Hadoop:pig 安装及入门示例
pig是hadoop的一个子项目,用于简化MapReduce的开发工作,可以用更人性化的脚本方式分析数据。
一、安装
a) 下载
从官网http://pig.apache.org下载最新版本(目前是0.14.0版本),最新版本可以兼容hadop 0.x /1.x / 2.x版本,直接解压到某个目录即可。
注:下面是几个国内的镜像站点
http://mirrors.cnnic.cn/apache/pig/
http://mirror.bit.edu.cn/apache/pig/
http://mirrors.hust.edu.cn/apache/pig/
本文的解压目录是:/Users/jimmy/app/pig-0.14.0
b) 环境变量
export PIG_HOME=/Users/jimmy/app/pig-0.14.0
export HADOOP_HOME=/Users/jimmy/app/hadoop-2.6.0
export PIG_CLASSPATH=${HADOOP_HOME}/etc/hadoop/
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
...
export PATH=${PIG_HOME}/bin:$PATH
至少要配置上面这几项,其它项比如JAVA_HOME就不必多说了,肯定也是要的。
c) 启动
$PIG_HOME/bin/pig
如果能正常进入grunt > 提示符就表示ok了
二、基本HDFS操作
pig的好处之一是简化了HDFS的操作,没有pig之前要查看一个hdfs的文件,必须$HADOOP_HOME/bin/hdfs dfs -ls /input 打一堆命令,而在pig shell交互模式下,只需要
ls /input 即可
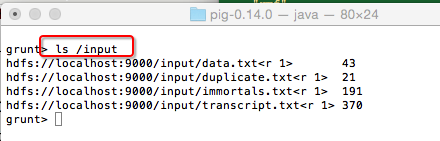
查看hdfs文件内容
cat /input/duplicate.txt
跟在linux下操作完全一样,其它命令留着大家自己去研究吧,不熟悉的可以用help查看帮助
三、基本的数据分析
在前面的文章 Hadoop: MapReduce2的几个基本示例 中,我们用JAVA编程的方式演示了几个基本例子,现在拿pig来实现一把作为对比:
a) 求Count
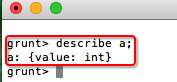
grunt> a = LOAD '/input/duplicate.txt' AS (value:int);
先将输入文件加载到a中,由于输入文件每行只有一个数字,最后的AS部分表示创建了一个列,名称为value,为整型,其值就是这个数字的值。
可以用describle a; 查看结构,如果要看具体值,可以用dump a;
grunt> b = GROUP a all;
对a进行分组,这里由于没有指定分组条件,所以相当每一行都是分组组件,这一条命令的主要作用是实现行转列,执行完以后,可以查下b的结构和值:


grunt> c = FOREACH b GENERATE COUNT(a.value);
由于b只有一行了,所以上面的语句其实就是求该所有a.value列的个数,即输入文件的总数。
原来用MapReduce要写一坨java代码的工作,现在用PIG只要3条命令就搞定了。
b) 求最大值(MAX)
grunt> c = FOREACH b GENERATE MAX(a.value);
c) 求平均值(AVG)
grunt> c = FOREACH b GENERATE AVG(a.value);
d) 求和(SUM)
grunt> c = FOREACH b GENERATE SUM(a.value);
e) 去重复(DISTINCT)
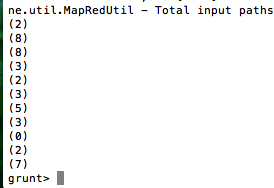
DISTINCT的思路跟前面略有不同,关键在于如何分组,见下面的命令:
grunt> b = GROUP a by value;
对a分组,分组依据为value值,这样重复的值就归到一组了,可以用dump b;看下结果:
剩下的事情就好办了,把b的第一列取出来即可
grunt> c = FOREACH b GENERATE group;
处理完成,用dump c;查看结果

当然,对本例而言,还有一种更简单的去重方法:
grunt> b = DISTINCT a;
f) WordCount
已经有人研究过了,就直接拿来用吧,见:http://blog.itpub.net/26495863/viewspace-1348121/
grunt> a = LOAD '/input/immortals.txt' as (line:chararray); //加载输入文件,并按行分隔
grunt> words = FOREACH a GENERATE flatten(TOKENIZE(line)) as w; //将每行分割成单词
grunt> g = GROUP words by w; //按单词分组
grunt> wordcount = FOREACH g GENERATE group,COUNT(words); //单词记数
输出结果 dump wordcount;
(I,4)
(Of,1)
(am,1)
(be,3)
(do,2)
(in,1)
(it,1)
(of,1)
(to,1)
(we,3)
(But,1)
(all,1)
(are,2)
(bad,1)
(but,1)
(dog,1)
(not,1)
(say,1)
(the,4)
(way,1)
(They,1)
(best,1)
(have,1)
(what,1)
(will,2)
(your,1)
(fever,1)
(flame,1)
(guard,1)
(dreams,1)
(eternal,1)
(watcher,1)
(behavior,1)
g) wordcount2(带词频倒排序)
在刚才的示例上修改一下:
a = LOAD '/input/immortals.txt' as (line:chararray);
words = FOREACH a GENERATE flatten(TOKENIZE(line)) as w;
g = GROUP words by w;
前面这几行都不用改
wordcount = FOREACH g GENERATE group,COUNT(words) as count;//给单词数所在列加一个别名count
r = foreach wordcount generate count,group;//将结果列交换,将变成{count,word}这种结构
(4,I)
(1,Of)
(1,am)
(3,be)
(2,do)
(1,in)
(1,it)
(1,of)
(1,to)
(3,we)
(1,But)
(1,all)
(2,are)
(1,bad)
(1,but)
(1,dog)
(1,not)
(1,say)
(4,the)
(1,way)
(1,They)
(1,best)
(1,have)
(1,what)
(2,will)
(1,your)
(1,fever)
(1,flame)
(1,guard)
(1,dreams)
(1,eternal)
(1,watcher)
(1,behavior)
g2 = group r by count;//按count分组
(1,{(1,behavior),(1,watcher),(1,eternal),(1,dreams),(1,guard),(1,flame),(1,fever),(1,your),(1,what),(1,have),(1,best),(1,They),(1,way),(1,say),(1,not),(1,dog),(1,but),(1,bad),(1,all),(1,But),(1,to),(1,of),(1,it),(1,in),(1,am),(1,Of)})
(2,{(2,will),(2,are),(2,do)})
(3,{(3,we),(3,be)})
(4,{(4,I),(4,the)})
x = foreach g2 generate group,r.group;//去掉无用的列
(1,{(behavior),(watcher),(eternal),(dreams),(guard),(flame),(fever),(your),(what),(have),(best),(They),(way),(say),(not),(dog),(but),(bad),(all),(But),(to),(of),(it),(in),(am),(Of)})
(2,{(will),(are),(do)})
(3,{(we),(be)})
(4,{(I),(the)})
y = order x by group desc;//按count倒排
(4,{(I),(the)})
(3,{(we),(be)})
(2,{(will),(are),(do)})
(1,{(behavior),(watcher),(eternal),(dreams),(guard),(flame),(fever),(your),(what),(have),(best),(They),(way),(say),(not),(dog),(but),(bad),(all),(But),(to),(of),(it),(in),(am),(Of)})
最后给二个网友整理的pig用法文章地址:
hadoop pig 入门总结 http://blackproof.iteye.com/blog/1791980
pig中各种sql语句的实现 http://www.open-open.com/lib/view/open1385173281604.html
Hadoop:pig 安装及入门示例的更多相关文章
- hadoop环境安装及简单Map-Reduce示例
说明:这篇博客来自我的csdn博客,http://blog.csdn.net/lxxgreat/article/details/7753511 一.参考书:<hadoop权威指南--第二版(中文 ...
- Pig安装及简单使用(pig版本0.13.0,Hadoop版本2.5.0)
原文地址:http://www.linuxidc.com/Linux/2014-03/99055.htm 我们用MapReduce进行数据分析.当业务比较复杂的时候,使用MapReduce将会是一个很 ...
- Hadoop之Pig安装
Pig可以看做是Hadoop的客户端软件,使用Pig Latin语言可以实现排序.过滤.求和.分组等操作. Pig的安装步骤: 一.去Pig的官方网站下载.http://pig.apache.org/ ...
- hadoop生态圈安装详解(hadoop+zookeeper+hbase+pig+hive)
-------------------------------------------------------------------* 目录 * I hadoop分布式安装 * II zoo ...
- hadoop pig入门总结
在这里贴一个pig源码的分析,做pig很长时间没做笔记,不包含任何细节,以后有机会再说吧 http://blackproof.iteye.com/blog/1769219 hadoop pig入门总结 ...
- TensorFlow入门,基本介绍,基本概念,计算图,pip安装,helloworld示例,实现简单的神经网络
TensorFlow入门,基本介绍,基本概念,计算图,pip安装,helloworld示例,实现简单的神经网络
- hadoop入门篇-hadoop下载安装教程(附图文步骤)
在前几篇的文章中分别就虚拟系统安装.LINUX系统安装以及hadoop运行服务器的设置等内容写了详细的操作教程,本篇分享的是hadoop的下载安装步骤. 在此之前有必要做一个简单的说明:分享的所有内容 ...
- Hadoop Pig
Pig包括两部分: 用于描述数据流的语言,称为Pig Latin. 用于执行Pig Latin程序的执行环境,当前有两个环境:单JVM中的本地执行环境和Hadoop集群上的分布式执行环境. Pig内部 ...
- Apache Hadoop2.x 边安装边入门
完整PDF版本:<Apache Hadoop2.x边安装边入门> 目录 第一部分:Linux环境安装 第一步.配置Vmware NAT网络 一. Vmware网络模式介绍 二. NAT模式 ...
随机推荐
- git之一
1.Git是什么Git是一款免费.开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目. Git是一个开源的分布式版本控制系统,用以有效.高速的处理从很小到非常大的项目版本管理.Git 是 ...
- WPF学习之路(十二)控件(Content控件)
Label Label相比TextBlock功能并不强大,但是支持键盘快捷键的方式获得焦点 <StackPanel> <Label Target="{Binding Ele ...
- Hessian 二进制RPC协议框架
Hessian是一个由Caucho Technology开发的轻量级二进制RPC协议. 和其他Web服务的实现框架不同的是,Hessian是一个使用二进制轻量级的Web服务协议的框架,免除了许多附加的 ...
- HDFS
1.HDFS shell 1.0查看帮助 hadoop fs -help <cmd> 1.1上传 hadoop fs -put <linux上文件> <hdfs上的路径& ...
- c# winform插件
插件接口 namespace IMsg { ///<summary> /// 这是插件必须实现的接口,也是主程序与插件通信的唯一接口 /// 换句话说,主程序只认识插件里的这些方法 /// ...
- ubuntu下apache2 安装 配置 卸载 CGI设置 SSL设置
一.安装.卸载apache2 apache2可直接用命令安装 sudo apt-get install apache2 卸载比较麻烦,必须卸干净,否则会影响ap ...
- 网友转发的很全的 LISTCTL 控件使用的说明
作者:lixiaosan 时间:04/06/2006 以下未经说明,listctrl默认view 风格为report 相关类及处理函数 MFC:CListCtrl类 SDK:以 "ListV ...
- 利用NuSoap开发WebService(PHP)
利用NuSoap开发WebService(PHP) 分类: php 2010-09-08 12:00 5005人阅读 评论(1) 收藏 举报 webservicephpsoapstringencodi ...
- node命令
- Eclipse中启动tomcat报错:A child container failed during start
我真的很崩溃,先是workspace崩了,费了好久重建的workspace,然后建立了一个小demo项目,tomcat中启动却报错,挑选其中比较重要的2条信息如下: A child container ...