5分钟spark streaming实践之 与kafka联姻
你:kafka是什么?
我:嗯,这个嘛。。看官网。
Apache Kafka® is a distributed streaming platform
Kafka is generally used for two broad classes of applications: Building real-time streaming data pipelines that reliably get data between systems or applications,Building real-time streaming applications that transform or react to the streams of data
你:我虽然英语很好,但是请你用中文回答嘛,或者自己的语言。
我:好,翻译下,kafka很牛
你:哎,你这个水平,我走了。。。
我:别,我是认真严肃的,用数据说话,看图,spark和kafka都是属于上升趋势,此图来源:
https://trends.google.com/trends/explore?date=all&q=%2Fm%2F0fdjtq,%2Fm%2F0ndhxqz,%2Fm%2F0zmynvd

你:还是没有回答我的问题,kafka可以做什么?
我:问题真多,本系列风格是做,做,做,优雅地说实践,要想找答案,请移步官网。
5分钟目标
练习spark 与kafka集成的API,要求和上次一样,必须可以任意地在浏览器中码代码和运行。
简单啊,和上次那个流程一样开始, 但是,等等,我有一个一千万的想法,就差个程序员帮我实现,哦 错了,不是差个程序员,是差个kafka集群,我这个本地怎么setup呢?
先来个OverView:

图中大致给出了一次执行流程,其中的每个组件都是个很大的topic,一般公司中有专门的团队在维护或者二次开发,本博客只是搭建一个可以学习,能够work的pipeline,还有我们的目标是学习spark api,以此能够运用相关业务中,所以各个组件搭建不是重点。
以下不算在5分钟里面(环境搭建是一次性的工作,开发是个无限迭代循环)
浏览器,zeppelin,spark 这部分昨天的5分钟里面已经完成,所以剩下的就是本地搭建个kafka cluster了。
kafka cluster setup ,the easier way https://github.com/wurstmeister/kafka-docker
1.git clone https://github.com/wurstmeister/kafka-docker.git
2.修改KAFKA_ADVERTISED_HOST_NAME in docker-compose.yml 为你本机
3. docker-compose up -d
看到这三步就可以完成,是不是很欣慰? 哈,少年,难道你不知道有墙?反正我是用代理才搞定的,时间也是发了半上午。
不要问我git ,docker-compose 是什么鬼? 不懂请自行google。
还是不行,要不你试试kafka官网自行安装?
好吧,5分钟到底想做什么?
1.kafka 的某个topic stream里面存的是些因为句子比如(spark is fun)
2.spark实时的读取这个topic,不断的计算句子中词的次数,所以结果就是,(spark,1),(is,1),(fun,1)
开始计时:
1. docker run -p 8080:8080 --name zeppelin fancyisbest/zeppeinsparkstreaming:0.2
2.进入http://localhost:8080/, 找到kafka integration notebook
3. 修改bootstrap server 参数, 运行代码, bingo,完成上图:
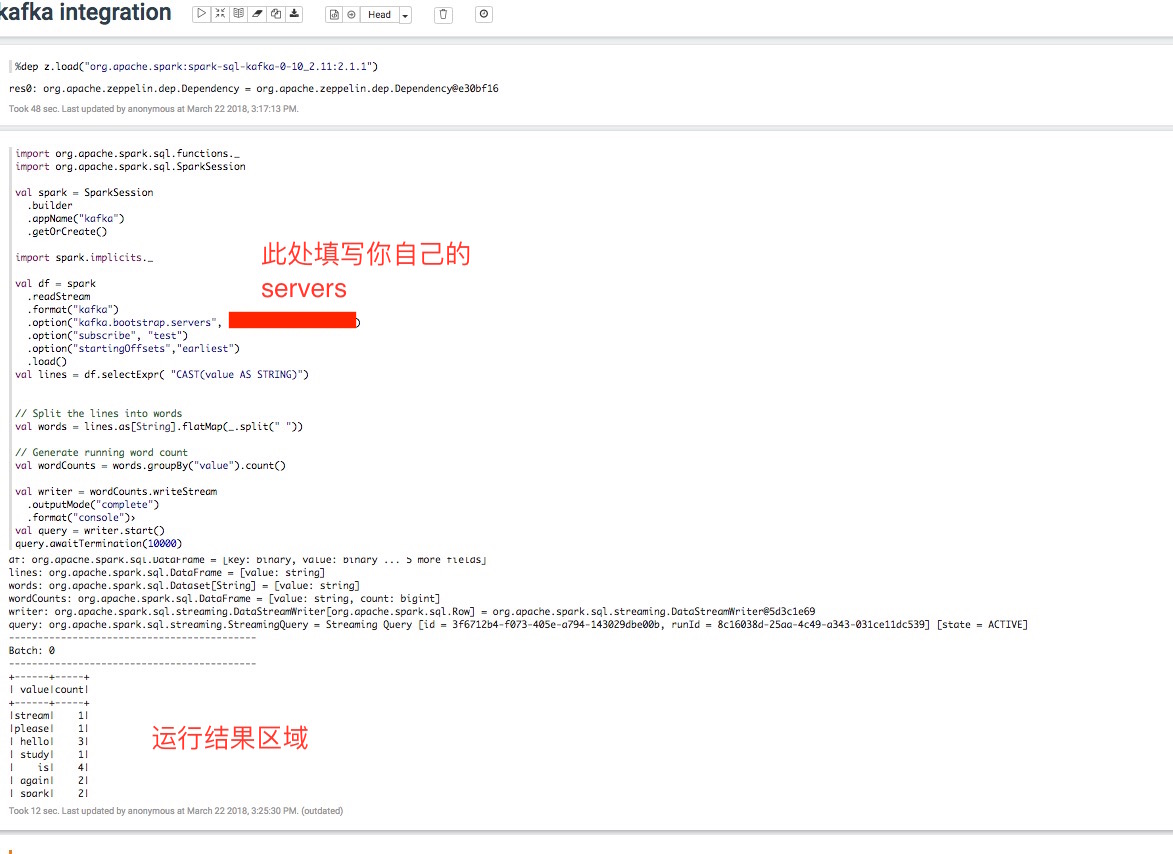
5分钟,这算是作弊吗?
我们的目标是探索spark 和integration的API,你在notebook里面可以尝试各种不同参数组合和不同的API,或者实现到不同的业务逻辑,别的费时间工作要么是一次性的,我准备好的模版代码也是让你能尽快运行起来。
什么?你没有得到结果?
注意啊,我省了向kafka里面创建topic,插入数据这些步骤,以下命令提供参考完成这些动作
1.进入kafka 容器,docker exec -it c81907e90cc2 /bin/bash
2.创建topic : kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic test
3.向topic写入数据:kafka-console-producer.sh --broker-list localhost:9092 --topic test
还有什么问题吗?请留言,期待与你共同学习与探讨
后续: 见证 exactly once语义。
参考:
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
https://kafka.apache.org/
https://github.com/wurstmeister/kafka-docker
5分钟spark streaming实践之 与kafka联姻的更多相关文章
- Spark Streaming实践和优化
发表于:<程序员>杂志2016年2月刊.链接:http://geek.csdn.net/news/detail/54500 作者:徐鑫,董西成 在流式计算领域,Spark Streamin ...
- 53、Spark Streaming:输入DStream之Kafka数据源实战
一.基于Receiver的方式 1.概述 基于Receiver的方式: Receiver是使用Kafka的高层次Consumer API来实现的.receiver从Kafka中获取的数据都是存储在Sp ...
- demo2 Kafka+Spark Streaming+Redis实时计算整合实践 foreachRDD输出到redis
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming.Spark SQL.MLlib.GraphX,这些内建库都提供了 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统(转)
原文链接:http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice2/index.html?ca=drs-&ut ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Spark Streaming + Kafka整合(Kafka broker版本0.8.2.1+)
这篇博客是基于Spark Streaming整合Kafka-0.8.2.1官方文档. 本文主要讲解了Spark Streaming如何从Kafka接收数据.Spark Streaming从Kafka接 ...
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
随机推荐
- java的mac自动化-自动运行java程序
本文旨在帮助读者介绍,如果一个测试工程师拿到了mac本,该如何在本地自动运行java代码 首先如图所示写下如下一段代码 package zlr;import org.junit.Test;public ...
- chrome使用Timeline做性能分析
使用Timeline做性能分析 Timeline面板记录和分析了web应用运行时的所有活动情况,这是研究和查找性能问题的最佳途径.###Timeline面板概览 Timeline面板主要有三个部分构成 ...
- MySQL InnoDB表压缩
MySQL InnoDB表压缩 文件大小减小(可达50%以上) ==> 查询速度变快(count * 约减少20%以上时间) 如何设置mysql innodb 表的压缩: 第一,mysql的版本 ...
- React是什么,为什么要使用它?
React是Facrbook内部的一个JavaScript类库,已于1年开源,可用于创建Web用户交互界面.它引入了一种新的方式来处理浏览器DOM.那些需要手动更新DOM.费力地记录每一个状态的日子一 ...
- java 集合框架(一)概述
一.概述 Java Collection Framework (JCF) 提供给我们一系列的类和接口,方便开发者处理集合对象. 在Java 2之前,Java是没有完整的集合框架的.它只有一些简单的可以 ...
- CSS3之Border-radius
1.属性介绍 border-radius:none|12.3px,取值不可为负数,表示边框圆角 相关属性:border-top-right-radius , border-bottom-right-r ...
- DML 触发器2
2.行级触发器的关联标识符 :new,:old >>1. 一般通过:new.filed 引用(filed是trigger_table的字段名) :new :old中filed字段的意义 触 ...
- Hibernate【映射】知识要点
前言 前面的我们使用的是一个表的操作,但我们实际的开发中不可能只使用一个表的...因此,本博文主要讲解关联映射 集合映射 需求分析:当用户购买商品,用户可能有多个地址. 数据库表 我们一般如下图一样设 ...
- Redis总结(七)Redis运维常用命令
redis 服务器端命令 redis 127.0.0.1:6380> time ,显示服务器时间 , 时间戳(秒), 微秒数 1) "1375270361" 2) &quo ...
- 【CF245H】Queries for Number of Palindromes(回文树)
[CF245H]Queries for Number of Palindromes(回文树) 题面 洛谷 题解 回文树,很类似原来一道后缀自动机的题目 后缀自动机那道题 看到\(n\)的范围很小,但是 ...