python---协程 学习笔记
协程
协程又称为微线程,协程是一种用户态的轻量级线程
协程拥有自己的寄存器和栈。协程调度切换的时候,将寄存器上下文和栈都保存到其他地方,在切换回来的时候,恢复到先前保存的寄存器上下文和栈,因此:协程能保留上一次调用状态,每次过程重入时,就相当于进入上一次调用的状态。
协程的好处:
1.无需线程上下文切换的开销(还是单线程)
2.无需原子操作(一个线程改一个变量,改一个变量的过程就可以称为原子操作)的锁定和同步的开销
3.方便切换控制流,简化编程模型
4.高并发+高扩展+低成本:一个cpu支持上万的协程都没有问题,适合用于高并发处理
缺点:
1.无法利用多核的资源,协程本身是个单线程,它不能同时将单个cpu的多核用上,协程需要和进程配合才能运用到多cpu上(协程是跑在线程上的)
2.进行阻塞操作时会阻塞掉整个程序:如io
使用yield实现协程的例子:
import time
import queue
def consumer(name):
print("---->start eating baozi......")
while True:
#yield默认可以返回数据,走到yield整个程序返回,yield被唤醒的时候还可以接收数据
#进入死循环碰到yield暂停,被唤醒的时候才执行print
new_baozi = yield
print("[%s] is eating baozi %s" %(name,new_baozi))
#time.sleep(2)
def producer():
#__next__()调用消费者的next,consumer直接调用的话,第一次不会执行,会变成一个生成器
#函数如果里面有yield第一次加括号调用,他是一个生成器,还没有真正执行,__next__()才会执行
r = con.__next__()
r = con2.__next__()
n = 0
while n<5:
n += 1
#send有两个作用:唤醒生成器的同时,传送一个值,传的这个值就是yield接收到的值new_baozi
con.send(n)
con2.send(n)
#time.sleep(1)
print("\033[32;1m[producer]\033[0m is making baozi %s" %n) if __name__ == '__main__':
con = consumer("c1")
con2 = consumer("c2")
p = producer()
整个就是通过yield实现的一个简单的协程,在程序运行过程中,直接完成运作,感觉像多并发的效果。
问题:他们好像能够实现多并发的效果,是因为每一个生产者没有任何的sleep,如果在producer中加一个time.sleep(1),那么运行速度就变慢了。
遇到io操作就切换,io操作很耗时,协程之所以能够处理大并发,就是把io操作去除,之后就变成这个程序只有cpu在切换
如何实现程序自动检测io操作完成:
greenlet
from greenlet import greenlet
def tesst1():
print(12)
gr2.switch()
print(34)
gr2.switch()
def tesst2():
print(56)
gr1.switch()
print(78)
gr1 = greenlet(tesst1)#启动一个协程
gr2 = greenlet(tesst2)
gr1.switch()#手动切换
运行结果:

greenlet现在还是手动切换
gevent
Gevent是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet,它是以c扩展模块形式接入python的轻量级协程。Greenlet全部运行在主程序操作系统进程的内部,但他们被协作式的调度
import gevent
def foo():
print("Running in foo")
gevent.sleep(2)
print("Explicit context switch to foo again") def bar():
print("Explicit context to bar")
gevent.sleep(1)
print("Implicit context to switch back to bar") gevent.joinall(
[
gevent.spawn(foo),
gevent.spawn(bar),
]
)
运行结果:

运行整个也就运行了2秒,模拟io操作
下面我们做一个简单的小爬虫:
from urllib.request import urlopen
import gevent,time
def f(url):
print("GET: %s "%url)
resp = urlopen(url)
data = resp.read()
print("%d bytes received from %s." %(len(data),url))
urls = [
'https://www.python.org/',
'https://www.yahoo.com/',
'https://github.com/'
]
time_start = time.time()
for url in urls:
f(url)
print("同步cost",time.time()-time_start) async_time_start = time.time() gevent.joinall([
gevent.spawn(f,'https://www.python.org/'),
gevent.spawn(f,'https://www.yahoo.com/'),
gevent.spawn(f,'https://github.com/')
])
print("异步cost",time.time()-time_start)
用了同步和异步两种方式来进行网页的爬取,但是结果却是同步的比异步的用的时间还要短,我们之前用了gevent.sleep(1)来模拟io操作,顺便就完成了执行任务。原因是:gevent调用urllib默认是堵塞的,gevent检测不到urllib的io操作,所以不会进行切换,所以还是串行运行。
那怎么才能够让gevent知道urllib是io操作呢,要用到一个模块monkey
from urllib.request import urlopen
import gevent,time
from gevent import monkey
monkey.patch_all()#把当前程序的所有io操作单独的坐上标记
def f(url):
print("GET: %s "%url)
resp = urlopen(url)
data = resp.read()
print("%d bytes received from %s." %(len(data),url))
urls = [
'https://www.python.org/',
'https://www.yahoo.com/',
'https://github.com/'
]
time_start = time.time()
for url in urls:
f(url)
print("同步cost",time.time()-time_start) async_time_start = time.time() gevent.joinall([
gevent.spawn(f,'https://www.python.org/'),
gevent.spawn(f,'https://www.yahoo.com/'),
gevent.spawn(f,'https://github.com/')
])
print("异步cost",time.time()-async_time_start)
这样就异步爬取的速度瞬间快了很多
下面我们在利用gevent写一个socket服务器端和客户端:
服务器端:
import sys,socket,time,gevent from gevent import socket,monkey
monkey.patch_all() def server(port):
s = socket.socket()
s.bind(('0.0.0.0',port))
s.listen(500)
while True:
cli,addr = s.accept()
gevent.spawn(handle_request,cli)
def handle_request(conn):
try:
while True:
data = conn.recv(1024)
print("recv:",data)
conn.send(data)
if not data:
conn.shutdown(socket.SHUT_WR)
except Exception as e:
print(e)
finally:
conn.close() if __name__ == '__main__':
server(8001)
和socketserver差不多,处理数据都是在handle_request函数中,然后在server中建立一个gevent
客户端:
import socket
HOST = 'localhost'
PORT = 8001
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect((HOST,PORT))
while True:
msg = bytes(input(">>>:"),encoding="utf-8")
s.sendall(msg)
data = s.recv(1024)
#repr格式化输出
print("Recv:",repr(data))
s.close()
运行结果:
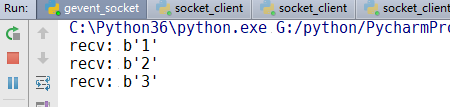
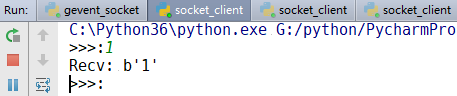

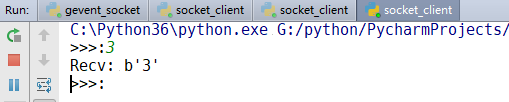
由上面几个运行结果可以知道:我们已经实行了并发运行,不需要使用什么多线程。我们用协程,遇到io就阻塞
我们现在实现了切换,但是我们是什么时候切换回来呢,我们怎么知道什么时候这个函数的东西执行完,切换到原函数呢
事件驱动与异步IO
通常,我们写服务器处理模型的程序时,有一下几个模型:
1.每收到一个请求,创建一个新的进程,来处理改请求:如socketserver
2.每收到一个请求,创建一个新的线程,来处理该请求:如socketserver
3.每收到一个请求,放入一个事件列表,让主进程通过非阻塞I/O方式来处理请求,即事件驱动的模式,该模式是大多数网络服务器采用的方式
在ui编程中,我们常常要对鼠标点击进行相应的反应,我们怎么获得鼠标点击呢?
目前大部分的UI编程都是事件驱动模型,如很多的ui平台都会提供onclick()事件,这个事件就代表了鼠标按下的事件。事件驱动模型大体思路:
1.有一个事件队列
2.鼠标按下时,往这个队列中增加一个点击事件
3.有个循环,不断的从队列中取出事件,根据不同的事件,调用不同 的函数,如:onclick(),onkeydown()等
4.事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数
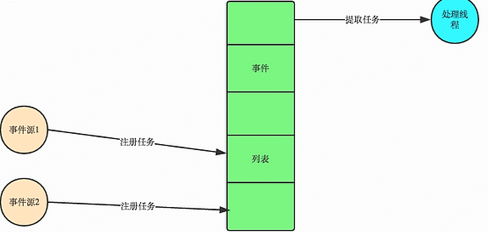
那我们在回到上面的问题,io什么时候切换回来。我们可以注册一个回调函数,回调函数就是当你的程序一遇到io操作,就切换,然后等着io操作结束又切换回来。io操作是操作系统完成的。就是通过这个事件驱动。
写的不是太好,希望大家多多包涵QAQ
python---协程 学习笔记的更多相关文章
- python 协程学习
协程 协程,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来 ...
- python 线程 进程 协程 学习
转载自大神博客:http://www.cnblogs.com/aylin/p/5601969.html 仅供学习使用···· python 线程与进程简介 进程与线程的历史 我们都知道计算机是由硬件和 ...
- day-5 python协程与I/O编程深入浅出
基于python编程语言环境,重新学习了一遍操作系统IO编程基本知识,同时也学习了什么是协程,通过实际编程,了解进程+协程的优势. 一.python协程编程实现 1. 什么是协程(以下内容来自维基百 ...
- Python协程(真才实学,想学的进来)
真正有知识的人的成长过程,就像麦穗的成长过程:麦穗空的时候,麦子长得很快,麦穗骄傲地高高昂起,但是,麦穗成熟饱满时,它们开始谦虚,垂下麦芒. --蒙田<蒙田随笔全集> *** 上篇论述了关 ...
- Python协程与Go协程的区别二
写在前面 世界是复杂的,每一种思想都是为了解决某些现实问题而简化成的模型,想解决就得先面对,面对就需要选择角度,角度决定了模型的质量, 喜欢此UP主汤质看本质的哲学科普,其中简洁又不失细节的介绍了人类 ...
- python协程详解,gevent asyncio
python协程详解,gevent asyncio 新建模板小书匠 #协程的概念 #模块操作协程 # gevent 扩展模块 # asyncio 内置模块 # 基础的语法 1.生成器实现切换 [1] ...
- 5分钟完全掌握Python协程
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 1. 协程相关的概念 1.1 进程和线程 进程(Process)是应用程序启动的实例,拥有代码.数据 ...
- Python协程与JavaScript协程的对比
前言 以前没怎么接触前端对JavaScript 的异步操作不了解,现在有了点了解一查,发现 python 和 JavaScript 的协程发展史简直就是一毛一样! 这里大致做下横向对比和总结,便于对这 ...
- Requests:Python HTTP Module学习笔记(一)(转)
Requests:Python HTTP Module学习笔记(一) 在学习用python写爬虫的时候用到了Requests这个Http网络库,这个库简单好用并且功能强大,完全可以代替python的标 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- Django App(一) StartApp
经过配置Pycharm在上一次的笔记中,已经解决了编写Django web程序调试的问题,这篇将记录Django官网提供的例子程序! 1.查看Pycharm terminal是否可用 ...
- Spider_Man_3 の selenium
一:介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作, ...
- 我的第一个python web开发框架(20)——产品发布(部署到服务器)
首先按上一章节所讲述的,将服务器环境安装好以后,接下来就是按步骤将网站部署到服务器上了. 我们的站点是前后端分离的,所以需要部署两个站点.首先来发布前端站点. 部署前端站点 输入命令进入svn管理文件 ...
- MLlib--SVD算法
转载请标明出处http://www.cnblogs.com/haozhengfei/p/4db529fa9f4c042673c6dc8218251f6c.html SVD算法 1.1什么是SVD? ...
- Micropython TPYBoard 智能温控小风扇资料分享
南方都下大雪了,苦逼的北方还没下雪,天寒地冻,不过这几天办公室空调开太大了就想到做一个温控小风扇,简单模型出来了.等夏天一定做一个美观精致的小风扇送给女朋友(如果有的话QAQ)话不多说直接上干货.(跪 ...
- curl说明
https://baike.baidu.com/item/curl/10098606?fr=aladdin curl是利用URL语法在命令行方式下工作的开源文件传输工具.它被广泛应用在Unix.多种L ...
- 搭建mybatis时的小问题
1.源文件中的xml文件经过编译后没有打包到classes中去,在源文件包中写的mapper文件运行时找不到. 解决办法: pom文件build下添加编译时加入xml和resource文件下的所有文件 ...
- 小白的Python之路 day5 logging模块
logging模块的特点及用法 一.概述 很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误.警告等信息输出,python的logging模块提供了标准的日志接口,你 ...
- CSS3 [attribute^=value] 选择器
设置 class 属性值以 "test" 开头的所有 div 元素的背景色: div[class^="test"] { background:#ffff00; ...
- struts异常:Caused by: Parent package is not defined: json-default - [unknown location]解决办法
问题描述: Unable to load configuration. - [unknown location] at com.opensymphony.xwork2.config.Configura ...