大数据 --> 大数据关键技术
大数据关键技术
大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性。
传统数据处理方法的不足
传统的数据采集来源单一,且存储、管理和分析数据量也相对较小,大多采用关系型数据库和并行数据仓库即可处理。对依靠并行计算提升数据处理速度方面而言,传统的并行数据库技术追求高度一致性和容错性,根据CAP理论,难以保证其可用性和扩展性。
传统的数据处理方法是以处理器为中心,而大数据环境下,需要采取以数据为中心的模式,减少数据移动带来的开销。因此传统的数据处理方法,已经不能适应大数据的需求。
大数据的处理流程
大数据的基本处理流程与传统数据处理流程并无太大差异,主要区别在于:由于大数据要处理大量、非结构化的数据,所以在各个处理环节中都可以采用MapReduce等方式进行并行处理。
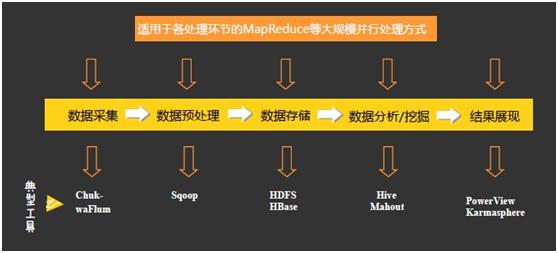
大数据技术为什么能提高数据的处理速度?
大数据的并行处理利器——MapReduce,大数据可以通过MapReduce这一并行处理技术来提高数据的处理速度。MapReduce的设计初衷是通过大量廉价服务器实现大数据并行处理,对数据一致性要求不高,其突出优势是具有扩展性和可用性,特别适用于海量的结构化、半结构化及非结构化数据的混合处理。MapReduce将传统的查询、分解及数据分析进行分布式处理,将处理任务分配到不同的处理节点,因此具有更强的并行处理能力。作为一个简化的并行处理的编程模型,MapReduce还降低了开发并行应用的门槛。
MapReduce是一套软件框架,包括Map(映射)和Reduce(化简)两个阶段,可以进行海量数据分割、任务分解与结果汇总,从而完成海量数据的并行处理。
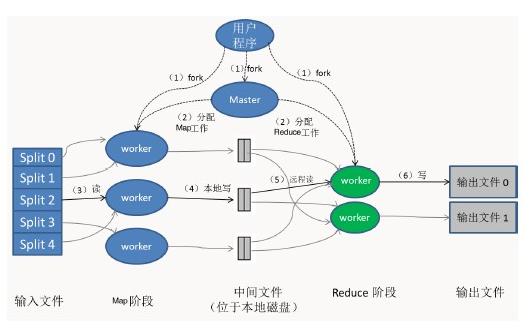
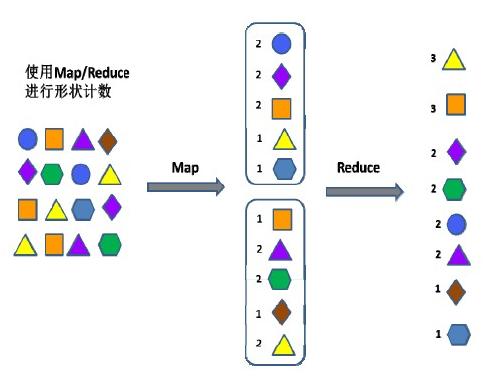
MapReduce的工作原理:其实是先分后合的数据处理方式。Map即“分解”,把海量数据分割成了若干部分,分给多台处理器并行处理;Reduce即“合并”,把各台处理器处理后的结果进行汇总操作以得到最终结果。如右图所示,如果采用MapReduce来统计不同几何形状的数量,它会先把任务分配到两个节点,由两个节点分别并行统计,然后再把它们的结果汇总,得到最终的计算结果。
MapReduce适合进行数据分析、日志分析、商业智能分析、客户营销、大规模索引等业务,并具有非常明显的效果。通过结合MapReduce技术进行实时分析,某家电公司的信用计算时间从33小时缩短到8秒,而MKI的基因分析时间从数天缩短到20分钟。
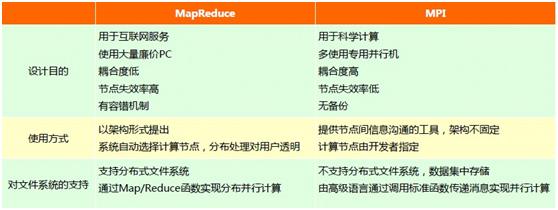
说到这里,再看一看MapReduce与传统的分布式并行计算环境MPI到底有何不同?MapReduce在其设计目的、使用方式以及对文件系统的支持等方面与MPI都有很大的差异,使其能够更加适应大数据环境下的处理需求。
大数据技术在数据采集方面采用了哪些新的方法
1)系统日志采集方法
很多互联网企业都有自己的海量数据采集工具,多用于系统日志采集,如Hadoop的Chukwa,Cloudera的Flume,Facebook的Scribe等,这些工具均采用分布式架构,能满足每秒数百MB的日志数据采集和传输需求。
2)网络数据采集方法:对非结构化数据的采集
网络数据采集是指通过网络爬虫或网站公开API等方式从网站上获取数据信息。该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联。除了网络中包含的内容之外,对于网络流量的采集可以使用DPI或DFI等带宽管理技术进行处理。
3)其他数据采集方法
对于企业生产经营数据或学科研究数据等保密性要求较高的数据,可以通过与企业或研究机构合作,使用特定系统接口等相关方式采集数据。
ref:http://blog.csdn.net/broadview2006/article/details/8124670
大数据 --> 大数据关键技术的更多相关文章
- 超级内存NVDIMM:下一代数据中心存储关键技术
1.背景介绍 连接到互联网的设备数量不断增长,到2015年,将达到150亿之多.而数据中心的压力也随之增加,唯有采用新的技术才能进一步提升其效率和性能. 相比于HDD传统硬盘,固态硬盘大大增加了I/O ...
- 医院大数据平台建设_构建医院智能BI平台的关键技术
在新技术层出不穷的当下,世界各地的组织正在以闪电般的速度变化和进化,以便在新技术可用时加以利用.其中目前最具活力的一个领域是商业智能(BI).想一想,你可能已经习惯以每周或每月IT或数据科学家交付给你 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- 自然语言处理工具HanLP被收录中国大数据产业发展的创新技术新书《数据之翼》
在12月20日由中国电子信息产业发展研究院主办的2018中国软件大会上,大快搜索获评“2018中国大数据基础软件领域领军企业”,并成功入选中国数字化转型TOP100服务商. 图:大快搜索获评“2018 ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- Hadoop! | 大数据百科 | 数据观 | 中国大数据产业观察_大数据门户
你正在使用过时的浏览器,Amaze UI 暂不支持. 请 升级浏览器 以获得更好的体验! 深度好文丨读完此文,就知道Hadoop了! 来源:BiThink 时间:2016-04-12 15:1 ...
- 解读:20大5G关键技术
解读:20大5G关键技术 5G网络技术主要分为三类:核心网.回传和前传网络.无线接入网. 核心网 核心网关键技术主要包括:网络功能虚拟化(NFV).软件定义网络(SDN).网络切片和多接入边缘计算(M ...
- 小小知识点(二十七)20大5G关键技术
5G网络技术主要分为三类:核心网.回传和前传网络.无线接入网. 核心网 核心网关键技术主要包括:网络功能虚拟化(NFV).软件定义网络(SDN).网络切片和多接入边缘计算(MEC). 1 网络功能虚拟 ...
随机推荐
- TI Davinci DM6446开发攻略——UBL移植
UBL的程序设计,相对UBOOT.KERNEL.ROOTFS.设备驱动.DSP开发来说,还是比较简单.我们先从DAVINCI的启动说起,了解UBL在DAVIN系统中的位置和作用.对于固件程序烧写在N ...
- PHP simpleXML文件编程
SimpleXML simpleXML该技术的核心思想是以面向对象的方式来操作xml文件 <?php //simplexml文件 讲所有的元素转成对象 $library=simplexml_lo ...
- VxWorks启动流程
镜像种类不同,VxWorks的启动过程会有所不同. 我们项目中使用的是加载型VxWorks镜像 函数 函数功能 所在文件 bootTask() (a) 通过createBootLineFromF ...
- Linux显示指定区块大小为1048576字节
Linux显示指定区块大小为1048576字节 youhaidong@youhaidong-ThinkPad-Edge-E545:~$ df -m 文件系统 1M-blocks 已用 可用 已用% 挂 ...
- Linux显示进程状态
Linux显示进程状态 youhaidong@youhaidong-ThinkPad-Edge-E545:~$ top top - 19:16:36 up 45 min, 2 users, load ...
- org.apache.catalina.LifecycleException: Failed to start component
1.错误描述 Using CATALINA_BASE: "D:\NetBeans\apache-tomcat-8.0.12" Using CATALINA_HOME: " ...
- ajax交互数据简单拼装,数组成字符串
json2Form:function(json) { var str = ""; for(var p in json){ // 判断对象是否为数组 if(typeof json[p ...
- python实现列表倒叙打印
def func(listNode): listNode.reverse() for i in listNode: print(i) li = [1,2,3,4,5] func(li) 利用pytho ...
- 【BZOJ1499】瑰丽华尔兹(动态规划)
[BZOJ1499]瑰丽华尔兹(动态规划) 题面 BZOJ 题解 先写部分分 设\(f[t][i][j]\)表示当前在\(t\)时刻,位置在\(i,j\)时走的最多的步数 这样子每一步要么停要么走 时 ...
- 【BZOJ2599】Race(点分治)
[BZOJ2599]Race(点分治) 题面 BZOJ权限题,洛谷 题解 好久没写过点分治了... 在ppl的帮助下终于想起来了 orz ppl 首先回忆一下怎么求有没有正好是\(K\)的路径 维护一 ...