什么是SQL Server2019大数据群集?
从SQL Server 2019(15.x)开始,SQL Server大数据群集允许您部署在Kubernetes上运行的SQL Server,Spark和HDFS容器的可伸缩群集。这些组件并排运行,使您能够从Transact-SQL或Spark读取,写入和处理大数据,从而使您可以轻松地将高价值的关系数据与大容量的大数据结合并进行分析。
有关最新版本的新功能和已知问题的更多信息,请参见发行说明。
情境
SQL Server大数据群集为您与大数据进行交互提供了灵活性。您可以查询外部数据源,将大数据存储在SQL Server管理的HDFS中,或通过群集查询来自多个外部数据源的数据。然后,您可以将数据用于AI,机器学习和其他分析任务。以下各节提供有关这些方案的更多信息。
数据虚拟化
通过利用SQL Server PolyBase,SQL Server大数据群集可以查询外部数据源,而无需移动或复制数据。SQL Server 2019(15.x)向数据源引入了新的连接器。
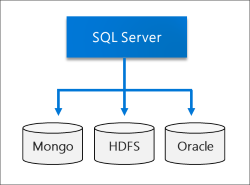
数据湖
SQL Server大数据群集包括一个可伸缩的HDFS 存储池。这可用于存储可能从多个外部源提取的大数据。一旦将大数据存储在大数据集群的HDFS中,您就可以分析和查询数据并将其与关系数据结合起来。
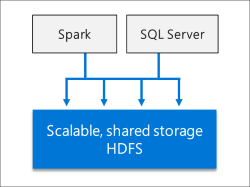
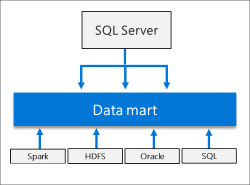
横向扩展数据集市
SQL Server大数据群集提供横向扩展计算和存储,以提高分析任何数据的性能。可以摄取来自各种来源的数据,并将其分布在整个数据池节点中作为缓存进行进一步分析。
集成的AI和机器学习
SQL Server大数据群集可对HDFS存储池和数据池中存储的数据启用AI和机器学习任务。您可以使用R,Python,Scala或Java在SQL Server中使用Spark以及内置的AI工具。

管理与监控
通过命令行工具,API,门户和动态管理视图的组合来提供管理和监视。
您可以使用Azure Data Studio在大数据群集上执行各种任务。新的SQL Server 2019 Extension启用了此功能。该扩展提供:
- 内置的片段,用于常见的管理任务。
- 能够浏览HDFS,上传文件,预览文件和创建目录。
- 能够创建,打开和运行Jupyter兼容的笔记本。
- 数据虚拟化向导可简化外部数据源的创建。
建筑
SQL Server大数据集群是由Kubernetes精心策划的Linux容器集群。
Kubernetes概念
Kubernetes是一个开源的容器编排器,可以根据需要扩展容器的部署。下表定义了一些重要的Kubernetes术语:
| 簇 | Kubernetes集群是一组机器,称为节点。一个节点控制群集,并被指定为主节点。其余节点是工作程序节点。Kubernetes主机负责在工作人员之间分配工作,并监视集群的运行状况。 |
| 节点 | 节点运行容器化的应用程序。它可以是物理机或虚拟机。Kubernetes集群可以包含物理机节点和虚拟机节点的混合体。 |
| 荚 | 吊舱是Kubernetes的原子部署单元。容器是运行一个应用程序所需的一个或多个容器以及相关资源的逻辑组。每个吊舱都在一个节点上运行;一个节点可以运行一个或多个Pod。Kubernetes主节点自动将Pod分配给集群中的节点。 |
在SQL Server大数据群集中,Kubernetes负责SQL Server大数据群集的状态。Kubernetes构建和配置集群节点,将Pod分配给节点,并监视集群的运行状况。
大数据集群架构
下图显示了SQL Server大数据群集的组件。
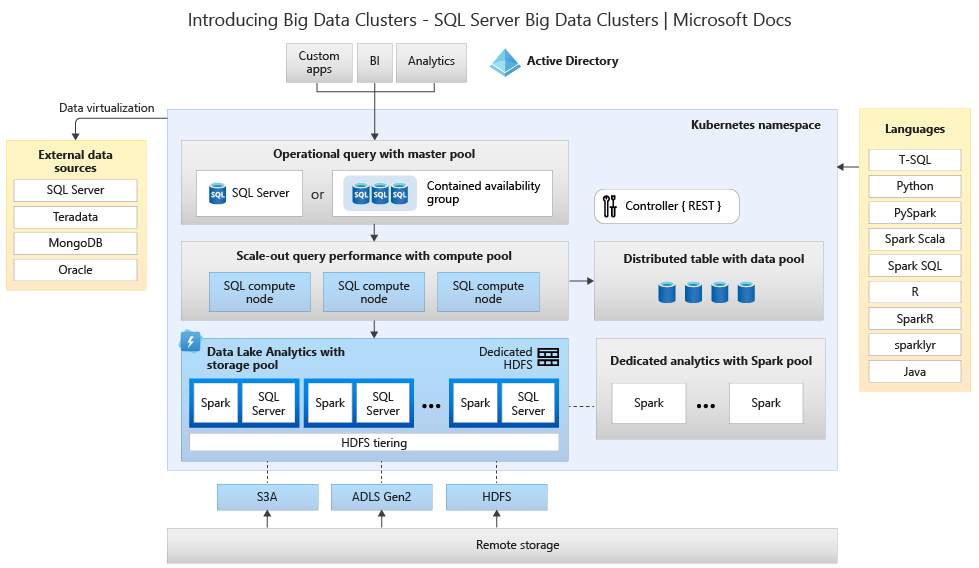
控制者
控制器为群集提供管理和安全性。它包含控制服务,配置存储和其他群集级别的服务,例如Kibana,Grafana和Elastic Search。
计算池
计算池为集群提供计算资源。它包含在Linux Pod上运行SQL Server的节点。计算池中的Pod分为用于特定处理任务的SQL Compute实例。
资料池
数据池用于数据持久性和缓存。数据池由一个或多个在Linux上运行SQL Server的Pod组成。它用于从SQL查询或Spark作业中提取数据。SQL Server大数据群集数据集市保留在数据池中。
储存池
存储池由存储池Pod组成,这些Pod由Linux,Spark和HDFS上的SQL Server组成。SQL Server大数据群集中的所有存储节点都是HDFS群集的成员。
什么是SQL Server2019大数据群集?的更多相关文章
- 知方可补不足~SQL为大数据引入分区表
回到目录 一些概念 分区表在oracle和sqlserver中都上存在的,当数据表的数据量过大时,上千万,上亿的数据,在进行数据查询时需要显得比较慢,性能很差,这时是时候引入分区表了,分区表顾名思义, ...
- C# & SQL Server大数据量插入方式对比
以下内容大部分来自: http://blog.csdn.net/tjvictor/article/details/4360030 部分内容出自互联网,实验结果为亲测. 最近自己开发一个向数据库中插入大 ...
- SQL Server 大数据量insert into xx select慢的解决方案
最近项目有个需求,把一张表中的数据根据一定条件增删改到另外一张表.按理说这是个很简单的SQL.可是在实际过程中却出现了超级长时间的执行过程. 后来经过排查发现是大数据量insert into xx s ...
- [转]Sql server 大数据量分页存储过程效率测试附代码
本文转自:http://www.cnblogs.com/lli0077/archive/2008/09/03/1282862.html 在项目中,我们经常遇到或用到分页,那么在大数据量(百万级以上)下 ...
- SQL优化-大数据量分页优化
百万数据量SQL,在进行分页查询时会出现性能问题,例如我们使用PageHelper时,由于分页查询时,PageHelper会拦截查询的语句会进行两个步骤 1.添加 select count(*)fro ...
- Microsoft Soft SQL Server 大数据----分区表性能测试
分区表 MSSQL有一个大数据储存方案,可以提高效率那就是分区表. 使用起来跟普通表没有区别.至于具体原理自己度娘吧. 真正性能的提高,是依赖于硬件的加入.也是就说,当把一个表设置成分区表,每一个分区 ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
- SQL Server 大数据量分页建议方案
简单的说就是这个 select top(20) * from( select *, rowid = row_number() over(order by xxx) from tb with(noloc ...
- sql server 大数据, 统计分组查询,数据量比较大计算每秒钟执行数据执行次数
-- 数据量比较大的情况,统计十分钟内每秒钟执行次数 ); -- 开始时间 ); -- 结束时间 declare @num int; -- 结束时间 set @begintime = '2019-08 ...
随机推荐
- 以Integer类型传参值不变来理解Java值传参
最近在写代码的时候出了一个错误,由于对值引用理解的不深,将Integer传入方法中修改,以为传入后直接修改Integer中的值就不用写返回值接收了,虽然很快发现了问题,但还是来总结一下 首先是代码: ...
- 获取豆瓣电影数据(R与API获取网页数据)
一般成熟的网站都会有反爬虫策略,例如限制访问次数,限制访问 IP,动态显示数据等.爬虫和反爬虫就是一直相爱相杀地互相钳制.如果要通过爬虫来获取某些大型网站的数据,那是一件很费时费力的活.小白总遭遇过在 ...
- PHP中,json汉字编码
当用json与js或者其它客户端交互时,如果有中文,则会变成unicode.虽然能使用,但是影响观看.不好调试呀.从网上找到了几个方法 一,用下面这个函数,需要编码时,直接调用这个函数就成 funct ...
- kindedit,uedit 上传跨域返回
1.kindedit 跨域上传图片的时候,a.com 上传到b.com接收图片服务器,然后返回图片地址. 2.一般如果不做任何处理是获取不到返回的信息的.原因是跨域了 3.所以一般在上传成功后,在跳转 ...
- Linux 下的 mysql 自动备份
Linux 下实现自动备份,主要就是编写好执行备份的 shell script( *.sh )文件,设好权限(可读,可执行).然后利用 Linux 定时任务 crontab 来执行备份脚本就可以了.以 ...
- Win10 默认用Windows照片查看程序打开图片
::复制以下内容到记事本: @echo off&cd\&color 0a&cls echo 恢复Win10照片查看器 reg add "HKLM\SOFTWARE\M ...
- Gin-Go学习笔记八:Gin-Web框架 常用的包
常用的包 1> 在java,.net,php,node.js等语言常常会使用到包的概念.包的使用,可以加快项目的进度的开发,以及更好的实现项目的效果.我在网上查到了包的作用如下: 1.包 ...
- 攻防世界-web -高手进阶区-PHP2
题目 首先发现源码泄露 /index.phps 查看源代码 即: <?php if("admin"===$_GET[id]) { echo("<p>no ...
- element表格的滚动条在合计上边
默认滚动条是在下边的,不好看,这里改一下 修改样式.完美解决: .el-table { overflow-x: auto; } .el-table__header-wrapper, .el-table ...
- Generate a document using docxtemplater
生成word文档,更新word内容 http://javascript-ninja.fr/docxtemplater/v1/examples/demo.html https://docxtempl ...