python中的set集合
当使用爬虫URL保存时,一般会选择set来保存urls,set是集合,集合中的元素不能重复,其次还有交集,并集等集合的功能,
爬虫每次获取的网页中提取网页中的urls,并保存,这就需要利用urls = set()
- 下面展示一下HTML解析器代码
#coding:utf-8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def parser(self,page_url,html_cont):
'''
用于解析网页内容抽取URL和数据
:param page_url: 下载页面的URL
:param html_cont: 下载的网页内容
:return:返回URL和数据
'''
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls,new_data
def _get_new_urls(self,page_url,soup):
'''
抽取新的URL集合
:param page_url: 下载页面的URL
:param soup:soup
:return: 返回新的URL集合
'''
new_urls = set()
#抽取符合要求的a标签
#原书代码
# links = soup.find_all('a',href=re.compile(r'/view/\d+\.htm'))
#2017-07-03 更新,原因百度词条的链接形式发生改变
links = soup.find_all('a', href=re.compile(r'/item/.*'))
for link in links:
#提取href属性
new_url = link['href']
#拼接成完整网址
new_full_url = urlparse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
'''
抽取有效数据
:param page_url:下载页面的URL
:param soup:
:return:返回有效数据
'''
data={}
data['url']=page_url
title = soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1')
data['title']=title.get_text()
summary = soup.find('div',class_='lemma-summary')
#获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回
data['summary']=summary.get_text()
return data
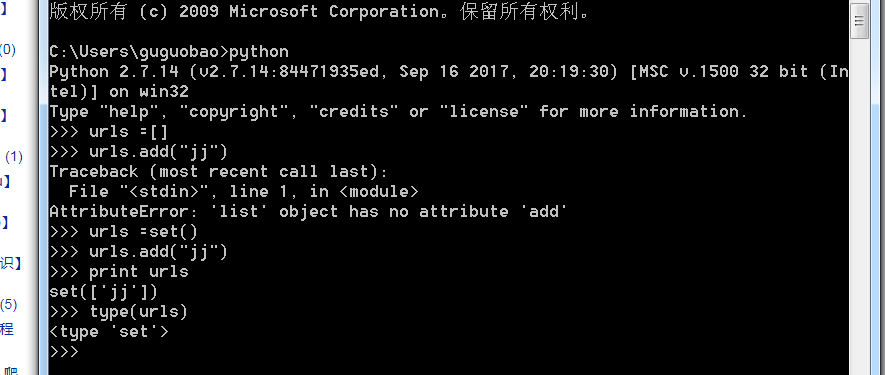
- 其次需要注意的是set可以add,而list不可以
python中的set集合的更多相关文章
- Python中字典和集合
Python中字典和集合 映射类型: 表示一个任意对象的集合,且可以通过另一个几乎是任意键值的集合进行索引 与序列不同,映射是无序的,通过键进行索引 任何不可变对象都可用作字典的键,如字符串.数字.元 ...
- 认识python中的set集合及其用法
python中,集合(set)是一个无序排列,可哈希, 支持集合关系测试,不支持索引和切片操作,没有特定语法格式, 只能通过工厂函数创建.集合里不会出现两个相同的元素, 所以集合常用来对字符串或元组或 ...
- Python中字典和集合的用法
本人开始学习python 希望能够慢慢的记录下去 写下来只是为了害怕自己忘记. python中的字典和其他语言一样 也是key-value的形式 利用空间换时间 可以进行快速的查找 key 是唯一的 ...
- Python中的SET集合操作
python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和 ...
- Python中的数据结构 --- 集合(set)
1.集合(set)里面的元素是不可以重复的 s={1,2,3,3,4,3,4} ## 输出之后,没有重复的 2.定义一个空集合 s = set([]) print s,type(s)3 ...
- python中的set集合和深浅拷贝
一.基础数据类型的补充 1.str中的join算法,将列表转换成字符串,并用'_'(或其他) li=['李嘉诚','马化腾','刘嘉玲','黄海峰',] s='_'.join(li) print(s) ...
- Python中字典,集合和元组函数总结
## 字典的所有方法- 内置方法 - 1 cmp(dict1, dict2) 比较两个字典元素. - 2 len(dict) 计算字典元素个数,即键的总数. - 3 str(dict) 输出字典可打印 ...
- 2018.8.3 python中的set集合及深浅拷贝
一.字符串和列表的相互转化 之前写到想把xx类型的数据转化成yy类型的数据,直接yy(xx)就可以了,但是字符串和列表的转化比较特殊,相互之间的转化要通过join()和split()来实现. 例如: ...
- day05 Python中的set集合
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的.以下是集合最重要的两点: 1.去重,把一个列表变成集合,就自动去重了. 2.关 ...
随机推荐
- css全部理解
如何设置标签样式 给标签设置长宽 只有块儿级标签才可以设置长宽 行内标签设置了没有任何作用(仅仅只取决于内部文本值) 字体颜色 color后面可以跟多种颜色数据 颜色英文 red #06a0de 直接 ...
- 下载安装mysql-connector
执行命令:python -m pip install mysql-connector 测试
- ios 打包下
一.打包真机方式 二.编译打包 三.配置打包信息 以下为打的包:
- 通过CSS实现 文字渐变色 的两种方式
说明 这次的重点就在于两个属性, background 属性 mask 属性这两个属性分别是两种实现方式的关键. 方式一 解释 <!DOCTYPE html> <html> & ...
- 部署dashboard
1.获取k8s版本: 2.访问dashboard的github:https://github.com/kubernetes/dashboard/releases,然后找到对应的版本 3.然后将yaml ...
- Win7 右键 新建图标消失的解决办法
方法一: 把下面一段代码存在一个记事本上,再选择另存为1.cmd,最后运行! regsvr32 /u /s igfxpph.dll reg delete HKEY_CLASSES_ROOT\Direc ...
- ssh远程连接centos7故障排除
导致故障的原因在两个方面 1.网络问题---物理链路就不通可以通过在客户端 telnet目标主机地址,例如:telnet 192.168.1.107 22 千万别忘了端口号!!!,如果通了还连不上则按 ...
- delphi请求http接口中文乱码问题
请求http接口的时候参数值是中文乱码: http接口一般都是由java,php以及C#开发而成的,乱码的原因也是由于编码的问题,一般传递数据的都是utf8,然后传递的时候都会urlEcode 那么d ...
- 十八、MySQL 数据排名查询某条数据是总数据的第几条
) as rowno )) b ORDER BY a.zjf DESC 注意:mysql的下标是从0开始的 参考文章: https://blog.csdn.net/warylee/article/de ...
- JavaWeb_(Hibernate框架)Hibernate与c3p0与Dbutils的区别
JavaWeb_(Hibernate框架)使用Hibernate开发用户注册功能 传送门 JavaWeb_(Hibernate框架)使用c3p0与Dbutils开发用户注册功能 传送门 Hiberna ...