超详细的Hadoop2配置详解
1. 集群环境
Master 192.168.2.100
Slave1 192.168.2.101
Slave2 192.168.2.102
2. 下载安装包
Master
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.8.4/hadoop-2.8.4.tar.gz
tar zxvf hadoop-2.8.4.tar.gz
3. 修改Hadoop配置文件
Master
cd hadoop-2.8.4/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim slaves
slave1
slave2
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.8.4/tmp</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.8.4/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.8.4/dfs/data</value>
</property>
<property>
<name>dfs.repliction</name>
<value>3</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
#创建临时目录和文件目录
mkdir /usr/local/hadoop-2.8.4/tmp
mkdir -p /usr/local/hadoop-2.8.4/dfs/name
mkdir -p /usr/local/hadoop-2.8.4/dfs/data
4. 配置环境变量
Master、Slave1、Slave2
vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.8.2
export PATH=$PATH:$HADOOP_HOME/bin
刷新环境变量
source ~/.bashrc
5. 拷贝安装包
Master
scp -r /usr/local/src/hadoop-2.8.4 root@slave1:/usr/local/src/hadoop-2.8.4
scp -r /usr/local/src/hadoop-2.8.4 root@slave2:/usr/local/src/hadoop-2.8.4
6. 启动集群
Master
初始化Namenode
hadoop namenode -format
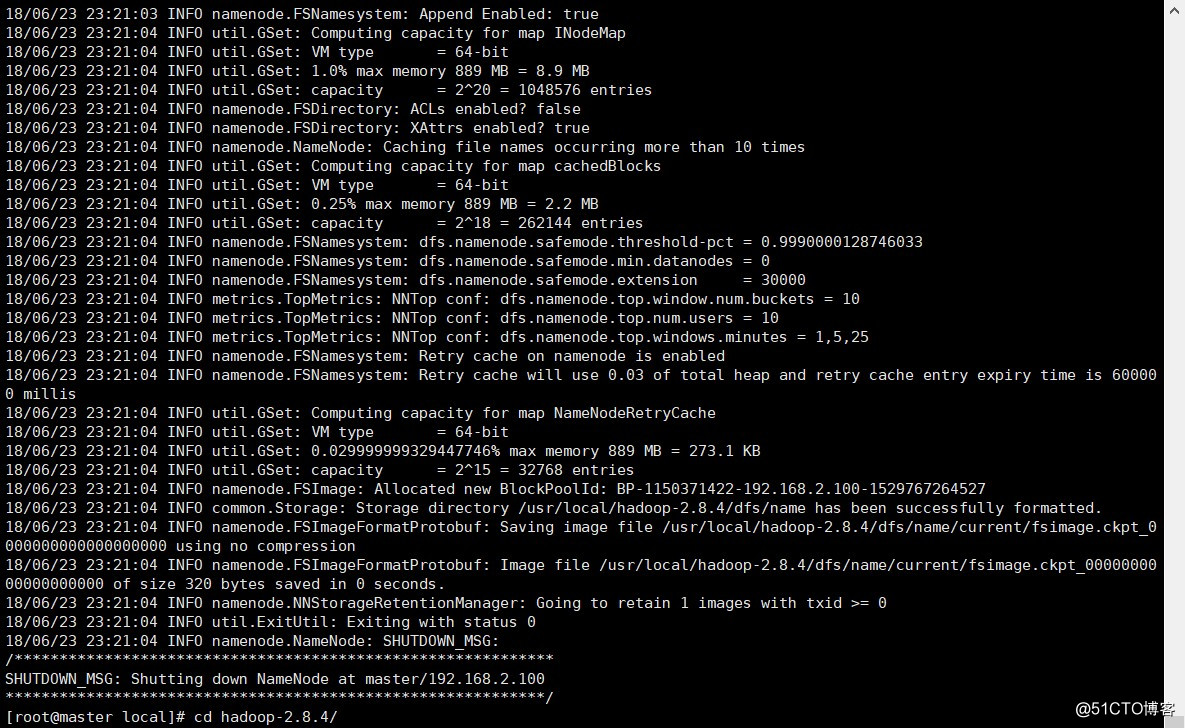
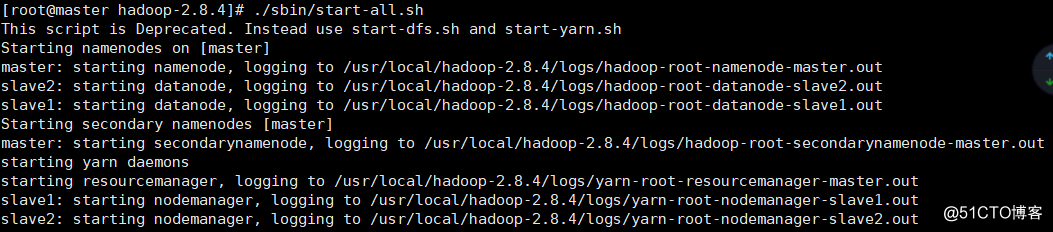
启动集群
./sbin/start-all.sh
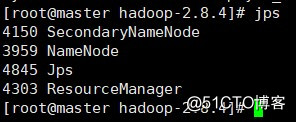
6. 集群状态
jps
Master
Slave1
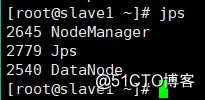
Slave2
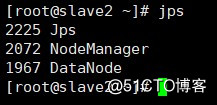
7.监控网页
http://master:8088
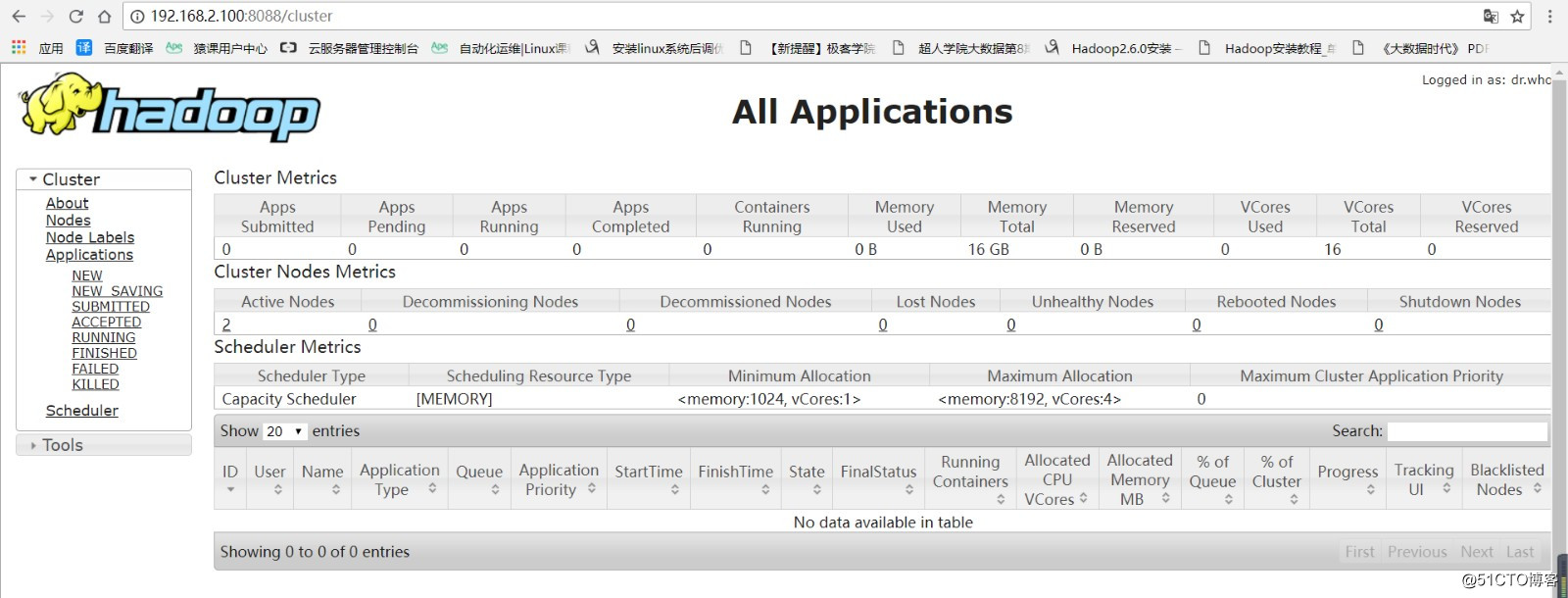
测试

关闭集群
./sbin/hadoop stop-all.sh
超详细的Hadoop2配置详解的更多相关文章
- Oracle数据库的安装 【超详细的文图详解】
Oracle简介Oracle Database,又名Oracle RDBMS,或简称Oracle.是甲骨文公司的一款关系数据库管理系统.它是在数据库领域一直处于领先地位的产品.可以说Oracle数据库 ...
- Hadoop2配置详解
配置文件 hadoop的配置是由两种重要类型的配置文件进行驱动的: 默认是只读的配置: core-default.xml, hdfs-default.xml, yarn-default.xml and ...
- 详细的ifcfg-eth0配置详解
通过查资料与工作中的进行一下总结: DEVICE="eth1" 网卡名称NM_CONTROLLED="yes" network mamager的参数 ,是否 ...
- keepalived的配置详解(非常详细)
keepalived的配置详解(非常详细) 2017-01-22 15:24 2997人阅读 评论(0) 收藏 举报 分类: 运维学习(25) 转载自:http://blog.csdn.net ...
- apache 虚拟主机详细配置:http.conf配置详解
apache 虚拟主机详细配置:http.conf配置详解 Apache的配置文件http.conf参数含义详解 Apache的配置由httpd.conf文件配置,因此下面的配置指令都是在httpd. ...
- Mysql系列五:数据库分库分表中间件mycat的安装和mycat配置详解
一.mycat的安装 环境准备:准备一台虚拟机192.168.152.128 1. 下载mycat cd /softwarewget http:-linux.tar.gz 2. 解压mycat tar ...
- Apache2 httpd.conf 配置详解
Apache2 httpd.conf 配置详解 <第一部分> 常用配置指令说明 1. ServerRoot:服务器的基础目录,一般来说它将包含conf/和logs/子目录,其它配置文件的相 ...
- Web.xml配置详解(转)
Web.xml配置详解 Posted on 2010-09-02 14:09 chinaifne 阅读(295105) 评论(16) 编辑 收藏 1 定义头和根元素 部署描述符文件就像所有XML文件一 ...
- Tomcat中的Server.xml配置详解
Tomcat中的Server.xml配置详解 Tomcat Server的结构图如下: 该文件描述了如何启动Tomcat Server <Server> <Listener /> ...
随机推荐
- PHP防止刷微信红包方法
PHP防止刷微信红包方法1 输入验证码2授权登陆后 领取红包记录下 openid ip 第二次用openid或者ip(ip)连接同一个路由器是一样的 所以用ip 判断最好是判断有没有6个以上 判断有没 ...
- linux设置root密码&进入不了root
刚装的linux无法使用root需要初始化密码 1.设置密码 sudo passwd root 点击回车,然后输入两次你想设置的密码,比如123456 2.切换用户 su root 再输入你刚才设置的 ...
- 将python工程部署到新服务器(对virtualenv工具进行环境迁移)
将python工程部署到新服务器(对virtualenv工具进行环境迁移) # 从开发的电脑上导出 pip list 到 requirements.txt 文件pip freeze > requ ...
- OpenLayers加载谷歌地球离线瓦片地图
本文使用OpenLayers最新版本V5.3.0演示:如何使用OpenLayer加载谷歌地球离线瓦片地图.OpenLayers 5.3.0下载地址为:https://github.com/openla ...
- Nginx静态服务配置---详解root和alias指令
Nginx静态服务配置---详解root和alias指令 静态文件 Nginx以其高性能著称,常用与做前端反向代理服务器.同时nginx也是一个高性能的静态文件服务器.通常都会把应用的静态文件使用ng ...
- python之数据解构和算法进阶
1.解压赋值多个变量 采用解构的方法.可迭代对象才可以,变量数量与元素个数要一一对应,或者采用*万能接收. 2.解压可迭代对象赋值多个变量 如果一个可迭代对象的元素个数超过变量个数时,会抛出一个 Va ...
- MacBook Pro配置汇编开发环境
配置开发环境 方法一: 打开命令行,输入指令which nasm查看nasm的安装路径,Mac系统默认安装了nasm.一般默认返回的路径是/usr/bin/nasm 接着输入指令alias nasm= ...
- [UOJ #393]【NOI2018】归程
题目大意:有一张$n$个点$m$条边的图,每个边有两个属性$a_i,b_i$.有$Q$个询问,每个询问给出$v,p$,表示所有边中$b_i\leqslant p$的边会被标记,在点$v$,可以通过不被 ...
- windows桌面远程连接突然不能双向复制文件
远程桌面连接windows 2008,突然无法在本地和服务器之间互相复制文件.根据微软的说明,由rdpclip.exe进程来控制,打开远程服务器的任务管理器,看到rdpclip.exe进程存在,即可进 ...
- C# vb .net实现淡出效果特效滤镜
在.net中,如何简单快捷地实现Photoshop滤镜组中的淡出效果特效呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第 ...