示例

该标注示例对应的schema为:
schema = '文档类别[发票,报关单]'
2.5 数据导出
勾选已标注图片ID,选择导出的文件类型为JSON,导出数据:

2.6 数据转换
将导出的文件重命名为label_studio.json后,放入./document/data目录下,并将对应的标注图片放入./document/data/images目录下(图片的文件名需与上传到label studio时的命名一致)。通过label_studio.py脚本可转为UIE的数据格式。
- 路径示例
./document/data/
├── images # 图片目录
│ ├── b0.jpg # 原始图片(文件名需与上传到label studio时的命名一致)
│ └── b1.jpg
└── label_studio.json # 从label studio导出的标注文件
- 抽取式任务
python label_studio.py \
--label_studio_file ./document/data/label_studio.json \
--save_dir ./document/data \
--splits 0.8 0.1 0.1\
--task_type ext
- 文档分类任务
python label_studio.py \
--label_studio_file ./document/data/label_studio.json \
--save_dir ./document/data \
--splits 0.8 0.1 0.1 \
--task_type cls \
--prompt_prefix "文档类别" \
--options "发票" "报关单"
2.7 更多配置
label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为["正向", "负向"]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度分类任务有效。默认为"##"。schema_lang:选择schema的语言,将会应该训练数据prompt的构造方式,可选有ch和en。默认为ch。ocr_lang:选择OCR的语言,可选有ch和en。默认为ch。layout_analysis:是否使用PPStructure对文档进行布局分析,该参数只对文档类型标注任务有效。默认为False。
备注:
- 默认情况下 label_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 label_studio.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过
negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。 - 对于从label_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。
References
数据标注工具 Label-Studio的更多相关文章
- 零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程. 1.通用文本分类技术UTC介绍 本项目提供基于通用文本分类 UTC(Universal Text C ...
- AI数据标注行业面临的5大发展困局丨曼孚科技
根据艾瑞咨询发布的行业白皮书显示,2018年中国人工智能基础数据服务市场规模为25.86亿元,预计2025年市场规模将突破113亿元,行业年复合增长率达到了23.5%. 作为人工智能产业的基石,数据 ...
- 曼孚科技:数据标注,AI背后的百亿市场
1. 两年前,来自山东农村的王磊成为了一位数据标注员.彼时的他,工作内容非常简单且枯燥:识别图片中人的性别. 然而,一段时间之后,他注意到分配给他的任务开始变得越来越复杂:从识别性别到年龄,从框选 ...
- 3.基于Label studio的训练数据标注指南:文本分类任务
文本分类任务Label Studio使用指南 1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取).文本分类等 2.基于Label studio的训练数据标注指南:(智能文档) ...
- 基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!
基于Label studio实现UIE信息抽取智能标注方案,提升标注效率! 项目链接见文末 人工标注的缺点主要有以下几点: 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模 ...
- Win10下数据增强及标注工具安装
Win10下数据增强及标注工具安装 一. 数据增强利器—Augmentor 1.安装 只需在控制台输入:pip install Augmentor 2.简介 Augmentor是用于图像增强的软件 ...
- 标注工具doccano导出数据为空的解决办法
地址:https://github.com/taishan1994/doccano_export doccano_export 使用doccano标注工具同时导出实体和关系数据为空的解决办法.docc ...
- CocoStuff—基于Deeplab训练数据的标定工具【三、标注工具的使用】
一.说明 本文为系列博客第三篇,主要展示COCO-Stuff 10K标注工具的使用过程及效果. 本文叙述的步骤默认在完成系列文章[二]的一些下载数据集.生成超像素处理文件的步骤,如果过程中有提示缺少那 ...
- label studio 结合 MMDetection 实现数据集自动标记、模型迭代训练的闭环
前言 一个 AI 方向的朋友因为标数据集发了篇 SCI 论文,看着他标了两个多月的数据集这么辛苦,就想着人工智能都能站在围棋巅峰了,难道不能动动小手为自己标数据吗?查了一下还真有一些能够满足此需求的框 ...
- 推荐 | 中文文本标注工具Chinese-Annotator(转载)
自然语言处理的大部分任务是监督学习问题.序列标注问题如中文分词.命名实体识别,分类问题如关系识别.情感分析.意图分析等,均需要标注数据进行模型训练.深度学习大行其道的今天,基于深度学习的 NLP 模型 ...
随机推荐
- 10分钟极速入门dash应用开发
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/dash-master 大家好我是费老师,几天前我发布了由我开源维护的dash通用网页组件库fac的0 ...
- Python argparse参数管理学习笔记1
1.前言 最近尝试学习使用argparse进行参数管理,顺便改善一下我那丝毫都不专业的.简单粗暴的代码习惯. argparse模块可以让人轻松地编写用户友好地命令行接口,并且还能够自动生成帮助与使用手 ...
- 学习MASA第一天:MASA Blazor TEST项目创建
个人博客地址: https://note.raokun.top 拥抱ChatGPT,国内访问网站:https://www.playchat.top 学习MASA第一天:MASA Blazor TEST ...
- 深度学习-06(PaddlePaddle体系结构与基本概念[Tensor、Layer、Program、Variable、Executor、Place]线性回归、波士顿房价预测)
文章目录 深度学习-06(PaddlePaddle基础) paddlePaddle概述 PaddlePaddle简介 什么是PaddlePaddle 为什么学习PaddlePaddle PaddleP ...
- 【Redis】Redis 编译安装配置优化,多实例配置
一.Redis 配置详解 # Redis configuration file example. # # Note that in order to read the configuration fi ...
- "树形List"与"扁平List"互转(Java实现)
背景:在平时的开发中,我们时常会遇到下列场景 公司的组织架构的数据存储与展示 文件夹层级的数据存储与展示 评论系统中,父评论与诸多子评论的数据存储与展示 ...... 对于这种有层级的结构化数据,就像 ...
- 2021-04-16:摆放着n堆石子。现要将石子有次序地合并成一堆,规定每次只能选相邻的2堆石子合并成新的一堆,并将新的一堆石子数记为该次合并的得分。求出将n堆石子合并成一堆的最小得分(或最大得分)合
2021-04-16:摆放着n堆石子.现要将石子有次序地合并成一堆,规定每次只能选相邻的2堆石子合并成新的一堆,并将新的一堆石子数记为该次合并的得分.求出将n堆石子合并成一堆的最小得分(或最大得分)合 ...
- 2021-09-11:给你一个32位的有符号整数x,返回将x中的数字部分反转后的结果。反转后整数超过 32 位的有符号整数的范围就返回0,假设环境不允许存储 64 位整数(有符号或无符号)。
2021-09-11:给你一个32位的有符号整数x,返回将x中的数字部分反转后的结果.反转后整数超过 32 位的有符号整数的范围就返回0,假设环境不允许存储 64 位整数(有符号或无符号). 福大大 ...
- json和字典dict的区别
json和字典dict的区别? 银河有希子关注 2021.07.03 11:13:00字数 987阅读 173 作者:Gakki json和字典dict的区别? 字典写法:dict1 = {'Alic ...
- Event Tables for Efficient Experience Replay
Abstract 事件表分层抽样(SSET),它将ER缓冲区划分为事件表,每个事件表捕获最优行为的重要子序列. 我们证明了一种优于传统单片缓冲方法的理论优势,并将SSET与现有的优先采样策略相结合,以 ...