什么是SQL Server2019大数据群集?
从SQL Server 2019(15.x)开始,SQL Server大数据群集允许您部署在Kubernetes上运行的SQL Server,Spark和HDFS容器的可伸缩群集。这些组件并排运行,使您能够从Transact-SQL或Spark读取,写入和处理大数据,从而使您可以轻松地将高价值的关系数据与大容量的大数据结合并进行分析。
有关最新版本的新功能和已知问题的更多信息,请参见发行说明。
情境
SQL Server大数据群集为您与大数据进行交互提供了灵活性。您可以查询外部数据源,将大数据存储在SQL Server管理的HDFS中,或通过群集查询来自多个外部数据源的数据。然后,您可以将数据用于AI,机器学习和其他分析任务。以下各节提供有关这些方案的更多信息。
数据虚拟化
通过利用SQL Server PolyBase,SQL Server大数据群集可以查询外部数据源,而无需移动或复制数据。SQL Server 2019(15.x)向数据源引入了新的连接器。
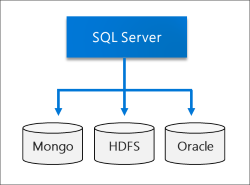
数据湖
SQL Server大数据群集包括一个可伸缩的HDFS 存储池。这可用于存储可能从多个外部源提取的大数据。一旦将大数据存储在大数据集群的HDFS中,您就可以分析和查询数据并将其与关系数据结合起来。
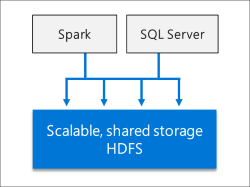
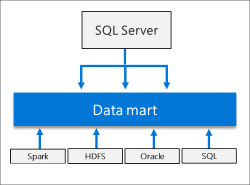
横向扩展数据集市
SQL Server大数据群集提供横向扩展计算和存储,以提高分析任何数据的性能。可以摄取来自各种来源的数据,并将其分布在整个数据池节点中作为缓存进行进一步分析。
集成的AI和机器学习
SQL Server大数据群集可对HDFS存储池和数据池中存储的数据启用AI和机器学习任务。您可以使用R,Python,Scala或Java在SQL Server中使用Spark以及内置的AI工具。

管理与监控
通过命令行工具,API,门户和动态管理视图的组合来提供管理和监视。
您可以使用Azure Data Studio在大数据群集上执行各种任务。新的SQL Server 2019 Extension启用了此功能。该扩展提供:
- 内置的片段,用于常见的管理任务。
- 能够浏览HDFS,上传文件,预览文件和创建目录。
- 能够创建,打开和运行Jupyter兼容的笔记本。
- 数据虚拟化向导可简化外部数据源的创建。
建筑
SQL Server大数据集群是由Kubernetes精心策划的Linux容器集群。
Kubernetes概念
Kubernetes是一个开源的容器编排器,可以根据需要扩展容器的部署。下表定义了一些重要的Kubernetes术语:
| 簇 | Kubernetes集群是一组机器,称为节点。一个节点控制群集,并被指定为主节点。其余节点是工作程序节点。Kubernetes主机负责在工作人员之间分配工作,并监视集群的运行状况。 |
| 节点 | 节点运行容器化的应用程序。它可以是物理机或虚拟机。Kubernetes集群可以包含物理机节点和虚拟机节点的混合体。 |
| 荚 | 吊舱是Kubernetes的原子部署单元。容器是运行一个应用程序所需的一个或多个容器以及相关资源的逻辑组。每个吊舱都在一个节点上运行;一个节点可以运行一个或多个Pod。Kubernetes主节点自动将Pod分配给集群中的节点。 |
在SQL Server大数据群集中,Kubernetes负责SQL Server大数据群集的状态。Kubernetes构建和配置集群节点,将Pod分配给节点,并监视集群的运行状况。
大数据集群架构
下图显示了SQL Server大数据群集的组件。
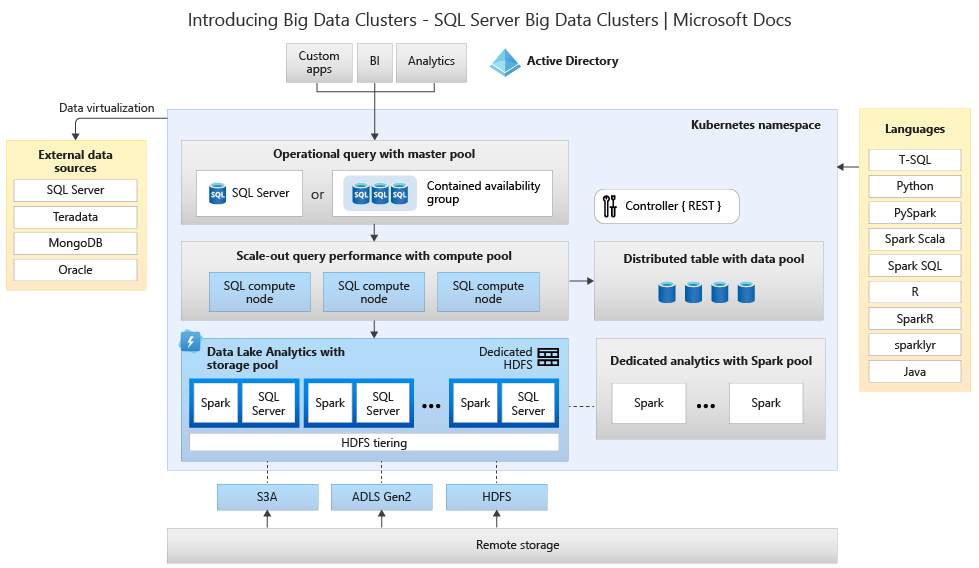
控制者
控制器为群集提供管理和安全性。它包含控制服务,配置存储和其他群集级别的服务,例如Kibana,Grafana和Elastic Search。
计算池
计算池为集群提供计算资源。它包含在Linux Pod上运行SQL Server的节点。计算池中的Pod分为用于特定处理任务的SQL Compute实例。
资料池
数据池用于数据持久性和缓存。数据池由一个或多个在Linux上运行SQL Server的Pod组成。它用于从SQL查询或Spark作业中提取数据。SQL Server大数据群集数据集市保留在数据池中。
储存池
存储池由存储池Pod组成,这些Pod由Linux,Spark和HDFS上的SQL Server组成。SQL Server大数据群集中的所有存储节点都是HDFS群集的成员。
什么是SQL Server2019大数据群集?的更多相关文章
- 知方可补不足~SQL为大数据引入分区表
回到目录 一些概念 分区表在oracle和sqlserver中都上存在的,当数据表的数据量过大时,上千万,上亿的数据,在进行数据查询时需要显得比较慢,性能很差,这时是时候引入分区表了,分区表顾名思义, ...
- C# & SQL Server大数据量插入方式对比
以下内容大部分来自: http://blog.csdn.net/tjvictor/article/details/4360030 部分内容出自互联网,实验结果为亲测. 最近自己开发一个向数据库中插入大 ...
- SQL Server 大数据量insert into xx select慢的解决方案
最近项目有个需求,把一张表中的数据根据一定条件增删改到另外一张表.按理说这是个很简单的SQL.可是在实际过程中却出现了超级长时间的执行过程. 后来经过排查发现是大数据量insert into xx s ...
- [转]Sql server 大数据量分页存储过程效率测试附代码
本文转自:http://www.cnblogs.com/lli0077/archive/2008/09/03/1282862.html 在项目中,我们经常遇到或用到分页,那么在大数据量(百万级以上)下 ...
- SQL优化-大数据量分页优化
百万数据量SQL,在进行分页查询时会出现性能问题,例如我们使用PageHelper时,由于分页查询时,PageHelper会拦截查询的语句会进行两个步骤 1.添加 select count(*)fro ...
- Microsoft Soft SQL Server 大数据----分区表性能测试
分区表 MSSQL有一个大数据储存方案,可以提高效率那就是分区表. 使用起来跟普通表没有区别.至于具体原理自己度娘吧. 真正性能的提高,是依赖于硬件的加入.也是就说,当把一个表设置成分区表,每一个分区 ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
- SQL Server 大数据量分页建议方案
简单的说就是这个 select top(20) * from( select *, rowid = row_number() over(order by xxx) from tb with(noloc ...
- sql server 大数据, 统计分组查询,数据量比较大计算每秒钟执行数据执行次数
-- 数据量比较大的情况,统计十分钟内每秒钟执行次数 ); -- 开始时间 ); -- 结束时间 declare @num int; -- 结束时间 set @begintime = '2019-08 ...
随机推荐
- Rider 中无法显示DataTable,VS2019的.netCore才有DataTable可视化工具(4)
如下图在vs2017中是这样的 在2019中是可以直接看的 在Rider中无论什么项目都不支持.
- javascript时间戳与日期格式的相互转换
这里总结下JavaScript中时间戳和日期格式的相互转换方法(自定义函数). 将时间戳转换为日期格式 function timestampToTime(timestamp) { var date = ...
- Kuboard Kubernetes安装
一.简介 Kubernetes 容器编排已越来越被大家关注,然而使用 Kubernetes 的门槛却依然很高,主要体现在这几个方面: 集群的安装复杂,出错概率大 Kubernetes相较于容器化,引入 ...
- excel中统计COUNTIFS的值为0
excel中统计COUNTIFS的值为0 个人认为是由于导出的文件里面的字符个数问题 使用 =COUNTIFS(H1:H175,"微信支付") 这个的结果居然是0,找了很多办法 于 ...
- java的三种随机数生成方式
随机数的产生在一些代码中很常用,也是我们必须要掌握的.而java中产生随机数的方法主要有三种: 第一种:new Random() 第二种:Math.random() 第三种:currentTimeMi ...
- Delphi - TIdFTP 两个重要函数
TIdFTP 两个重要函数 项目开发过程中发现,直接对于服务器上的文件/路径进行处理,是很危险的事情,因为一旦文件/路径不存在,程序就会抛异常,影响客户体验.所以在对服务器上的文件/路径进行访问之前, ...
- js 数组去重总结
es6 set ES6 提供了新的数据结构 Set.它类似于数组,但是成员的值都是唯一的,没有重复的值. let arr = [1,2,3,4,3,2,3,4,6,7,6]; let unique = ...
- Salesforce LWC学习(一)Salesforce DX配置
LWC: Create a Salesforce DX Project and Lightning Web Component:https://www.youtube.com/watch?v=p268 ...
- Vue 动态控制页面中按钮是否显示和样式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 基于 ECharts 封装甘特图并实现自动滚屏
项目中需要用到甘特图组件,之前的图表一直基于 EChart 开发,但 EChart 本身没有甘特图组件,需要自行封装 经过一番鏖战,终于完成了... 我在工程中参考 v-chart 封装了一套图表组件 ...