Clickhouse高可用配置总结
1. 简述
Clickhouse默认是多分片单副本集群,分布式表的配置是每个分片只有一份,如果某个节点挂掉的话,则会直接导致写入或查询异常;Clickhouse是具有高可用特性的,即每个分片具有2个或以上的副本,当某个节点挂掉时,其他节点上的副本会替代其继续工作,以保证集群正常运行。
本文主要介绍近期针对clickhouse高可用配置的方法以及数据复制的几种方式进行总结。
2. 环境说明
2.1. 软硬件环境
|
硬件环境 |
CPU:8 Intel Xeon E312xx (Sandy Bridge) 内存:16 GB 网卡:千兆虚拟网卡 |
|
软件环境 |
OS:CentOS Linux release 7.5.1804 ClickHouse 19.4.3.1. |
2.2. 集群介绍
|
序号 |
名称 |
IP |
|
1 |
wuxiang-test-1 |
192.168.40.218 |
|
2 |
wuxiang-test-2 |
192.168.40.238 |
|
3 |
wuxiang-test-3 |
192.168.40.239 |
|
4 |
wuxiang-test-4 |
192.168.40.240 |
|
5 |
wuxiang-test-5 |
192.168.40.241 |
3. 配置文件说明
clickhouse高可用配置主要用到metrika.xml,默认路径:/etc/metrika.xml。

internal_replication
表示是否只将数据写入其中一个副本,默认为false,表示写入所有副本,在复制表的情况下可能会导致重复和不一致,所以这里一定要改为true。
四种复制模式:
- 非复制表,internal_replication=false。写入单机表时,不同服务器查询结果不同;插入到分布式表中的数据被插入到两个本地表中,如果在插入期间没有问题,则两个本地表上的数据保持同步。我们称之为“穷人的复制”,因为复制在网络出现问题的情况下容易发生分歧,没有一个简单的方法来确定哪一个是正确的复制。
- 非复制表,internal_replication=true。数据只被插入到一个本地表中,但没有任何机制可以将它转移到另一个表中。因此,在不同主机上的本地表看到了不同的数据,查询分布式表时会出现非预期的数据。显然,这是配置ClickHouse集群的一种不正确的方法。
- 复制表,internal_replication=true。插入到分布式表中的数据仅插入到其中一个本地表中,但通过复制机制传输到另一个主机上的表中。因此两个本地表上的数据保持同步。这是官方推荐配置。
- 复制表,internal_replication=false。数据被插入到两个本地表中,但同时复制表的机制保证重复数据会被删除。数据会从插入的第一个节点复制到其它的节点。其它节点拿到数据后如果发现数据重复,数据会被丢弃。这种情况下,虽然复制保持同步,没有错误发生。但由于不断的重复复制流,会导致写入性能明显的下降。所以这种配置实际应该是避免的。
一条数据要insert到ontime_all_2中,假设经过rand()实际是要写入到hadoop1的ontime_local表中,此时ontime_local配置了两个副本。
如果internal_replication是false,那么就会分别往两个副本中插入这条数据。注意!!!分别插入,可能一个成功,一个失败,插入结果不检验!这就导致了不一致性;
而如果internal_replication是true,则只往1个副本里写数据,其他副本则是由ontime_local自己进行同步,这样就解决了写入一致性问题。
配置文件中macros若省略,则建复制表时每个分片需指定zookeeper路径及副本名称,同一分片上路径相同,副本名称不同;若不省略需每个分片不同配置:
<!-- wuxiang-test-1 -->
- <macros>
- <shard>01</shard>
- <replica>replica1</replica>
- </macros>
<!-- wuxiang-test-2 -->
- <macros>
- <shard>01</shard>
- <replica>replica2</replica>
- </macros>
<!-- wuxiang-test-3 -->
- <macros>
- <shard>02</shard>
- <replica>replica1</replica>
- </macros>
<!-- wuxiang-test-4 -->
- <macros>
- <shard>02</shard>
- <replica>replica2</replica>
- </macros>
4. 复制表引擎说明
复制表引擎采用Replicated*MergeTree表引擎,此类表引擎支持表级别的数据副本,要使用副本,需在配置中设置zookeeper集群地址。
--创建复制表
- CREATE TABLE test.szt_data_rep
- (
- id String,
- card_id String,
- deal_time String,
- trade_type String,
- trade_sum Int16,
- trade_value Int16,
- terminal_code String,
- com_line String,
- line_station String,
- car_gate String,
- flag String,
- finish_time Date
- )
- ENGINE = ReplicatedMergeTree('/data/clickhouse/{shard}/szt_data_rep', '{replica}')
- PARTITION BY finish_time
- ORDER BY (card_id, terminal_code)
- SAMPLE BY card_id;
ReplicatedMergeTree参数
- zoo_path — ZooKeeper 中该表的路径,可自定义。
- replica_name — ZooKeeper 中的该表的副本名称,自定义。
以上参数则是读取配置文件中macros自动填充
表副本创建完成后,可连接zk查看对应路径:
/share/apps/zookeeper-3.4./bin/zkCli.sh -server 192.168.40.218:
5. 数据副本
本文档主要研究两种数据备份方式:服务器备份、交叉备份。
5.1. 服务器备份
服务器备份,按照本文研究的2分片2副本的情况,即一个分片下两个服务器作为两个副本,这两个服务器的数据互相备份。

配置文件修改如下:

若internal_replication为true,则是由表自动同步数据,若为false则由集群自动同步数据,若使用复制表推荐internal_replication设置为true。
此种配置优点在于若分片中有一台服务器挂掉,则另一台可以立即替代其继续运行,待机器启动后数据会自动同步;缺点:复制表需占用整台服务器,耗费资源。
5.2. 交叉备份
交叉备份与上一种备份方式的区别在于,每台机器上运行多个clickhouse实例,以不同端口区分,这样两台服务器上的表数据即可交叉备份。
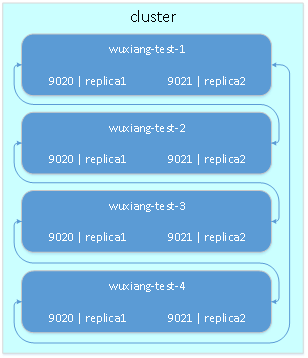
配置文件修改如下:
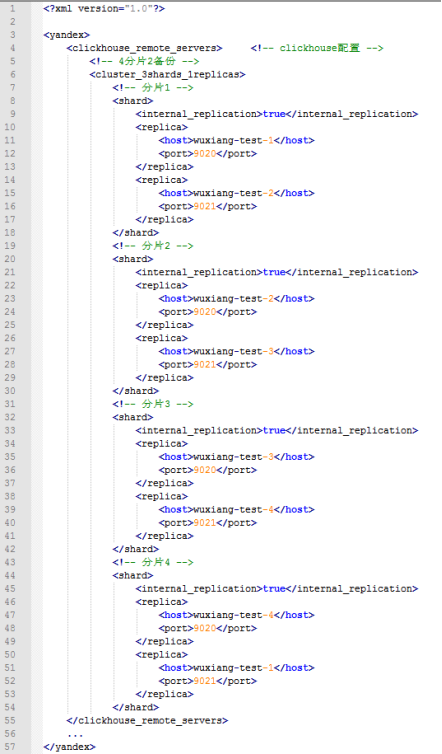
此种配置方式优点在于节省服务器成本,缺点在于clickhouse对于复杂查询本身占用CPU比较多,多一个服务器同时运行多个实例,可能会对性能造成一定影响。
多实例配置方法:
复制并修改clickhouse server文件:clickhouse-server-1
cp /etc/rc.d/init.d/clickhouse-server /etc/rc.d/init.d/clickhouse-server- vim /etc/rc.d/init.d/clickhouse-server-
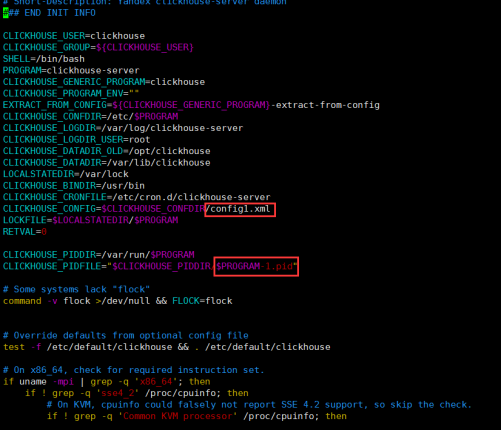
复制并修改配置文件:config1.xml
cp /etc/clickhouse-server/config.xml /etc/clickhouse-server/config1.xml vim /etc/clickhouse-server/config1.xml
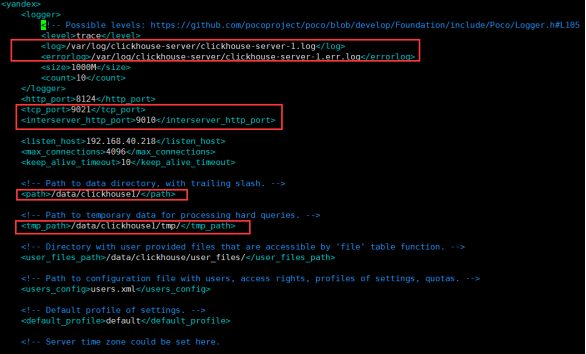
users.xml以及/etc/metrika.xml可根据实际情况决定是否创建新的配置文件;
修改完成之后启动新的实例,并按新设定的端口连接clickhouse即可。
#若没有对应的服务启动端口,需添加
firewall-cmd --zone=public --add-port=9021/tcp --permanent
#启动新的服务
service clickhouse-server- start #用新的端口启动
clickhouse-client -m -u default -h 192.168.40.218 --password F7Us3TU1 --port
6.集群扩展
对于增加或减少服务器的情况,分布式操作只需修改metrika.xml配置文件即可,至于表数据同步,目前找到两种方法:
6.1. 手动同步
在新的服务器上创建相同的表,将需迁移的服务器上的表数据移动到新的服务器对应目录下,然后连接clickhouse执行以下语句:
- detach table szt_data_t3; --先将表与数据分离(若表已存在)
- attach table szt_data_t3; --然后重新添加进来
6.2. 创建临时表
在新的服务器上创建表结构相同但表名不同的临时分布式表,然后执行以下语句:
- insert into {new_table} select * from {old_table};
然后删除原分布式表,将临时表重命名即可。
Clickhouse高可用配置总结的更多相关文章
- ClickHouse高可用集群的配置
上一篇文章写过centos 7下clickhouse rpm包安装和基本的目录结构,这里主要介绍clickhouse高可用集群的部署方案,因为对于默认的分布式表的配置,每个分片只有一份,这样如果挂掉一 ...
- MariaDB+Keepalived双主高可用配置MySQL-HA
利用keepalived构建高可用MySQL-HA,保证两台MySQL数据的一致性,然后用keepalived实现虚拟VIP,通过keepalived自带的服务监控功能来实现MySQL故障时自动切换. ...
- ResourceManager高可用配置
ResourceManager高可用配置 1. yarn-site.xml配置 <property> <name>yarn.resourcemanager.cluster-id ...
- Redis Sentinel实现高可用配置
一般情况下yum安装redis的启动目录在:”/usr/sbin” :配置目录在”/etc/redis/”在其目录下会有默认的redis.conf和redis-sentinel.conf redis高 ...
- Spring Cloud之踩坑01 -- Eureka高可用配置
转载:https://blog.csdn.net/dear_Alice_moon/article/details/79373955 问题描述: 在进行Eureka高可用配置时,控制台一直出现“.... ...
- Flume 高可用配置案例+load balance负载均衡+ 案例:日志的采集及汇总
高可用配置案例 (一).failover故障转移 在完成单点的Flume NG搭建后,下面我们搭建一个高可用的Flume NG集群,架构图如下所示: (1)节点分配 Flume的Agent和Colle ...
- Keepalived保证Nginx高可用配置
Keepalived保证Nginx高可用配置部署环境 keepalived-1.2.18 nginx-1.6.2 VM虚拟机redhat6.5-x64:192.168.1.201.192.168.1. ...
- springcloud-07-eureka HA的高可用配置
单机版的eureka, 运行时间稍长, 就会在管理界面出现红色的警告, 为了消除这个警告, 可以使用eureka的高可用配置: 只需要写一个工程配置不同的配置文件, 然后启动多实例即可: 请参照单机版 ...
- Rabbitmq安装、集群与高可用配置
历史: RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多 ...
随机推荐
- aardio类的例子
论坛里面相关资料太少,这里贴一下 库需要在工程的lib目录下,在ide里面就是用户库目录,比如 my_lib namespace my_lib{ import console class MyLibC ...
- 登陆服务器提示“You need to run "nvm install N/A" to install it before using it.”
一.登陆服务器提示“You need to run "nvm install N/A" to install it before using it.” 二.执行命令: nvm ls ...
- final,static,super,this
## final 关键字 **final关键字主要用在三个地方:变量.方法.类.** 1. **对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改:如果是引用类型的变 ...
- Android Studio 3.0——unable to resolve dependency for cordovalib
Android Studio 3.0 更新了gradle后,项目竟然开始报错unable to resolve dependency for cordovalib...打开build.gradle看了 ...
- python初级(302) 6 对象(五)
一.复习 1.什么是多态 2.什么是继承 二.继承:向父母学习 在面向对象编程中,类可以从其他类继承属性和方法.这样就有了类的整个家族,这个家族中的每个类共享相同的属性和方法.这样一来,每次向家族增加 ...
- python - logging.basicConfig format参数无效
有这么一段python代码 import threading import time import requests from decimal import Decimal, ROUND_DOWN i ...
- c# .net 4.5.2 asp.net mvc 使用hangfire
一定要有hangfire数据库,否则hangfire会报错. (obStorage.Current property value has not been initialized. You must ...
- C#反射机制(转自Binfire博客)
一:反射的定义 审查元数据并收集关于它的类型信息的能力.元数据(编译以后的最基本数据单元)就是一大堆的表,当编译程序集或者模块时,编译器会创建一个类定义表,一个字段定义表,和一个方法定义表等. Sys ...
- 实现简单的string类
摘要 实现了一个string类,包括基本的构造.赋值.判断.大小写等. String API Constructors string(); string(const char& ch); st ...
- php 按照字典序排序 微信卡券签名算法用到
代码 <?php $data=array("api_ticket"=>"IpK_1T69hDhZkLQTlwsAXzJqxGE_7RuU_tjnx8rWC9f ...