sql server 复习笔记1
查询数据库是否存在:
if DB_ID("testDB")is not null;
检查表是否存在:
if OBJECT_ID(“textDB”,“U”) is not null ;其中U代表用户表
创建数据库:
create database+数据名
删除数据库:
drop database 数据库名 --删除数据库的
drop table 表名--删除表的
delete from 表名 where 条件 --删除数据的
查询语句:
use 数据库名称 --修改的数据库
select*from +表名称 --要查询的表
select某某,某某,某某 from 表名称 where 条件 --带条件查询的数据
插入数据:
insert into 表名称 (条件)values (相对应的值)
四.单表查询
(1)分组--对于分组查询,select字句会有限制,需要查询字段要出现在group by 子句中,同时分组以后,可以对分组情况进行统计。
查询雇员表,根据雇员所在国家分组,统计每组的人数情况:
1 select country,count(*) as N'人数'
2 from hr.Employees
3 group by country
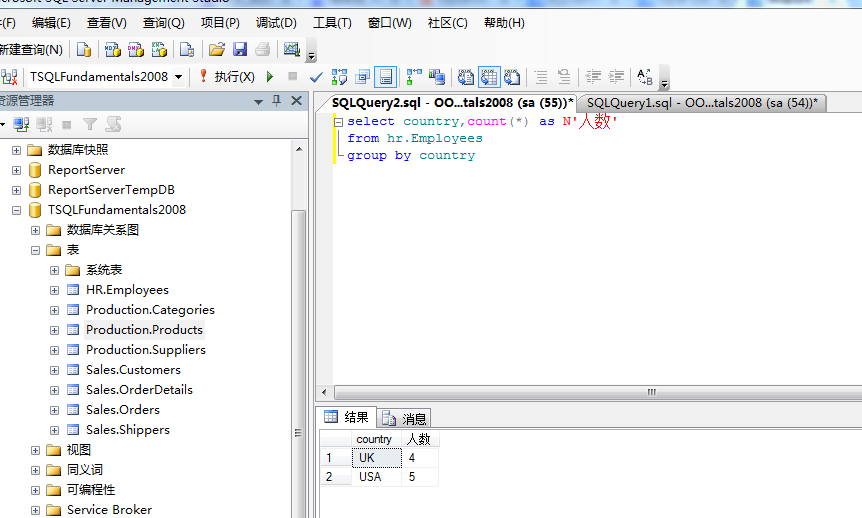
当要查询的字段不包含在group by子句中,则会报相应的错误,所以此时要注意出现在select 后面的查询字段进行分组后,也同时需要出现在group by后面。

2)在这里提示一下:查询条件不要使用计算列,下面谈谈具体原因:
例如:查询雇员表里面雇员出生为1973年的所有雇员信息,可以这样编写sql语句:
1 select YEAR(birthdate),firstname,lastname from HR.Employees
2 where YEAR(birthdate)='1973'

可以看到查询结果将1973年的雇员信息查出来了,但是大家可以思考一下,上面的sql语句在查询的时候,首先是要讲birthdate进行取出年度的计算,
Year(birthdate),其中Year为sql的内置函数,可以用于对字符串日期进行取出年份的计算。同时我们还可以采用下面的sql语句进行查询:

通过sql执行计划可以看出来,查询条件带计算列走的是索引扫描,而where子句后面采用查找范围限制,则走的是索查找。对比两个查询显然绝大部分情况下
走索引查找的查询性能要高于走索引扫描,特别是查询的数据库不是非常大的情况下,索引查找的消耗时间要远远少于索引扫描的时间。所以在查询条件中尽
量避免计算条件。
(3)说说sqlserver中的null,null在数据库中表示不存在,与C#中的null不同,不表示空引用,没有对象,NULL的运算规则:有null的任何运算都是null。
is [not] null: 只能用做条件判断表达式,是否是null?是 条件为true,不是 条件为false。
isnull():函数,如果第一个参数是null,则用第二个参数的值替换第一个参数的值作为函数的返回值。记住:第二个参数的类型必须和第一个兼容。
nullif():函数,如果两个参数值相等、有一个参数是null、或两个参数是null,函数返回值是null;否则返回第一个参数的值。
(4)top用法:意在取出表中满足条件的前多少位。top 10---前10位
说到top,突然想到了面试题中经常出现的查询某表中的前30—40条记录,注意id可能不连续。利用top可以这样写:
1 select top 10 * from A where ID
2 not in(select top 30 ID from A order by ID asc)
3 order by ID asc
同时也可以采用如下写法,只不过可读性比较差:
1 select top 10 * fron A where ID>
2 (select Max(ID) from (select top 30 ID from A order by ID)as t)
3 order by ID asc
当然既然有范围in存在,就可以用exist实现:

1 select top 10 * from A a1
2 WHERE NOT EXISTS
3 (SELECT * from
4 (SELECT TOP 30 * FROM A ORDER BY id asc) a2
5 WHERE a2.id =a1.id
6 )
但是目前需要考虑到----相关子查询:主查询每遍历一条记录时,都要针对主查询的值执行子查询,所以效率比较低。
下面介绍一下top与percent联合使用,percent表示所占的百分比:例如查询雇员表里面,前面百分之二十的雇员的信息,可以写sql,查询结果为两人。
我们在查询一下hr.employees(雇员表),同时查询一下雇员表里面总共有多少人,查出结果显示有9人。
1 select count(*) as N'总人数' from hr.employees
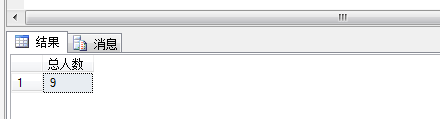
可以看出,9个人按百分之二十取整数了,所以查出来的显示有两个人。
(5)with ties附加属性:
当我们查询订单表时,查询sql:
1 select orderid,orderdate
2 from sales.orders order by orderdate desc
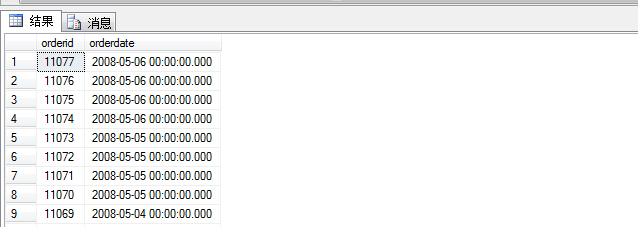
加入我们查询前五个订单信息时候,加入top 5
1 select top 5 orderid,orderdate
2 from sales.orders order by orderdate desc
查询结果如图:
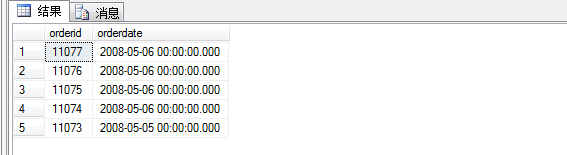
对比没有加top 5,查询结果截取了前五条订单信息,但是有时候我们需要将与最后一条订单日期相同的一起取出来,此时就需要采用附加属性with ties。

(6)over开窗函数:
上面讲到要用count聚合函数,在需要分组求和。但采用over 则可以同样实现基于什么的求和。省去group by。
1 select firstname,lastname ,count(*) over() as N'总人数'
2 from hr.employees
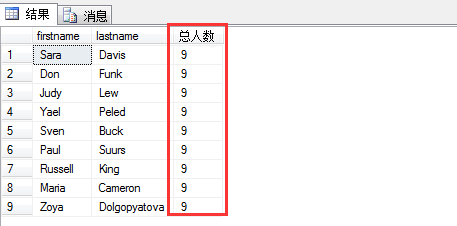
其中over(),括号里面可以附加条件,基于什么进行汇总。不添加,则表示对所有的记录进行汇总。例如求每位顾客所消费的订单总额,可以这样写:
1 select orderid,custid,sum(val) over (partition by custid) as N'顾客消费总额',
2 sum(val) over() as N'订单总额' from sales.ordervalues

五.排名函数
(1)row_number,行号,一般与over联合使用。over基于什么排名。
1 select row_number() over(order by lastname) as N'行号', lastname,firstname
2 from hr.employees
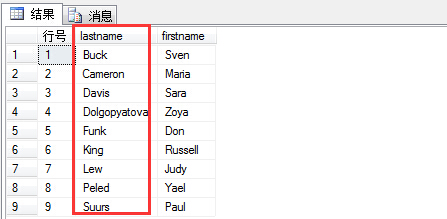
(2)rank ,排名,真正意义上的排名,例如:
1 select country,row_number() over(order by country) as N'rank排名', lastname,firstname
2 from hr.employees
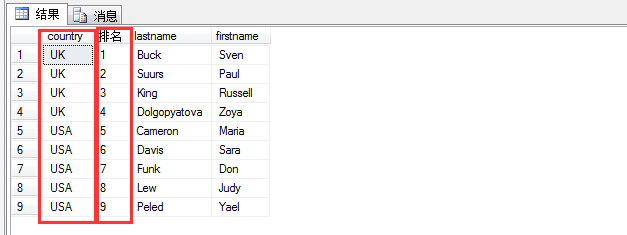
可以看出,根据country排名,确实排出来啦,但是发现前四位同为UK,按理来说使部分先后顺序的,所以在此可以用rank来操作。
1 select country,rank() over(order by country) as N'rank排名', lastname,firstname
2 from hr.employees

可以看出来,使用rank以后,country同为UK的并列第一,类似于学生考试成绩排名并列第一的情况。
(3)dense_rank,密集排名
通过上面rank排名以后,存在并列第一的情况,但是country为USA的应该为第二,所以就出现了使用密集排名dense_rank进行排名。
1 select country,dense_rank() over(order by country) as N'dense_rank排名', lastname,firstname
2 from hr.employees
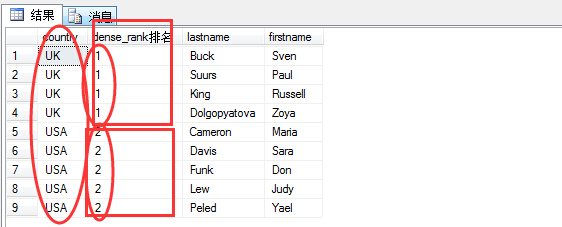
可以看出采用dense_rank以后,就满足了某一条件下,同属一个名次的需求。
(4)分组ntile。按某一条件进行分组。
1 select country,ntile(3) over (order by country) as N'ntile分组',dense_rank() over(order by country) as N'dense_rank排名', lastname,firstname
2 from hr.employees
3 order by country

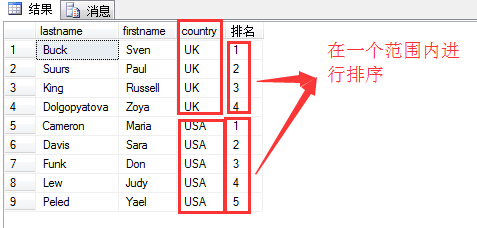
有时候为了在某一个范围内进行排序,比如:
1 select lastname,firstname,country,row_number() over( order by country) as N'排名'
2 from hr.employees

为了实现根据在country范围内排序,即country为Uk的为一组进行排序,country为USA的为一组进行排序。可以这样写:
1 select lastname,firstname,country,row_number() over( partition by country order by country) as N'排名'
2 from hr.employees
sql server 复习笔记1的更多相关文章
- sql server 复习笔记2
主键约束 可以通过定义primary key 约束来定义主键, 用于强制表的实体化完整性,一个表只能有一个主键约束, 并且primary key 约束中的列不能为空值,由于primary key 约束 ...
- SQL Server -- 回忆笔记(五):T-SQL编程,系统变量,事务,游标,触发器
SQL Server -- 回忆笔记(五):T-SQL编程,系统变量,事务,游标,触发器 1. T-SQL编程 (1)声明变量 declare @age int (2)为变量赋值 (3)while循环 ...
- 【SQL Server学习笔记】Delete 语句、Output 子句、Merge语句
原文:[SQL Server学习笔记]Delete 语句.Output 子句.Merge语句 DELETE语句 --建表 select * into distribution from sys.obj ...
- sql server 常见问题笔记
1.关于复制类型 快照发布:发布服务器按预定的时间间隔向订阅服务器发送已发布数据的快照. 事务发布:在订阅服务器收到已发布数据的初始快照后,发布服务器将事务流式传输到订阅服务器. 对等发布:对等发布支 ...
- sql server 2008笔记
sql server 2008开启远程访问数据库 1.以windows验证模式进入数据库管理器. 第二步:右击sa,选择属性: 在常规选项卡中,重新填写密码和确认密码(改成个好记的).把强制实施密码策 ...
- SQL server 学习笔记1
1.查询安装的排序规则选项喝当前的排序规则服务器属性 select * from fn_helpcollations(); 2.查看当前服务器的排序规则 select serverproperty(' ...
- SQL server 复习一
第一天 下面我们从最基础的开始: 在运行里面输入:services.msc 一.启动服务 二.数据库登录的两种身份验证方式 另外一种身份验证方式就是SQL Server身份验证. sa不能使用的时候可 ...
- SQL Server 自学笔记
--★★★SQL语句本身区分大小写吗 --SQLServer 不区分大小写 --Oracle 默认是区分大小写的 --datetime的输入格式,2008-01-07输入进去后显示为1905-06-2 ...
- SQL Server -- 回忆笔记(四):case函数,索引,子查询,分页查询,视图,存储过程
SQL Server知识点回忆篇(四):case函数,索引,子查询,分页查询,视图,存储过程 1. CASE函数(相当于C#中的Switch) then '未成年人' else '成年人' end f ...
随机推荐
- Centos7.3安装jdk和maven
安装jdk和maven 通过winscp上传jdk 解压 tar -zxvf jdk-8u91-linux-x64.ta ...
- SAS学习笔记29 logistic回归
变量筛选 当对多个自变量建立logistic回归模型时,并不是每一个自变量对模型都有贡献.通常我们希望所建立的模型将具有统计学意义的自变量都包含在内,而将没有统计学意义的自变量排除在外,即进行变量筛选 ...
- Java BinarySearch
Java BinarySearch /** * <html> * <body> * <P> Copyright 1994-2018 JasonInternation ...
- JavaScript list转tree
js list转tree //------------------------------------List Convert to Tree ---------------------------- ...
- Senparc.Weixin+nginx配置之坑 ‘10003 redirect_uri域名与后台不一致’
微信公众号扫一扫功能提示:10003 redirect_uri域名与后台不一致 Senparc.Weixin组件很好用,但一个坑,不知道这和个是否有关.. 先说明下环境,centos+.net cor ...
- 十二、react-reudx之@connect 摆脱redux的繁琐操作
如果对redux的概念和用法掌握的已经不错了 那么现在react-redux会让你的操作更加的得心印手 忘记subscribe,记住reducer,action和dispatch即可 Reac ...
- 漏洞预警 | ThinkPHP 5.x远程命令执行漏洞
ThinkPHP采用面向对象的开发结构和MVC模式,融合了Struts的思想和TagLib(标签库).RoR的ORM映射和ActiveRecord模式,是一款兼容性高.部署简单的轻量级国产PHP开发框 ...
- 【转载】salesforce 零基础开发入门学习(一)Salesforce功能介绍,IDE配置以及资源下载
salesforce 零基础开发入门学习(一)Salesforce功能介绍,IDE配置以及资源下载 目前国内已经有很多公司做salesforce,但是国内相关的资料确是少之又少.上个月末跳槽去了新 ...
- C++ 虚函数相关
多态 C++的封装.继承和多态三大特性,封装没什么好说的,就是把事务属性和操作抽象成为类,在用类去实例化对象,从而对象可以使用操作/管理使用它的属性. 至于继承,和多态密不可分.基类可以进行派生,而派 ...
- XML文件解析之JDOM解析
1.JDOM介绍 JDOM的官方网站是http://www.jdom.org/,JDOM解析用到的jar包可以在http://www.jdom.org/dist/binary/中下载,最新的JDOM2 ...