逻辑回归(Logistic Regression)二分类原理及python实现
本文目录:
1. sigmoid function (logistic function)
2. 逻辑回归二分类模型
3. 神经网络做二分类问题
4. python实现神经网络做二分类问题
-----------------------------------------------------------------------------------
1. sigmoid unit
对于一个输入样本$X(x_1,x_2, ..., x_n)$,sigmoid单元先计算$x_1,x_2, ..., x_n$的线性组合:
$z = {{\bf{w}}^T}{\bf{x}} = {w_1}{x_1} + {w_2}{x_2} + ... + {w_n}{x_n}$
然后把结果$z$输入到sigmoid函数:
$\sigma (z) = \frac{1}{{1 + {e^{ - z}}}}$
sigmoid函数图像:
sigmoid函数有个很有用的特征,就是它的导数很容易用它的输出表示,即
$\frac{{\partial \sigma (z)}}{{\partial z}} = \frac{{{e^{ - z}}}}{{{{(1 + {e^{ - z}})}^2}}} = \frac{1}{{1 + {e^{ - z}}}} \cdot \frac{{{e^{ - z}}}}{{1 + {e^{ - z}}}} = \frac{1}{{1 + {e^{ - z}}}} \cdot (1 - \frac{1}{{1 + {e^{ - z}}}}) = \sigma (z)(1 - \sigma (z))\begin{array}{*{20}{c}}
{} & {} & {} & {(1)} \\
\end{array}$
2. 逻辑回归二分类模型
把sigmoid函数应用到二分类中,当$\sigma(z)>=0.5$,输出标签$y=1$;当$\sigma(z)<0.5$,输出标签$y=0$。并定义如下条件概率:
$P\{ Y = 1|\bf{x}\} = p(x) = \frac{1}{{1 + {e^{ - {{\bf{w}}^T}\bf{x}}}}}$
$P\{ Y = 0|\bf{x}\} = 1 - p(\bf{x}) = \frac{{{e^{ - {{\bf{w}}^T}\bf{x}}}}}{{1 + {e^{ - {{\bf{w}}^T}\bf{x}}}}}$
一个事件的几率($odds$)是指该事件发生的概率和该事件不发生的概率的比值。如果事件发生的概率是$p$,那么该事件的几率是$\frac{p}{1-p}$,该事件的对数几率($log$ $odds$)或$logit$函数是$logit(p)=ln\frac{p}{1-p}$。在逻辑回归二分类模型中,事件的对数几率是
$\ln \frac{{P\{ Y = 1|\bf{x}\} }}{{P\{ Y = 0|\bf{x}\} }} = \ln \frac{{p(x)}}{{1 - p(\bf{x})}} = \ln ({e^{{{\bf{w}}^T}\bf{x}}}) = {{\bf{w}}^T}\bf{x}$
上式表明,在逻辑回归二分类模型中,输出$y=1$的对数几率是输入$\bf{x}$的线性函数。
在逻辑回归二分类模型中,对于给定的数据集$T = \{ ({{\bf{x}}_1},{y_1}),({{\bf{x}}_2},{y_2}),...,({{\bf{x}}_n},{y_n})\}$,可以应用极大似然估计法估计模型参数${{\bf{w}}^T} = ({w_1},{w_2},...,{w_n})$。
设:
$\begin{array}{l}
P\{ Y = 1|\bf{x}\} = \sigma ({{\bf{w}}^T}{\bf{x}}) \\
P\{ Y = 0|\bf{x}\} = 1 - \sigma ({{\bf{w}}^T}{\bf{x}}) \\
\end{array}$
似然函数为:
$\prod\limits_{i = 1}^n {{{[\sigma ({{\bf{w}}^T}{{\bf{x}}_i})]}^{{y_i}}}} {[1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})]^{1 - {y_i}}}$
对数似然函数为:
$L({\bf{w}}) = \sum\limits_{i = 1}^n {[{y_i}\log } \sigma ({{\bf{w}}^T}{{\bf{x}}_i}) + (1 - {y_i})\log (1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i}))]$
对$L({\bf{w}})$取极大值,
$\frac{{\partial L({\bf{w}})}}{{\partial{w_j}}} = \sum\limits_{i = 1}^n {[\frac{{{y_i}}}{{\sigma ({{\bf{w}}^T}{{\bf{x}}_i})}}} - \frac{{1 - {y_i}}}{{1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})}}]\frac{{\partial \sigma ({{\bf{w}}^T}{{\bf{x}}_i})}}{{\partial ({{\bf{w}}^T}{{\bf{x}}_i})}}\frac{{\partial ({{\bf{w}}^T}{{\bf{x}}_i})}}{{\partial {w_j}}}$
应用式(1),有
$\frac{{\partial L({\bf{w}})}}{{\partial{w_j}}} = \sum\limits_{i = 1}^n {[\frac{{{y_i} - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})}}{{\sigma ({{\bf{w}}^T}{{\bf{x}}_i})[1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})]}}} ] \cdot \sigma ({{\bf{w}}^T}{{\bf{x}}_i})[1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})] \cdot {x_{ij}}$
$\frac{{\partial L({\bf{w}})}}{{\partial{w_j}}} = \sum\limits_{i = 1}^n [ {y_i} - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})] \cdot {x_{ij}}$
令$\frac{{\partial L({\bf{w}})}}{{{w_j}}}=0$即可得到参数${\bf{w}}$的估计值。
3. 神经网络做二分类问题,交叉熵损失函数
在阈值函数是sigmoid函数的神经网络中,针对二分类问题,交叉熵损失函数是比较合适的损失函数,其形式为(和上一节的对数似然函数只相差一个负号):
$C =- \frac{1}{n}\sum\limits_{i = 1}^n {[{y_i}\log } \sigma ({{\bf{w}}^T}{{\bf{x}}_i}) + (1 - {y_i})\log (1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i}))]$
在神经网络的训练过程中,权重的迭代过程为:
$w_j^{k + 1} = w_j^k - \eta \frac{{\partial C}}{{\partial w_j^k}}$
在损失函数是交叉熵损失函数的情况下,
$\frac{{\partial C}}{{\partial w_j^k}} = \sum\limits_{i = 1}^n [ \sigma ({{\bf{w}}^T}{{\bf{x}}_i}) - {y_i}] \cdot {x_{ij}} = ({{\bf{x}}^T}[\sigma ({{\bf{w}}^T}{\bf{x}}) - {\bf{y}}] )_j= ({{\bf{x}}^T}{\bf{e}})_j$
其中,${\bf{y}}$是由样本标签构成的列向量,等号后的两个式子的下标$j$表示向量的第$j$个分量。
4. python实现神经网络做二分类问题
神经网络结构:一个sigmoid单元
训练数据:总共500个训练样本,链接https://pan.baidu.com/s/1qWugzIzdN9qZUnEw4kWcww,提取码:ncuj
损失函数:交叉熵损失函数
代码如下:
import numpy as np
import matplotlib.pyplot as plt class Logister():
def __init__(self, path):
self.path = path def file2matrix(self, delimiter):
fp = open(self.path, 'r')
content = fp.read() # content现在是一行字符串,该字符串包含文件所有内容
fp.close()
rowlist = content.splitlines() # 按行转换为一维表
# 逐行遍历
# 结果按分隔符分割为行向量
recordlist = [list(map(float, row.split(delimiter))) for row in rowlist if row.strip()]
return np.mat(recordlist) def drawScatterbyLabel(self, dataSet):
m, n = dataSet.shape
target = np.array(dataSet[:, -1])
target = target.squeeze() # 把二维数据变为一维数据
for i in range(m):
if target[i] == 0:
plt.scatter(dataSet[i, 0], dataSet[i, 1], c='blue', marker='o')
if target[i] == 1:
plt.scatter(dataSet[i, 0], dataSet[i, 1], c='red', marker='o') def buildMat(self, dataSet):
m, n = dataSet.shape
dataMat = np.zeros((m, n))
dataMat[:, 0] = 1
dataMat[:, 1:] = dataSet[:, :-1]
return dataMat def logistic(self, wTx):
return 1.0/(1.0 + np.exp(-wTx)) def classfier(self, testData, weights):
prob = self.logistic(sum(testData*weights)) # 求取概率--判别算法
if prob > 0.5:
return 1
else:
return 0 if __name__ == '__main__':
logis = Logister('testSet.txt') print('1. 导入数据')
inputData = logis.file2matrix('\t')
target = inputData[:, -1]
m, n = inputData.shape
print('size of input data: {} * {}'.format(m, n)) print('2. 按分类绘制散点图')
logis.drawScatterbyLabel(inputData) print('3. 构建系数矩阵')
dataMat = logis.buildMat(inputData) alpha = 0.1 # learning rate
steps = 600 # total iterations
weights = np.ones((n, 1)) # initialize weights
weightlist = [] print('4. 训练模型')
for k in range(steps):
output = logis.logistic(dataMat * np.mat(weights))
errors = target - output
print('iteration: {} error_norm: {}'.format(k, np.linalg.norm(errors)))
weights = weights + alpha*dataMat.T*errors # 梯度下降
weightlist.append(weights) print('5. 画出训练过程')
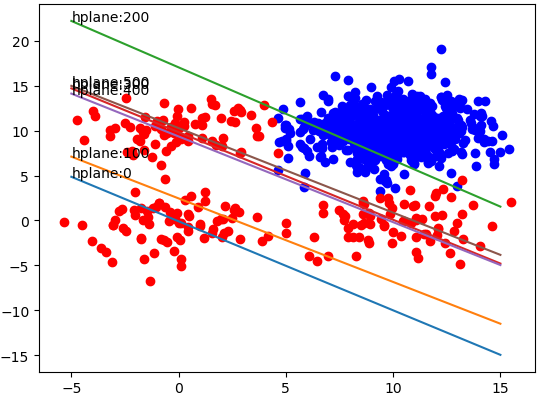
X = np.linspace(-5, 15, 301)
weights = np.array(weights)
length = len(weightlist)
for idx in range(length):
if idx % 100 == 0:
weight = np.array(weightlist[idx])
Y = -(weight[0] + X * weight[1]) / weight[2]
plt.plot(X, Y)
plt.annotate('hplane:' + str(idx), xy=(X[0], Y[0]))
plt.show() print('6. 应用模型到测试数据中')
testdata = np.mat([-0.147324, 2.874846]) # 测试数据
m, n = testdata.shape
testmat = np.zeros((m, n+1))
testmat[:, 0] = 1
testmat[:, 1:] = testdata
print(logis.classfier(testmat, np.mat(weights))) # weights为前面训练得出的
训练600个iterations,每100个iterations输出一次训练结果,如下图:
【参考文献】
[1] 《机器学习》Mitshell,第四章
[2] 《机器学习算法原理与编程实践》郑捷,第五章第二节
[3] Neural Network and Deep Learning,Michael Nielsen,chapter 3
逻辑回归(Logistic Regression)二分类原理及python实现的更多相关文章
- 机器学习 (三) 逻辑回归 Logistic Regression
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang 的个人 ...
- ML 逻辑回归 Logistic Regression
逻辑回归 Logistic Regression 1 分类 Classification 首先我们来看看使用线性回归来解决分类会出现的问题.下图中,我们加入了一个训练集,产生的新的假设函数使得我们进行 ...
- 机器学习总结之逻辑回归Logistic Regression
机器学习总结之逻辑回归Logistic Regression 逻辑回归logistic regression,虽然名字是回归,但是实际上它是处理分类问题的算法.简单的说回归问题和分类问题如下: 回归问 ...
- Coursera公开课笔记: 斯坦福大学机器学习第六课“逻辑回归(Logistic Regression)” 清晰讲解logistic-good!!!!!!
原文:http://52opencourse.com/125/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D ...
- 机器学习方法(五):逻辑回归Logistic Regression,Softmax Regression
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 前面介绍过线性回归的基本知识, ...
- 逻辑回归(Logistic Regression)详解,公式推导及代码实现
逻辑回归(Logistic Regression) 什么是逻辑回归: 逻辑回归(Logistic Regression)是一种基于概率的模式识别算法,虽然名字中带"回归",但实际上 ...
- 机器学习(四)--------逻辑回归(Logistic Regression)
逻辑回归(Logistic Regression) 线性回归用来预测,逻辑回归用来分类. 线性回归是拟合函数,逻辑回归是预测函数 逻辑回归就是分类. 分类问题用线性方程是不行的 线性方程拟合的是连 ...
- 机器学习入门11 - 逻辑回归 (Logistic Regression)
原文链接:https://developers.google.com/machine-learning/crash-course/logistic-regression/ 逻辑回归会生成一个介于 0 ...
- [Machine Learning] 逻辑回归 (Logistic Regression) -分类问题-逻辑回归-正则化
在之前的问题讨论中,研究的都是连续值,即y的输出是一个连续的值.但是在分类问题中,要预测的值是离散的值,就是预测的结果是否属于某一个类.例如:判断一封电子邮件是否是垃圾邮件:判断一次金融交易是否是欺诈 ...
随机推荐
- BFS和DFS
1.图的两种遍历方式 图的遍历通常有两种方式,即深度优先搜索(Depth First Search)和广度优先搜索(Breadth First Search).前者类似于树的先序遍历,而后者类似于树的 ...
- 基于Ajax技术的前后端Json数据交互方式实现
前言 使用浏览器访问网站是日常生活中必不可少的一件事情,当我们在浏览器地址栏中输入网址后会看到网站的内容,那么这个过程中发生了什么?下面简单介绍下浏览器访问网站过程. 第一步:浏览器向DNS服务器发起 ...
- 前端知识体系:JavaScript基础-原型和原型链-实现继承的几种方式以及他们的优缺点
实现继承的几种方式以及他们的优缺点(参考文档1.参考文档2.参考文档3) 要搞懂JS继承,我们首先要理解原型链:每一个实例对象都有一个__proto__属性(隐式原型),在js内部用来查找原型链:每一 ...
- 【Python之路】特别篇--Django瀑布流实现
瀑布流 瀑布流,又称瀑布流式布局.是比较流行的一种网站页面布局,视觉表现为参差不齐的多栏布局,随着页面滚动条向下滚动,这种布局还会不断加载数据块并附加至当前尾部.最早采用此布局的网站是Pinteres ...
- siblings([expr])
siblings([expr]) 概述 取得一个包含匹配的元素集合中每一个元素的所有唯一同辈元素的元素集合.可以用可选的表达式进行筛选.大理石平台维修 参数 exprStringV1.0 用于筛选 ...
- Visual Studio 2019 激活
Visual Studio 2019 Enterprise 企业版:BF8Y8-GN2QH-T84XB-QVY3B-RC4DF Visual Studio 2019 Professional 专业版: ...
- git log/show/HEAD step(2)
git log can see all commit log #git logcommit 2737cfa37f81810072f074dcf19964be0a5eea2e (HEAD -> m ...
- bzoj4152
The Captain HYSBZ - 4152 给定平面上的n个点,定义(x1,y1)到(x2,y2)的费用为min(|x1-x2|,|y1-y2|),求从1号点走到n号点的最小费用. Input ...
- airflow自动生成dag
def auto_create_dag(): dag_list=[] dag = DAG() dag_list.append(dag) return dag_list dags = auto_crea ...
- Leetcode题目78.子集(回溯-中等)
题目描述: 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明:解集不能包含重复的子集. 示例: 输入: nums = [1,2,3] 输出: [ [3], [1] ...