Ubuntu搭建Hadoop的踩坑之旅(一)
本文将介绍如何使用虚拟机一步步从安装Ubuntu到搭建Hadoop伪分布式集群。
本文主要参考:在VMware下安装Ubuntu并部署Hadoop1.2.1分布式环境 - CSDN博客
一、所需的环境和软件:(以下是我们的环境,仅供参考)
1. 操作系统:Windows 10 64位
2. 内存:4G以上(4G 可以搭建,不过虚拟机的运行可能会比较慢,这种情况可以考虑双系统)
3. VMware Workstation 12:VMware-workstation-full-12.5.7-5813279.exe
4. VMware Tools:通过VMware来安装
5. Ubuntu12.04:ubuntu-14.04.5-desktop-amd64.iso,ubuntu-16.04.3-desktop-amd64.iso(团队中两种系统都有人成功,不过高版本的比较顺利)
6. SSH:通过linux命令来安装
7. JDK1.8:jdk-8u11-linux-x64.tar.gz
8. Hadoop2.6.0:hadoop-2.6.0.tar.gz
二、VMware的安装
到网上去下载一个合适版本的VMware,我们用的是VMware-workstation-full-12.5.7-5813279.exe,然后找到激活码,按照提示下一步就行,这个非常简单,就不再赘述了。安装完成之后是一下界面:
三、在VMware下安装一个空白的虚拟机
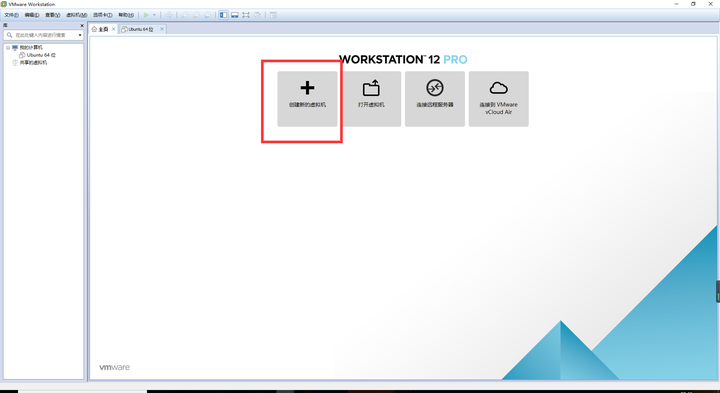
- 打开VMware,点击创建新的虚拟机
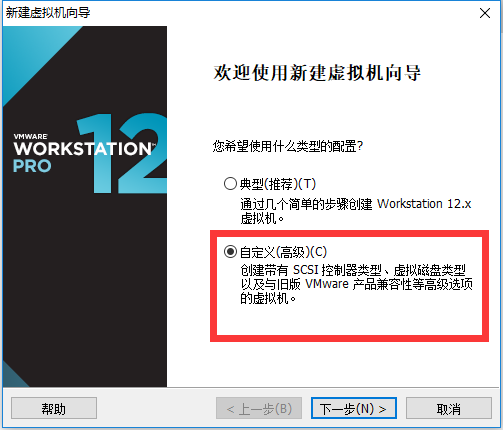
2、出现如下界面,点击自定义,下一步
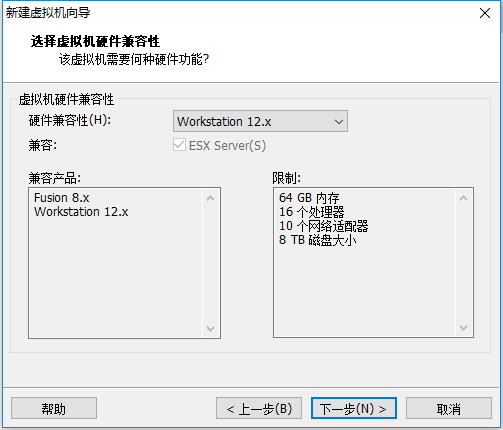
3、出现如下界面,直接下一步
4、出现如下界面,点击稍后安装系统,下一步
5、出现如下界面,点击Linux,版本视你的安装镜像而定,下一步
6、出现如下界面,更改合适的位置(最好别装c盘,选一个比较空余的盘),下一步
7、出现如下界面,根据个人电脑配置而定,下一步
8、出现如下界面,选择合适的内存,如果内存较大,建议2个g以上,如果本机内存较小,1.5G为怡,下一步
9、出现如下界面,主要是两种,桥接可以和内网的其他机子通信,.net只能和本机通信,建议桥接,下一步
10、出现如下界面,使用推荐的就好,下一步
11、出现如下界面,使用推荐的就好,下一步

12、出现如下界面,使用默认的就好,下一步
13、出现如下界面,20g并不是一下子占用20g而是随着使用而扩大,这点不必担心,下一步
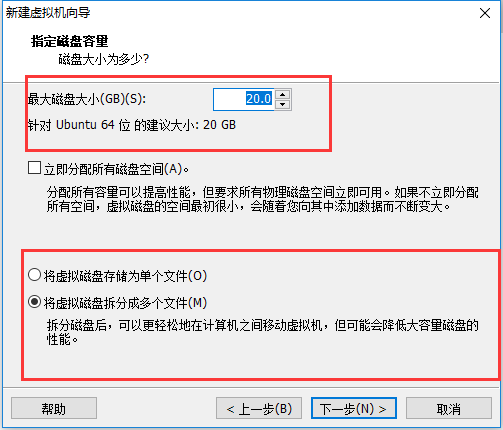
14、出现如下界面,最好新建一个目录,方便出现问题时候,直接删除这个虚拟机,注意是删除虚拟机而不是VWM(这两个是有区别的),下一步
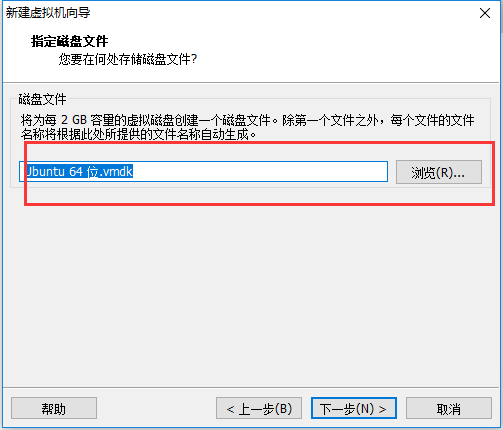
15、单击完成。
四、安装Ubuntu
1、找到刚刚建好的虚拟机,点击编辑虚拟机配置

2、会看到下面的界面,上一步配置的东西在这里都可以改,我们要点击CD/DVD
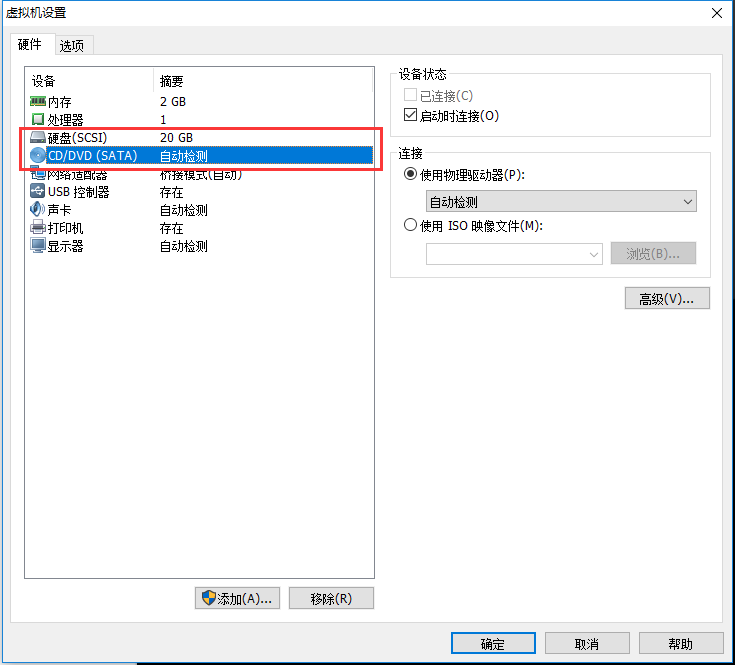
3、使用镜像安装,找到你下载的Ubuntu镜像
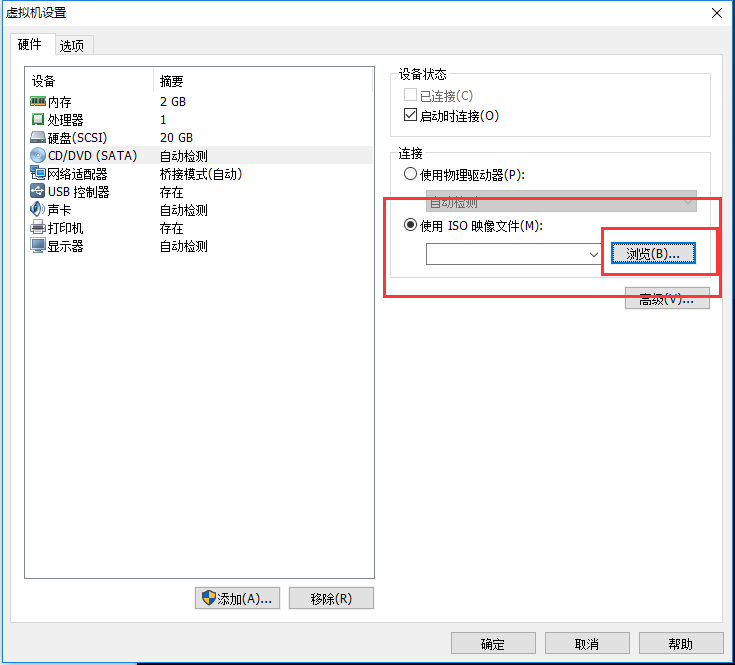
4、ok,确定
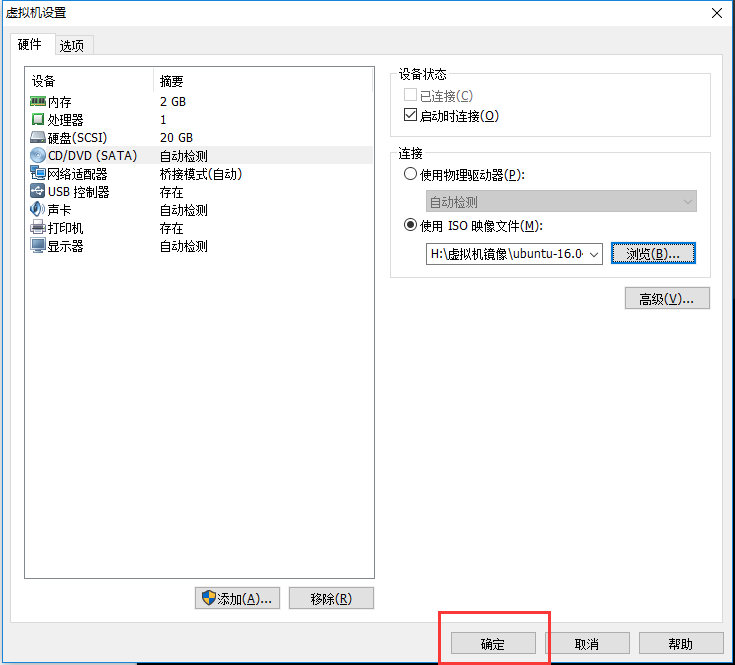
5、回到这个页面,开启此虚拟机
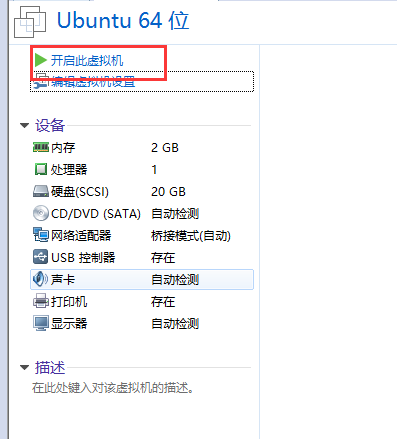
6、稍等,看到如下界面:语言拉下来,有中文,然后安装Ubuntu
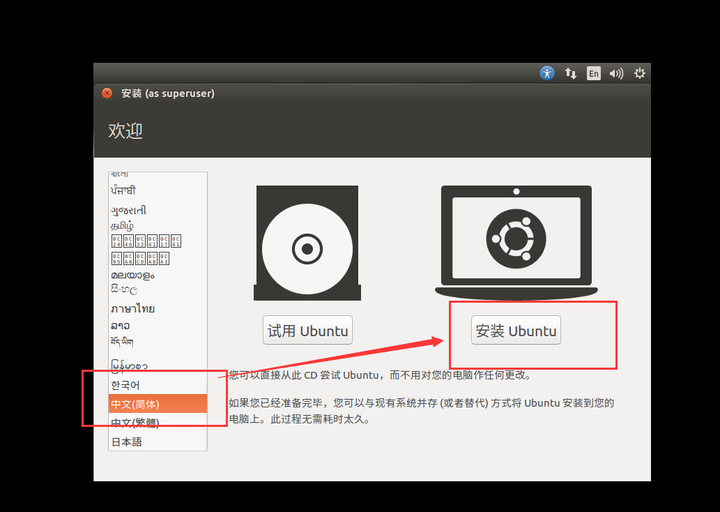
7、看到如下界面:上面的框看个人喜好,继续
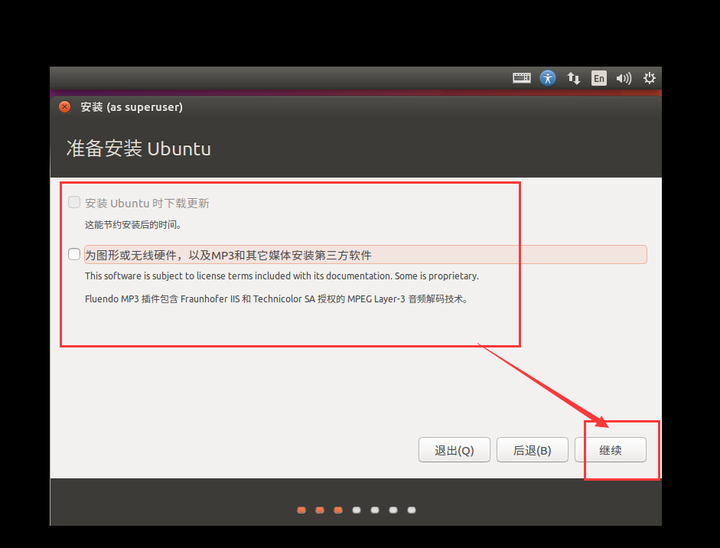
8、看到如下界面:这里的格式化是指你分配的虚拟机空间,并不会直接格式化你的整个磁盘,可以放心使用。然后点击现在安装
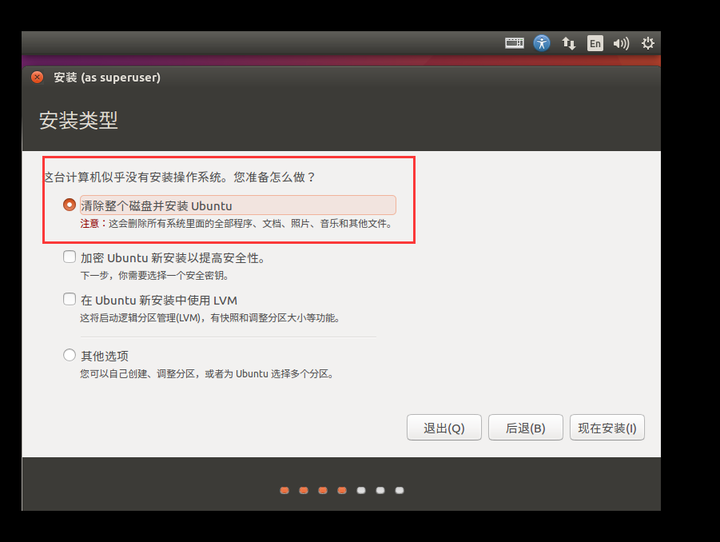
9、已经自动建立好了分区,继续
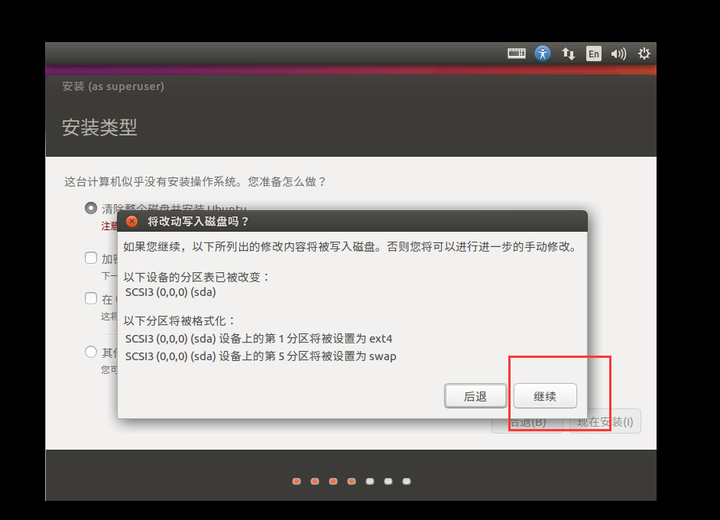
10、时区随意咯,继续

11、会出现下面的界面,键盘布局点汉语,继续
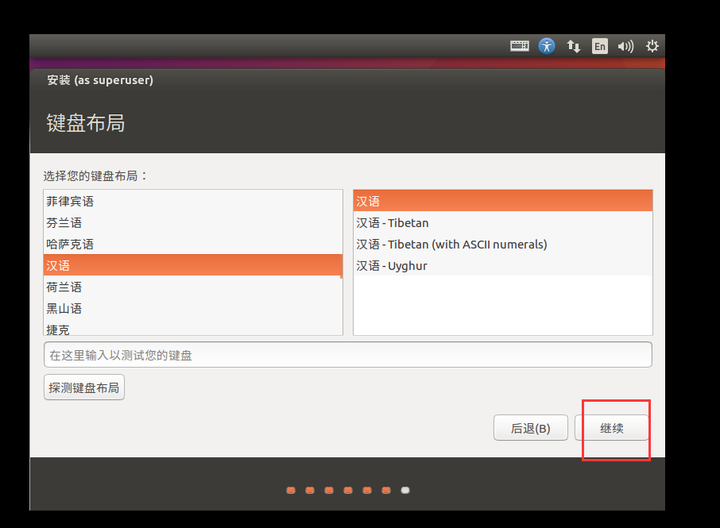
12、会出现下面的界面,计算名什么的随意,不过如果配置多台机器,用户名最好要一致,密码仅供测试用,可以尽量简单。继续

13、开始安装,等待吧......
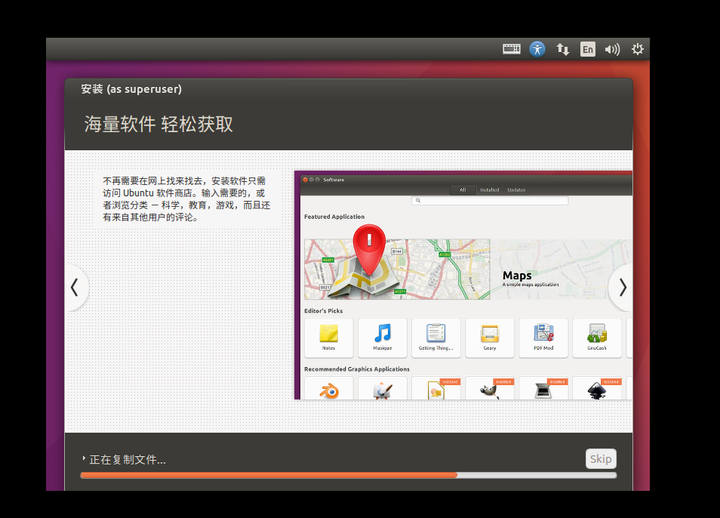
14、安装完毕,重启(忘了截图)。
15、重启后会进入下页面,说明Ubuntu安装成功
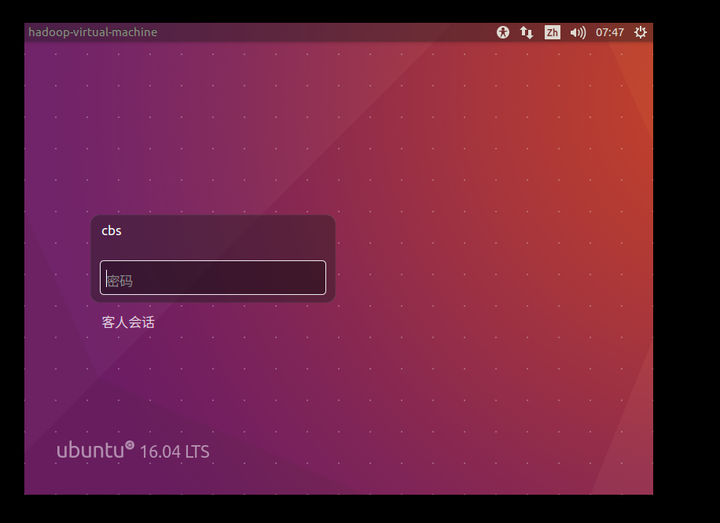
备注:重启时有一段信息需要回车,如果长时间不按,会卡主,这时点击虚拟机上面的重启就好。
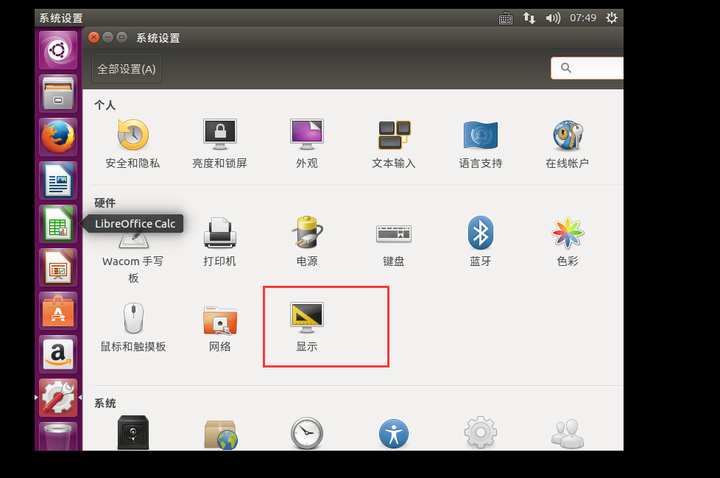
显示可以改分辨率,会舒服些。
16、安装VMware的tools,单击虚拟机,会有一个安装的选项,之后Ubuntu会自动弹出安装包。
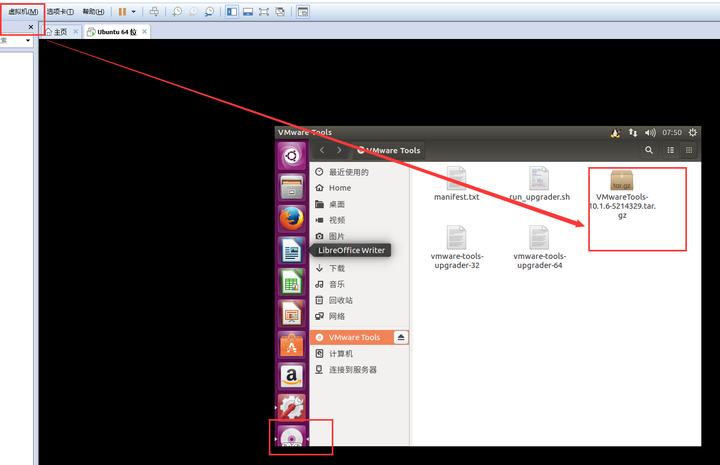
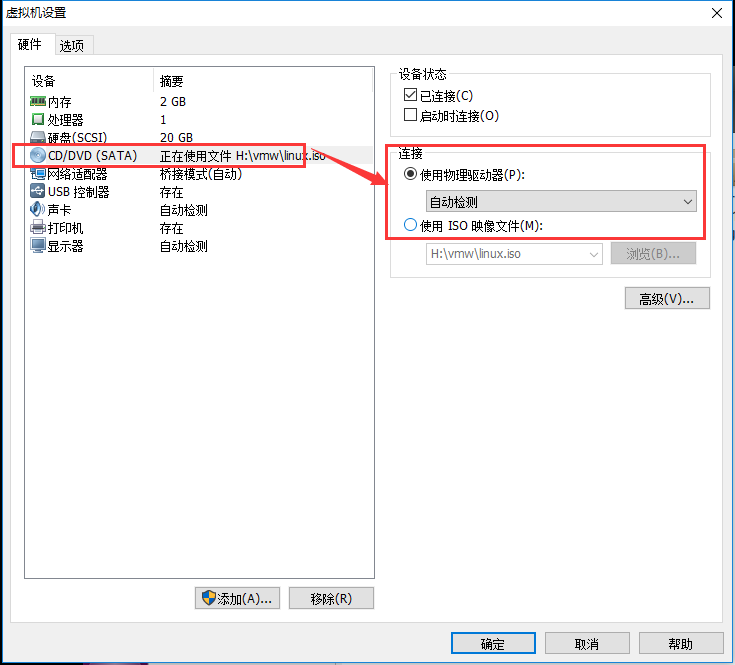 如果没有弹出,去驱动器改回来
如果没有弹出,去驱动器改回来
将安装包拖到home目录下:
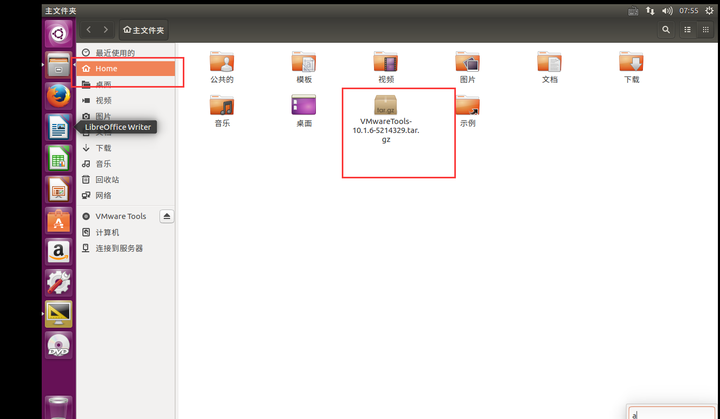
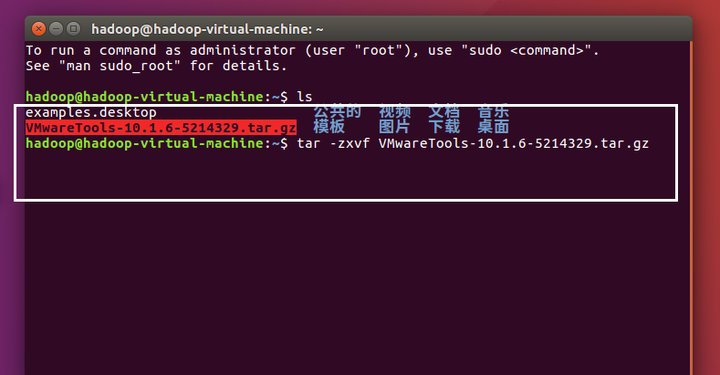
CTRL alt +T打开一个终端,使用“tar -zxvf VMwareTools-10.1.6-1294478.tar.gz”命令解压文件, VMwareTools-10.1.6-1294478.tar.gz视你的版本而定。
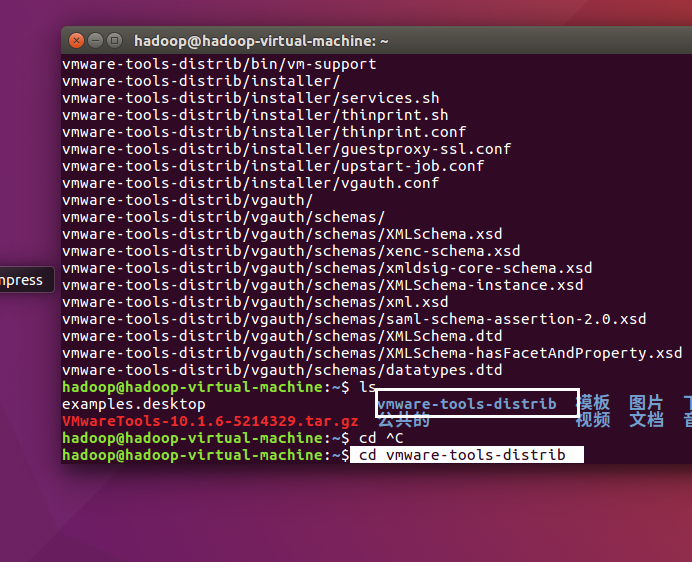
使用cd vmware-tools-distrib命令进入文件夹,
用sudo passwd root更改root 密码:密码不会显示,输就是了
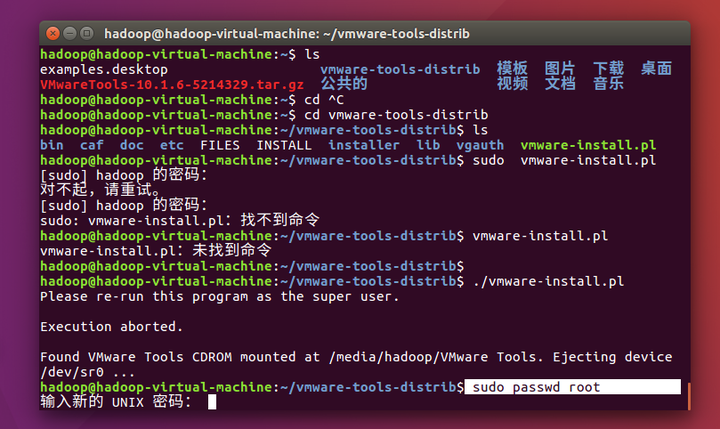
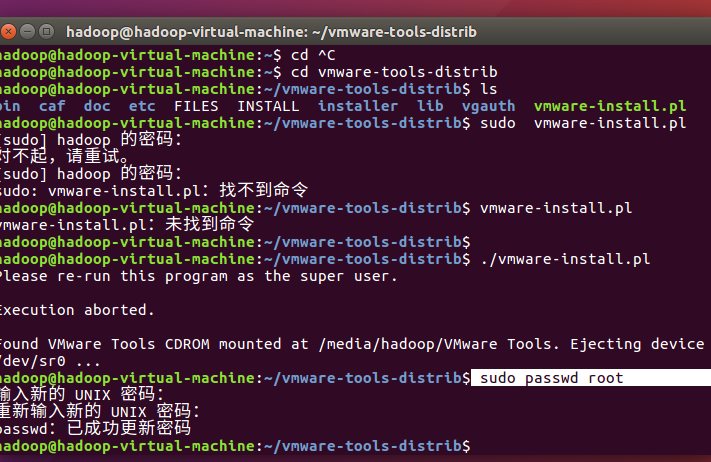
输入sudo ./vmware-install.pl安装
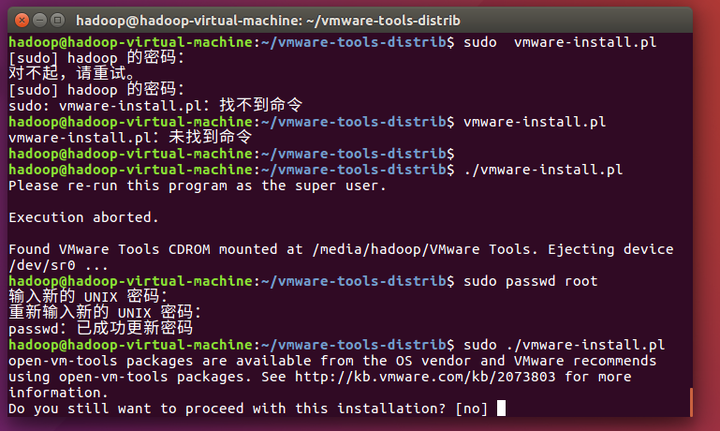
安装过程中,根据提示(回车、或者输入yes或no),并输入相应的内容。这样就可以安装成功,重启虚拟机后会生效。
比如:“”什么也没有,按键 “回车”;
[yes] 输入yes
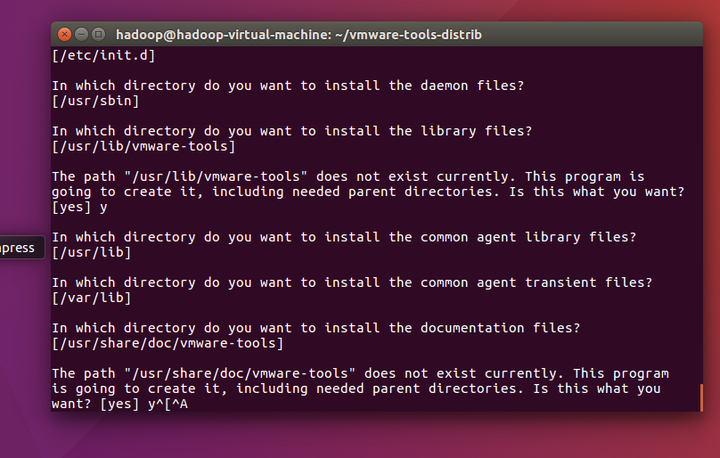
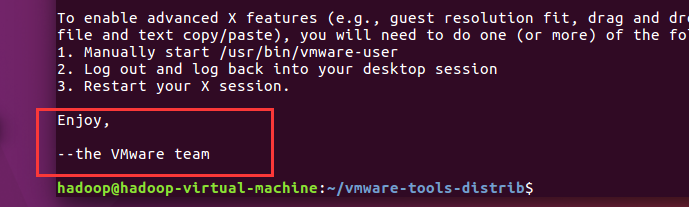
到这里就成功了:
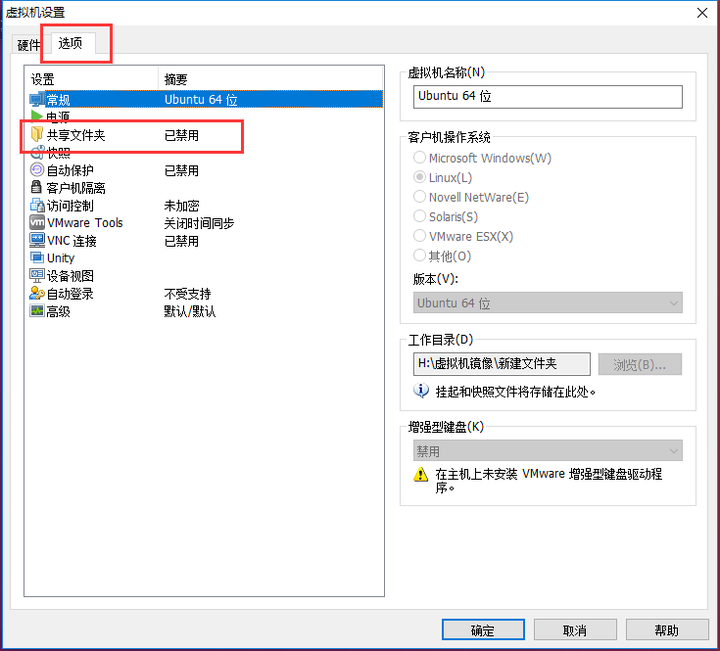
17、配置共享文件夹
单击虚拟机>设置:>共享文件夹
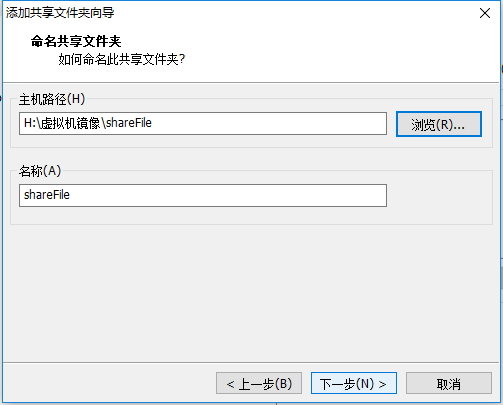
看到这个:单机总是启用,添加即可,设置后可以在虚拟机和Windows下看到同一个文件夹


到此,你的入坑第一步结束,祝~你~愉~快~
Ubuntu搭建Hadoop的踩坑之旅(一)的更多相关文章
- ubuntu搭建开发环境踩坑实录
谨以此文,记录和ubuntu系统不死不休的搏斗过程,后续待补. 1.双系统安装,windows采用uefi模式安装(优启通可制作uefi的win10安装盘),ubuntu不要划分boot区,而应该划分 ...
- 微信小程序之mpvue+iview踩坑之旅
因为之前参照微信的原生的文档写过一些小程序的demo,写的过程比较繁琐,后来出了美团的mpvue,可以直接使用vue开发,其他的不作对比,这篇文章记录一下踩坑之旅. 参照mpvue http://mp ...
- 我的微信小程序入门踩坑之旅
前言 更好的阅读体验请:我的微信小程序入门踩坑之旅 小程序出来也有一段日子了,刚出来时也留意了一下.不过赶上生病,加上公司里也有别的事,主要是自己犯懒,就一直没做.这星期一,赶紧趁着这股热乎劲,也不是 ...
- vue+ vue-router + webpack 踩坑之旅
说是踩坑之旅 其实是最近在思考一些问题 然后想实现方案的时候,就慢慢的查到这些方案 老司机可以忽略下面的内容了 1)起因 考虑到数据分离的问题 因为server是express搭的 自然少 ...
- ubuntu 下安装docker 踩坑记录
ubuntu 下安装docker 踩坑记录 # Setp : 移除旧版本Docker sudo apt-get remove docker docker-engine docker.io # Step ...
- vue踩坑之旅 -- computed watch
vue踩坑之旅 -- computed watch 经常在使用vue初始化组件时,会报一些莫名其妙的错误,或者,数据明明有数据,确还是拿不到,这是多么痛苦而又令人忍不住抓耳挠腮,捶胸顿足啊 技术点 v ...
- Python踩坑之旅其一杀不死的Shell子进程
目录 1.1 踩坑案例 1.2 填坑解法 1.3 坑位分析 1.4 坑后扩展 1.4.1 扩展知识 1.4.1 技术关键字 1.5 填坑总结 1.1 踩坑案例 踩坑的程序是个常驻的Agent类管理进程 ...
- Python 踩坑之旅进程篇其三pgid是个什么鬼 (子进程\子孙进程无法kill 退出的解法)
目录 1.1 踩坑案例 1.2 填坑解法 1.3 坑位分析 1.4.1 技术关键字 下期坑位预告 代码示例支持 平台: Centos 6.3 Python: 2.7.14 Github: https: ...
- [代码修订版] Python 踩坑之旅 [进程篇其四] 踩透 uid euid suid gid egid sgid的坑坑洼洼
目录 1.1 踩坑案例 1.2 填坑解法 1.3 坑位分析 1.4 技术关键字 1.5 坑后思考 下期坑位预告 代码示例支持 平台: Centos 6.3 Python: 2.7.14 代码示例: 公 ...
随机推荐
- PDO错误调试
在服务器上用PDO操作数据库,怎么都获取不到数据,query语句返回null,但是同样的代码在本地运行无误.SO,开始找bug. <?php $host='localhost'; $dbname ...
- zabbix图形乱码
毕竟是中文为主,特别是有些香项目最好以中文命名,容易区分,也方便识别 环境: centos7.3安装zabbix3.2 问题: 图文乱码问题 原理上只要找到对应的字符集,在修改配置文件 windows ...
- 【转】c++ 获取程序运行时间
转自:http://blog.csdn.net/ghevinn/article/details/22800059 DWORD start_time=GetTickCount(); {...} DWOR ...
- awk运用
awk编程: 1. 变量: 在awk中变量无须定义即可使用,变量在赋值时即已经完成了定义.变量的类型可以是数字.字符串.根据使用的不同,未初始化变量的值为0或空白字符串" ",这主 ...
- Object对象和function对象
Obejct对象 1.ECMAScript 中的 Object 对象与 Java 中的 java.lang.Object 相似. 2.ECMAScript中的所有对象都由Object对象继承而来,Ob ...
- javase学习小结二
三角函数方法 Math.sin(radians):Math.sin(Math.PI/6)=0.5 Math.cos(radians):Math.cos(Math.PI/3)=0.5 Math.tan( ...
- 浏览器通过file://访问文件和通过http://访问文件有什么区别
1.file协议用于访问本地计算机中的文件,就如同在Windows资源管理器中打开文件一样,注意它是针对本地(本机)的,简单来说,file协议是访问你本机的文件资源.http访问本地HTML,是在本地 ...
- 为MySQL选择合适的备份方式[转]
原文链接:http://nettedfish.sinaapp.com/blog/2013/05/31/choose-suitable-backup-strategy-for-mysql/ 数据库的备份 ...
- HDU 4349 Xiao Ming's Hope [Lucas定理 二进制]
这种题面真是够了......@小明 题意:the number of odd numbers of C(n,0),C(n,1),C(n,2)...C(n,n). 奇数...就是mod 2=1啊 用Lu ...
- 自兴人工智能------------python入门基础(2)列表和元祖
一.通用序列操作: 列表中所有序列都可以进行特定的操作,包括索引(indexing).分片(slicing).序列相加(adding).乘法,成员资格,长度,最小值,最大值,下面会一一介绍这些操作法. ...