肤浅的聊聊 TiDB 扫表算子, 扫索引算子, 合取范式(CNF), 析取范式(DNF), skyline pruning
这一章主要涉及TiDB如下的源码:
1. 扫表算子怎样转换为扫索引算子;
2. 怎样把Selection算子的过滤条件化简, 转为区间扫描;
假设我们有一个表:
t1(
id int primary key not null auto_increment,
a int,
b int,
c varchar(),
index(a)
);
其中, id 是主键, a 是索引;
我们执行如下的 sql:
select a from t1 where a= or ( a> and (a> and a <) and a<);
这条 sql 的最终执行计划是这样的:
+---------------+--------+-----------+-----------------------------------------------------------------------+
| id | count | task | operator info |
+---------------+--------+-----------+-----------------------------------------------------------------------+
| IndexReader_6 | 260.00 | root | index:IndexScan_5 |
| └─IndexScan_5 | 260.00 | cop[tikv] | table:t1, index:a, range:[5,5], (6,8), keep order:false, stats:pseudo |
+---------------+--------+-----------+-----------------------------------------------------------------------+
这是一个索引扫描的执行计划, 索引扫描区间是 [5,5], (6,8);
我们转到源代码, 看这样的计划是怎样生成的;
这是解析 sql 之后最初生成的执行计划:
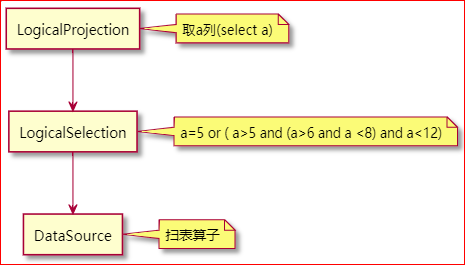
在调用 logicalOptimize 函数做逻辑优化之后, 执行计划变为下面这样:
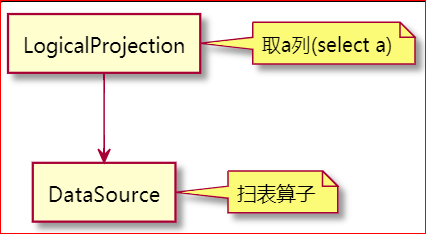
Selection算子哪儿去了?
Selection算子被下推到了 DataSource 算子中, 在 DataSource 的 pushedDownConds 中保存着下推的过滤算子, 是这样的:
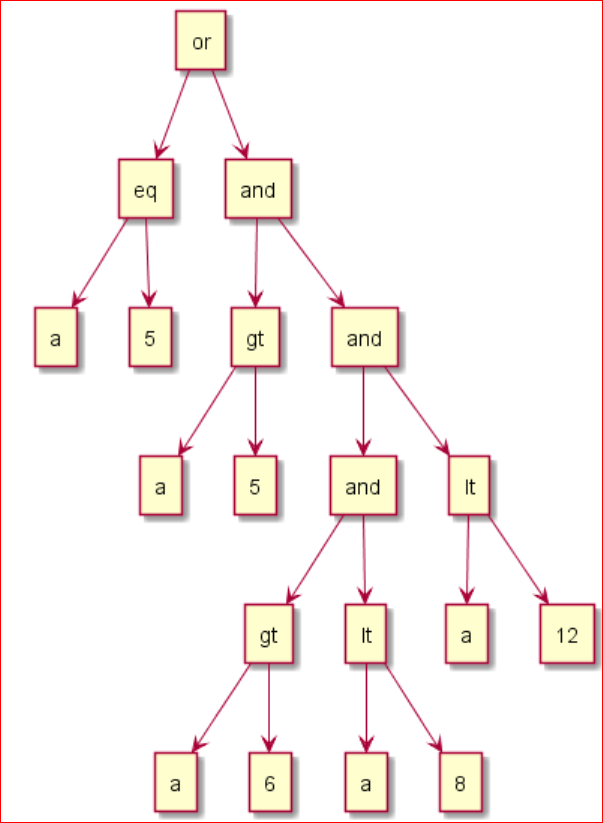
这样的一个递归的树状的过滤算子很难在索引扫描中使用, 因为索引底层是顺序排列的, 所以要将这颗树转为扫描区间;
在物理优化中, 会调用 DetachCondAndBuildRangeForIndex 来生成扫描区间, 这个函数会递归的调用如下 2 个函数:
detachDNFCondAndBuildRangeForIndex, 展开 析取范式(DNF), 生成扫描区间或合并扫描区间;
detachCNFCondAndBuildRangeForIndex, 展开 合取范式(CNF), 生成扫描区间或合并扫描区间;
上面的表达式树最终生成了这样的区间: [5,5], (6,8) --- "[" 是开区间, "(" 是闭区间, 递归被消除了;
接下来, 这个索引扫描会加入到 DataSource 的备选的访问表的方法中;
在 DataSource 的 possibleAccessPaths 里保存了访问表的可能的方案, 这里是 2 个方案:
1. 全表扫描, 用表达式树进行过滤: a=5 or ( a>5 and (a>6 and a <8) and a<12);
2. 扫索引 a 列, 执行区间扫描 [5,5], (6,8);
物理优化阶段, 会从算子树的根节点递归调用每个算子的 findBestTask 函数, DataSoure 算子会从 possibleAccessPaths 获取最优的执行计划;
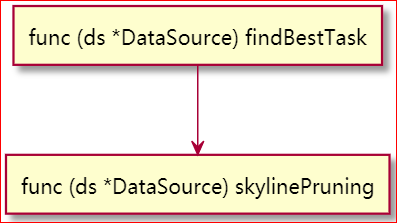
这里用到了 skyline pruning 算法, 从多个维度来判断哪个执行计划更优, 最后用索引扫描算子替换掉 DataSource 算子;
最终生成了这样的执行计划:

结束;
肤浅的聊聊 TiDB 扫表算子, 扫索引算子, 合取范式(CNF), 析取范式(DNF), skyline pruning的更多相关文章
- 肤浅的聊聊关联子查询,数据集连接,TiDB代码,关系代数,等等
本章涉及的内容是TiDB的计算层代码,就是我们编译完 TiDB 后在bin目录下生成的 tidb-server 的可执行文件,它是用 go 实现的,里面对 TiPD 和 TiKV实现了Mock,可以单 ...
- 简单聊聊TiDB中sql优化的一个规则---左连接消除(Left Out Join Elimination)
我们看看 TiDB 一段代码的实现 --- 左外连接(Left Out Join)的消除; select 的优化一般是这样的过程: 在逻辑执行计划的优化阶段, 会有很多关系代数的规则, 需要将逻辑执行 ...
- 隔行扫瞄/逐行扫瞄的介绍(Interlaced / Progressive)
隔行扫瞄/逐行扫瞄的介绍(Interlaced / Progressive) 本篇不是着重在理论说明, 而是实际验証结果的分享, 所以只简略解释何谓交错与非交错, 请参考如后. 交错扫瞄(隔行扫瞄 ...
- 关于数据库表中的索引及索引列的CRUD
-- 查询一个数据库表中的索引及索引列use [RuPengWangDB]GOSELECT indexname = a.name , tablename = c. name , indexcolu ...
- 无法重新组织表 "ty_wf_ex_local_process_info" 的索引 "idx_prc_act_id" (分区 1),因为已禁用页级锁定。
无法重新组织表 "ty_wf_ex_local_process_info" 的索引 "idx_prc_act_id" (分区 1),因为已禁用页级锁定. ALT ...
- Mysql数据库表排序规则不一致导致联表查询,索引不起作用问题
Mysql数据库表排序规则不一致导致联表查询,索引不起作用问题 表更描述: 将mysql数据库中的worktask表添加ishaspic字段. 具体操作:(1)数据库worktask表新添是否有图片字 ...
- SQL优化的四个方面,缓存,表结构,索引,SQL语句
一,缓存 数据库属于 IO 密集型的应用程序,其主要职责就是数据的管理及存储工作.而我们知道,从内存中读取一个数据库的时间是微秒级别,而从一块普通硬盘上读取一个IO是在毫秒级别,二者相差3个数量级.所 ...
- 单表扫描,MySQL索引选择不正确 并 详细解析OPTIMIZER_TRACE格式
单表扫描,MySQL索引选择不正确 并 详细解析OPTIMIZER_TRACE格式 一 表结构如下: 万行 CREATE TABLE t_audit_operate_log ( Fid b ...
- SQL Server 查看指定表上的索引
解决方案: sys.indexs; ---------------------------------------------------------------------------------- ...
随机推荐
- fwrite & fread 的使用
每一次切换文件操作模式必须调用fclose关闭文件. 如果直接切换操作模式,文件将损坏(出现乱码)或操作失败. 在调用了fclose时,作为参数的文件指针将被回收,必须再次定义,因此最好将功能封装. ...
- Nmap脚本使用
Nmap是主机扫描工具,他的图形化界面是Zenmap,分布式框架为Dnamp. Nmap可以完成以下任务: 主机探测 端口扫描 版本检测 系统检测 支持探测脚本的编写 Nmap在实际中应用场合如下: ...
- mysql中sum与if,case when 结合使用
1.sum与if结合使用 如图:数据表中,count_money 字段可为正,可为负.为正表示收入,负表示支出. 统计总收入,总支出. select sum(if(count_money > 0 ...
- UI单据字段值查看方式
1.单据界面右键属性,获取当前单据URL连接:http://172.16.168.12/U9/erp/display.aspx?lnk=SCM.INV.INV2020_10&sId=3017n ...
- 3.03定义常量之enum
[注:本程序验证是使用vs2013版] #include <stdio.h> #include <stdlib.h> #include <string.h> #pr ...
- Java初学心得(二)
数组概述 一,数组基本操作 ①一维数组的创建:数组元素类型[] 数组名字=new 数组类型[数组元素个数] 例:int []arr=new int[5];数组长度为5 ②初始化一维数组:第一种:int ...
- [jsp学习笔记]servelt get post
1.post提交数据是隐式的,get是通过在url里面传递的(可以看一下你浏览器的地址栏),用来传递一些不需要保密的数据. 2.用get时,传输数据的大小有限制 (注意不是参数的个数有限制),为2K: ...
- cocoaPods升级遇到的问题 升级ruby 升级cocoaPos
最近重复了一次,修复一些更改. 1.查询 rvm版本rvm -v 2.查询ruby版本ruby -v 3.查询 gem 版本gem -v 4.查询ruby 镜像gem sources -l 5.升级r ...
- Angular应用架构设计-3:Ngrx Store
这是有关Angular应用架构设计系列文章中的一篇,在这个系列当中,我会结合这近两年中对Angular.Ionic.甚至Vuejs等框架的使用经验,总结在应用设计和开发过程中遇到的问题.和总结的经验, ...
- Oracle 用户模式
在 Oracle 数据库中,为了便于管理用户所创建的数据库对象(数据表.索引.视图等),引入了模式的概念,这样某个用户所创建的数据库对象就都属于该用户模式. 一.模式与模式对象 模式是一个数据库对象的 ...