17.Azkaban实战
首先创建一个command.job文件
#command.job
type=command
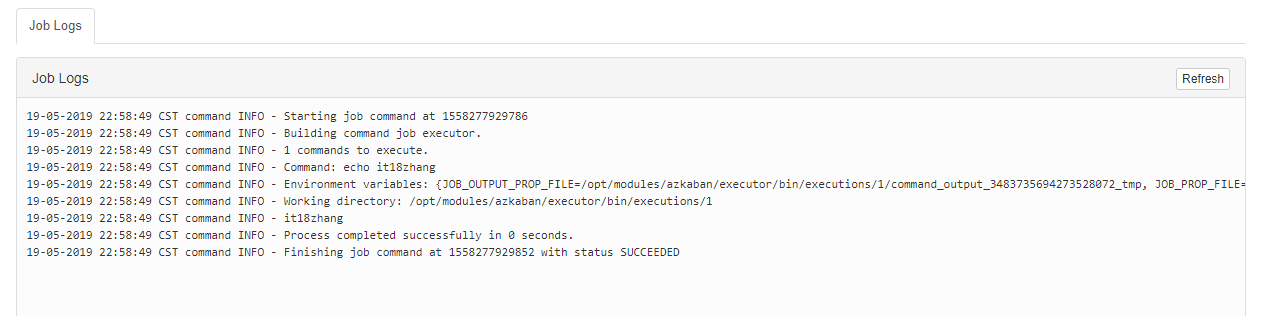
command=echo it18zhang
然后打成zip压缩包
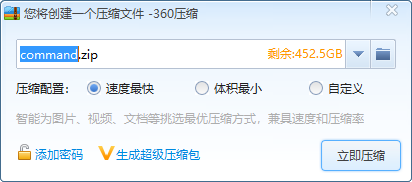



上传刚刚打包的zip包
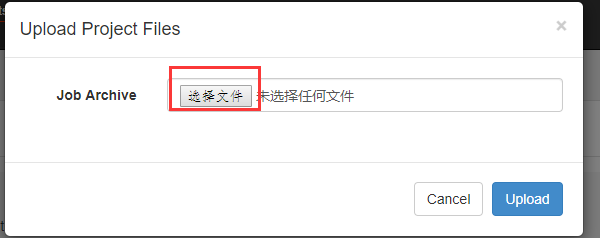

上传完后可以执行他
可以定时执行
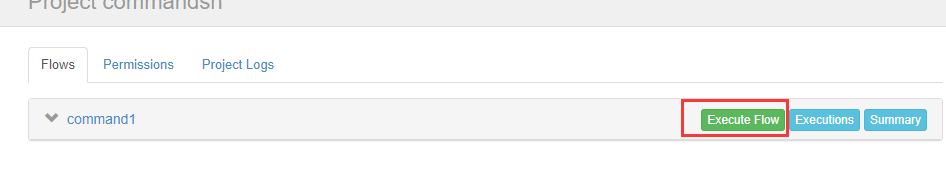
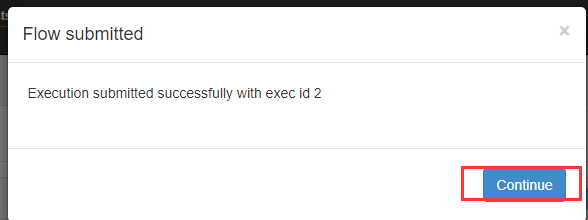
现在我们立马执行
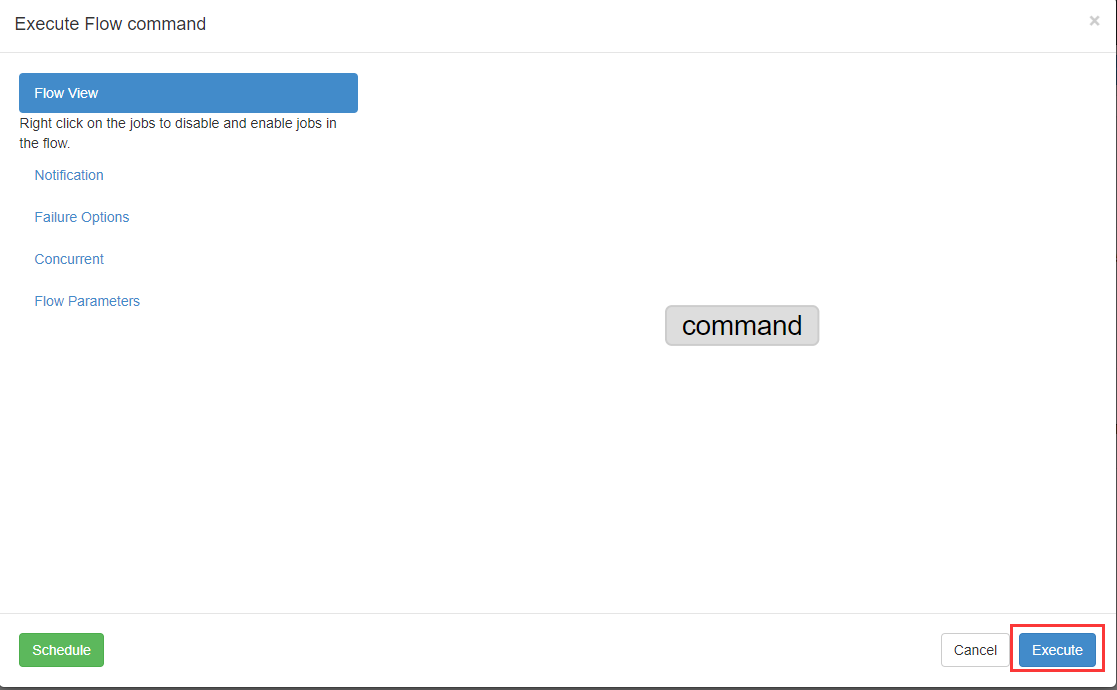
现在我们要执行一个脚本
新建一个commad1.job文件
#command.job
type=command
command=bash hello.sh
再编写一个hello,sh脚本
#!/bin/bash
echo 'hello it18zhang~~~~'
把两个文件都选上一起打包
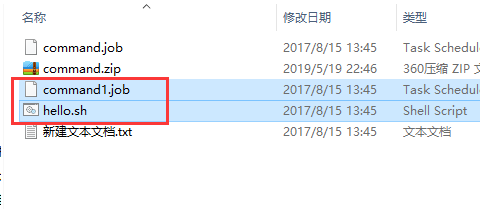
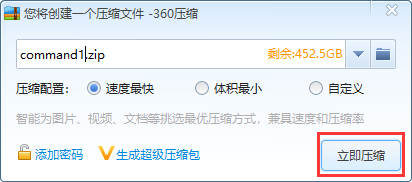


上传刚刚打的zip包


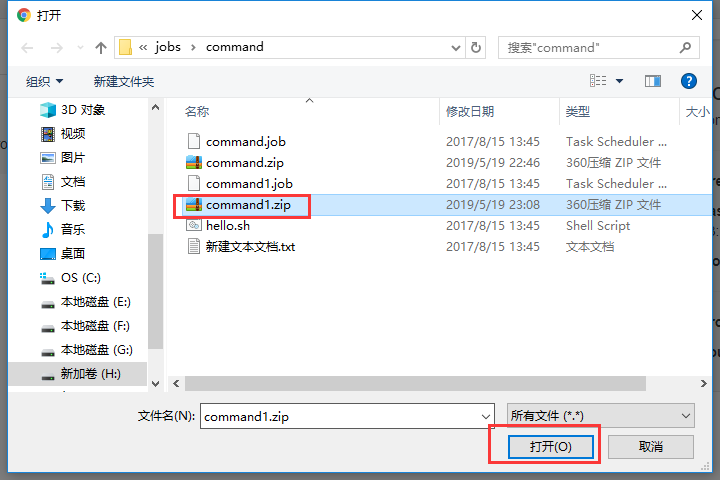

执行


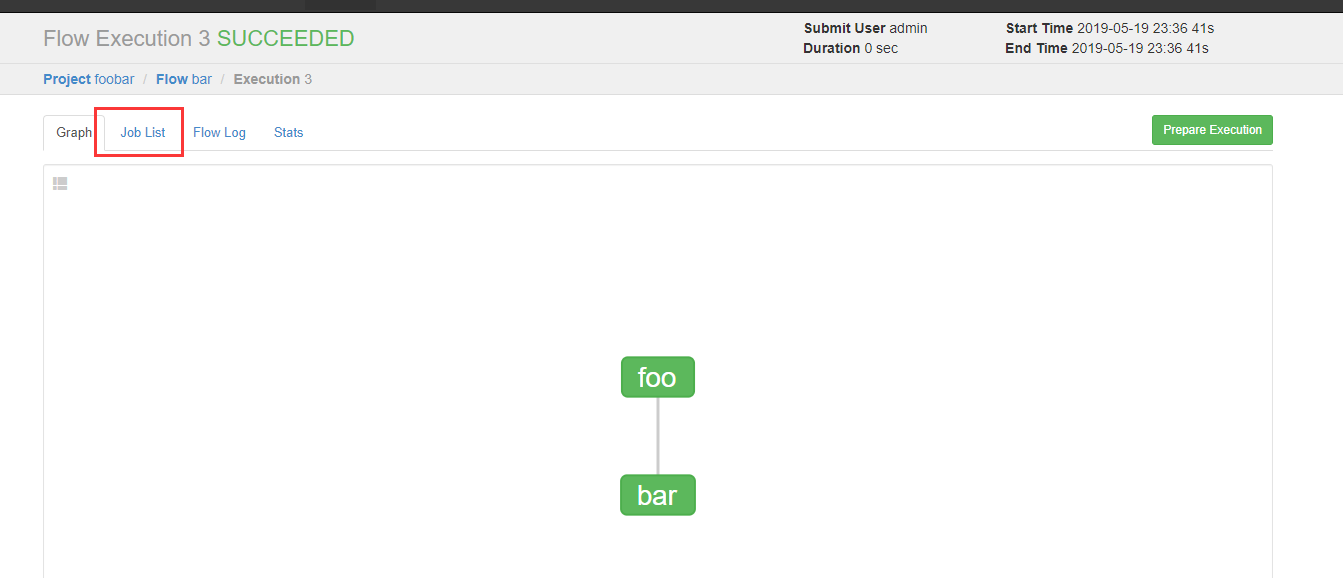
创建有依赖关系的多个job描述
新建一个bar.job
# bar.job
type=command
dependencies=foo
command=echo bar
新建一个foo.job
# foo.job
type=command
command=echo foo
把这两个文件一起打成zip包






HDFS操作任务
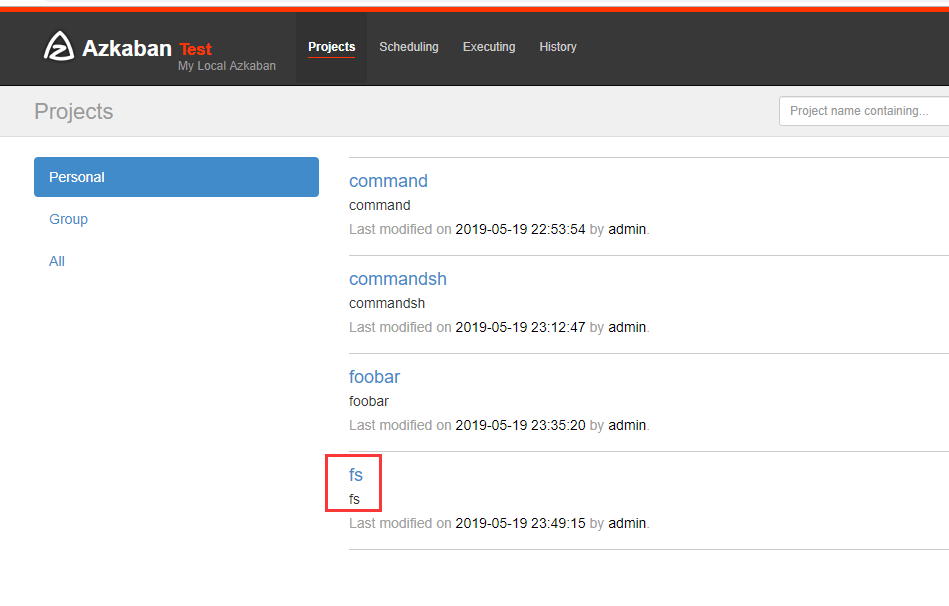
新建文件fs.job
# fs.job
type=command
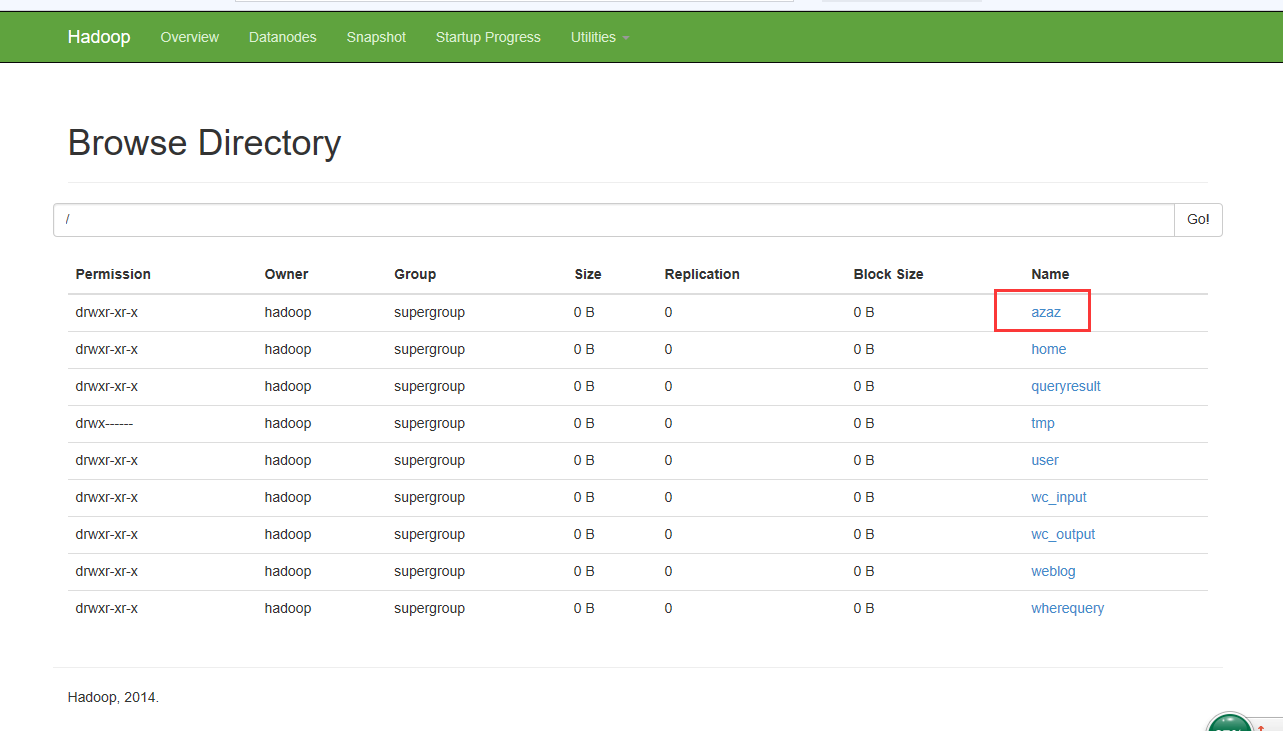
command=/opt/modules/hadoop-2.6./bin/hadoop fs -mkdir /azaz
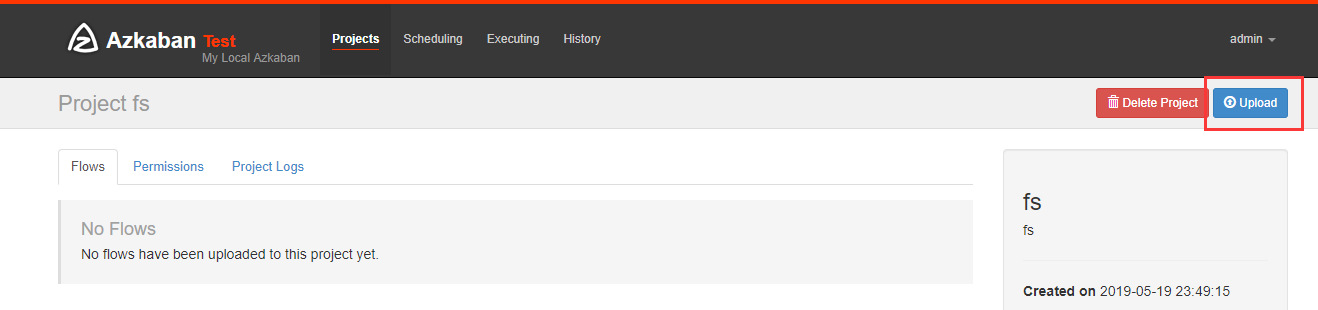
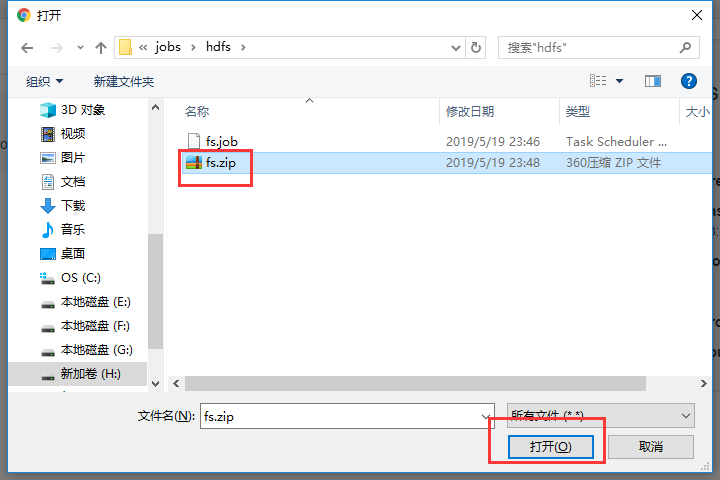
打包成zip包




MAPREDUCE任务
先创建一个输入路径


创建一个数据文件b.txt

输入一些单词

把b.txt文件上传到hdfs上

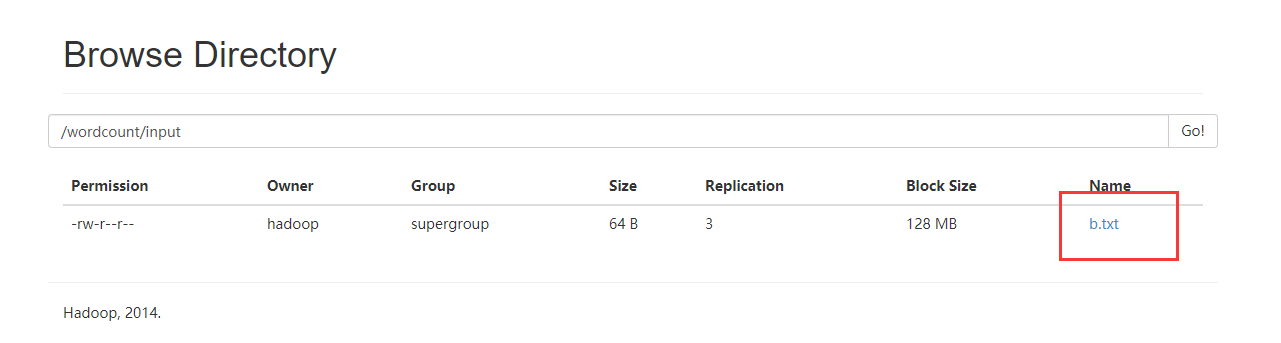
创建mrwc.job文件
# mrwc.job
type=command
command=/opt/modules/hadoop-2.6./bin/hadoop jar hadoop-mapreduce-examples-2.6..jar wordcount /wordcount/input /wordcount/azout
把这两个文件一起打包
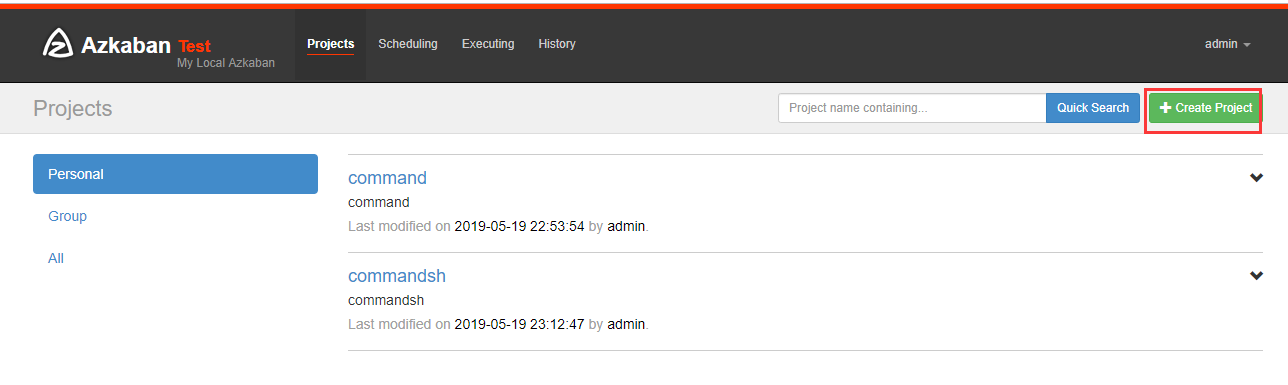
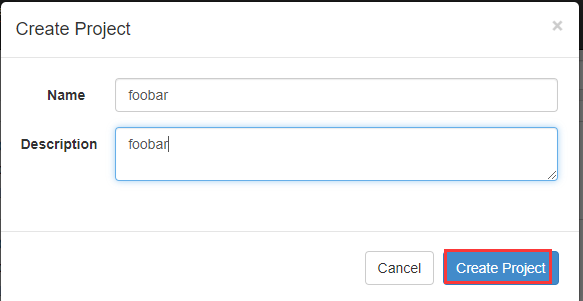
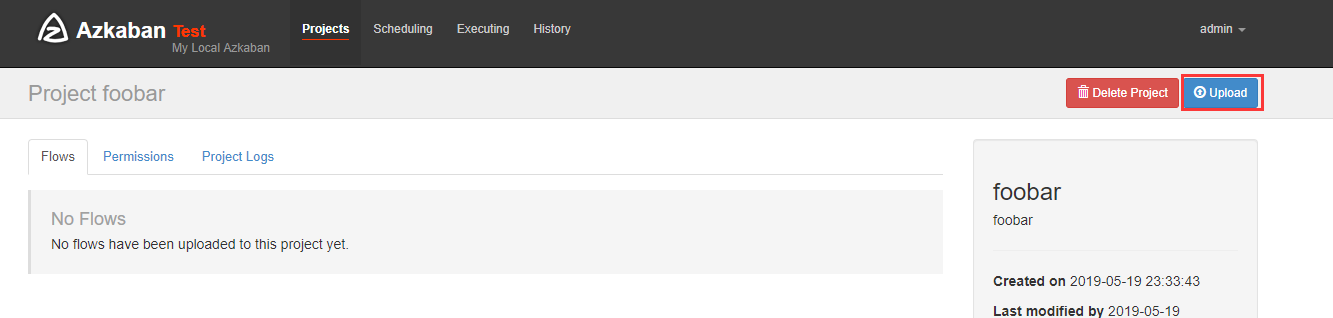
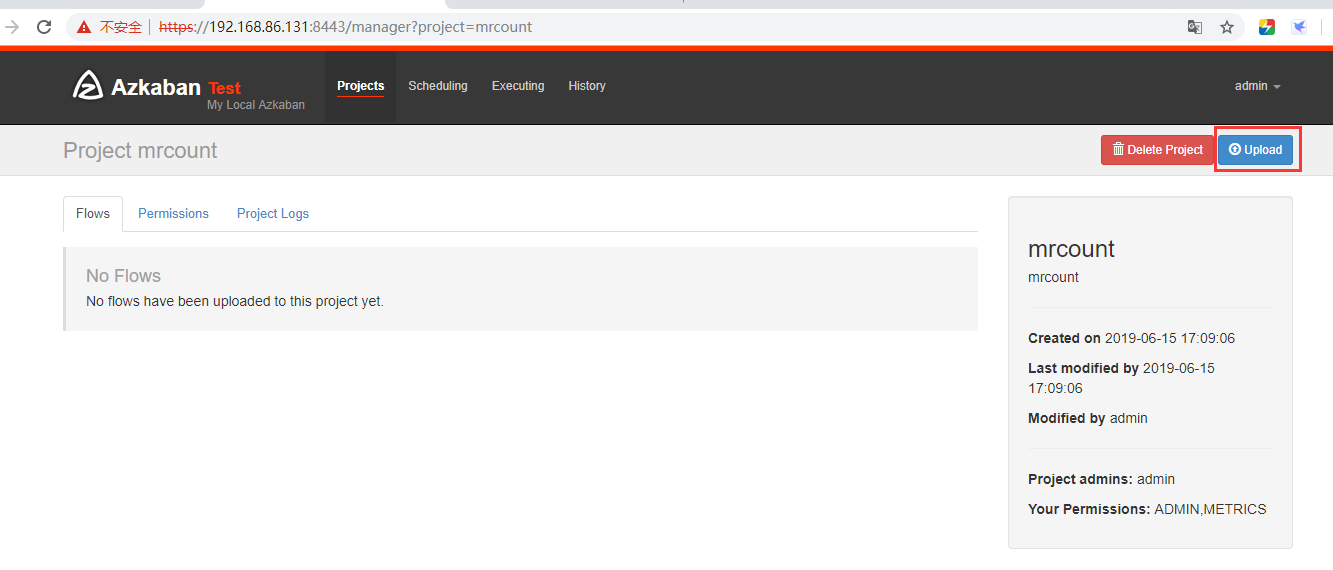
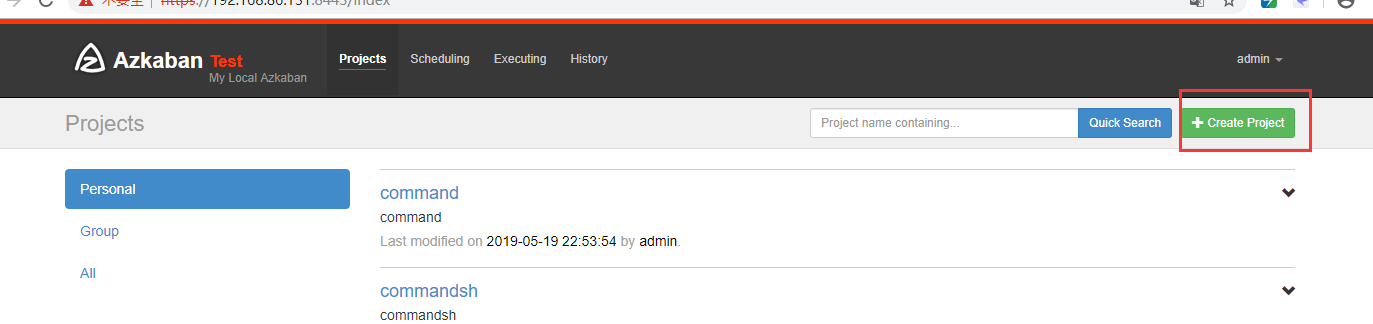
在azkaban创建一个project


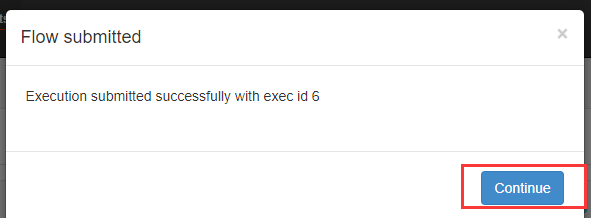

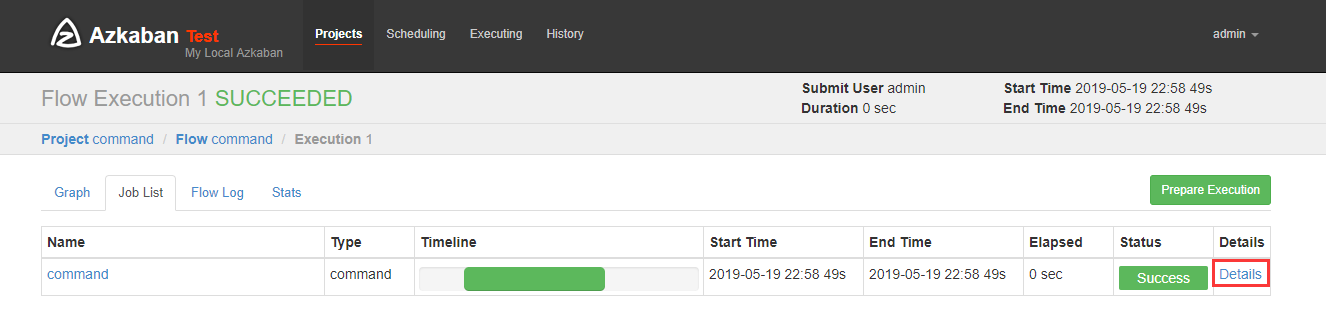
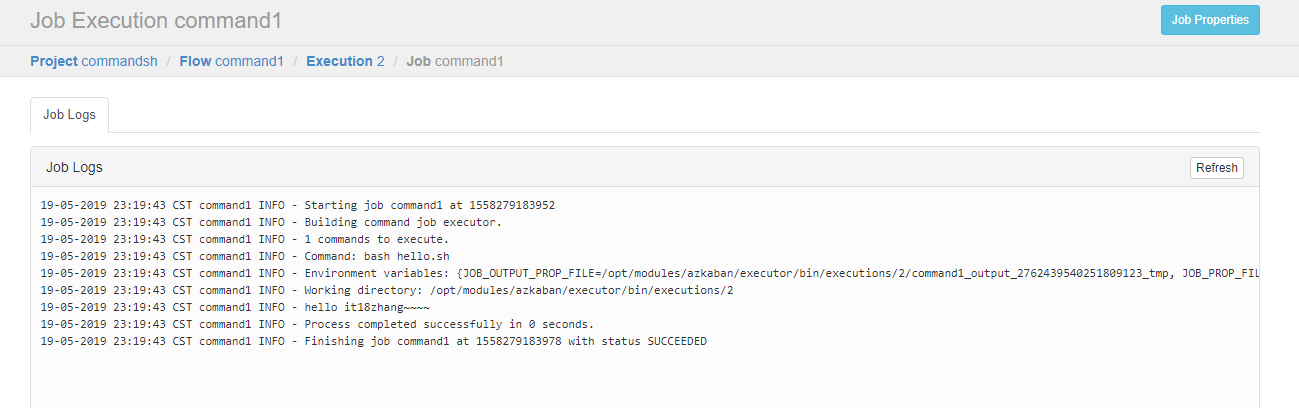
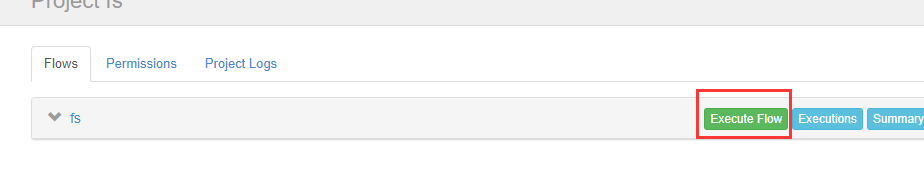
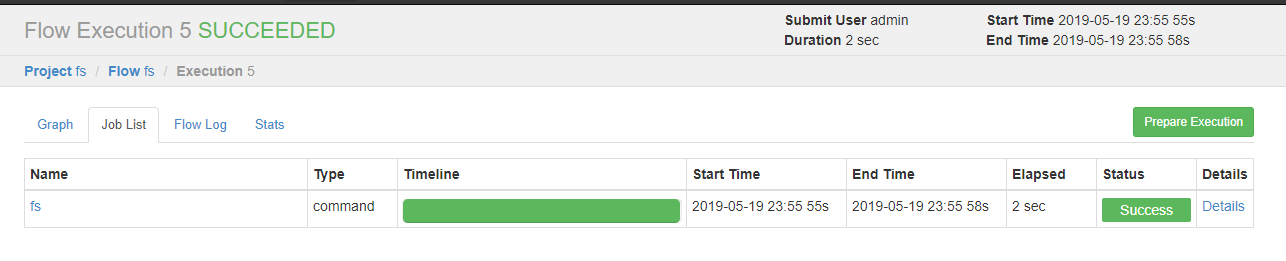
可以看到执行成功了
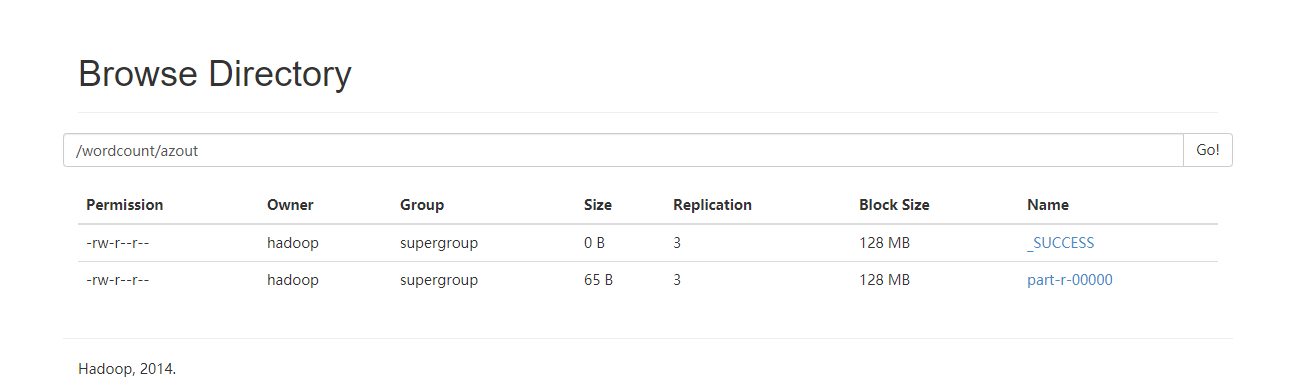
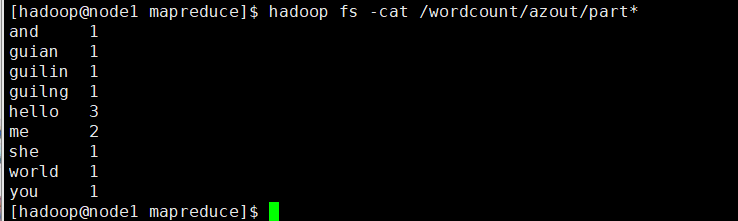
HIVE脚本任务
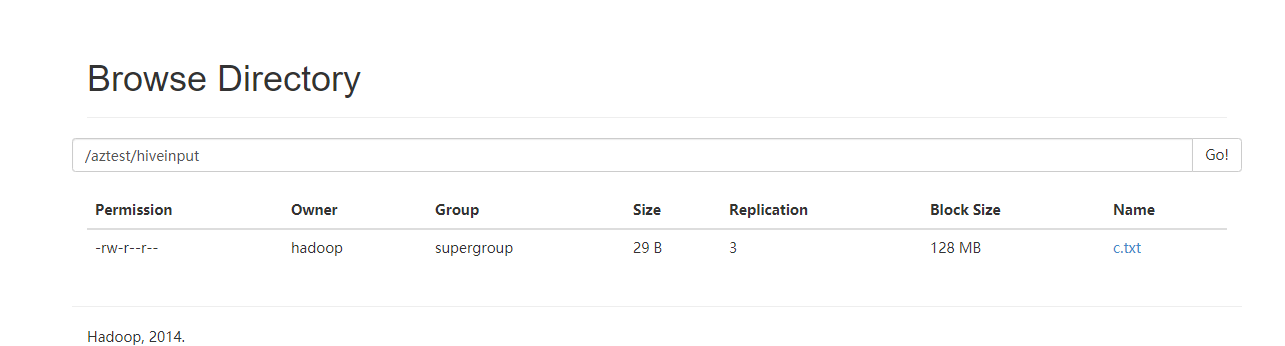
先创建目录
hadoop fs -mkdir -p /aztest/hiveinput
新建一个c.txt数据文件


把c.txt文件上传到HDFS上

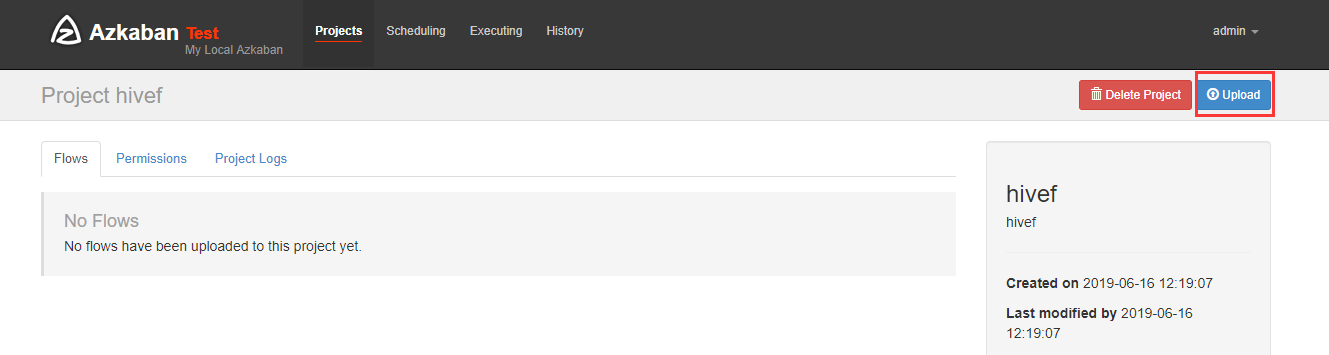
新建hivef.job
# hivef.job
type=command
command=/opt/modules/hive/bin/hive -f 'test.sql'
新建test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',' ;
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count() from aztest;
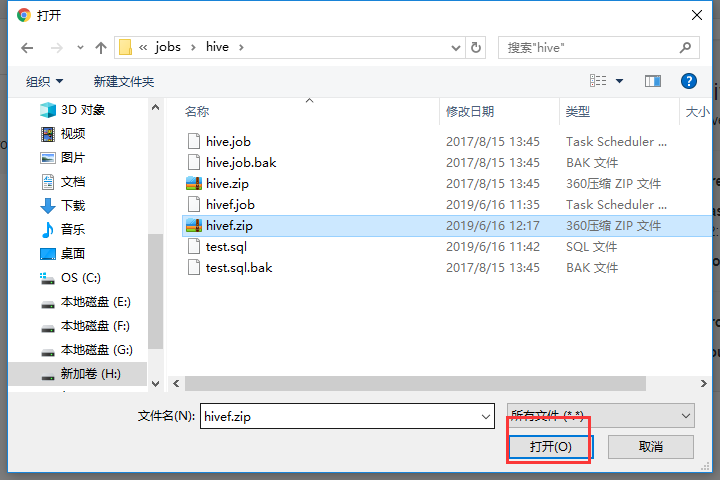
打包成hivef.zip



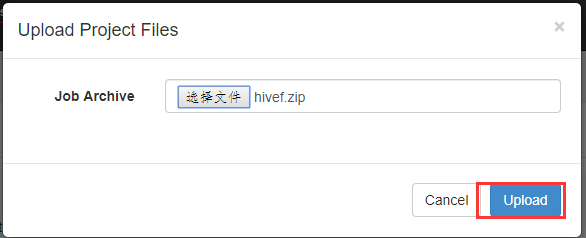
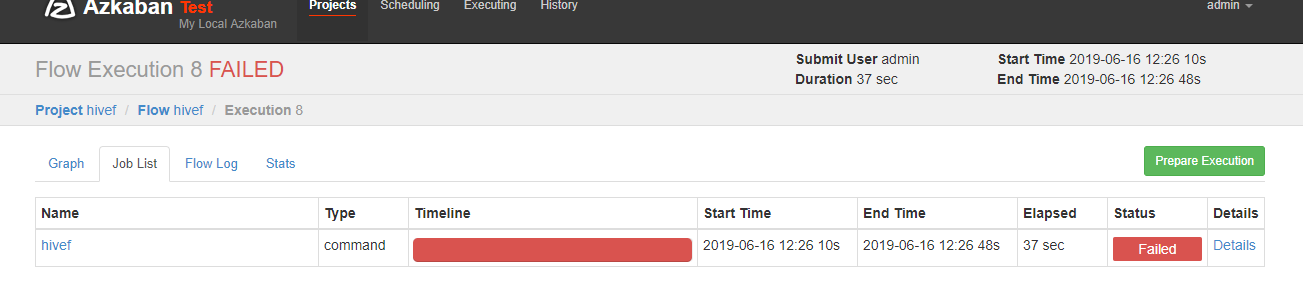
可以看到失败了,查看原因
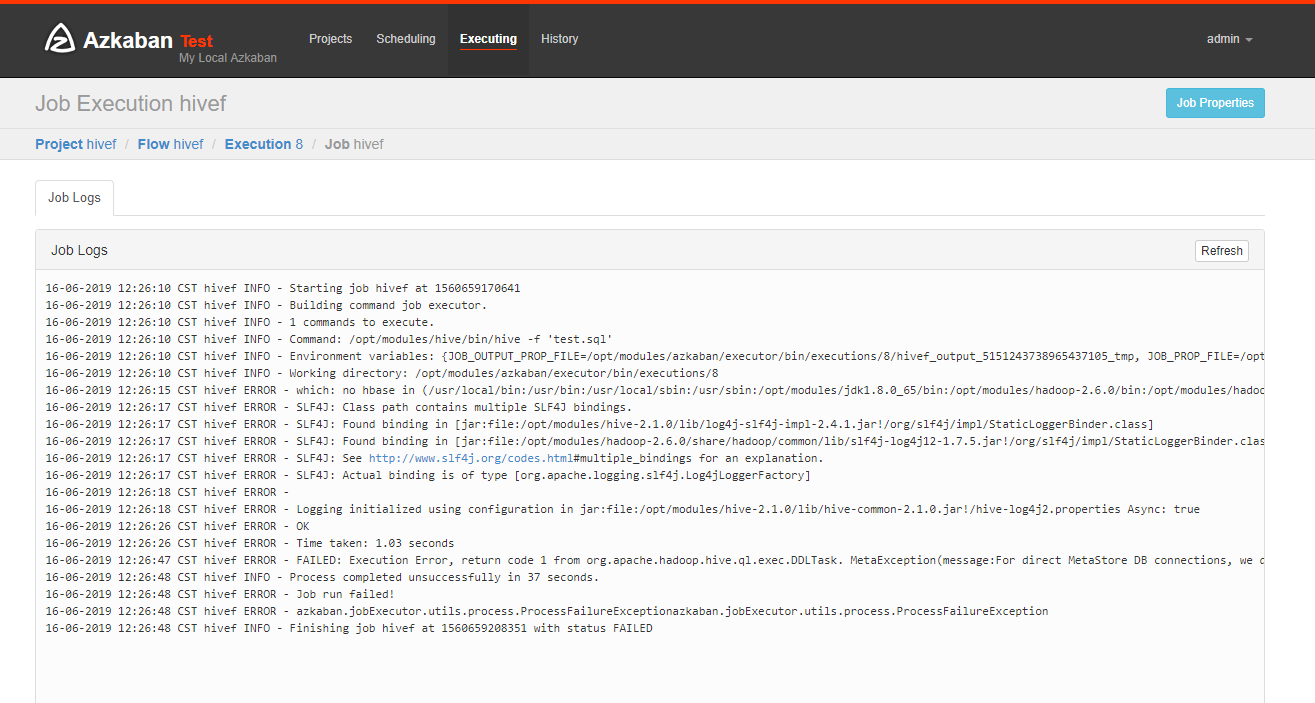
把本地hive的Lib目录下的mysql连接包的版本更换一下
换成这个5.1.28版本
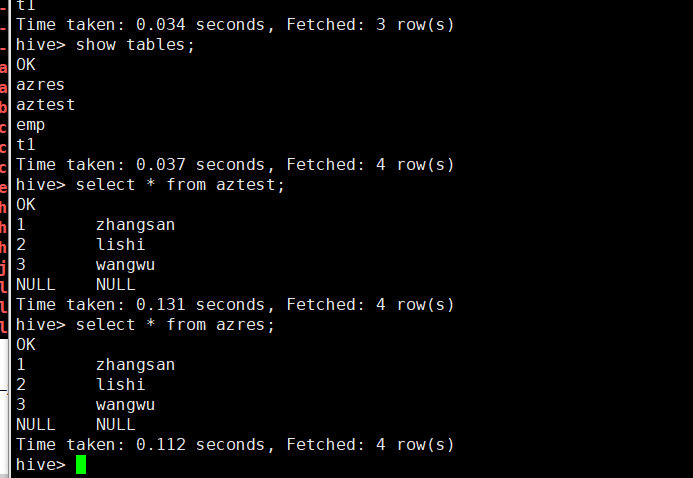
再运行一次,同样失败了,但是hive和hdfs上出来了相应的结果,具有原因我也不懂

17.Azkaban实战的更多相关文章
- 大数据技术之_13_Azkaban学习_Azkaban(阿兹卡班)介绍 + Azkaban 安装部署 + Azkaban 实战
一 概述1.1 为什么需要工作流调度系统1.2 常见工作流调度系统1.3 各种调度工具特性对比1.4 Azkaban 与 Oozie 对比二 Azkaban(阿兹卡班) 介绍三 Azkaban 安装部 ...
- Azkaban实战,Command类型单一job示例,任务中执行外部shell脚本,Command类型多job工作flow,HDFS操作任务,MapReduce任务,HIVE任务
本文转载自:https://blog.csdn.net/tototuzuoquan/article/details/73251616 1.Azkaban实战 Azkaba内置的任务类型支持comman ...
- Hadoop生态圈-Azkaban实战之Command类型执行指定脚本
Hadoop生态圈-Azkaban实战之Command类型执行指定脚本 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 1>.服务端测试代码(别忘记添加权限哟!) [yinzh ...
- Hadoop生态圈-Azkaban实战之Command类型多job工作流flow
Hadoop生态圈-Azkaban实战之Command类型多job工作流flow 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Azkaban内置的任务类型支持command.ja ...
- azkaban(安装配置加实战)
为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成:shell 脚本程序,java 程序,mapreduce 程序.hive 脚本等 各任务单元之间存在时间先后及前后依赖关 ...
- Flume+Sqoop+Azkaban笔记
大纲(辅助系统) 离线辅助系统 数据接入 Flume介绍 Flume组件 Flume实战案例 任务调度 调度器基础 市面上调度工具 Oozie的使用 Oozie的流程定义详解 数据导出 sqoop基础 ...
- 【大数据】Azkaban学习笔记
一 概述 1.1 为什么需要工作流调度系统 1)一个完整的数据分析系统通常都是由大量任务单元组成: shell脚本程序,java程序,mapreduce程序.hive脚本等 2)各任务单元之间存在时间 ...
- 《Spring 3.x 企业应用开发实战》目录
图书信息:陈雄华 林开雄 编著 ISBN 978-7-121-15213-9 概述: 第1章:对Spring框架进行宏观性的概述,力图使读者建立起对Spring整体性的认识. 第2章:通过一个简单的例 ...
- AI人工智能顶级实战工程师 课程大纲
课程名称 内容 阶段一.人工智能基础 — 高等数学必知必会 1.数据分析 "a. 常数eb. 导数c. 梯度d. Taylore. gini系数f. 信息熵与组合数 ...
随机推荐
- virtualBox中有线和无线两种情况下centos虚拟机和本地机互ping的方案
之前写微信点餐系统的时候,刚开始是无线连接,然后每次进去虚拟机ip和本地ip都会改变,所以每次都需要配置一下nginx,还有本地的路径.之后换有线连接,就研究了一下桥接模式有线情况下虚拟机静态ip设置 ...
- hdu 4810 Wall Painting (组合数+分类数位统计)
Wall Painting Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) T ...
- 2019ICPC陕西邀请赛复盘
题目链接:The 2019 ACM-ICPC China Shannxi Provincial Programming Contest A:签到,按花费时间从小到大排个序 #include<cs ...
- codeforces865C
Gotta Go Fast CodeForces - 865C You're trying to set the record on your favorite video game. The gam ...
- JVM——内存结构
一.程序计数器/PC寄存器 (Program Counter Registe) 用于保存当前正在执行的程序的内存地址(下一条jvm指令的执行地址),由于Java是支持多线程执行的,所以程序执行的轨迹不 ...
- SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xce in position 0: invalid continuatio
点击 文档>>设置文件编码>>Unicode>>Unicode(UTF-8)
- Python基础之深浅copy
1. 赋值 lst1 = [1, 2, 3, ["a", "b", "c"]] lst2 = lst1 lst1[0] = 11 print ...
- Linux长格式文件属性介绍
长格式文件属性 查看长格式文件命令:ll (或ls -l) (1)-:文件类型 -:普通文件 d:目录 b:块设备文件(随机读取) c:字符设备文件(顺序读取) p:管道文件 s:Socket套接字文 ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句SQL基本用法
本文展示三种在Hibernate中使用SQL语句进行数据查询基本用法 1.基本查询 2.条件查询 3.分页查询 package com.Gary.dao; import java.util.List; ...
- IO之复制文件的四种方式
1. 使用FileStreams复制 这是最经典的方式将一个文件的内容复制到另一个文件中. 使用FileInputStream读取文件A的字节,使用FileOutputStream写入到文件B. 这是 ...