ARTS第七周打卡
Algorithm : 做一个 leetcode 的算法题
/////////////////////////////////////////////////////////////////////////////////
206. 反转链表
反转一个单链表。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
进阶:
你可以迭代或递归地反转链表。你能否用两种方法解决这道题?
// 方法一:迭代
// 时间复杂度O(n),空间复杂度O(1)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if(NULL == head || NULL == head->next)
{
return head;
} #if 0
// 方法一: 迭代
ListNode* pPreNode = NULL;
ListNode* pNewHead = NULL;
while(head)
{
// 保存下一个节点
ListNode* pNextNode = head->next; // 如果是最后一个节点,作为新链表头结点返回
if(pNextNode == NULL)
{
pNewHead = head;
} // 改变链表节点指向方向
head->next = pPreNode;
pPreNode = head;
head = pNextNode;
} return pNewHead; #else // 方法二:递归(执行用时 :12 ms, 内存消耗 :9.4 MB)
ListNode* pNode = reverseList(head->next);
head->next->next = head; // 当前节点的后一个节点的next指向自己
head->next = NULL; // 更新当前节点的next为NULL return pNode;
#endif
}
};
/////////////////////////////////////////////////////////////////////////////////
// 141.环形链表
// 给定一个链表,判断链表中是否有环
//你能用 O(1)(即,常量)内存解决此问题吗?
bool HasCycle(ListNode<int>* pHead)
{
if (NULL == pHead || NULL == pHead->m_pNextNode)
{
return false;
} ListNode<int>* pSlow = pHead;
ListNode<int>* pFast = pHead->m_pNextNode; while (pSlow && pFast && pFast->m_pNextNode)
{
if (pFast == pSlow)
{
return true;
} pSlow = pSlow->m_pNextNode;
pFast = pFast->m_pNextNode->m_pNextNode;
} return false;
}
/////////////////////////////////////////////////////////////////////////////////////////////////
// 148 排序链表
// 在O(nlgn)的时间复杂度和O(1)空间复杂度下,对链表进行排序; ---> 符合排序的方法有: 快速排序、归并排序、堆排序(空间复杂度不符合)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/ // 时间复杂度O(nlogn) --> 排序算法:快速排序(不稳定)、归并排序(稳定)、堆排序(不稳定)
// 空间复杂度O(1) --> // 归并排序:
// 1.找到链表中间节点(快慢链表)
// 2.合并两条有序的链表
// 归并排序有由上向下(找到中间节点)和由下向下(知道链表的长度)
class Solution {
public:
ListNode* MergeList(ListNode* head1, ListNode* head2)
{
if(NULL == head1)
{
return head2;
} if(NULL == head2)
{
return head1;
} // 1.较小的节点为新链表的头结点
ListNode* pMergeHead = NULL;
if(head1->val < head2->val)
{
pMergeHead = head1;
head1 = head1->next;
}
else
{
pMergeHead = head2;
head2 = head2->next;
} // 2.比较两条链表,较小的节点插入新链表
ListNode* pTmpNode = pMergeHead;
while(head1 && head2)
{
if(head1->val < head2->val)
{
pTmpNode->next = head1;
head1 = head1->next;
}
else
{
pTmpNode->next = head2;
head2 = head2->next;
} pTmpNode = pTmpNode->next;
} // 3.往新链表插入剩余的节点
if(NULL != head1)
{
pTmpNode->next = head1;
} if(NULL != head2)
{
pTmpNode->next = head2;
} return pMergeHead;
} ListNode* sortList(ListNode* head) {
if(NULL == head || NULL == head->next)
{
return head;
} // 1.使用归并排序:找到链表中间节点(这里使用快慢链表)
ListNode* pSlow = head;
ListNode* pFast = head->next;
while(pFast && pFast->next)
{
pSlow = pSlow->next;
pFast = pFast->next->next;
} // 2. 分成两个链表
pFast = pSlow;
pSlow = pSlow->next;
pFast->next = NULL; // 3.分治思想,继续排序剩下的节点
pFast = sortList(head);
pSlow = sortList(pSlow); // 4.合并两条有序的链表
return MergeList(pFast, pSlow);
}
};
// 方法二:使用快速排序
template <typename TYPE>
ListNode<TYPE>* GetPartation(ListNode<TYPE>* pLow, ListNode<TYPE>* pHight)
{
if (NULL == pLow)
{
return NULL;
} // 基准元素
TYPE stPivotVal = pLow->m_stData;
ListNode<TYPE>* pPivotNode = pLow; ListNode<TYPE>* pNode = pLow->m_pNextNode;
while (pNode != pHight)
{
if (pNode->m_stData < stPivotVal)
{
pPivotNode = pPivotNode->m_pNextNode;
std::swap(pNode->m_stData, pPivotNode->m_stData); // 这里只交换节点的值!!!
}
pNode = pNode->m_pNextNode;
} std::swap(pPivotNode->m_stData, pLow->m_stData); return pPivotNode;
} template <typename TYPE>
void QuickSortListLogic(ListNode<TYPE>* pHead, ListNode<TYPE>* pTail)
{
//链表范围是[low, high) ---> 数组范围是(low, hight)
if (pHead != pTail && pHead->m_pNextNode != pTail)
{
ListNode<TYPE>* pMidNode = GetPartation(pHead, pTail);
QuickSortListLogic(pHead, pMidNode);
QuickSortListLogic(pMidNode->m_pNextNode, pTail);
}
} template <typename TYPE>
ListNode<TYPE>* QuickSortList(ListNode<TYPE>* pHead)
{
if (NULL == pHead || NULL == pHead->m_pNextNode)
{
return pHead;
} QuickSortListLogic(pHead, (ListNode<TYPE>*)NULL); return pHead;
}
Review : 阅读并点评一篇英文技术文章
Mysql锁和锁等待信息:原文链接:https://dev.mysql.com/doc/refman/8.0/en/innodb-information-schema-understanding-innodb-locking.html
InnoDB Lock and Lock-Wait Information(锁和锁等待消息)
注意:mysql8.0之后….
When a transaction updates a row in a table, or locks it with
SELECT FOR UPDATE,InnoDBestablishes a listor queue of locks on that row.
当事物更新表中的一行,或者使用 SELECT FOR UPDATE锁定该行时,InnoDB会在该行上建立一个锁列表或者锁队列。
Similarly,
InnoDBmaintains a list of locks on a table for table-level locks.类似地,InnoDB在表上维护表级锁的锁列表
If a second transaction wants to update a row or lock a table already locked by a prior transaction in an
incompatible mode,
InnoDBadds a lock request for the row to the corresponding queue.如果第二个事务想要更新一行或者锁定一个已经被先前事务以不兼容模式锁定的表,InnoDB会将该行的锁请求添加到相应的队列中。
For a lock to be acquired by a transaction, all incompatible lock requests previously entered into the lock
queue for that row or table must be removed (which occurs when the transactions holding or requesting
those locks either commit or roll back).
对于事务要获取的锁,必须删除之前为该行或表进入锁队列的所有不兼容的锁请求(当持有或请求这些锁的事务提交或回滚时发生这种情况).
A transaction may have any number of lock requests for different rows or tables.
对于不同的行或表,事务可以有任意数量的锁请求。
At any given time, a transaction may request a lock that is held by another transaction, in which case it is
blocked by that other transaction.
在任何给定时间,事务都可以请求由另一个事务持有的锁,在这种情况下,它被另一个事务阻塞。
The requesting transaction must wait for the transaction that holds the blocking lock to commit or roll back.
请求事务必须等待持有阻塞锁的事务提交或者回滚
If a transaction is not waiting for a lock, it is in a
RUNNINGstate. If a transaction is waiting for a lock, it is in aLOCK WAITstate. (TheINFORMATION_SCHEMAINNODB_TRXtable indicates transaction state values.)如果事务不等待锁,则它处于运行状态;如果事务正在等待锁,则它处于锁等待状态。(INFOMATIOON_SCHEMA INNODB TRX 表表示事务状态值)
The Performance Schema
data_lockstable holds one or more rows for eachLOCK WAITtransaction,indicating any lock requests that prevent its progress.
性能模式 data_lock表为每个锁等待事务保存一个或多个行,指示阻止其进展的任何锁请求。
This table also contains one row describing each lock in a queue of locks pending for a given row or table.
该表哦还包含一行,描述给定行货表挂起的锁队列中的每个锁。
The Performance Schema
data_lock_waitstable shows which locks already held by a transaction areblocking locks requested by other transactions.
性能模式 data_lock 表显示事务已经持有哪些锁正在阻塞洽谈事务请求的锁。
Tips : 学习一个技术技巧
1.TCP与UDP(原文链接:https://hit-alibaba.github.io/interview/basic/network/TCP.html)
1.1 TCP在IP头部的封装

1.2 TCP头部
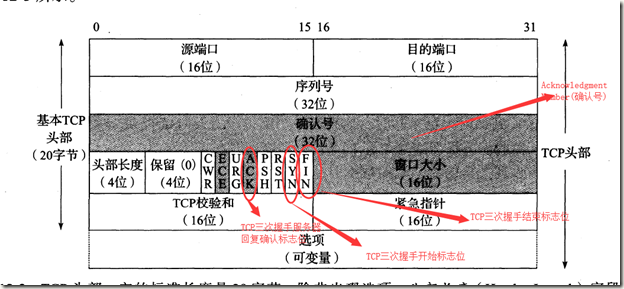
1.3 TCP的特性

1.4 TCP三次握手
三次握手的过程的示意图如下:
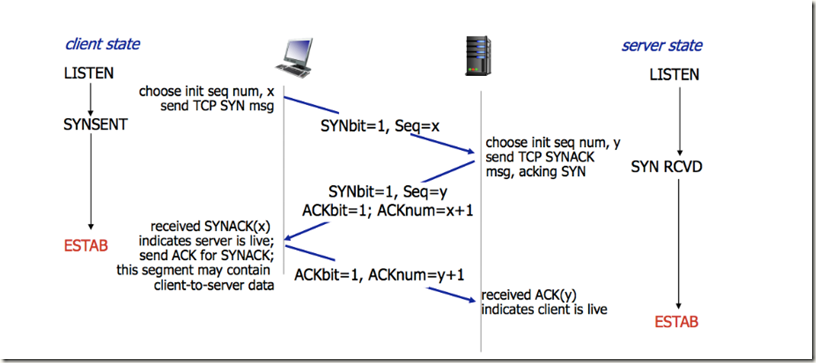
所谓三次握手(Three-way Handshake),是指建立一个 TCP 连接时,需要客户端和服务器总共发送3个包。
三次握手的目的是连接服务器指定端口,建立 TCP 连接,并同步连接双方的序列号和确认号,交换 TCP 窗口大小信息。在 socket 编程中,客户端执行 connect() 时。将触发三次握手。
- 第一次握手(SYN=1, seq=x):
客户端发送一个 TCP 的 SYN 标志位置1的包,指明客户端打算连接的服务器的端口,以及初始序号 X,保存在包头的序列号(Sequence Number)字段里。
发送完毕后,客户端进入 SYN_SEND 状态。
- 第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1):
服务器发回确认包(ACK)应答。即 SYN 标志位和 ACK 标志位均为1。服务器端选择自己 ISN 序列号,放到 Seq 域里,同时将确认序号(Acknowledgement Number)设置为客户的 ISN 加1,即X+1。 发送完毕后,服务器端进入 SYN_RCVD 状态。
- 第三次握手(ACK=1,ACKnum=y+1)
客户端再次发送确认包(ACK),SYN 标志位为0,ACK 标志位为1,并且把服务器发来 ACK 的序号字段+1,放在确定字段中发送给对方,并且在数据段放写ISN的+1
发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态,TCP 握手结束。
1.5 TCP四次挥手
四次挥手的示意图如下:
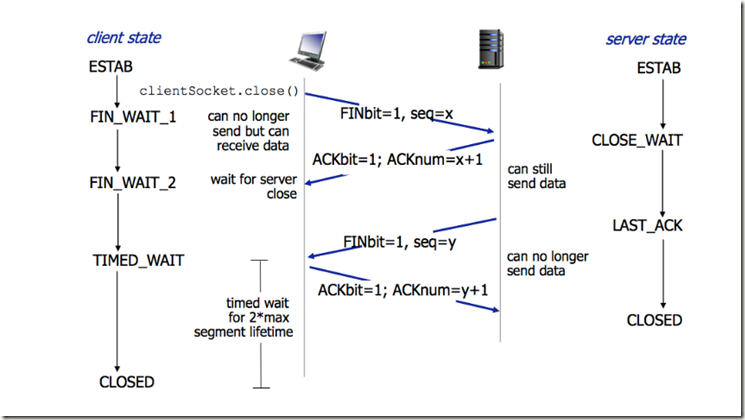
TCP 的连接的拆除需要发送四个包,因此称为四次挥手(Four-way handshake),也叫做改进的三次握手。客户端或服务器均可主动发起挥手动作,在 socket 编程中,任何一方执行 close() 操作即可产生挥手操作。
- 第一次挥手(FIN=1,seq=x)
假设客户端想要关闭连接,客户端发送一个 FIN 标志位置为1的包,表示自己已经没有数据可以发送了,但是仍然可以接受数据。
发送完毕后,客户端进入 FIN_WAIT_1 状态。
- 第二次挥手(ACK=1,ACKnum=x+1)
服务器端确认客户端的 FIN 包,发送一个确认包,表明自己接受到了客户端关闭连接的请求,但还没有准备好关闭连接。
发送完毕后,服务器端进入 CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态,等待服务器端关闭连接。
- 第三次挥手(FIN=1,seq=y)
服务器端准备好关闭连接时,向客户端发送结束连接请求,FIN 置为1。
发送完毕后,服务器端进入 LAST_ACK 状态,等待来自客户端的最后一个ACK。
- 第四次挥手(ACK=1,ACKnum=y+1)
客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT状态,等待可能出现的要求重传的 ACK 包。
服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态。
客户端等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。
2.1 UDP在IP数据包中的封装
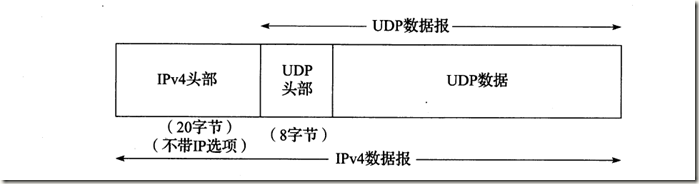
2.2 UDP头部
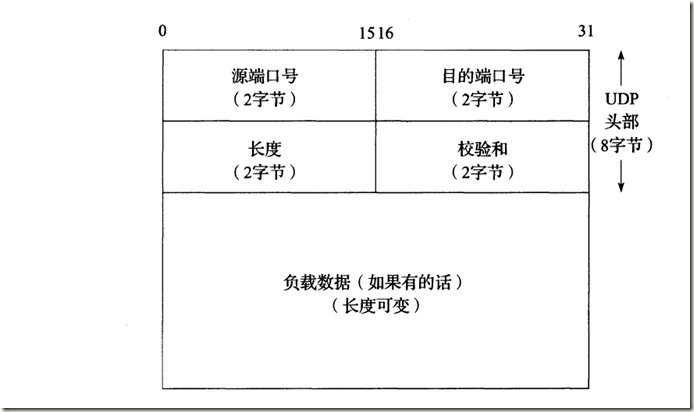
2.3 UDP特性
1.UDP缺乏可靠性
{
1.UDP 本身不提供确认,序列号,超时重传等机制。
2.UDP 数据报可能在网络中被复制,被重新排序。
3.即 UDP 不保证数据报会到达其最终目的地,也不保证各个数据报的先后顺序,也不保证每个数据报只到达一次
}
2.UDP长度是有限制的
{
- 每个 UDP 数据报都有长度,如果一个数据报正确地到达目的地,那么该数据报的长度将随数据一起传递给接收方。而 TCP 是一个字节流协议,没有任何(协议上的)记录边界。
- UDP 是无连接的。UDP 客户和服务器之前不必存在长期的关系。UDP 发送数据报之前也不需要经过握手创建连接的过程。
}
3.UDP支持广播和多播
2.4 UDP的优点
1.速度快,比TCP稍微安全,因为没有(SYN)
2.如何能同时实现TCP和UDP的优点?
{
UDP加connect
}
Share : 分享一篇有观点和思考的技术文章
https://hit-alibaba.github.io/interview/basic/network/TCP.html
ARTS第七周打卡的更多相关文章
- ARTS 第八周打卡
Algorithm : 做一个 leetcode 的算法题 13. 罗马数字转整数 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I ...
- ARTS 第十周打卡
Algorithm : 做一个 leetcode 的算法题 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: [&quo ...
- ARTS第六周打卡
Algorithm : 做一个 leetcode 的算法题 1.合并两个排序链表 2.树的子结构 3.二叉树的镜像 4.包含Min函数的栈 5.栈的压入.弹出 6.二叉搜索树的后序遍历 7.从上往下打 ...
- ARTS第七周
补上.瞎忙,看来还是效率的问题. 1.Algorithm:每周至少做一个 leetcode 的算法题2.Review:阅读并点评至少一篇英文技术文章3.Tip:学习至少一个技术技巧4.Share:分享 ...
- 20172325 2017-2018-2 《Java程序设计》第七周学习总结
20172325 2017-2018-2 <Java程序设计>第七周学习总结 教材学习内容总结 1.创建子类 (1) 子类是父类更具体的版本,但子类的实例化不依赖于父类: (2) 继承有单 ...
- 20145213《Java程序设计》第七周学习总结
20145213<Java程序设计>第七周学习总结 教材学习内容总结 周末快乐的时间总是短暂的,还没好好感受就到了要写博客的周日.有人喟叹时间都去哪儿了,那本周我们就来认识一下Java里的 ...
- 20145304 Java第七周学习报告
20145304<Java程序设计>第七周学习总结 教材学习内容总结 1.时间的度量: 格林威治标准时间(GMT)通过观察太阳而得,其正午是太阳抵达天空最高点之时,因地球的公转与自传,会造 ...
- 20145330第七周《Java学习笔记》
20145330第七周<Java学习笔记> 第十三章 时间与日期 认识时间与日期 时间的度量 GMT(格林威治标准时间):现在不是标准时间 世界时(UT):1972年UTC出来之前,UT等 ...
- 20145337《JAVA程序设计》第七周学习总结
20145337 <Java程序设计>第七周学习总结 教材学习内容总结 时间的度量 格林威治时间GMT,世界时UT,国际原子时TAI,世界协调时间UTC 就目前来说,即使标注为GMT,实际 ...
随机推荐
- Spring Cloud Gateway(三):网关处理器
1.Spring Cloud Gateway 源码解析概述 API网关作为后端服务的统一入口,可提供请求路由.协议转换.安全认证.服务鉴权.流量控制.日志监控等服务.那么当请求到达网关时,网关都做了哪 ...
- Tkinter 之Frame标签
一.参数说明 语法 作用 width 设置 Frame 的宽度默认值是 0 height 设置 Frame 的高度默认值是 0 background(bg) 设置 Frame 组件的背景颜色 bord ...
- Tkinter 之ListBox列表标签
一.参数说明 参数 作用 background (bg) 设置背景颜色 borderwidth (bd) 指定 Listbox 的边框宽度,通常是 2 像素 cursor 指定当鼠标在 Listbo ...
- mysql PS1个性化
method ) $ export MYSQL_PS1="\u@\h [\d]> " method ) mysql> prompt \u@\h [\d]> met ...
- OF1.7中的p_rgh【翻译】
翻译自:CFD-online 帖子地址:http://www.cfd-online.com/Forums/openfoam-solving/80454-p_rgh-1-7-a.html stawrog ...
- fixedFluxPressure边界条件【转载】
转载自:http://blog.sina.com.cn/s/blog_e256415d0102vikh.html fixedFluxPressure是OpenFOAM较新的一个边界条件,表示边界处压力 ...
- UNIX网络编程 环境搭建
配置好动态链接库或者静态链接库 1,下载UNIX网络编程书的头文件及示例源码unpv13e 2 按照readme来编译 Execute the following from the src/ d ...
- 2018-2019-2 (内附jdk与webgoat完整安装教程)《网络对抗技术》Exp9 Web安全基础 Week13 20165233
Exp9 Web安全基础 目录 一.基础问题 二.实验步骤 实验前准备:jdk与webgoat的安装 实验点一:SQL 命令注入(Command Injection) 数字型注入(Numeric SQ ...
- Mercury:唯品会全链路应用监控系统解决方案详解(含PPT)
Mercury:唯品会全链路应用监控系统解决方案详解(含PPT) 原创: 姚捷 高可用架构 2016-08-08
- java 接口和抽象类的一个最大的区别
写在前面,下面是在百度百科上看到的,之前就看过,这次再看感觉有更深的体会,真的是这样,每一个脚印都会留下痕迹 java接口和java抽象类有太多相似的地方,又有太多特别的地方,这里说下两者之间的一个最 ...