5分钟spark streaming实践之 与kafka联姻
你:kafka是什么?
我:嗯,这个嘛。。看官网。
Apache Kafka® is a distributed streaming platform
Kafka is generally used for two broad classes of applications: Building real-time streaming data pipelines that reliably get data between systems or applications,Building real-time streaming applications that transform or react to the streams of data
你:我虽然英语很好,但是请你用中文回答嘛,或者自己的语言。
我:好,翻译下,kafka很牛
你:哎,你这个水平,我走了。。。
我:别,我是认真严肃的,用数据说话,看图,spark和kafka都是属于上升趋势,此图来源:
https://trends.google.com/trends/explore?date=all&q=%2Fm%2F0fdjtq,%2Fm%2F0ndhxqz,%2Fm%2F0zmynvd

你:还是没有回答我的问题,kafka可以做什么?
我:问题真多,本系列风格是做,做,做,优雅地说实践,要想找答案,请移步官网。
5分钟目标
练习spark 与kafka集成的API,要求和上次一样,必须可以任意地在浏览器中码代码和运行。
简单啊,和上次那个流程一样开始, 但是,等等,我有一个一千万的想法,就差个程序员帮我实现,哦 错了,不是差个程序员,是差个kafka集群,我这个本地怎么setup呢?
先来个OverView:

图中大致给出了一次执行流程,其中的每个组件都是个很大的topic,一般公司中有专门的团队在维护或者二次开发,本博客只是搭建一个可以学习,能够work的pipeline,还有我们的目标是学习spark api,以此能够运用相关业务中,所以各个组件搭建不是重点。
以下不算在5分钟里面(环境搭建是一次性的工作,开发是个无限迭代循环)
浏览器,zeppelin,spark 这部分昨天的5分钟里面已经完成,所以剩下的就是本地搭建个kafka cluster了。
kafka cluster setup ,the easier way https://github.com/wurstmeister/kafka-docker
1.git clone https://github.com/wurstmeister/kafka-docker.git
2.修改KAFKA_ADVERTISED_HOST_NAME in docker-compose.yml 为你本机
3. docker-compose up -d
看到这三步就可以完成,是不是很欣慰? 哈,少年,难道你不知道有墙?反正我是用代理才搞定的,时间也是发了半上午。
不要问我git ,docker-compose 是什么鬼? 不懂请自行google。
还是不行,要不你试试kafka官网自行安装?
好吧,5分钟到底想做什么?
1.kafka 的某个topic stream里面存的是些因为句子比如(spark is fun)
2.spark实时的读取这个topic,不断的计算句子中词的次数,所以结果就是,(spark,1),(is,1),(fun,1)
开始计时:
1. docker run -p 8080:8080 --name zeppelin fancyisbest/zeppeinsparkstreaming:0.2
2.进入http://localhost:8080/, 找到kafka integration notebook
3. 修改bootstrap server 参数, 运行代码, bingo,完成上图:
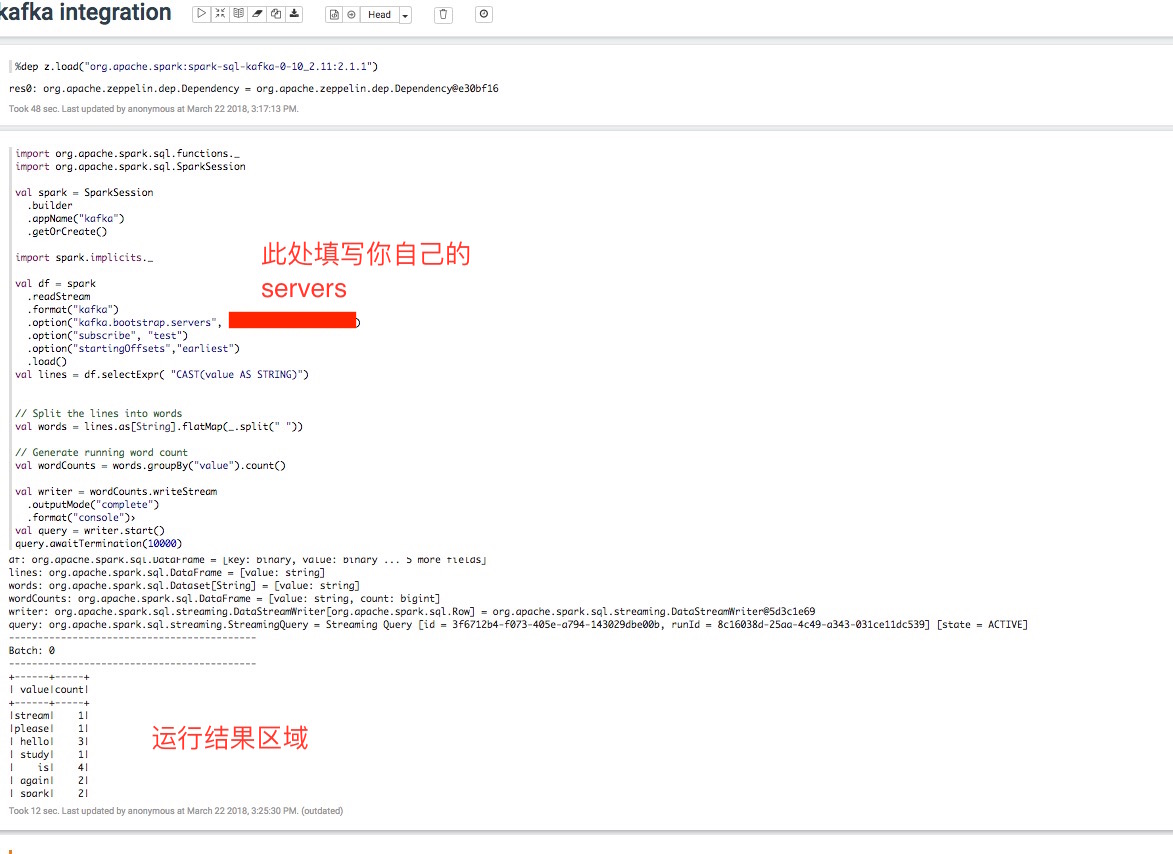
5分钟,这算是作弊吗?
我们的目标是探索spark 和integration的API,你在notebook里面可以尝试各种不同参数组合和不同的API,或者实现到不同的业务逻辑,别的费时间工作要么是一次性的,我准备好的模版代码也是让你能尽快运行起来。
什么?你没有得到结果?
注意啊,我省了向kafka里面创建topic,插入数据这些步骤,以下命令提供参考完成这些动作
1.进入kafka 容器,docker exec -it c81907e90cc2 /bin/bash
2.创建topic : kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic test
3.向topic写入数据:kafka-console-producer.sh --broker-list localhost:9092 --topic test
还有什么问题吗?请留言,期待与你共同学习与探讨
后续: 见证 exactly once语义。
参考:
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
https://kafka.apache.org/
https://github.com/wurstmeister/kafka-docker
5分钟spark streaming实践之 与kafka联姻的更多相关文章
- Spark Streaming实践和优化
发表于:<程序员>杂志2016年2月刊.链接:http://geek.csdn.net/news/detail/54500 作者:徐鑫,董西成 在流式计算领域,Spark Streamin ...
- 53、Spark Streaming:输入DStream之Kafka数据源实战
一.基于Receiver的方式 1.概述 基于Receiver的方式: Receiver是使用Kafka的高层次Consumer API来实现的.receiver从Kafka中获取的数据都是存储在Sp ...
- demo2 Kafka+Spark Streaming+Redis实时计算整合实践 foreachRDD输出到redis
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming.Spark SQL.MLlib.GraphX,这些内建库都提供了 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统(转)
原文链接:http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice2/index.html?ca=drs-&ut ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Spark Streaming + Kafka整合(Kafka broker版本0.8.2.1+)
这篇博客是基于Spark Streaming整合Kafka-0.8.2.1官方文档. 本文主要讲解了Spark Streaming如何从Kafka接收数据.Spark Streaming从Kafka接 ...
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
随机推荐
- 计蒜客的一道题dfs
这是我无聊时在计蒜客发现的一道题. 题意: 蒜头君有一天闲来无事和小萌一起玩游戏,游戏的内容是这样的:他们不知道从哪里找到了N根不同长度的木棍, 看谁能猜出这些木棍一共能拼出多少个不同的不等边三角形. ...
- uva211 回溯
大致题意:每个多米诺骨牌可能横着,也可能竖着,请你判断有哪些合法的摆放方式. 这题的dfs需要注意一下,不能以某个点直接开始延伸,如果这样延伸可能会无法到达终点(也就是遍历全图).我的dfs方法就是枚 ...
- 关于 target="_blank"漏洞的分析
创建: 于 八月 30, 2016 关于 target="_blank"漏洞的分析 一.漏洞详情:首先攻击者能够将链接(指向攻击者自己控制的页面的,该被控页面的js脚本可以对母页 ...
- RTLinux编程总结
做过一个有关RTLinux的项目,时间一长,差不多忘光了,现在尽量把原来做过的东西总结一下,以备后用,同时正在做类似项目的一个借鉴平台主机:redhat 8.0目标机:PC104模块.ISA总线脉冲输 ...
- Android(Java)利用findbugs进行代码静态检查
主要介绍利用java静态代码检查工具findbugs进行代码检查,包括其作用.安装.使用.高级功能(远程review和bug同步). 虽然Android提供了Test Project工程以及instr ...
- 【linux】mysql安装问题 g++: not found
问题现象: ../depcomp: line 512: exec: g++: not foundmake[2]: *** [my_new.o] Error 127make[2]: Leaving di ...
- 利用Java API生成50到100之间的随机数
利用Java API生成50到100之间的随机数 /** * */ package com.you.demo; import java.util.Random; /** * @author Admin ...
- Java代码输出是“father”还是“child”(一)
1.实例 /** * 以下代码输出的结果是 */ package com.you.model; /** * @author YouHaidong * 输出的结果 */ public class Fat ...
- day8(字符串操作)
一.字符串操作 1.index #返回字符串的索引值 s = "Hello word" print(s.index('o')) 2.isalnum #检测字符串是否由字母和数字组 ...
- 描述Spring Web MVC的工作流程
Spring Web MVC的共工作流程如下: 1.浏览器发出Spring mvc请求,请求给前端控制器 DispatcherServlet处理. 2.控制器通过HandlerMapping维护的请求 ...