17.Azkaban实战
首先创建一个command.job文件
#command.job
type=command
command=echo it18zhang
然后打成zip压缩包



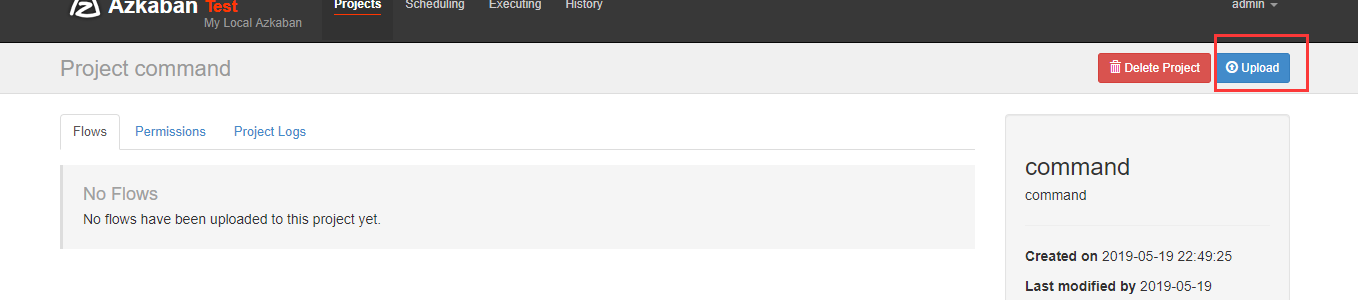
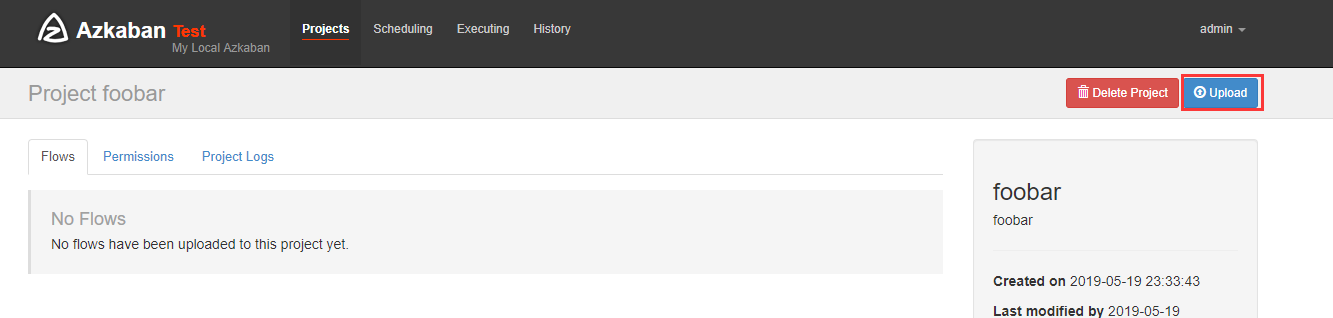
上传刚刚打包的zip包
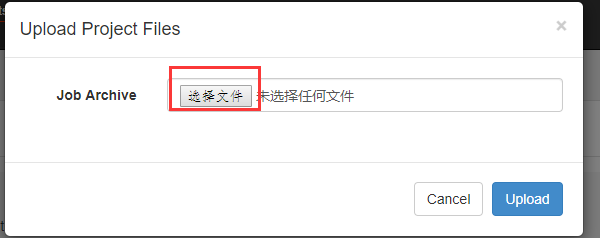
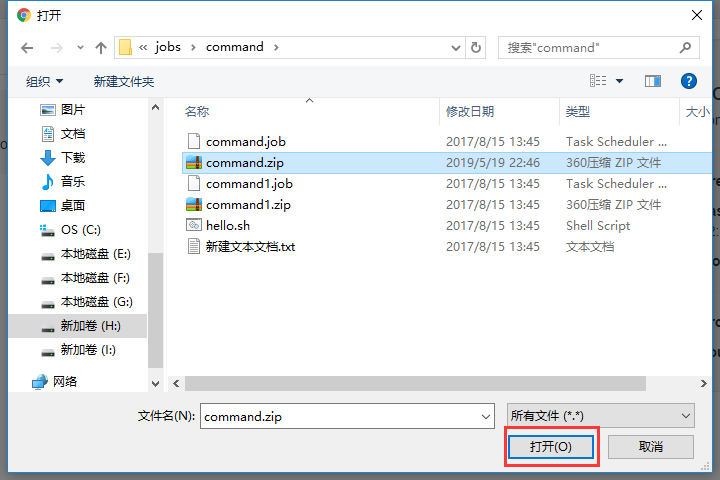

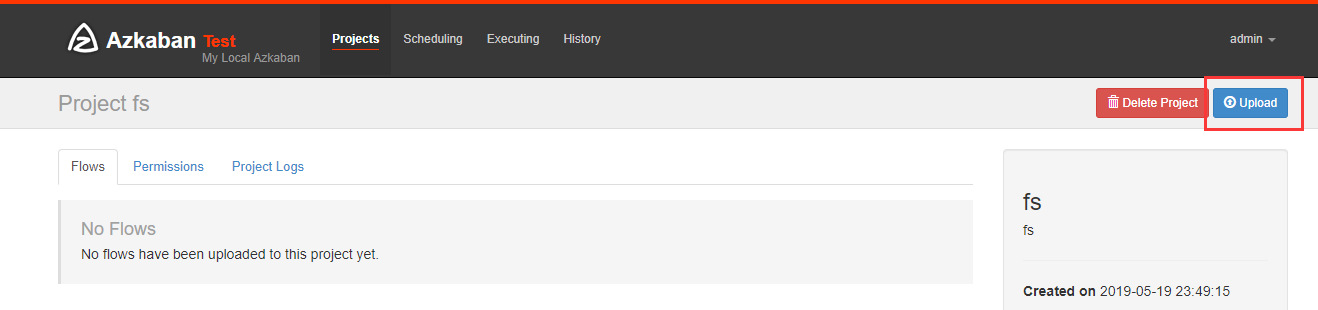
上传完后可以执行他
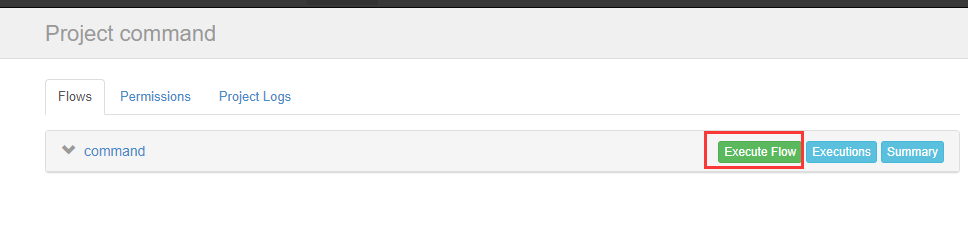
可以定时执行
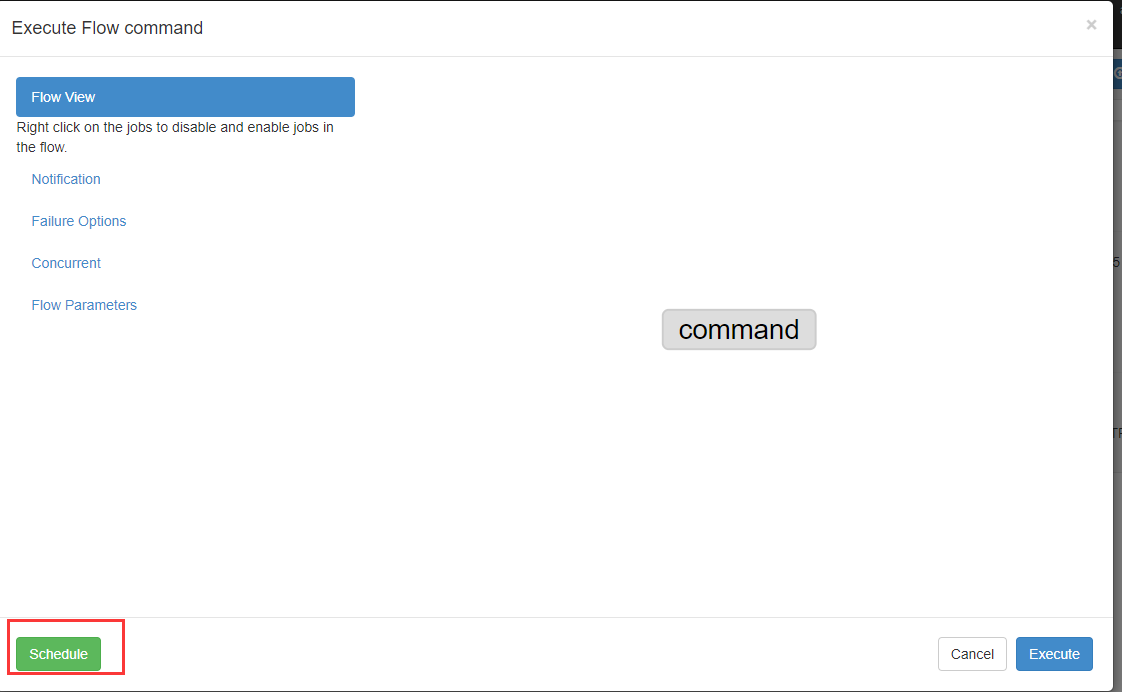
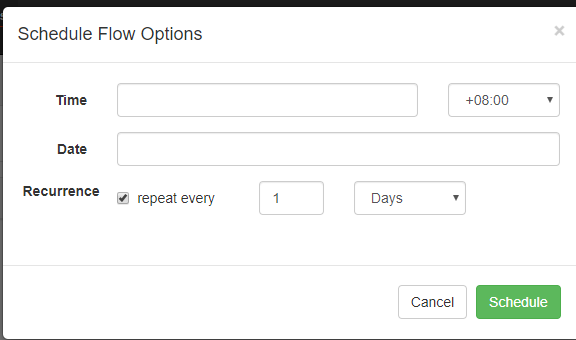
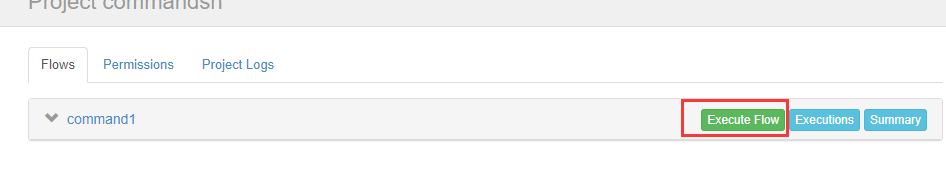
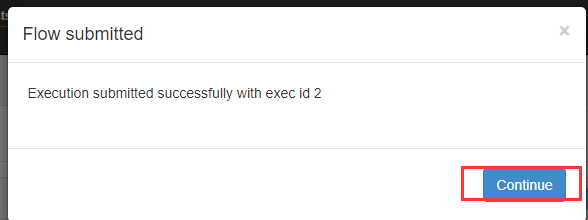
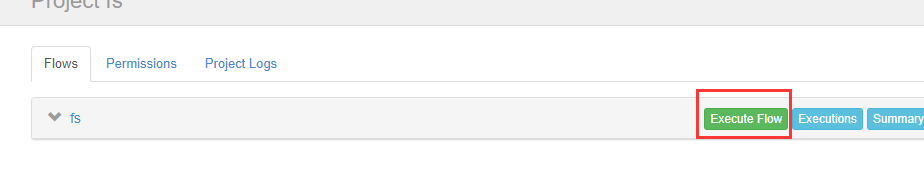
现在我们立马执行
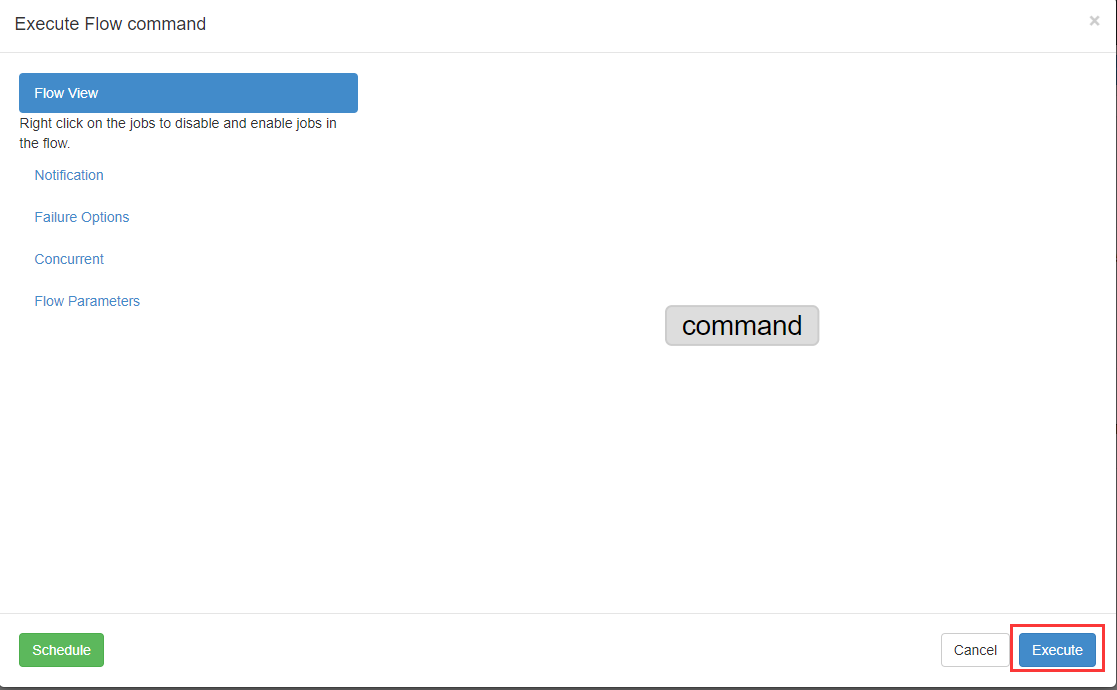
现在我们要执行一个脚本
新建一个commad1.job文件
#command.job
type=command
command=bash hello.sh
再编写一个hello,sh脚本
#!/bin/bash
echo 'hello it18zhang~~~~'
把两个文件都选上一起打包
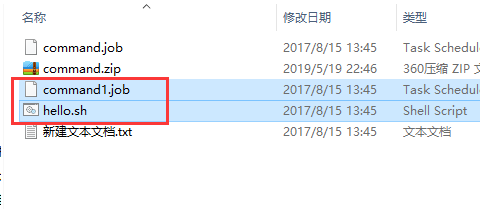
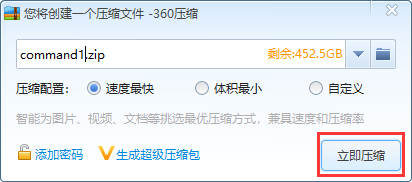


上传刚刚打的zip包


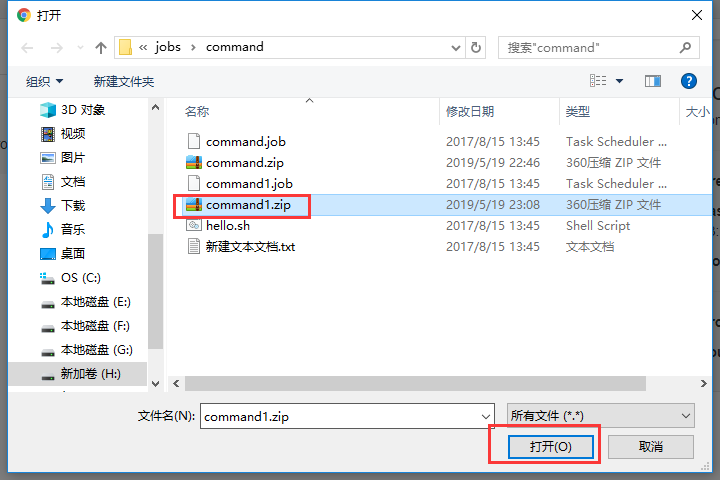

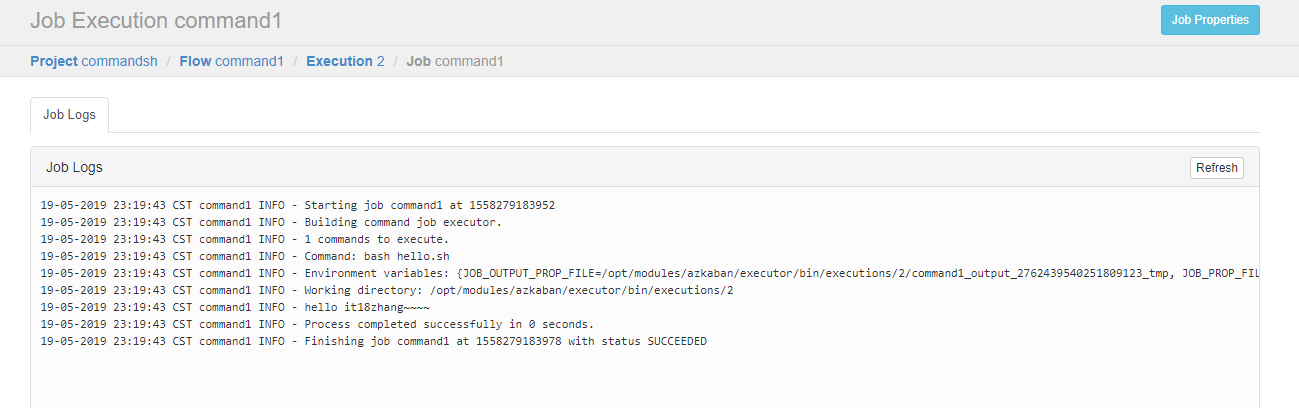
执行


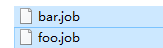
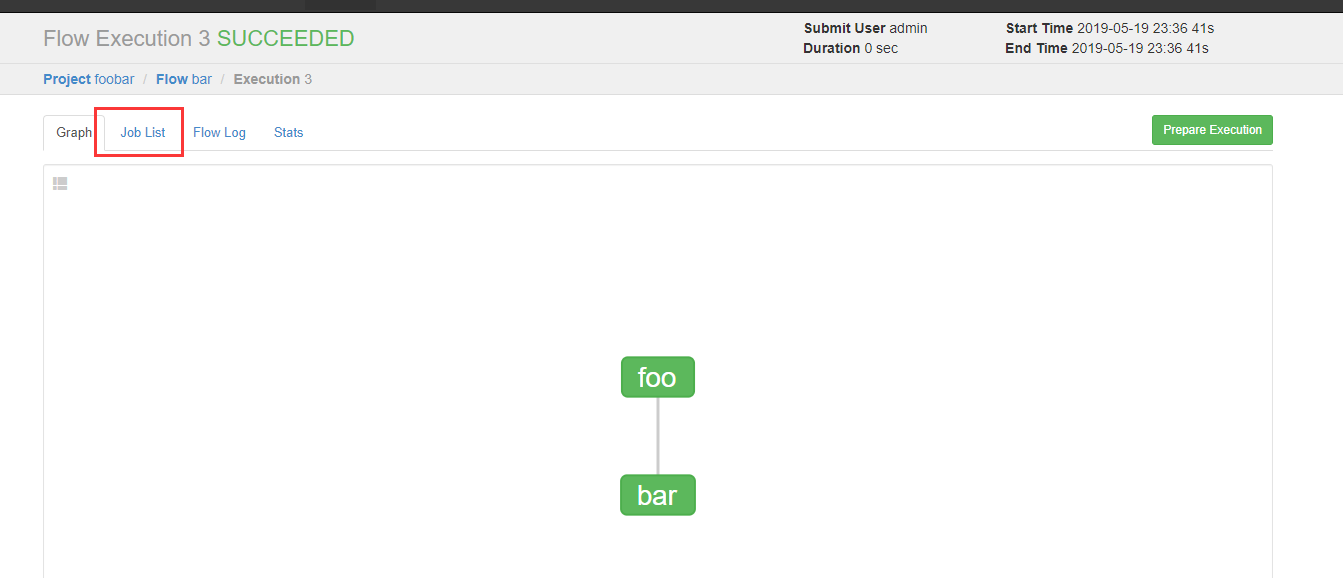
创建有依赖关系的多个job描述
新建一个bar.job
# bar.job
type=command
dependencies=foo
command=echo bar
新建一个foo.job
# foo.job
type=command
command=echo foo
把这两个文件一起打成zip包






HDFS操作任务
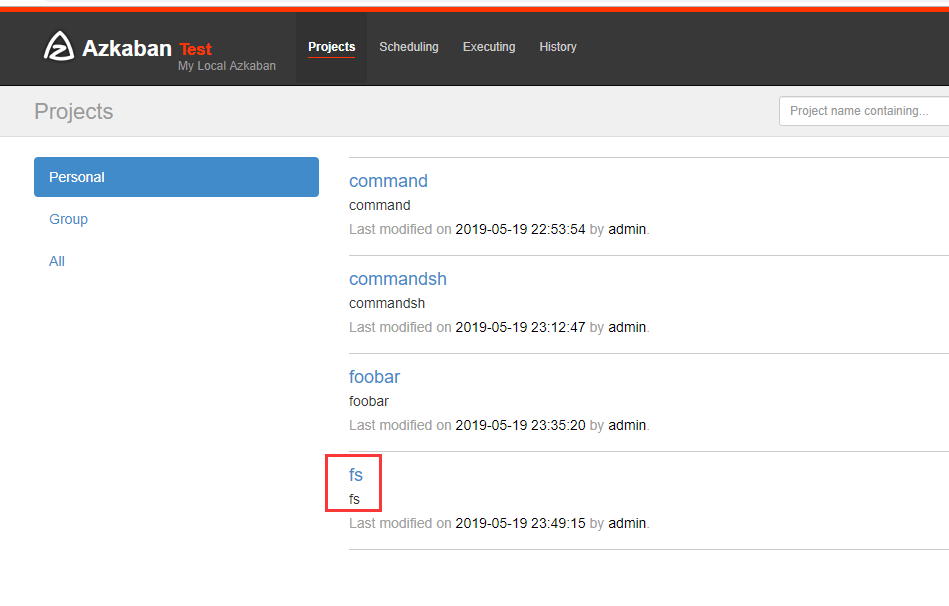
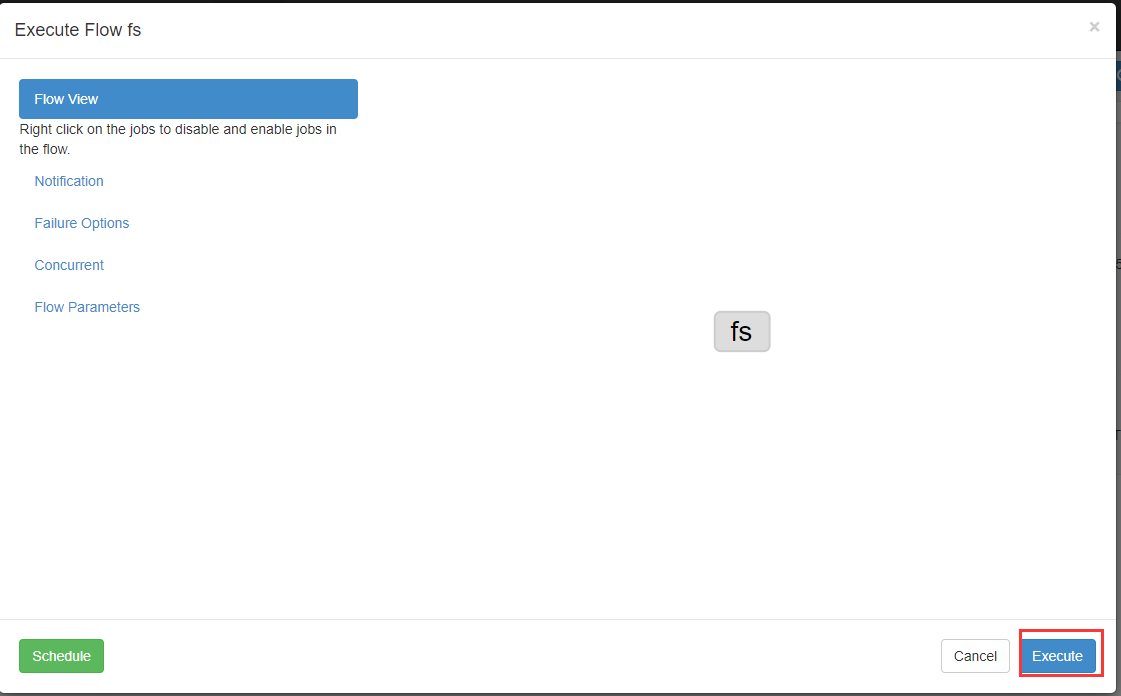
新建文件fs.job
# fs.job
type=command
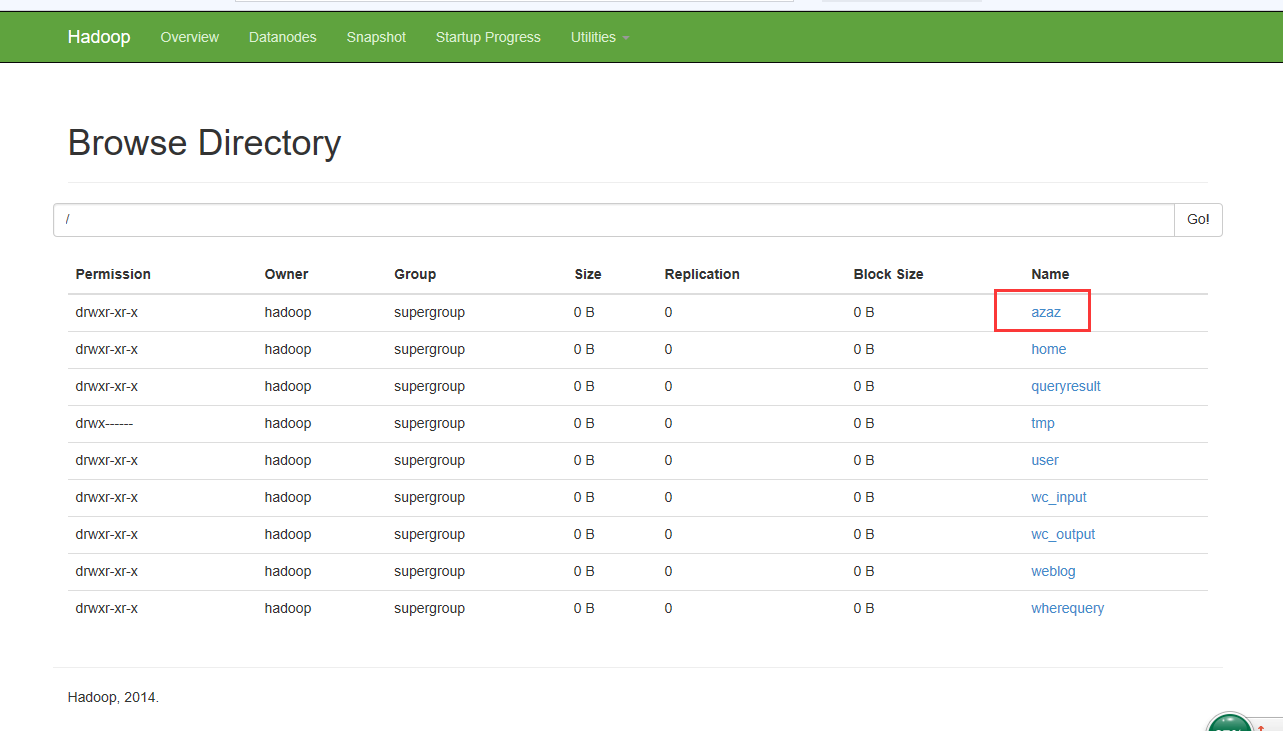
command=/opt/modules/hadoop-2.6./bin/hadoop fs -mkdir /azaz
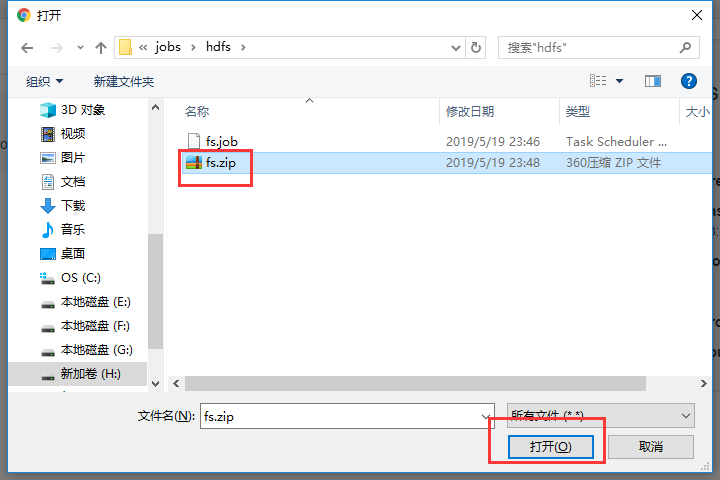
打包成zip包




MAPREDUCE任务
先创建一个输入路径


创建一个数据文件b.txt

输入一些单词

把b.txt文件上传到hdfs上

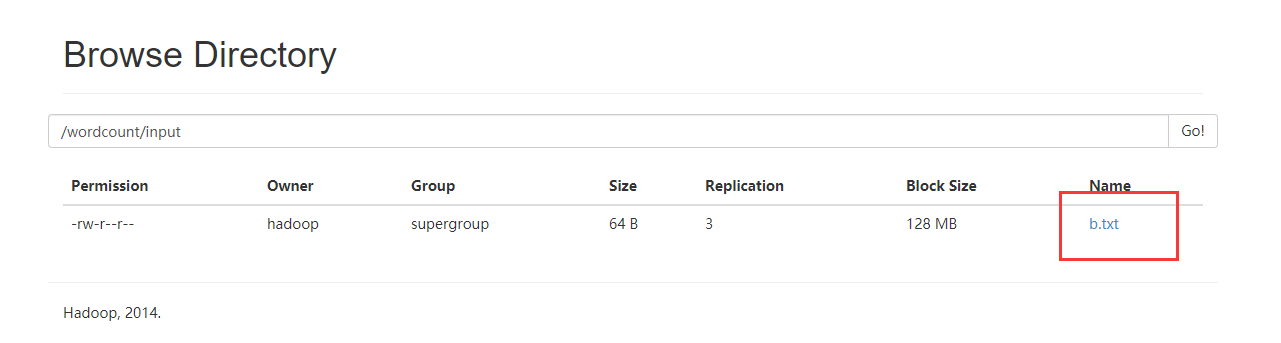
创建mrwc.job文件
# mrwc.job
type=command
command=/opt/modules/hadoop-2.6./bin/hadoop jar hadoop-mapreduce-examples-2.6..jar wordcount /wordcount/input /wordcount/azout
把这两个文件一起打包
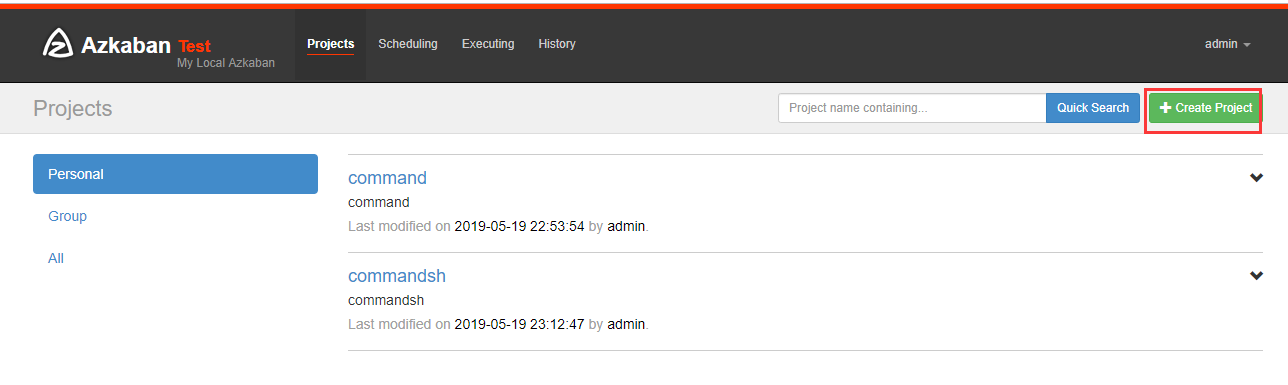
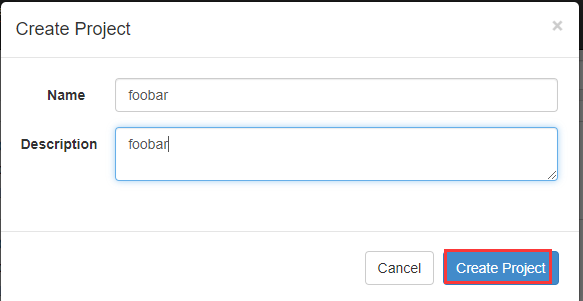
在azkaban创建一个project


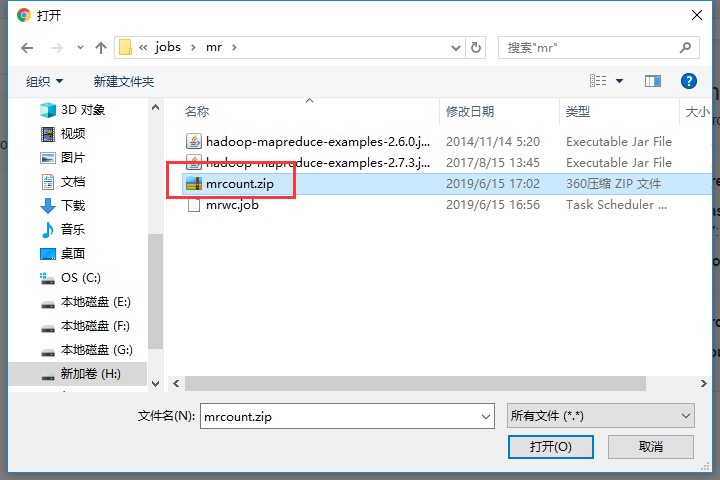
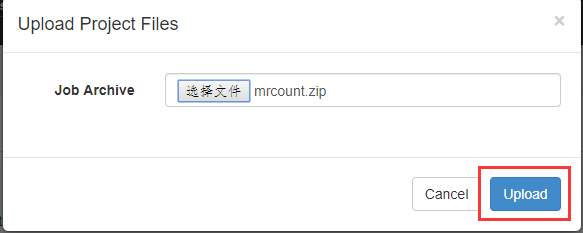
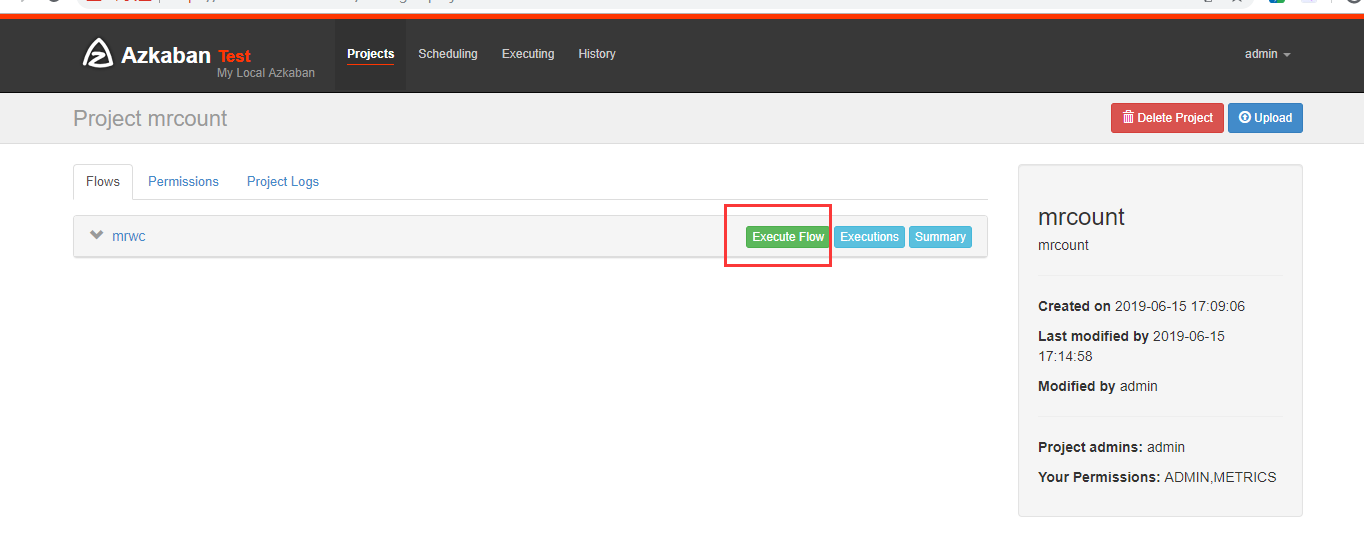
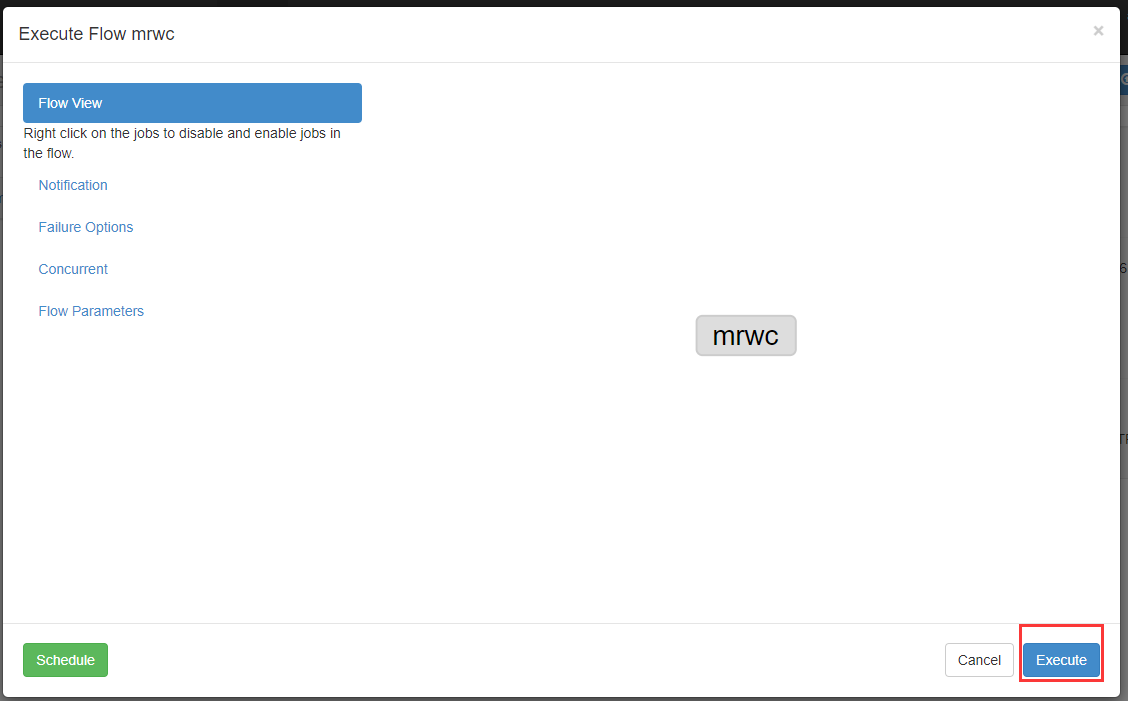
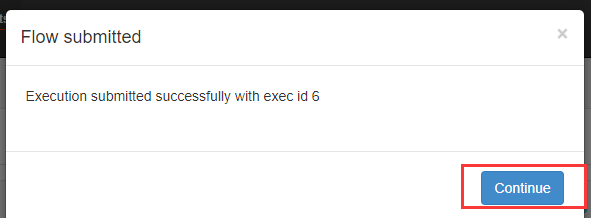

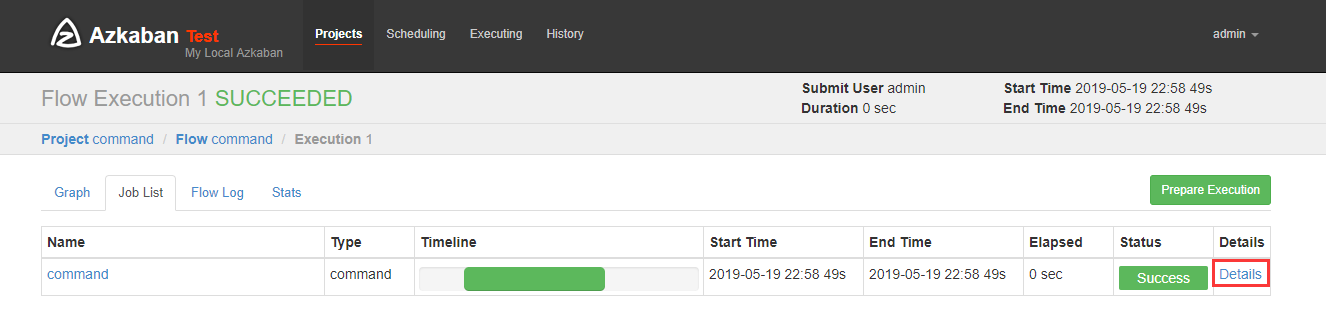
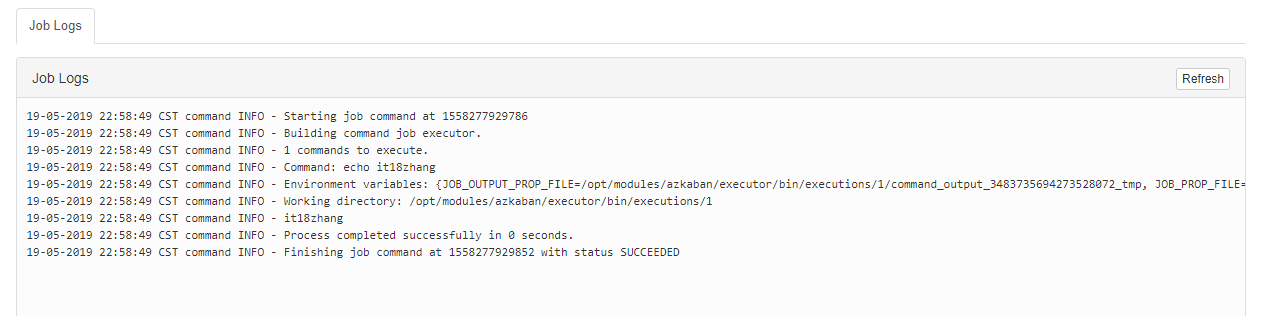
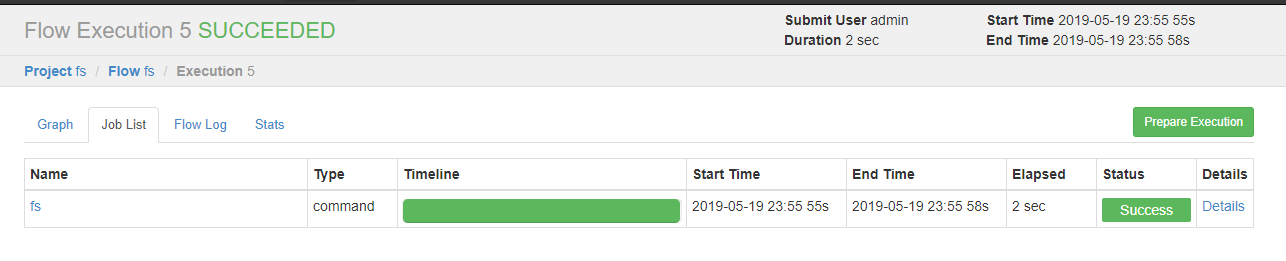
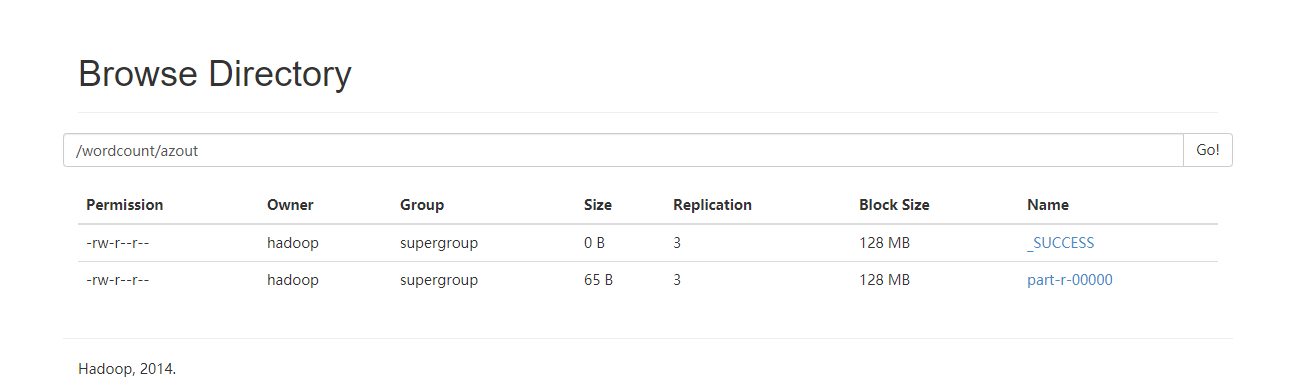
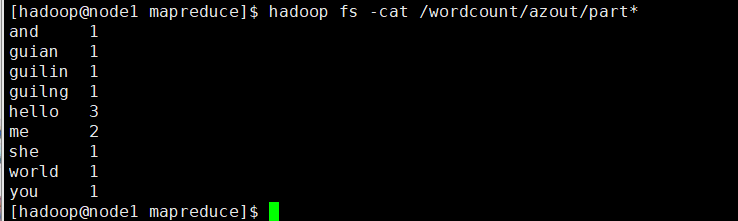
可以看到执行成功了
HIVE脚本任务
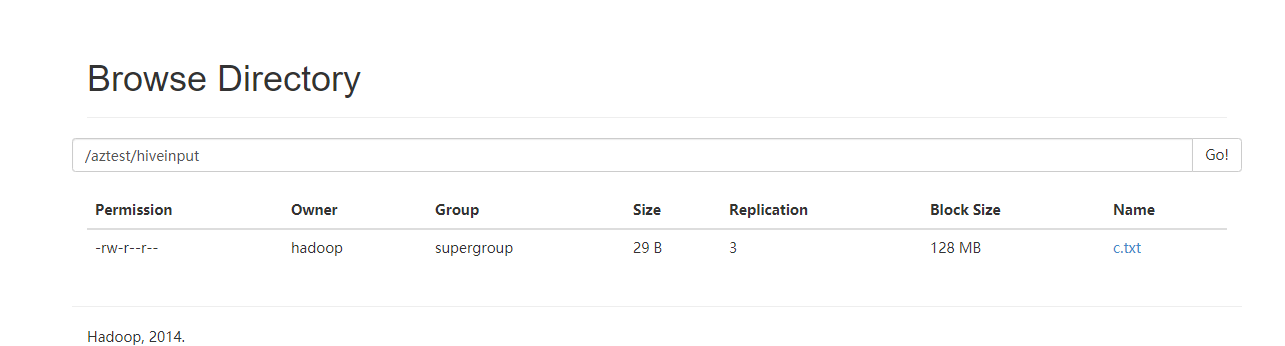
先创建目录
hadoop fs -mkdir -p /aztest/hiveinput
新建一个c.txt数据文件


把c.txt文件上传到HDFS上

新建hivef.job
# hivef.job
type=command
command=/opt/modules/hive/bin/hive -f 'test.sql'
新建test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',' ;
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count() from aztest;
打包成hivef.zip



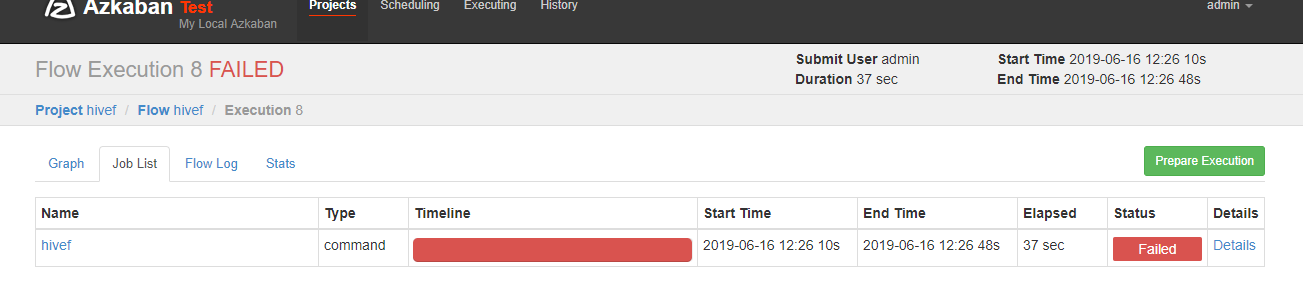
可以看到失败了,查看原因
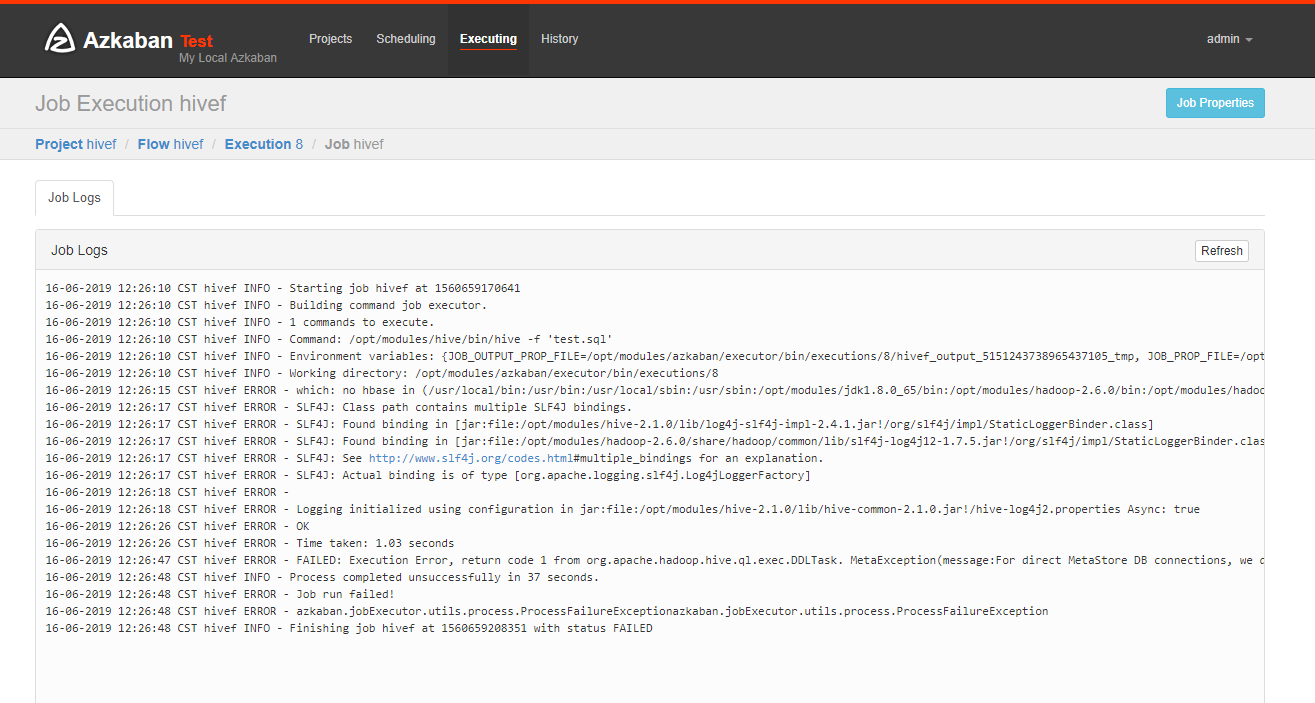
把本地hive的Lib目录下的mysql连接包的版本更换一下
换成这个5.1.28版本
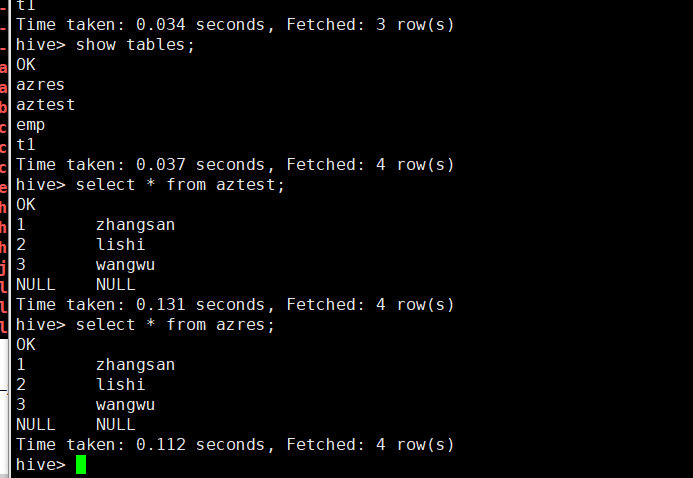
再运行一次,同样失败了,但是hive和hdfs上出来了相应的结果,具有原因我也不懂

17.Azkaban实战的更多相关文章
- 大数据技术之_13_Azkaban学习_Azkaban(阿兹卡班)介绍 + Azkaban 安装部署 + Azkaban 实战
一 概述1.1 为什么需要工作流调度系统1.2 常见工作流调度系统1.3 各种调度工具特性对比1.4 Azkaban 与 Oozie 对比二 Azkaban(阿兹卡班) 介绍三 Azkaban 安装部 ...
- Azkaban实战,Command类型单一job示例,任务中执行外部shell脚本,Command类型多job工作flow,HDFS操作任务,MapReduce任务,HIVE任务
本文转载自:https://blog.csdn.net/tototuzuoquan/article/details/73251616 1.Azkaban实战 Azkaba内置的任务类型支持comman ...
- Hadoop生态圈-Azkaban实战之Command类型执行指定脚本
Hadoop生态圈-Azkaban实战之Command类型执行指定脚本 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 1>.服务端测试代码(别忘记添加权限哟!) [yinzh ...
- Hadoop生态圈-Azkaban实战之Command类型多job工作流flow
Hadoop生态圈-Azkaban实战之Command类型多job工作流flow 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Azkaban内置的任务类型支持command.ja ...
- azkaban(安装配置加实战)
为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成:shell 脚本程序,java 程序,mapreduce 程序.hive 脚本等 各任务单元之间存在时间先后及前后依赖关 ...
- Flume+Sqoop+Azkaban笔记
大纲(辅助系统) 离线辅助系统 数据接入 Flume介绍 Flume组件 Flume实战案例 任务调度 调度器基础 市面上调度工具 Oozie的使用 Oozie的流程定义详解 数据导出 sqoop基础 ...
- 【大数据】Azkaban学习笔记
一 概述 1.1 为什么需要工作流调度系统 1)一个完整的数据分析系统通常都是由大量任务单元组成: shell脚本程序,java程序,mapreduce程序.hive脚本等 2)各任务单元之间存在时间 ...
- 《Spring 3.x 企业应用开发实战》目录
图书信息:陈雄华 林开雄 编著 ISBN 978-7-121-15213-9 概述: 第1章:对Spring框架进行宏观性的概述,力图使读者建立起对Spring整体性的认识. 第2章:通过一个简单的例 ...
- AI人工智能顶级实战工程师 课程大纲
课程名称 内容 阶段一.人工智能基础 — 高等数学必知必会 1.数据分析 "a. 常数eb. 导数c. 梯度d. Taylore. gini系数f. 信息熵与组合数 ...
随机推荐
- eq(index|-index)
eq(index|-index) 概述 获取当前链式操作中第N个jQuery对象,返回jQuery对象,当参数大于等于0时为正向选取,比如0代表第一个,1代表第二个.当参数为负数时为反向选取,比如-1 ...
- Linq to XML - C#生成XML
1.System.Xml.XmlDocument XML file转成字符串 string path3 = @"C:\Users\test.xml"; XmlDocument ...
- g++版本低于4.7使用C++11
编译时需要添加: 需要添加头文件#include<memory> g++ -std=gnu++0x share_ptr.cpp -o s 原文: C++11 features are av ...
- delphi将两个Strlist合并,求交集 (保留相同的)
Function StrList_Join(StrListA,StrListB:String):String; //将两个Strlist合并,求交集 (保留相同的) var SListA,SListB ...
- ANDROID_ID
在设备首次启动时,系统会随机生成一个64位的数字,并把这个数字以16进制字符串的形式保存下来,这个16进制的字符串就是ANDROID_ID,当设备被wipe后该值会被重置.可以通过下面的方法获取: i ...
- JS基础_垃圾回收(GC)
垃圾回收(GC) 程序运行过程中也会产生垃圾,这些垃圾积攒过多以后,会导致程序运行的速度过慢,所以我门需要一个垃圾回收的机制,来处理程序运行过程中产生的垃圾 当一个对象没有任何的变量或属性对它进行引用 ...
- vue 动态渲染数据很慢或不渲染
vue 动态渲染数据很慢或不渲染 原因是因为vue检测速度很慢,因为多层循环了,在VUE 2.x的时候还能渲染出来,1.x的时候压根渲染不出来.解决方式:在动态改变数据的方法,第一行加上 this.$ ...
- postgresql 字符串转整数 int、integer
--把'1234'转成整数 select cast('1234' as integer ) ; --用substring截取字符串,从第8个字符开始截取2个字符:结果是12 select cast(s ...
- Flume-日志聚合
Flume-1 监控文件 /tmp/tomcat.log. Flume-2 监控某一个端口的数据流. Flume-1 与 Flume-2 将数据发送给 Flume-3,Flume-3 将最终数据打印到 ...
- express使用ejs模板引擎渲染html文件
小场景小知识点. 在使用express过程中,按照官网教程,利用express生成器很容易初始化express项目模板. 那么初始化项目之后应该如何使用ejs作为模板引擎呢?如下 // 注释掉默认生成 ...