Linux内核链表——看这一篇文章就够了
本文从最基本的内核链表出发,引出初始化INIT_LIST_HEAD函数,然后介绍list_add,通过改变链表位置的问题引出list_for_each函数,然后为了获取容器结构地址,引出offsetof和container_of宏,并对内核链表设计原因作出了解释,一步步引导到list_for_each_entry,然后介绍list_del函数,通过在遍历时list_del链表的不安全行为,引出list_for_each_entry_safe函数,通过本文,我希望读者可以得到如下三个技能点:
1.能够熟练使用内核链表的相关宏和函数,并应用在项目中;
2.明白内核链表设计者们的意图,为什么要那样去设计链表的操作和提供那样的函数接口;
3.能够将内核链表移植到非GNU环境。
大多数人在学习数据结构的时候,链表都是第一个接触的内容,笔者也不列外,虽然自己实现过几种链表,但是在实际工作中,还是Linux内核的链表最为常用(同时笔者也建议大家使用内核链表,因为会了这个,其他的都会了),故总结一篇Linux内核链表的文章。
阅读本文之前,我假设你已经具备基本的链表编写经验。

内核链表的结构是个双向循环链表,只有指针域,数据域根据使用链表的人的具体需求而定。内核链表设计哲学:
既然链表不能包含万事万物,那么就让万事万物来包含链表。
假设以如下方式组织我们的数据结构:
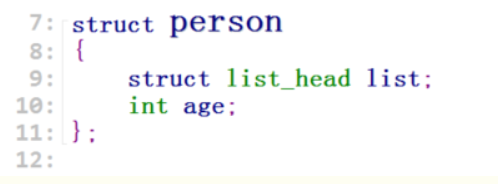
创建一个结构体,并将链表放在结构体第一个成员地址处(后面会分析不在首地址时的情况)。
#include <stdio.h>
#include <stdlib.h> #include "list.h" struct person
{
struct list_head list;
int age;
}; int main(int argc,char **argv)
{
int i;
struct person *p;
struct person person1;
struct list_head *pos; INIT_LIST_HEAD(&person1.list); for (i = ;i < ;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*;
list_add(&p->list,&person1.list);
} list_for_each(pos, &person1.list) {
printf("age = %d\n",((struct person *)pos)->age);
} return ;
}
我们先定义struct person person1;此时person1就是一个我们需要使用链表来链接的节点,使用链表之前,需要先对链表进行初始化,LIST_HEAD和INIT_LIST_HEAD都可以初始化一个链表,两者的区别是,前者只需要传入链表的名字,就可以初始化完毕了;而后者需要先定义出链表的实体,如前面的person1一样,然后将person1的地址传递给初始化函数即可完成链表的初始化。内核链表的初始化是非常简洁的,让前驱和后继都指向自己。
完成了初始化之后,我们可以像链表中增加节点,先以头插法为例:


list_add函数,可以在链中增加节点,改函数为头插法,即每次插入的节点都位于上一个节点之前,比如上一个节点是head->1->head,本次使用头插法插入之后,链表结构变成了 head->2->1->head。也就是使用list_add头插法,最后第一个插入的节点,将是链表结构中的第一个节点。
list_add函数的实现步骤也非常简洁,一定要自己去推演一下这个过程,O(1)的时间复杂度,就4条指针操作,不自己去推演一下这个过程你会少很多心得体会,尤其是在接触过其他的还要考虑头部和尾部特殊情况的链表之后,更会觉得内核链表设计简洁的妙处。list_add函数的第一个参数就是要增加到头结点链表中的数据结构,第二个参数就是头结点,本例中为&person1.list。
本例中增加5个节点,头结点的数据域不重要,可以根据需要利用头结点的数据域,一般而言,头结点数据域不使用,在使用头结点数据域的情况下,一般也仅仅记录链表的长度信息,这个在后面我们可以自己实现一下。
在增加了5个节点之后,我们需要遍历链表,访问其数据域的内容,此时,我们先使用list_for_each函数,遍历链表。

该函数就是遍历链表,直到出现pos == head时,循环链表就编译完毕了。对于其中的prefetch(pos->next)函数,如果你是在GNU中使用gcc进行程序开发,可以不做更改,直接使用上面的函数即可;但如果你想把其移植到Windows环境中进行使用,可以直接将prefetch(pos->next)该条语句删除即可,因为prefetch函数它通过对数据手工预取的方法,减少了读取延迟,从而提高了性能,也就是prefetch是gcc用来提高效率的函数,如果要移植到非GNU环境,可以换成相应环境的预取函数或者直接删除也可,它并不影响链表的功能。
list_for_each的第一个参数pos,代表位置,需要是struct list_head * 类型,它其实相当于临时变量,在本例中,定义了一个指针pos, struct list_head *pos;用其来遍历链表。
可以遍历链表之后,那么就需要对数据进行打印了。

本例中的输出,将pos强制换成struct person *类型,然后访问age元素,得到程序输出入下:
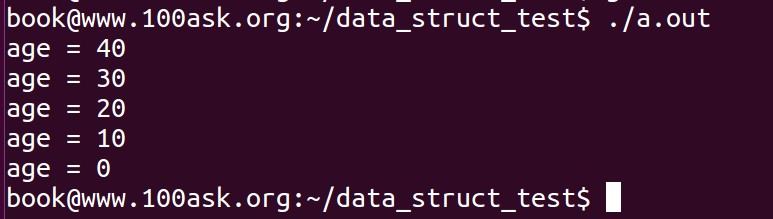
可以发现,list_add头插法,果然是最后插入的先打印,最先插入的最后打印。
其次,为什么笔者要使用printf("age = %d\n",((struct person *)pos)->age);这样的强制类型转换来打印呢?能这样打印的原理是什么呢?
现在回到我们的数据结构:
struct person
{
struct list_head list;
int age;
};
由于我们将链表放在结构体的首地址处,那么此时链表list的地址,和struct person 的地址是一致的,所以通过pos的地址,将其强制转换成struct person *就可以访问age元素了。
前面说到,内核链表是有头结点的,一般而言头结点的数据域我们不使用,但也有使用头结点数据域记录链表长度的实现方法。头结点其实不是必需的,但作为学习,我们可以实现一下,了解其过程:
#include <stdio.h>
#include <stdlib.h> #include "list.h" struct person_head
{
struct list_head list;
int len;
}; struct person
{
struct list_head list;
int age;
}; int main(int argc,char **argv)
{
int i;
struct person *p;
struct person_head head;
struct list_head *pos; INIT_LIST_HEAD(&head.list);
head.len=; for (i = ;i < ;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*;
list_add(&p->list,&head.list);
} list_for_each(pos, &head.list) {
printf("age = %d\n",((struct person *)pos)->age);
head.len++;
}
printf("list len =%d\n",head.len); return ;
}
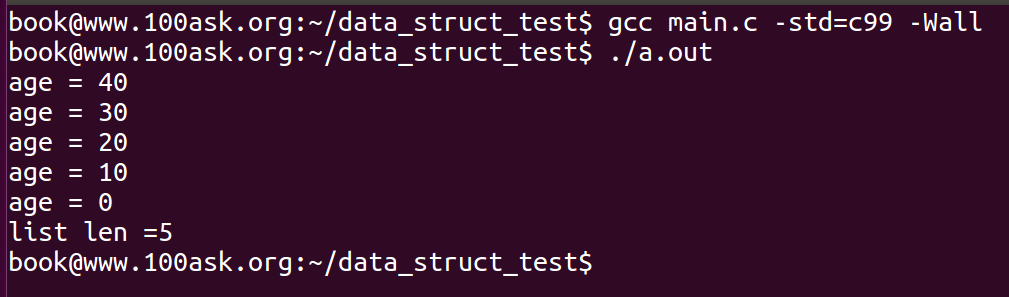
本例中定义了person_head结构,其数据域保存链表的长度,由于list_for_each会遍历链表,本例仅作为功能说明的实现,记录了链表的长度信息,并打印了链表长度。如果实际开发中需要记录链表的长度或者其他信息,应该封装成相应的函数,同时,增加节点的时候,增加len的计数,删除节点的时候,减少len的计数。
在笔者最早接触到将链表放在结构体第一个成员地址处时,觉得Linux内核链表后面的container_of,offsetof宏为什么如此多余,因为按照上面的方法,根本不再需要container_of,offsetof这样的宏了,甚至当时还觉得内核为什么这么笨,还不更新代码(当然,这也是当时听了某个老师的课说现代的链表已经发展成为上面例子的情况,而内核链表处于不断发展的过程,并没有使用这样最新的方式)。所以笔者在学生时代时学到这里就收手没有再继续下去了,因为我当时认为按照这样的方法就够用了。可是,当我进入到企业工作之后,我发现并不是这样的,因为没有人可以保证链表可以放在结构体的第一个成员地址处,哪怕能够保证,那么在复杂数据结构中,有多个链表怎么办?哪怕你能够保证有一个链表位于结构体的首地址处,那其他的链表怎么办呢?直到那时,我才发现Linux内核那帮设计者们并不笨,而是自己当时的知识面太窄并且项目经验不足(这样同样证明了一个授课老师的知识水平,对学生的影响是很大的,当然,瑕不掩瑜,我内心还是非常感谢当初那位老师的,只是,我需要更强大的力量了^_^)。内核链表设计者们,考虑到了很多情况下,我们根本不能保证每个链表都处于结构体的首地址,所以,也就出现了container_of,offsetof这两个广为人知的宏。
试想,如果将我上面代码中的person结构体位置更改一下:

将链表不放置在结构体的首地址处,那么前面的代码将不能正常工作了:

因为此时强制类型转换得到地址不再是struct person结构的首地址,进行->age操作时,指针偏移不正确。
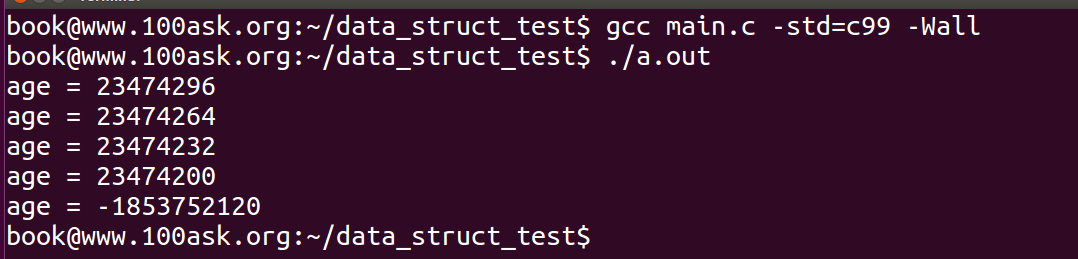
果然,运行之后代码得到的age值不正确,为了解决这一问题,内核链表的开发者们设计出了两个宏:

我们先来分析offsetof宏,其语法也是非常简洁和简单的,该宏得到的是TYPE(结构体)类型中成员MEMBER相对于结构体的偏移地址。但是,其中有一个知识点需要注意:为什么((TYPE *)0)->MEMBER这样的代码不会出现段错误,我们都知道,p->next,等价于(*p).next;那么((TYPE *)0)->MEMBER,不是应该等价于(*(TYPE *)0).MEMBER吗?这样不就出现了对0地址的解引用操作吗?为什么内核使用这样的代码却没有问题呢?
为了解释这个问题,我们先做一个测试:


没有问题,现在我们把for_test的参数改为NULL,看看会不会出现段错误:

注意,此时传递给for_test的参数为NULL,同时为了显示偏移数,我将地址以%u打印,程序输出如下:
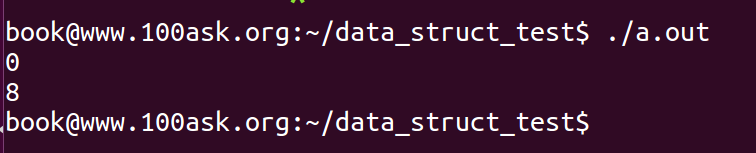
你发现了什么?对,程序并没有奔溃,而且得到了age和list在struct person中偏移量,一个为0,一个为8(笔者的Linux是64bit的)。为什么传递NULL空指针进去,并没有发生错误,难道是我们之前学习的C语言有问题?
没有发生错误,是因为在ABI规范中,编译器处理结构体地址偏移时,使用的是如下方式:

在编译阶段,编译器就会将结构体的地址以如上方式组织,也就是说,编译器去取得结构体某个成员的地址,就是使用的偏移量,所以,即使传入NULL,也不会出现错误,也就是说,内核的offsetof宏不会有任何问题。

那么offsetof之所以将0强制类型转换,就是为了得到TYPE结构体中MEMBER的偏移量,最后将偏移量强制类型转换为size_t,这就是offsetof。那么为什么要这样求偏移呢?前面说到了,想在结构体中得到链表的地址,怎么得到地址呢?如果我们知道了链表和结构体的偏移量,那么即使链表不位于结构体首地址处,我们也可以使用链表了啊。
下面,我们对container_of宏做解析:

其中typeof是GNU中获取变量类型的关键字,如果要将其移植到Windows中,可以再添加一个参数解决,有兴趣的可自行实验。
现在我们来看,第一句,其实第一句话没有也完全不影响该宏的功能,但是内核链表设计者们为什么要增加这个一个赋值的步骤呢?这是因为宏没有参数检查的功能,增加这个const typeof( ((type *)0)->member ) *__mptr = (ptr)赋值语句之后,如果类型不匹配,会有警告,所以说,内核设计者们不会把没用的东西放在上面。
现在我们来说一下该宏的三个参数,ptr,是指向member的指针,type,是容器结构体的类型,member就是结构体中的成员。用__mptr强制转换成char *类型 减去member在type中的偏移量,得到结果就是容器type结构体的地址,这也就是该宏的作用。你可能会想,type的地址不是直接取地址得到吗?为什么还要这么麻烦使用这个宏呢?
要解答这个问题,我们先来看一下这两个宏的应用场景。
前面说到在链表不放在结构体首地址时的问题,现在我们使用内核链表的list_entry宏来解决这个问题:

list_entry宏其实就是container_of。回忆前面我们的问题:

前面说到这里获取age是错误的,就是因为pos的地址不位于结构体首地址了,试想,如果我们能够通过将pos指针传递给某个宏或者函数,该函数或者宏能够通过pos返回包含pos容器这个结构体的地址,那么我们不就可以正常访问age了吗。很显然, container_of宏,就是这个作用啊,在内核中,将其又封装成了 list_entry宏,那么我们改进前面的代码:
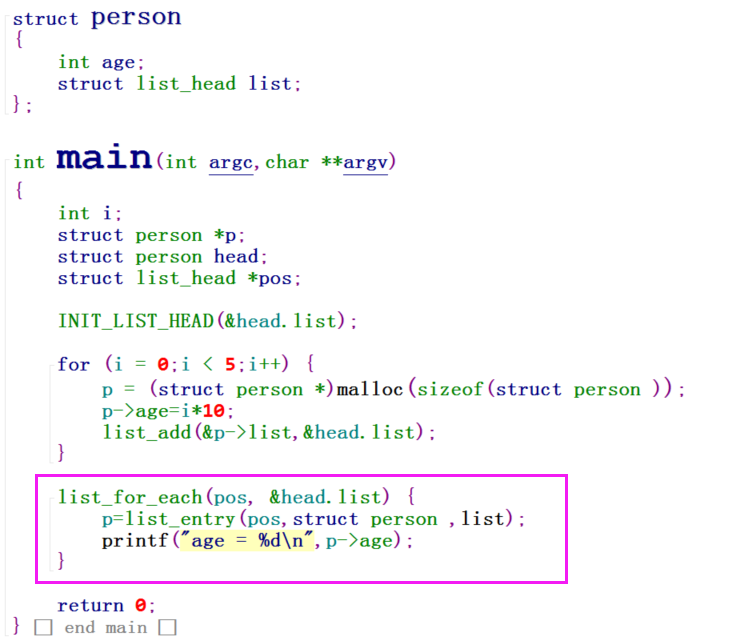
现在运行之后,即可以得到正确的结果了。

细心的读者可能发现了,为什么之前我使用gcc编译时都加上了-std=c99,但是上图中并没有使用c99标准,这也是需要注意的,此时使用c99标准进行编译或报错,至于出错原因:
/* 在编译时加上-std=c99,使用c99标准,对内核链表进行编译,会报语法错误,那是因为c99并不支持某些gcc的语法特性,如果想在GNU中启用c99标准,可以使用-std=gnu99,使用这个选项之后,会对gnu语法进行特殊处理,并使用c99标准 */
现在我们对内核链表做分析:
使用list_entry之后,我们可以得到容器结构体的地址,所以自然可以对结构体中的age元素进行操作了。前面说到,容器结构的地址,我们直接使用取地址符&不就行了吗,为什么还要使用这个复杂的宏list_entry去取地址呢?结合上面的应用场景,你想想,此时你能容易取到容器结构体的地址吗?显然,在链表中,尤其是在内核链表这种没有数据域的链表结构中,获取链表的地址是容易的,但是获取包含链表容器结构的地址需要额外的存储操作,所以内核链表的设计者们设计出的list_entry宏,可谓精妙。
在上面的代码中,我们使用:

这样的循环遍历链表,获取容器地址,取出相应结构体的age元素,内核链表设计者早已考虑到了这一点,所以为我们封装了另一个宏:list_for_each_entry

list_for_each_entry,通过其名字我们也能猜测其功能,list_for_each是遍历链表,增加entry后缀,表示遍历的时候,还要获取entry(条目),即获取链表容器结构的地址。该宏中的pos类型为容器结构类型的指针,这与前面list_for_each中的使用的类型不再相同,不过这也是情理之中的事,毕竟现在的pos,我要使用该指针去访问数据域的成员age了;head是你使用INIT_LIST_HEAD初始化的那个对象,即头指针,注意,不是头结点;member就是容器结构中的链表元素对象。使用该宏替代前面的方法:

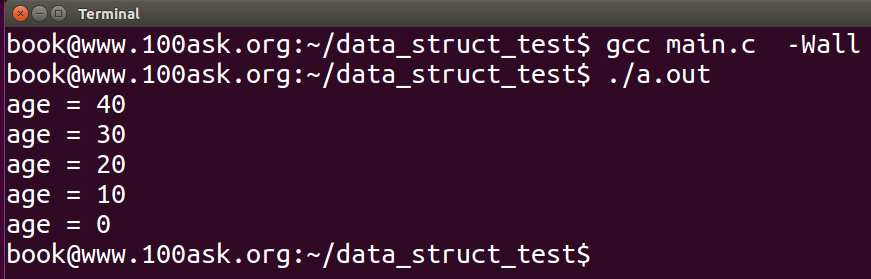
运行结果如下:
在此之前,我们都没有使用删除链表的操作,现在我们来看一下删除链表的内核函数list_del:


#include <stdio.h>
#include <stdlib.h> #include "list.h" struct person
{
int age;
struct list_head list;
}; int main(int argc,char **argv)
{
int i;
struct person *p;
struct person head;
struct person *pos; INIT_LIST_HEAD(&head.list); for (i = ;i < ;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*;
list_add(&p->list,&head.list);
} list_for_each_entry(pos,&head.list,list) {
if (pos->age == ) {
list_del(&pos->list);
break;
}
} list_for_each_entry(pos,&head.list,list) {
printf("age = %d\n",pos->age);
}
return ;
}
链表删除之后,entry的前驱和后继会分别指向LIST_POISON1和LIST_POISON2,这个是内核设置的一个区域,但是在本例中将其置为了NULL。运行结果如下:
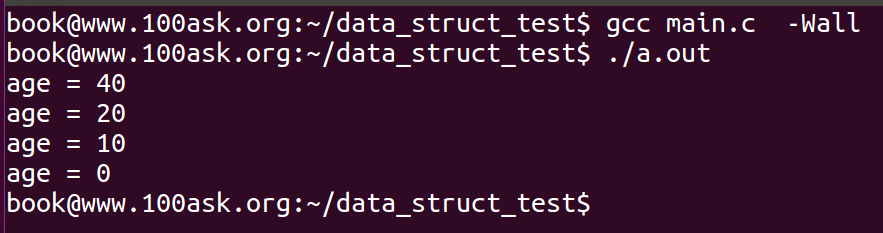
可以发现,正确地删除了相应的链表,但是注意了,如果在下面代码中不使用break;会发生异常。


为什么会这样呢?那是因为list_for_each_entry的实现方式并不是安全的,如果想要在遍历链表的时候执行删除链表的操作,需要对list_for_each_entry进行改进。显然,内核链表设计者们早已给我们考虑到了这一情况,所以内核又提供了一个宏:list_for_each_entry_safe

使用这个宏,可以在遍历链表时安全地执行删除操作,其原理就是先把后一个节点取出来使用n作为缓存,这样在还没删除节点时,就得到了要删除节点的笑一个节点的地址,从而避免了程序出错。
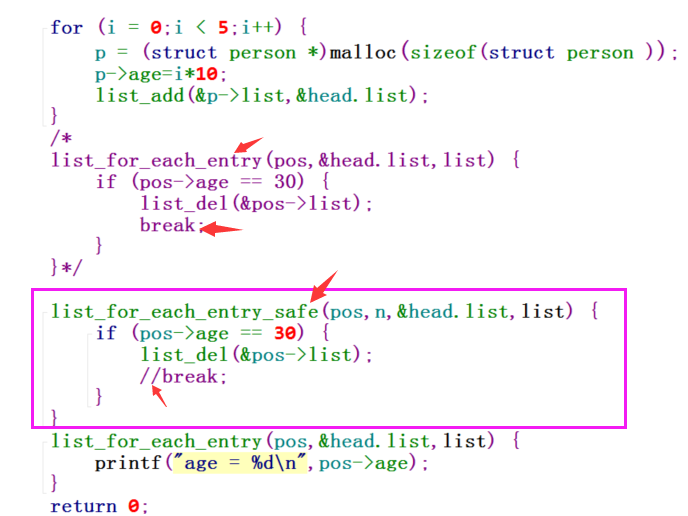
使用list_for_each_entry_safe宏,它使用了一个中间变量缓存的方法,实现更为安全的变量链表方法,其执行效果如下:

对于内核链表的宏和函数而言,其语法都是非常简洁和简单的,就不再具体分析每一个语句的作用了,我相信读者也能轻松地阅读明白这些代码,在笔者之前的学习中,就是缺少一个练习使用这些链表的过程,所以一定要自己去写一个程序推演一下整个过程。
list_del让删除的节点前驱和后继指向LIST_POISON1和LIST_POISON2的位置,本例中为NULL,内核同时提供了:
list_del_init

根据业务需要,可以自行选择适合自己的函数。
现在,我再来说另一种插入方式:尾插法,如果原来是head->1->head,尾插法一个节点之后变成了head->1->2->head。
内核提供的函数接口为:list_add_tail

我们将前面代码的list_add改为list_add_tail之后,得到:
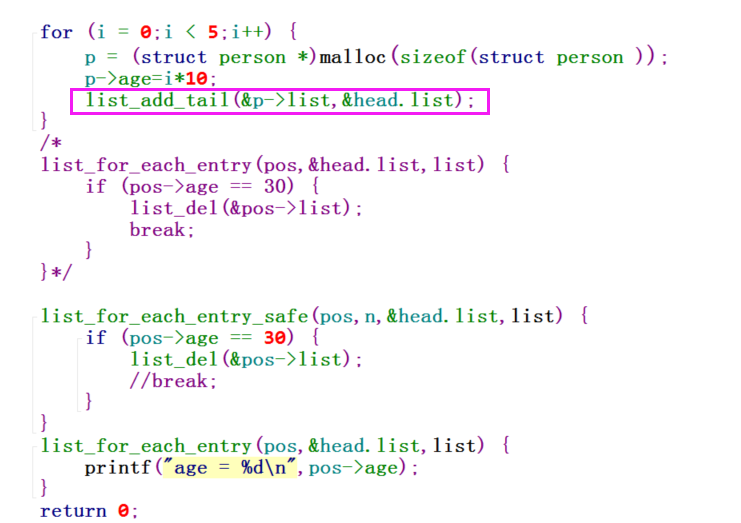
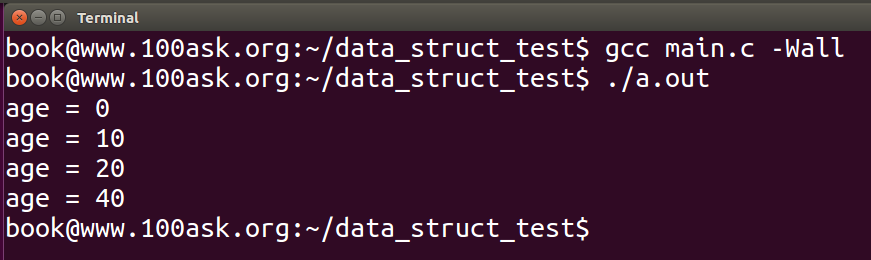
对于多核系统上,内核还提供了list_add_rcu和list_add_tail_rcu等函数,其具体实现机制(主要是内存屏障相关的)需要根据cpu而定。
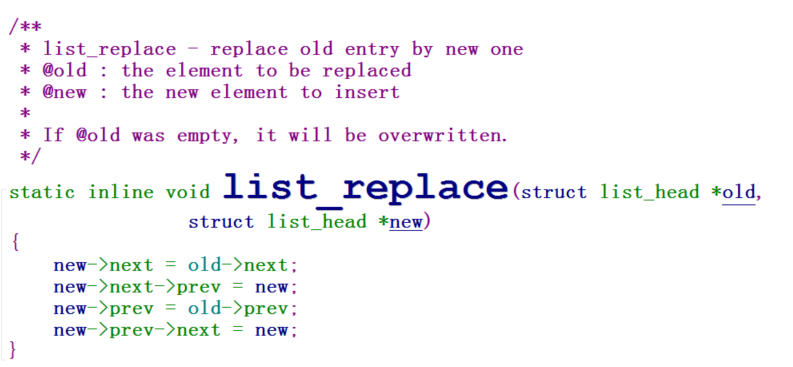
下面我们介绍:list_replace,通过其名字我们就能知道,该函数是替换链表的:
#include <stdio.h>
#include <stdlib.h> #include "list.h" struct person
{
int age;
struct list_head list;
}; int main(int argc,char **argv)
{
int i;
struct person *p;
struct person head;
struct person *pos,*n;
struct person new_obj={.age=}; INIT_LIST_HEAD(&head.list); for (i = ;i < ;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*;
list_add_tail(&p->list,&head.list);
}
/*
list_for_each_entry(pos,&head.list,list) {
if (pos->age == 30) {
list_del(&pos->list);
break;
}
}*/ list_for_each_entry_safe(pos,n,&head.list,list) {
if (pos->age == ) {
//list_del(&pos->list);
list_replace(&pos->list,&new_obj.list);
//break;
}
}
list_for_each_entry(pos,&head.list,list) {
printf("age = %d\n",pos->age);
}
return ;
}

由于list_replace没有将old的前驱和后继断开,所以内核又提供了:list_replace_init

这样,替换之后会将old重新初始化,使其前驱和后继指向自身。显然我们通常应该使用list_replace_init。
当项目中另外一个地方处理完成一个同类型的节点数据时,可以直接使用list_replace_init替换想要处理的节点,这样可以不再做拷贝操作。
内核链表还提供给我们:list_move

有了前面的知识累积,我们可以和轻松地明白,list_move就是删除list指针所处的容器结构节点,然后将其重新以头插法添加到另一个头结点中去,head可以是该链表自身,也可以是其他链表的头指针。
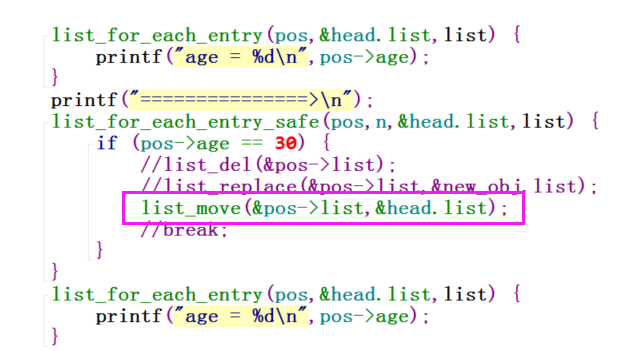
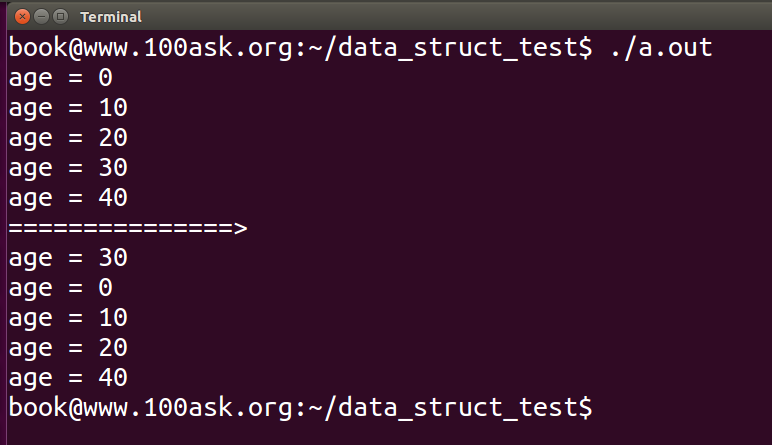
既然有头插法的list_move,那么也同样有尾插法的list_move_tail:

将测试函数改为:

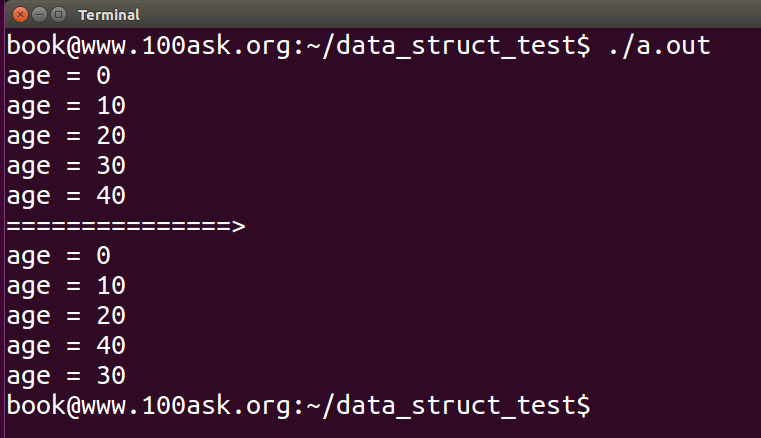
注意,在这里lis_move和list_move_tail都有删除操作,但是这里却可以不使用list_for_each_entry_safe而直接使用list_for_each_entry,想想这是为什么呢?
这是因为move函数,后面有一个添加链表的操作,将删除的节点前驱后继的LIST_POISON1和LIST_POISON2(本例中为NULL),重新赋值了。
值得注意的是,如果链表数据域中的元素都相等,使用list_for_each_entry_safe反而会无限循环,list_for_each_entry却能正常工作。但是,在通常的应用场景下,数据域的判断条件不会是全部相同链表,例如在自己使用链表实现的线程中,常用线程名字作为move的条件判断,而线程名字肯定不应该是相同的。所以,具体的内核链表API,需要根据自己的应用场景选择。list_for_each_entry_safe是缓存了下一个节点的地址,list_for_each_entry是无缓存的,挨个遍历,所以在删除节点的时候,list_for_each_entry需要注意,如果没有将删除节点的前驱后继处理好,那么将引发问题,而list_for_each_entry_safe通常不用关心,但是在你使用的条件判断进行move操作时,不应该使用各个节点可能相同的条件。
有list_for_each_entry往后依次遍历,那么也有list_for_each_entry_reverse往前依次遍历:
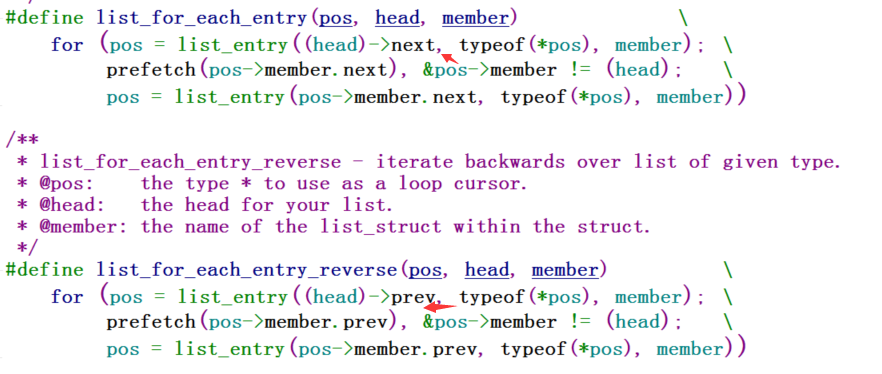
测试代码如下:
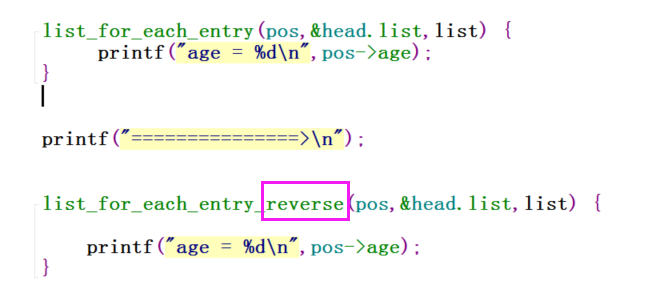
运行结果,一个往后遍历,一个往前遍历:
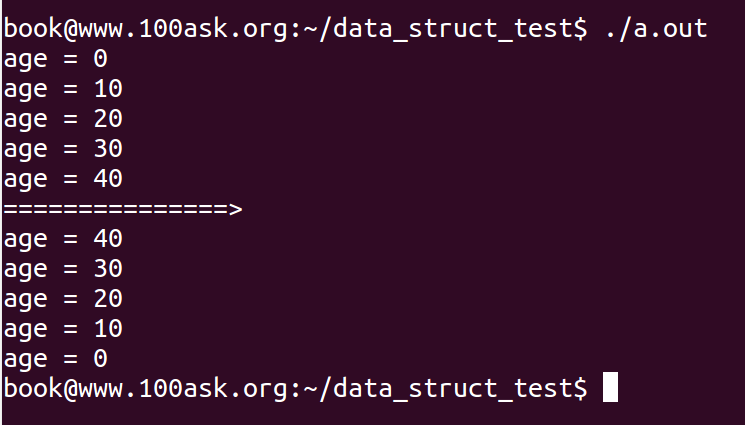
同样,有安全的往后遍历:list_for_each_entry_safe,那么也有安全的往前遍历:list_for_each_entry_safe_reverse
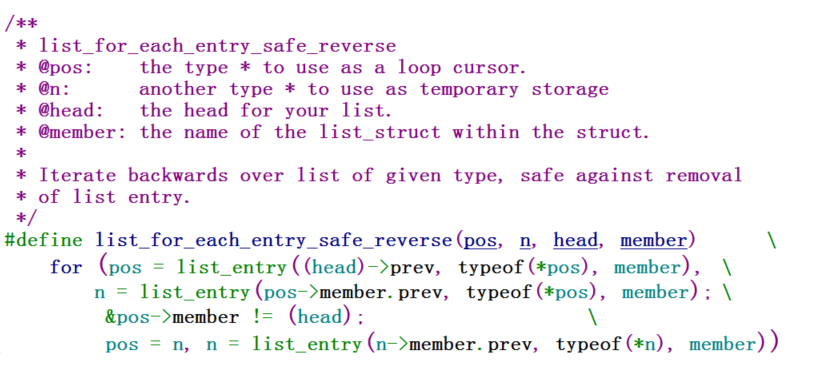
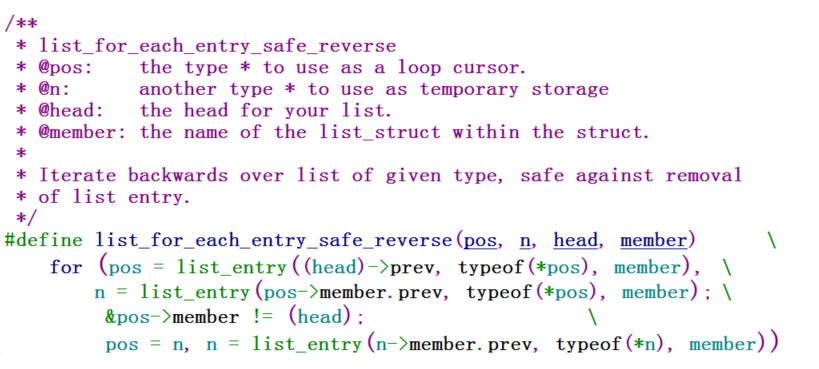
测试代码:

运行结果和前面的一致。
另一方面,内核链表还提供了得到第一个条目的宏:

还提供了判断链表是否是最后一个或者链表是否为空的函数

对于将GNU上的链表移植到Windows环境,需要注意的是,将预取指函数删除,或者换成你所使用的环境中可以达到相同效果的指令或函数,还有就是,typeof是gcc的特殊关键字,在Windows环境下,可以通过将相应的内核链表宏增加一个参数,该参数用来表示类型。
最后说两句:
动手实践一次,比眼看100次更有收获。
talk is cheap,show me the code.
Linux内核链表——看这一篇文章就够了的更多相关文章
- 2300+字!在不同系统上安装Docker!看这一篇文章就够了
辰哥准备出一期在Docker跑Python项目的技术文,比如在Docker跑Django或者Flask的网站.跑爬虫程序等等. 在Docker跑Python程序的时候不会太过于细去讲解Docker的基 ...
- .Net vs .Net Core,我改如何选择?看这一篇文章就够了
前言 .Net目前支持构建服务器端应用程序的两种实现主要有两种,.NET Framework和.NET Core.两者共享许多相同的组件,并且您可以在两者之间共享代码.但是,两者之间存在根本差异,在我 ...
- 想学会SOLID原则,看这一篇文章就够了!
背景 在我们日常工作中,代码写着写着就出现下列的一些臭味.但是还好我们有SOLID这把'尺子', 可以拿着它不断去衡量我们写的代码,除去代码臭味.这就是我们要学习SOLID原则的原因所在. 设计的臭味 ...
- Linux 内核 链表 的简单模拟(2)
接上一篇Linux 内核 链表 的简单模拟(1) 第五章:Linux内核链表的遍历 /** * list_for_each - iterate over a list * @pos: the & ...
- Linux 内核 链表 的简单模拟(1)
第零章:扯扯淡 出一个有意思的题目:用一个宏定义FIND求一个结构体struct里某个变量相对struc的编移量,如 struct student { int a; //FIND(struct stu ...
- linux内核链表的使用
linux内核链表:链表通常包括两个域:数据域和指针域.struct list_head{struct list_head *next,*prev;};include/linux/list.h中实现了 ...
- Linux 内核链表的使用及深入分析【转】
转自:http://blog.csdn.net/BoArmy/article/details/8652776 1.内核链表和普通链表的区别 内核链表是一个双向链表,但是与普通的双向链表又有所区别.内核 ...
- 链表的艺术——Linux内核链表分析
引言: 链表是数据结构中的重要成员之中的一个.因为其结构简单且动态插入.删除节点用时少的长处,链表在开发中的应用场景许多.仅次于数组(越简单应用越广). 可是.正如其长处一样,链表的缺点也是显而易见的 ...
- Linux 内核链表 list.h 的使用
Linux 内核链表 list.h 的使用 C 语言本身并不自带集合(Collection)工具,当我们需要把结构体(struct)实例串联起来时,就需要在结构体内声明指向下一实例的指针,构成所谓的& ...
随机推荐
- Springboot 整合Activiti流程设计器 完成一个简单的请假流程
目录 1.前言 2.准备 3.下载解压 4.开始整合 mysql + activiti + thymeleaf 2.配置文件 3.复制文件 4.加入控制器 5.修改配置文件 6.剔除启动类里面的安全校 ...
- LVS负载均衡部署
一.lvs-nat模式 1.1.环境介绍 本实验用三台虚拟机完成,一台虚拟机模拟lvs调度器,两块网卡,一块模拟公网一块模拟私网,公网地址192.168.0.201/24,私网地址192.168.4. ...
- 配置nginx的systemctl命令
启动nginx的命令为 /usr/local/nginx/sbin/nginx 停止nginx的命令为 /usr/local/nginx/sbin/nginx -s stop 重启ng ...
- MyBatis-plus的入门学习
MyBatis优势: Sql简单语句可以自由控制,更灵活,性能更高.. sql与代码分离,易于阅读和维护 提供xml标签,支持编写动态sql语句. 劣势: 简单crud操作还是写SQL 语句 xml中 ...
- How would you differentiate JDK, JRE, JVM, and JIT?
Q5. How would you differentiate JDK, JRE, JVM, and JIT?A5. There is no better way to get the big pic ...
- IDEA创建Mybatis的配置文件---sqlMapConfig.xml
Mybatis的配置文件不像Spring的配置文件,在Maven当中添加过依赖之后就可以在下面这个地方打开,需要自己去手动去编写配置文件,但是自己编写的话会记不住要引入的DTD,所以就需要自己创建一个 ...
- Apache是什么?
Apache HTTP Server(简称Apache)是Apache软件基金会的一个开放源码的网页服务器,可以在大多数计算机操作系统中运行, 由于其多平台和安全性被广泛使用,是最流行的Web服务器端 ...
- 多目标跟踪MOT综述
https://blog.csdn.net/u012435142/article/details/85255005 多目标跟踪MOT 1评价指标 https://www.cnblogs.com/YiX ...
- cc2530的第二次实验,用按键控制流水灯
按键控制流水灯 具体想要实现按一下按键,然后单片机的三个灯会以流水灯的形式都亮一遍 实验相关寄存器 实验相关电路 宏定义 #define uint unsigned int #define uchar ...
- WinDbg常用命令系列---!runaway
简介 !runaway扩展显示有关每个线程使用的时间的信息. 使用形式 !runaway [Flags] 参数 Flags指定要显示的信息类型. 标志可以是以下位的任意组合. 默认值为 0x1.位 0 ...