Cypher查询语言--Neo4j 之高级篇 (六)
目录
- 排序Order by
- 通过节点属性排序节点
- 通过多节点属性排序节点
- 倒序排列节点
- 空值排序
- Skip
- 跳过前三个
- 返回中间两个
- Limit
- 返回第一部分
- 函数Functions
- 判断
- All
- Any
- None
- Single
- Scalar函数
- Length
- Type
- Id
- Coalesce
- Iterable函数
- Nodes
- Relationships
- Extract
排序(Order by)
输出结果排序可以使用order by 子句。注意,不能使用节点或者关系排序,仅仅只针对其属性有效。
图:

通过节点属性排序节点
查询:
START n=node(3,1,2)
RETURN n
ORDER BY n.name
结果:

通过多节点属性排序节点
在order by子句中可以通过多个属性来排序每个标识符。Cypher首先将通过第一个标识符排序,如果第一个标识符或属性相等,则在order by中检查下一个属性,依次类推。
查询:
START n=node(3,1,2)
RETURN n
ORDER BY n.age, n.name
首先通过age排序,然后再通过name排序。
结果:

倒序排列节点
可以在标识符后添加desc或asc来进行倒序排列或顺序排列。
查询:
START n=node(3,1,2)
RETURN n
ORDER BY n.name DESC
结果:

空值排序
当排列结果集时,在顺序排列中null将永远放在最后,而在倒序排列中放最前面。
查询:
START n=node(3,1,2)
RETURN n.length?, n
ORDER BY n.length?
结果:

Skip
Skip允许返回总结果集中的一个子集。此不保证排序,除非使用了order by’子句。
图:

跳过前三个
返回结果中一个子集,从第三个结果开始,语法如下:
查询:
START n=node(3, 4, 5, 1, 2)
RETURN n
ORDER BY n.name
SKIP 3
前三个节点将略过,最后两个节点将被返回。
结果:

返回中间两个
查询:
START n=node(3, 4, 5, 1, 2)
RETURN n
ORDER BY n.name
SKIP 1
LIMIT 2
中间两个节点将被返回。
结果:

Limit
Limit允许返回结果集中的一个子集。
图:
返回第一部分
查询:
START n=node(3, 4, 5, 1, 2)
RETURN n
LIMIT 3
结果:

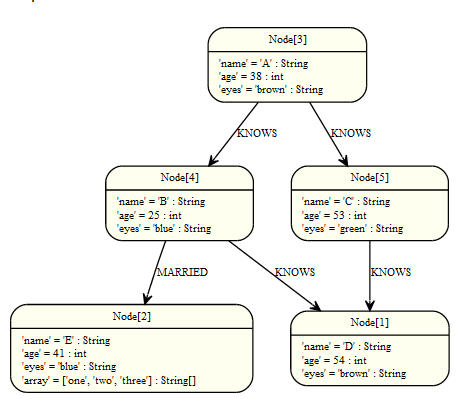
函数(Functions)
在Cypher中有一组函数,可分为三类不同类型:判断、标量函数和聚类函数。
图:
判断
判断为boolean函数,对给出的输入集合做判断并返回true或者false。常用在where子句中过滤子集。
All
迭代测试集合中所有元素的判断。
语法:
All(标识符 in iterable where 判断)
参数:
Ø iterable :一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø 标识符:可用于判断比较的标识符。
Ø 判断:一个测试所有迭代器中元素的判断。
查询:
START a=node(3), b=node(1)
MATCH p=a-[*1..3]->b
WHERE all(x in nodes(p) WHERE x.age > 30)
RETURN p
过滤包含age〈30的节点的路径,返回符合条件路径中所有节点。
结果:
Any
语法:ANY(identifierin iterable WHERE predicate)
参数:
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø Identifier(标识符):可用于判断比较的标识符。
Ø Predicate(判断):一个测试所有迭代器中元素的判断。
查询:
START a=node(2)
WHERE any(x in a.array WHERE x = "one")
RETURN a
结果:

None
在迭代器中没有元素判断将返回true。
语法:NONE(identifierin iterable WHERE predicate)
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø Identifier(标识符):可用于判断比较的标识符。
Ø Predicate(判断):一个测试所有迭代器中元素的判断。
查询:
START n=node(3)
MATCH p=n-[*1..3]->b
WHERE NONE(x in nodes(p) WHERE x.age = 25)
RETURN p
结果:

Single
如果迭代器中仅有一个元素则返回true。
语法:SINGLE(identifierin iterable WHERE predicate)
参数:
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø Identifier(标识符):可用于判断比较的标识符。
Ø Predicate(判断):一个测试所有迭代器中元素的判断。
查询:
START n=node(3)
MATCH p=n-->b
WHERE SINGLE(var in nodes(p) WHERE var.eyes = "blue")
RETURN p
结果:

Scalar函数
标量函数返回单个值。
Length
使用详细的length属性,返回或过滤路径的长度。
语法:LENGTH(iterable )
参数:
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
查询:
START a=node(3)
MATCH p=a-->b-->c
RETURN length(p)
返回路径的长度。
结果:
Type
返回关系类型的字符串值。
语法:TYPE(relationship )
参数:
Ø Relationship:一条关系。
查询:
START n=node(3)
MATCH (n)-[r]->()
RETURN type(r)
返回关系r的类型。
结果:

Id
返回关系或者节点的id
语法:ID(property-container )
参数:
Ø Property-container:一个节点或者一条关系。
查询:
START a=node(3, 4, 5)
RETURN ID(a)
返回这三个节点的id。
结果:

Coalesce
返回表达式中第一个非空值。
语法:COALESCE(expression [, expression]* )
参数:
Ø Expression:可能返回null的表达式。
查询:
START a=node(3)
RETURN coalesce(a.hairColour?,a.eyes?)
结果:

Iterable函数
迭代器函数返回一个事物的迭代器---在路径中的节点等等。
Nodes
返回一个路径中的所有节点。
语法:NODES(path )
参数:
Ø Path:路径
查询:
START a=node(3), c=node(2)
MATCH p=a-->b-->c
RETURN NODES(p)
结果:

Relationships
返回一条路径中的所有关系。
语法:RELATIONSHIPS(path )
参数:
Ø Path:路径
查询:
START a=node(3), c=node(2)
MATCH p=a-->b-->c
RETURN RELATIONSHIPS(p)
结果:

Extract
可以使用extract单个属性,或从关系或节点集合迭代一个函数的值。将遍历迭代器中所有的节点并运行表达式返回结果。
语法:EXTRACT(identifier in iterable : expression )
Ø Iterable(迭代器):一个集合属性,或者可迭代的元素,或一个迭代函数。
Ø Identifier(标识符):闭包中表述内容的标识符,这决定哪个标识符将用到。
Ø expression(表达式):这个表达式将对于迭代器中每个值运行一次,并生成一个结果迭代器。
查询:
START a=node(3), b=node(4),c=node(1)
MATCH p=a-->b-->c
RETURN extract(n in nodes(p) : n.age)
返回路径中所有age属性值。
结果:

Cypher查询语言--Neo4j 之高级篇 (六)的更多相关文章
- Cypher查询语言--Neo4j 入门 (一)
目录 操作符 参数 标识符 注解 Start 通过id绑定点 通过id绑定关系 通过id绑定多个节点 所有节点 通过索引查询获取节点 通过索引查询获取关系 多个开始点 Cypher是一个描述性的图形 ...
- Cypher查询语言--Neo4j之聚合函数(五)
目录 聚合Aggregation 计数 计算节点数 分组计算关系类型 计算实体数 计算非空可以值数 求和sum 平均值avg 最大值max 最小值min 聚类COLLECT 相异DISTINCT 聚合 ...
- C# 扩展方法奇思妙用高级篇六:WinForm 控件选择器
在Web开发中,jQuery提供了功能异常强大的$选择器来帮助我们获取页面上的对象.但在WinForm中,.Net似乎没有这样一个使用起来比较方便的选择器.好在我们有扩展方法,可以很方便的打造一个. ...
- Cypher查询语言--Neo4j 综合(四)
目录 返回节点 返回关系 返回属性 带特殊字符的标识符 列的别名 可选属性 特别的结果 查询中的返回部分,返回途中定义的感兴趣的部分.可以为节点.关系或其上的属性. 图 返回节点 返回一个节点,在 ...
- Neo4j Cypher查询语言详解
Cypher介绍 "Cypher"是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询.Cypher还在继续发展和成熟,这也就意味着有可能会出现 ...
- ORM查询语言(OQL)简介--高级篇(续):庐山真貌
相关文章内容索引: ORM查询语言(OQL)简介--概念篇 ORM查询语言(OQL)简介--实例篇 ORM查询语言(OQL)简介--高级篇:脱胎换骨 ORM查询语言(OQL)简介--高级篇(续):庐山 ...
- ORM查询语言(OQL)简介--高级篇:脱胎换骨
相关文章内容索引: ORM查询语言(OQL)简介--概念篇 ORM查询语言(OQL)简介--实例篇 ORM查询语言(OQL)简介--高级篇:脱胎换骨 ORM查询语言(OQL)简介--高级篇(续):庐山 ...
- ORM查询语言(OQL)简介高级篇
ORM查询语言(OQL)简介--高级篇:脱胎换骨 在写本文之前,一直在想文章的标题应怎么取.在写了<ORM查询语言(OQL)简介--概念篇>.<ORM查询语言(OQL)简介--实例篇 ...
- 【转载】Spark性能优化指南——高级篇
前言 数据倾斜调优 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数 ...
随机推荐
- 前端 IoC 理念入门
背景 近几年,前端应用(WebApp)正朝着大规模方向发展,在这个过程中我们会对项目拆解成多个模块/组件来组合使用,以此提高我们代码的复用性,最终提高研发效率. 在编写一个复杂组件的时候,总会依赖其他 ...
- 更换HomeBrew源
比较少用brew,只有之前安装Opencv的时候用过一次,后面有人问我怎么装,于是帮他研究了一下.MacOS的brew其实就是通过两个git仓库(brew和homebrew-core)来实现的源更新机 ...
- Gym 100952B&&2015 HIAST Collegiate Programming Contest B. New Job【模拟】
B. New Job time limit per test:1 second memory limit per test:64 megabytes input:standard input outp ...
- 2017广东工业大学程序设竞赛B题占点游戏
Description 众所周知的是,TMK特别容易迟到,终于在TMK某次又迟到了之后,Maple怒了,Maple大喊一声:"我要跟你决一死战!"然后Maple就跟TMK玩起了一个 ...
- 水dp第二天(背包有关)
水dp第二天(背包有关) 标签: dp poj_3624 题意:裸的01背包 注意:这种题要注意两个问题,一个是要看清楚数组要开的范围大小,然后考虑需要空间优化吗,还有事用int还是long long ...
- const类型变量的详细解读
const类型变量--------------------------------------int i;const int *p; --------------------------------- ...
- 【JAVA】SWING_ 界面风格
在java中,界面外观的管理是由UIManager类来管理的.不同的系统上安装的外观不一样 ,默认的是java的跨平台外观. 1.获取系统所有外观 import javax.swing.*; impo ...
- ios开发 第三天
1.复合 对象可以引用其它对象,可以利用其它对象提供的特性. 通过包含作为实例变量的对象指针实现的. 2.OC是单一继承 3.继承-重构 4.类实例化对象时,self指向了对象的首地址. 类对象isa ...
- Insert Sort Singly List
对单链表插入排序,给出个单链表的head节点:返回排完序的head节点: 首先数据结构中习惯了以数组为参数排序,瞬间想到是遍历单链表存入arraylist中,再进行insert sort,(O(n** ...
- gRPC实战
gRPC是Google开源的一款非常棒的系统间通信工具,完美的communication抽象,构建在protobuf之上的RPC. 下面我们聊聊它的应用场景,grpc为分布式系统而生,可以是系统间通信 ...