100天搞定机器学习|day54 聚类系列:层次聚类原理及案例
几张GIF理解K-均值聚类原理
k均值聚类数学推导与python实现
前文说了k均值聚类,他是基于中心的聚类方法,通过迭代将样本分到k个类中,使每个样本与其所属类的中心或均值最近。
今天我们看一下无监督学习之聚类方法的另一种算法,层次聚类:
层次聚类前提假设类别直接存在层次关系,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。创建聚类树有聚合聚类(自下而上合并)和分裂聚类(自上而下分裂)两种方法,分裂聚类一般很少使用,不做介绍。
聚合聚类
聚合聚类具体过程
对于给定的样本集合,开始将每个样本分到一个类,然后再按照一定的规则(比如类间距最小),将满足规则的类进行合并,反复进行,直到满足停止条件。聚合聚类三要素有:
①距离或相似度(闵可夫斯基距离,相关系数、夹角余弦)
②合并规则(最长/短距离,中心距离,平均距离)
③停止条件(类个数或类直径达到或超过阈值)

聚合聚类算法
输入:n个样本组成的样本集合及样本间距离
输出:样本集合的层次化聚类
(1)计算n个样本两两之间欧氏距离{dij}
(2)构造n个类,每个类只包含一个样本
(3)合并类间距最小的两个类,构造一个新类
(4)计算新类与其他各类的距离,若类的个数为1,终止计算,否则回到(3)

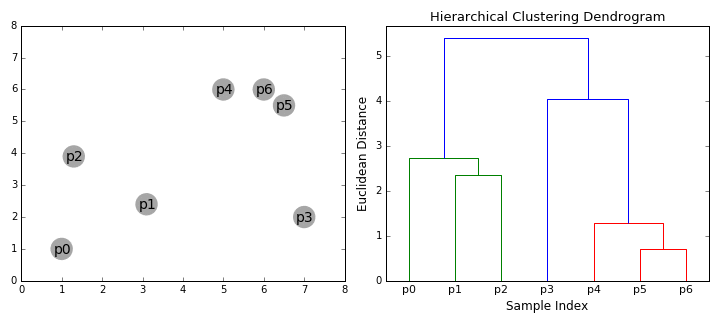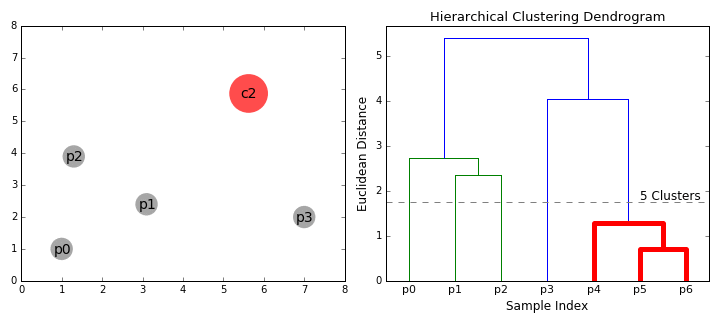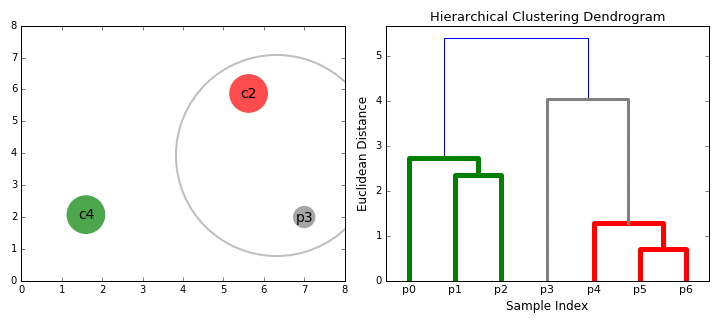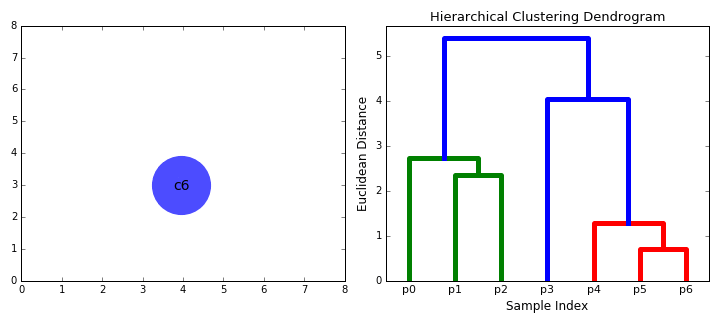
动画表示:

python实现及案例
import queue
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
class clusterNode:
def init(self, value, id=[],left=None, right=None, distance=-1, count=-1, check = 0):
'''
value: 该节点的数值,合并节点时等于原来节点值的平均值
id:节点的id,包含该节点下的所有单个元素
left和right:合并得到该节点的两个子节点
distance:两个子节点的距离
count:该节点所包含的单个元素个数
check:标识符,用于遍历时记录该节点是否被遍历过
'''
self.value = value
self.id = id
self.left = left
self.right = right
self.distance = distance
self.count = count
self.check = check
def show(self):
#显示节点相关属性
print(self.value,' ',self.left.id if self.left!=None else None,' ',\
self.right.id if self.right!=None else None,' ',self.distance,' ',self.count)
class hcluster:
def distance(self,x,y):
#计算两个节点的距离,可以换成别的距离
return math.sqrt(pow((x.value-y.value),2))
def minDist(self,dataset):
#计算所有节点中距离最小的节点对
mindist = 1000
for i in range(len(dataset)-1):
if dataset[i].check == 1:
#略过合并过的节点
continue
for j in range(i+1,len(dataset)):
if dataset[j].check == 1:
continue
dist = self.distance(dataset[i],dataset[j])
if dist < mindist:
mindist = dist
x, y = i, j
return mindist, x, y
#返回最小距离、距离最小的两个节点的索引
def fit(self,data):
dataset = [clusterNode(value=item,id=[(chr(ord('a')+i))],count=1) for i,item in enumerate(data)]
#将输入的数据元素转化成节点,并存入节点的列表
length = len(dataset)
Backup = copy.deepcopy(dataset)
#备份数据
while(True):
mindist, x, y = self.minDist(dataset)
dataset[x].check = 1
dataset[y].check = 1
tmpid = copy.deepcopy(dataset[x].id)
tmpid.extend(dataset[y].id)
dataset.append(clusterNode(value=(dataset[x].value+dataset[y].value)/2,id=tmpid,\
left=dataset[x],right=dataset[y],distance=mindist,count=dataset[x].count+dataset[y].count))
#生成新节点
if len(tmpid) == length:
#当新生成的节点已经包含所有元素时,退出循环,完成聚类
break
for item in dataset:
item.show()
return dataset
def show(self,dataset,num):
plt.figure(1)
showqueue = queue.Queue()
#存放节点信息的队列
showqueue.put(dataset[len(dataset) - 1])
#存入根节点
showqueue.put(num)
#存入根节点的中心横坐标
while not showqueue.empty():
index = showqueue.get()
#当前绘制的节点
i = showqueue.get()
#当前绘制节点中心的横坐标
left = i - (index.count)/2
right = i + (index.count)/2
if index.left != None:
x = [left,right]
y = [index.distance,index.distance]
plt.plot(x,y)
x = [left,left]
y = [index.distance,index.left.distance]
plt.plot(x,y)
showqueue.put(index.left)
showqueue.put(left)
if index.right != None:
x = [right,right]
y = [index.distance,index.right.distance]
plt.plot(x,y)
showqueue.put(index.right)
showqueue.put(right)
plt.show()
def setData(num):
#生成num个随机数据
Data = list(np.random.randint(1,100,size=num))
return Data
if name == 'main':
num = 20
dataset = setData(num)
h = hcluster()
resultset = h.fit(dataset)
h.show(resultset,num)

添加微信,我们在微信群接着聊

参考:
https://cdn-images-1.medium.com/max/800/1*ET8kCcPpr893vNZFs8j4xg.gif
https://github.com/MLEveryday/100-Days-Of-ML-Code
https://blog.csdn.net/qiu1440528444/article/details/80707845
https://blog.csdn.net/weixin_41958939/article/details/83218634

{kind=link}
本文由博客一文多发平台 OpenWrite 发布!
100天搞定机器学习|day54 聚类系列:层次聚类原理及案例的更多相关文章
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day9-12 支持向量机
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day11 实现KNN
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- 100天搞定机器学习|Day17-18 神奇的逻辑回归
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day19-20 加州理工学院公开课:机器学习与数据挖掘
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day21 Beautiful Soup
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day22 机器为什么能学习?
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day33-34 随机森林
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
随机推荐
- 【自己给自己题目做】:如何用裸的 Canvas 实现魔方效果
最终demo -> 3d魔方 体验方法: 浮动鼠标找到合适的位置,按空格键暂停 选择要翻转的3*3模块,找到相邻两个正方体,鼠标点击第一个正方体,并且一直保持鼠标按下的状态直到移到第二个正方体后 ...
- 网络分裂 redis 集群
REDIS cluster-tutorial -- Redis中文资料站 -- Redis中国用户组(CRUG) http://www.redis.cn/topics/cluster-tutorial ...
- 制作 python解释器
https://www.zhihu.com/tardis/sogou/qus/27286136
- visual studio python快捷键
打开交互式窗口: alt + i 智能提示: ctrl + j, or alt + ->
- flutter GridView 网格布局
当数据量很大的时候用矩阵方式排列比较清晰.此时我们可以用网格列表组件 GridView 实 现布局. GridView 创建网格列表有多种方式,常用有以下两种. 1.可以通过 GridView.cou ...
- Dart 变量、常量和命名规则
/* Dart 变量: dart是一个强大的脚本类语言,可以不预先定义变量类型 ,自动会类型推导 dart中定义变量可以通过var关键字可以通过类型来申明变量 如: var str='this is ...
- python中的修饰符@的作用
1.一层修饰符 1)简单版,编译即实现 在一个函数上面添加修饰符 @另一个函数名 的作用是将这个修饰符下面的函数作为该修饰符函数的参数传入,作用可以有比如你想要在函数前面添加记录时间的代码,这样每个函 ...
- 将一个多表关联的条件查询中的多表通过 create select 转化成一张单表的sql、改为会话级别临时表 【我】
将一个多表关联的条件查询中的多表通过 create select 转化成一张单表的sql 将结果改为创建一个会话级别的临时表: -- 根据下面这两个sql CREATE TABLE revenu ...
- spring Securicty入门(一)
在一次项目中启动测试一个借口,结果提示要登录,如下图.原因是无意中引用了spring Securicty的依赖,别的啥都没干就弹出来这个,懵逼了半天最后注释掉.shiro你引个jar包别的不配置,也不 ...
- Qt编写气体安全管理系统13-短信告警
一.前言 短信告警这个模块在很多项目中都用上了,比如之前做过的安防系统,温湿度报警系统等,主要的流程就是收到数据判断属于某种报警后,组织短信字符串内容,发送到指定的多个手机号码上面,使用的是短信猫硬件 ...