介绍一种非常好用汇总数据的方式GROUPING SETS
介绍
对于任何人而言,用T-SQL语句来写聚会查询都是工作中重要的一环。我们大家也都很熟悉GROUP BY子句来实现聚合表达式,但是如果打算在一个结果集中包含多种不同的汇总结果,可能会比较麻烦。我将举例展示给大家使用GROUPING SETS操作符来完成这个“混合的结果集”。
或许当我们在打算分析较大规模的数据集时,不知道从何下手,此时处理这种情况最好的方式就是汇总数据,快速的得到一个数据预览。
在T-SQL中,使用GROUP BY子句在一个聚合查询中来汇总需要的数据。这个子句由一组表达式定义的分组构成。结果集中每一行返回GROUP BY 子句中表达式的唯一值或者组合,并且聚合函数,像COUNT或者SUM等可以对查询中的任何行进行聚合。但是,如果你想要多种不同组合的聚合时,一般有两种方式:
1.将不懂组合聚合的结果集UNIONALL在一起。
2.使用 GROUPING SETS操作符,结合GROUP BY一起在一个语句中实现。
本文中,我会展示如何使用GROUPING SETS来实现这一目的。
准备数据集
本文中所有的查询都使用AdventureWorks2012 数据库中的数据,这里提供一个下载地址方便使用(AdventureWorks2012)
实例: Data Analyst at Adventure Works
比如你是一个数据分析师,对于公司今年的收入很感兴趣。这意味着你需要分组汇总公司的每一年的收入,查询语句如下:
Query 1. 汇总每年收入
USE AdventureWorks2012;
GO SELECT
YEAR(OrderDate) AS OrderYear,
SUM(SubTotal) AS Income
FROM Sales.SalesOrderHeader
GROUP BY YEAR(OrderDate)
ORDER BY OrderYear;
GO
Query 1 返回结果集:
|
OrderYear |
Income |
|
2005 |
11331809 |
|
2006 |
30674773.2 |
|
2007 |
42011037.2 |
|
2008 |
25828762.1 |
根据这个结果集,可知该公2005到2008年的收入情况。这类数据信息对于商业分析来说很常见。
但是,如果你想要更多关于收入的信息,比如其他汇总条件,你必须要重新运行一个GROUP BY子句。比如查询返回公司每个月的收入情况。查询语句如下:
Query 2. 公司每个月的收入
SELECT
YEAR(OrderDate) AS OrderYear,
MONTH(OrderDate) AS OrderMonth,
SUM(SubTotal) AS Income
FROM Sales.SalesOrderHeader
GROUP BY YEAR(OrderDate), MONTH(OrderDate)
ORDER BY OrderYear, OrderMonth;
GO
结果集如下:
|
OrderYear |
OrderMonth |
Income |
|
2005 |
7 |
962716.742 |
|
2005 |
8 |
2044600 |
|
2005 |
9 |
1639840.11 |
|
2005 |
10 |
1358050.47 |
|
2005 |
11 |
2868129.2 |
|
2005 |
12 |
2458472.43 |
|
2006 |
1 |
1309863.25 |
|
2006 |
2 |
2451605.62 |
|
2006 |
3 |
2099415.62 |
|
2006 |
4 |
1546592.23 |
|
2006 |
5 |
2942672.91 |
|
2006 |
6 |
1678567.42 |
|
2006 |
7 |
2894054.68 |
|
2006 |
8 |
4147192.18 |
|
2006 |
9 |
3235826.19 |
|
2006 |
10 |
2217544.45 |
|
2006 |
11 |
3388911.41 |
|
2006 |
12 |
2762527.22 |
|
2007 |
1 |
1756407.01 |
|
2007 |
2 |
2873936.93 |
|
2007 |
3 |
2049529.87 |
|
2007 |
4 |
2371677.7 |
|
2007 |
5 |
3443525.25 |
|
2007 |
6 |
2542671.93 |
|
2007 |
7 |
3554092.32 |
|
2007 |
8 |
5068341.51 |
|
2007 |
9 |
5059473.22 |
|
2007 |
10 |
3364506.26 |
|
2007 |
11 |
4683867.05 |
|
2007 |
12 |
5243008.13 |
|
2008 |
1 |
3009197.42 |
|
2008 |
2 |
4167855.43 |
|
2008 |
3 |
4221323.43 |
|
2008 |
4 |
3820583.49 |
|
2008 |
5 |
5194121.52 |
|
2008 |
6 |
5364840.18 |
|
2008 |
7 |
50840.63 |
这个结果集要比之前的更详细一点。可以得到具体某个月的收入汇总。显然GROUP BY 后面的列越多其越详细,结果一般也越多(除非有传递依赖键)。
如果你仔细观察两个查询,你会发现他们都是根据个子的分组表达式进行分组汇总的。前面的是按照年,后面的是按照年和月。
假如我想查看两种汇总结果在一个结果集中应该怎么处理那?为了实现这个目标,我们前面说了两个方案,方案1就是使用UNION ALL,代码如下:
Query 3. 公司收入(每年|每月)
SELECT
YEAR(OrderDate) AS OrderYear,
NULL AS OrderMonth, --Dummy Column
SUM(SubTotal) AS Incomes
FROM Sales.SalesOrderHeader
GROUP BY YEAR(OrderDate)
UNION ALL
SELECT
YEAR(OrderDate) AS OrderYear,
MONTH(OrderDate) AS OrderMonth,
SUM(SubTotal) AS Incomes
FROM Sales.SalesOrderHeader
GROUP BY YEAR(OrderDate), MONTH(OrderDate)
ORDER BY OrderYear, OrderMonth;
GO
结果集如下图所示:
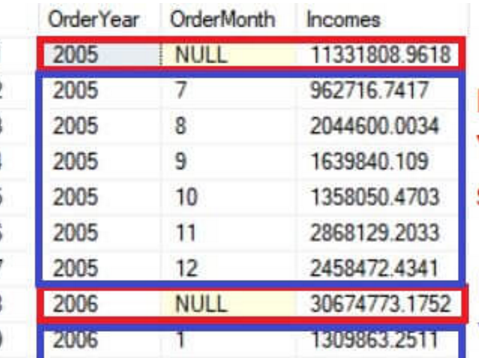
其中红色框内为按照年的汇总数据。蓝色框内为按照年和月的分组汇总。
如图所示两个结果集被合并在一起了。注意。此时NULL出现在里面,使用NULL作为假列来标识order year分组的结果。因为按年分组没有这个列。
尽管你已经获得了想要的结果,但是这样需要完成两次的语句,接下来我们尝试一下grouping set,方案2。因为我们都是懒人吗,所以这个方式一定要更加简单。目的就是“更少代码,相同结果”。接下来我们详细看一下:
Query 4.使用 GROUPING SETS实现相同结果
SELECT
YEAR(OrderDate) AS OrderYear,
MONTH(OrderDate) AS OrderMonth,
SUM(SubTotal) AS Incomes
FROM Sales.SalesOrderHeader
GROUP BY
GROUPING SETS
(
YEAR(OrderDate), --1st grouping set
(YEAR(OrderDate),MONTH(OrderDate)) --2nd grouping set
);
GO
结果集跟之前的一模一样。但是新的代码要少很多。GROUPING SETS 操作符要和GROUP BY 子句在一起使用。并且允许我们可以做一个多分组的查询。尽管如此,我们要仔细检查指定的分组集。例如假如一个分组包含两个列,假设列A和B,两个列都需要包含在括号内:(column A, column B)。如果没有括号,这个子句将会被定义为独立的分组,结果就不同了。
上面语句的结果如下:
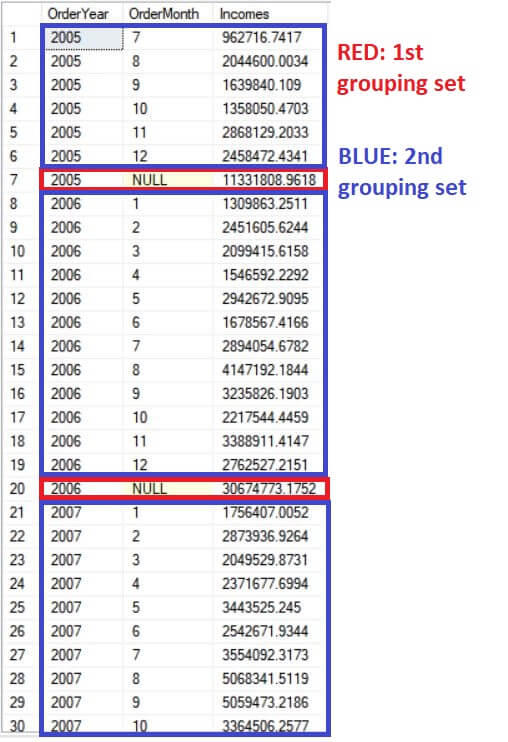
顺便说一下,如果我们打算聚合整个结果集(不分组聚合所有数据),只需要添加有一个空的括号在分组集里面即可。查询语句如下:
Query 5. 加入总体汇总结果
SELECT
YEAR(OrderDate) AS OrderYear,
MONTH(OrderDate) AS OrderMonth,
SUM(SubTotal) AS Incomes
FROM Sales.SalesOrderHeader
GROUP BY
GROUPING SETS
(
YEAR(OrderDate), --1st grouping set
(YEAR(OrderDate),MONTH(OrderDate)), --2nd grouping set
() --3rd grouping set (grand total)
);
GO
结果如图:
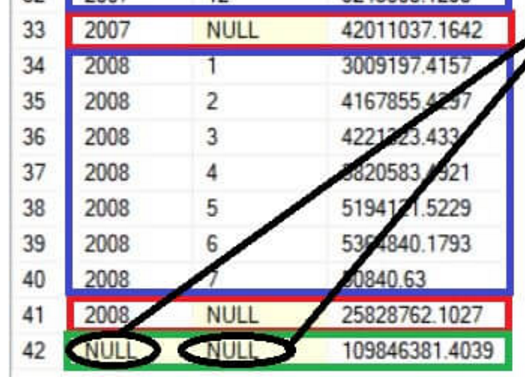
注意最下方的42行,年月都为null,这个查询汇总了郑铁的所有收入,因为没有进行任何分组。
注意,需要强调一个十强,一定要确保分组列字段部位NULL,因此NULLS不能被用作分组列在GROUPING SETS中使用。如果非要那个为空字段,需要使用 GROUPING 或者 GROUPING_ID 函数判断是否NULL来自GROUPING SETS 操作符。
总结
本篇文章中,主要介绍如何使用另一种聚合查询方式来实现多种分组聚合结果的合并。熟悉后你会发现这种方式对于总结汇总数据非常有帮助,大大提高了我们代码的效率。
介绍一种非常好用汇总数据的方式GROUPING SETS的更多相关文章
- 05.Python网络爬虫之三种数据解析方式
引入 回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需要进行指 ...
- Python爬虫之三种数据解析方式
一.引入 二.回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需 ...
- 05,Python网络爬虫之三种数据解析方式
回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需要进行指定数据 ...
- 《Python网络爬虫之三种数据解析方式》
引入 回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需要进行指 ...
- Python网络爬虫之三种数据解析方式 (xpath, 正则, bs4)
引入 回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需要进行指 ...
- Android的数据存储方式(转)
数据存储在开发中是使用最频繁的,在这里主要介绍Android平台中实现数据存储的5种方式,分别是: 1 使用SharedPreferences存储数据 2 文件存储数据 3 SQLite数据库存储数据 ...
- Android两种为ViewPager+Fragment添加Tab的方式
在Android开发中ViewPager的使用是非常广泛的,而它不仅仅能够实现简单的开始引导页,还可以结合Fragment并添加Tab作为选项卡或为显示大批量页面实现强大的顺畅滑动 下面介绍两种为Vi ...
- 简单总结几种常见web攻击手段及其防御方式
web攻击手段有几种,本文简单介绍几种常见的攻击手段及其防御方式 XSS(跨站脚本攻击) CSRF(跨站请求伪造) SQL注入 DDOS XSS 概念 全称是跨站脚本攻击(Cross Site Scr ...
- 简单地总结几种常见web攻击手段及其防御方式
web攻击手段有几种,本文简单介绍几种常见的攻击手段及其防御方式 XSS(跨站脚本攻击) CSRF(跨站请求伪造) SQL注入 DDOS XSS 概念 全称是跨站脚本攻击(Cross Site Scr ...
随机推荐
- 通过案例理解position:relative和position:absolute
w3school过了HTML的知识之后,觉得要自己单纯地去啃知识点有点枯燥,然后自己也很容易忘记,所以便找具体的网站练手便补上不懂的知识点.position:relative和postion:abso ...
- 使用setTimeout实现setInterval
setInterval = () =>{ console.log(1) //使用递归 setTimeout(setInterval,1000); }; setInterval()
- RegExp对象的三个方法
RegExp 对象有 3 个方法:test().exec() 以及 compile(). test( ) test()方法检索字符串中的指定值.返回值是true或false. 例子: 因为字符 ...
- Use LiveCD to acquire images from a VM
Forensic examiners usually acquire images from suspect's PC or Laptop. What if the target computer i ...
- dedecms标签大全
今天用了1个小时的时间整理了dedecms标签大全,非常经典,非常经典的织梦dedecms标签,希望对大家制作dedecms网站有帮助 channel_____栏目 dede_arcty ...
- 批处理注册dll时候 遇到错误:模块已加载,但对***dll的调用失败
解决方法 在批处理的第一行加入:cd /d %~dp0 然后在批处理上右键选择使用管理员权限运行
- 自己写的日志框架--linkinLog4j--实现基本的框架功能
OK,上面一步我们已经知道了日志框架的必要性,然后我们也对比了直接不用日志框架来记录日志的种种弊端.现在我们开始就来一步一步的实现自己的日志框架. 大体的思路如下: 1,实现多种日志级别,通过设值不同 ...
- junit3对比junit4
本文内容摘自junit实战,感谢作者的无私奉献. 个人觉得每个开源包的版本对比意义不大,闲来无事,这里就来整理一下好了.本文名为junit3对比junit4,但是我通过这篇博客主要也是想统一的来整理下 ...
- linkin大话设计模式--桥接模式
linkin大话设计模式--桥接模式 桥接模式是一种结构化模式,他主要应对的是:由于实际的需要,某个类具有2个或者2个以上维度的变化,如果只是使用继承将无法实现功能,或者会使得设计变得相当的臃肿.我们 ...
- ClearCase config_spec
1.使用分支前要在vob创建branch type,Config_Spec不能自动创建branch type: 2.如果可能,最好在以前确定的label上进行新的工作,避免维护复杂的config_s ...