【Spark2.0源码学习】-9.Job提交与Task的拆分
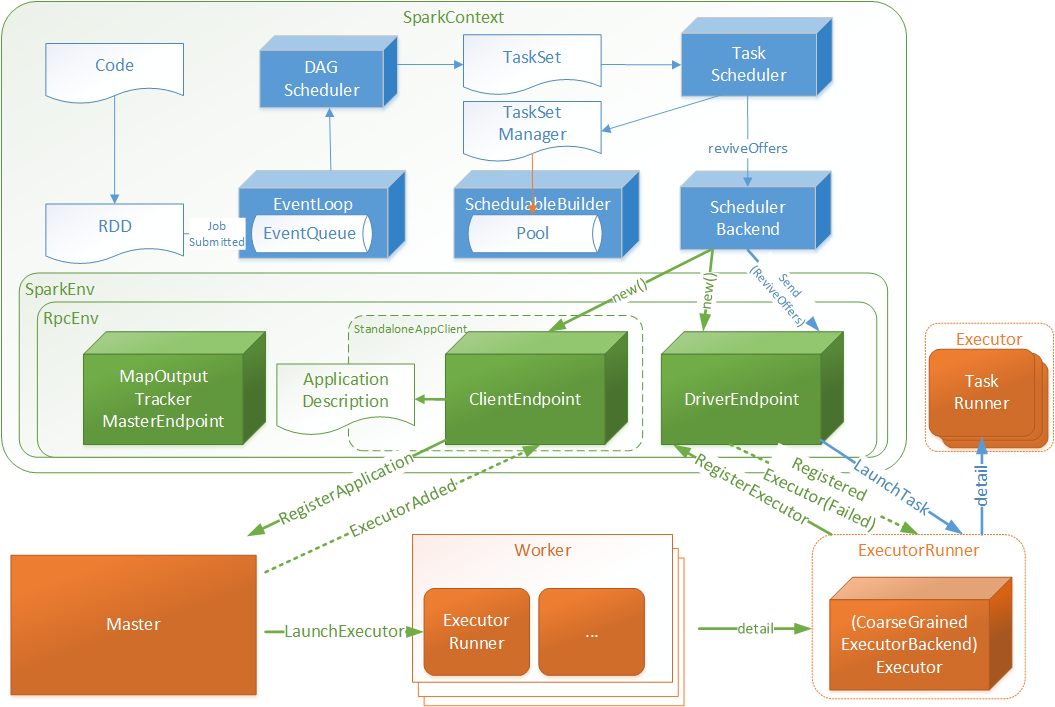
.png)
- Code:指的用户编写的代码
- RDD:弹性分布式数据集,用户编码根据SparkContext与RDD的api能够很好的将Code转化为RDD数据结构(下文将做转化细节介绍)
- DAGScheduler:有向无环图调度器,将RDD封装为JobSubmitted对象存入EventLoop(实现类DAGSchedulerEventProcessLoop)队列中
- EventLoop: 定时扫描未处理JobSubmitted对象,将JobSubmitted对象提交给DAGScheduler
- DAGScheduler:针对于JobSubmitted进行处理,最终将RDD转化为执行TaskSet,并将TaskSet提交至TaskScheduler
- TaskScheduler: 根据TaskSet创建TaskSetManager对象存入SchedulableBuilder的数据池(Pool)中,并调用DriverEndpoint唤起消费(ReviveOffers)操作
- DriverEndpoint:接受ReviveOffers指令后将TaskSet中的Tasks根据相关规则均匀分配给Executor
- Executor:启动一个TaskRunner执行一个Task
.png)
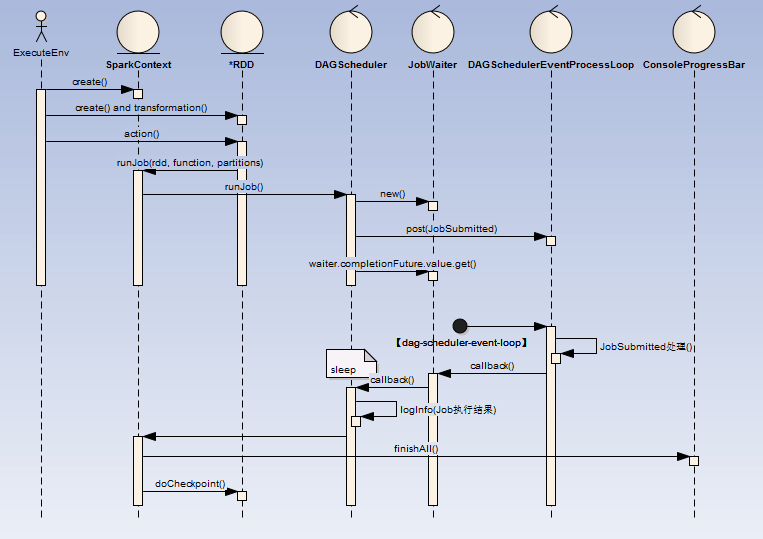
- ExecuteEnv(执行环境 )
- 这里可以是通过spark-submit提交的MainClass,也可以是spark-shell脚本
- MainClass : 代码中必定会创建或者获取一个SparkContext
- spark-shell:默认会创建一个SparkContext
- RDD(弹性分布式数据集)
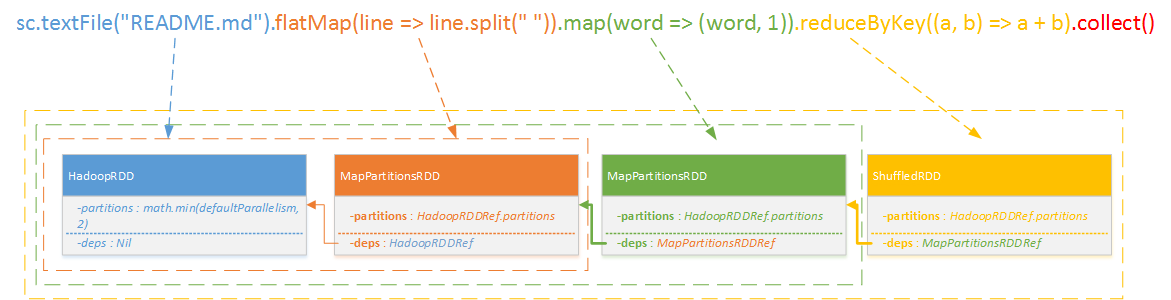
- create:可以直接创建(如:sc.parallelize(1 until n, slices) ),也可以在其他地方读取(如:sc.textFile("README.md"))等
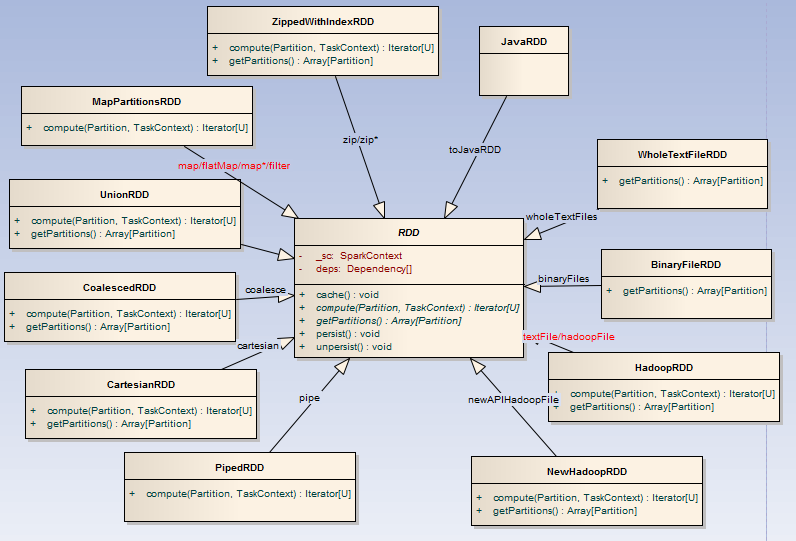
- transformation:rdd提供了一组api可以进行对已有RDD进行反复封装成为新的RDD,这里采用的是装饰者设计模式,下面为部分装饰器类图
.png)
- action:当调用RDD的action类操作方法时(collect、reduce、lookup、save ),这触发DAGScheduler的Job提交
- DAGScheduler:创建一个名为JobSubmitted的消息至DAGSchedulerEventProcessLoop阻塞消息队列(LinkedBlockingDeque)中
- DAGSchedulerEventProcessLoop:启动名为【dag-scheduler-event-loop】的线程实时消费消息队列
- 【dag-scheduler-event-loop】处理完成后回调JobWaiter
- DAGScheduler:打印Job执行结果
- JobSubmitted:相关代码如下(其中jobId为DAGScheduler全局递增Id):
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
- 最终示例:
.png)
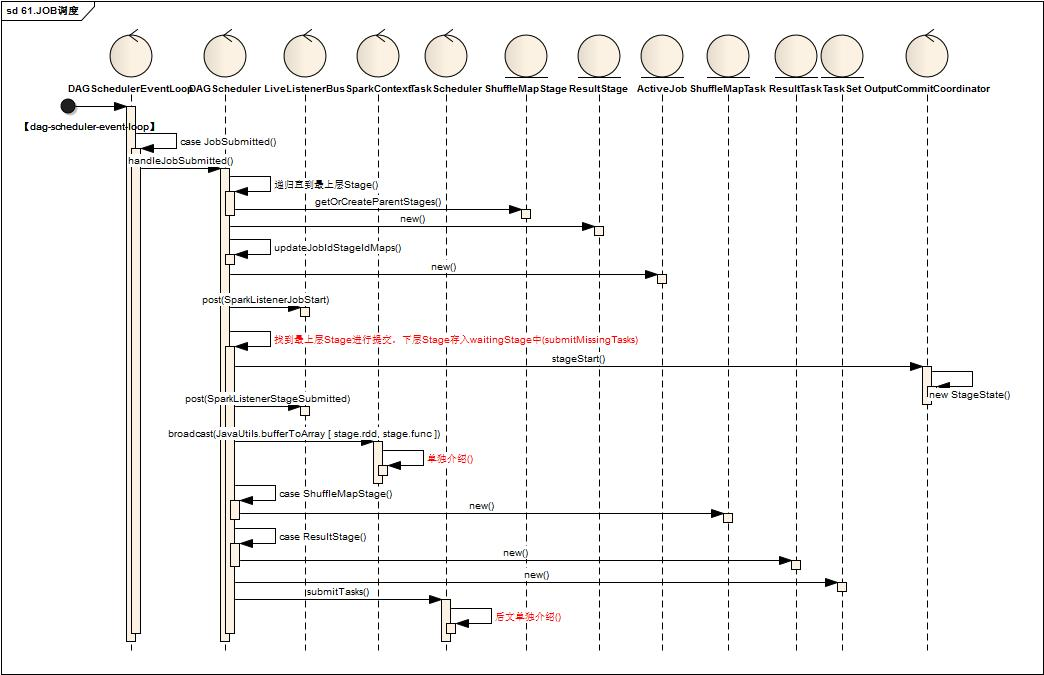

- DAGSchedulerEventProcessLoop中,线程【dag-scheduler-event-loop】处理到JobSubmitted
- 调用DAGScheduler进行handleJobSubmitted
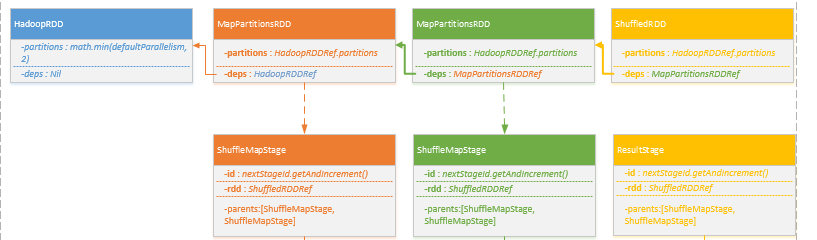
- 首先根据RDD依赖关系依次创建Stage族,Stage分为ShuffleMapStage,ResultStage两类
.png)
- 更新jobId与StageId关系Map
- 创建ActiveJob,调用LiveListenerBug,发送SparkListenerJobStart指令
- 找到最上层Stage进行提交,下层Stage存入waitingStage中待后续处理
- 调用OutputCommitCoordinator进行stageStart()处理
- 调用LiveListenerBug, 发送 SparkListenerStageSubmitted指令
- 调用SparkContext的broadcast方法获取Broadcast对象
- 根据Stage类型创建对应多个Task,一个Stage根据findMissingPartitions分为多个对应的Task,Task分为ShuffleMapTask,ResultTask
.png)
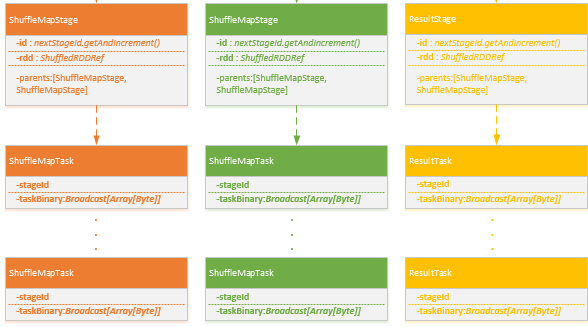
- 将Task封装为TaskSet,调用TaskScheduler.submitTasks(taskSet)进行Task调度,关键代码如下:
- 首先根据RDD依赖关系依次创建Stage族,Stage分为ShuffleMapStage,ResultStage两类
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
.png)
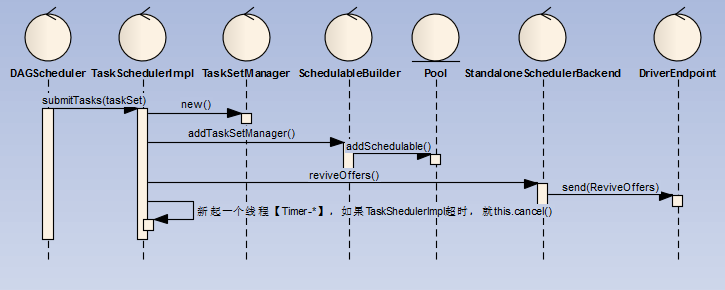
- DAGSheduler将TaskSet提交给TaskScheduler的实现类,这里是TaskChedulerImpl
- TaskSchedulerImpl创建一个TaskSetManager管理TaskSet,关键代码如下:
new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt)
- 同时将TaskSetManager添加SchedduableBuilder的任务池Poll中
- 调用SchedulerBackend的实现类进行reviveOffers,这里是standlone模式的实现类StandaloneSchedulerBackend
- SchedulerBackend发送ReviveOffers指令至DriverEndpoint
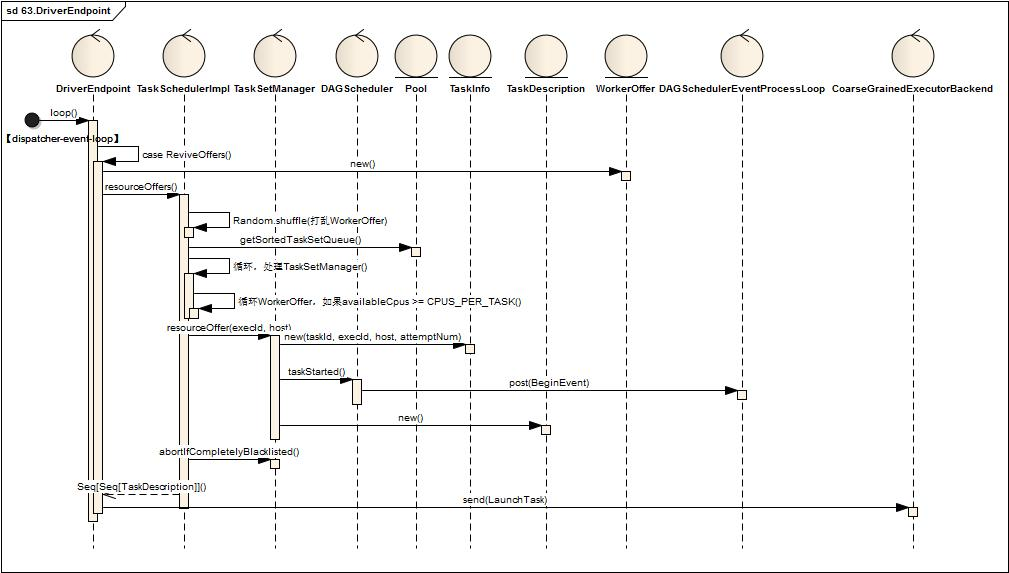

- 首先根据executorDataMap缓存信息得到可用的Executor资源信息(WorkerOffer),关键代码如下
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
- 接着调用TaskScheduler进行资源匹配,方法定义如下:
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {..}
- 将WorkerOffer资源打乱(val shuffledOffers = Random.shuffle(offers))
- 将Poo中待处理的TaskSetManager取出(val sortedTaskSets = rootPool.getSortedTaskSetQueue),
- 并循环处理sortedTaskSets并与shuffledOffers循环匹配,如果shuffledOffers(i)有足够的Cpu资源( if (availableCpus(i) >= CPUS_PER_TASK) ),调用TaskSetManager创建TaskDescription对象(taskSet.resourceOffer(execId, host, maxLocality)),最终创建了多个TaskDescription,TaskDescription定义如下:
new TaskDescription(
taskId,
attemptNum,
execId,
taskName,
index,
sched.sc.addedFiles,
sched.sc.addedJars,
task.localProperties,
serializedTask)
- 如果TaskDescriptions不为空,循环TaskDescriptions,序列化TaskDescription对象,并向ExecutorEndpoint发送LaunchTask指令,关键代码如下:
for (task <- taskDescriptions.flatten) {
val serializedTask = TaskDescription.encode(task)
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
【Spark2.0源码学习】-9.Job提交与Task的拆分的更多相关文章
- 【Spark2.0源码学习】-1.概述
Spark作为当前主流的分布式计算框架,其高效性.通用性.易用性使其得到广泛的关注,本系列博客不会介绍其原理.安装与使用相关知识,将会从源码角度进行深度分析,理解其背后的设计精髓,以便后续 ...
- spark2.0源码学习
[Spark2.0源码学习]-1.概述 [Spark2.0源码学习]-2.一切从脚本说起 [Spark2.0源码学习]-3.Endpoint模型介绍 [Spark2.0源码学习]-4.Master启动 ...
- 【Spark2.0源码学习】-2.一切从脚本说起
从脚本说起 在看源码之前,我们一般会看相关脚本了解其初始化信息以及Bootstrap类,Spark也不例外,而Spark我们启动三端使用的脚本如下: %SPARK_HOME%/sbin/st ...
- 【Spark2.0源码学习】-3.Endpoint模型介绍
Spark作为分布式计算框架,多个节点的设计与相互通信模式是其重要的组成部分. 一.组件概览 对源码分析,对于设计思路理解如下: RpcEndpoint: ...
- 【Spark2.0源码学习】-4.Master启动
Master作为Endpoint的具体实例,下面我们介绍一下Master启动以及OnStart指令后的相关工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-5.Worker启动
Worker作为Endpoint的具体实例,下面我们介绍一下Worker启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-6.Client启动
Client作为Endpoint的具体实例,下面我们介绍一下Client启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/bin/jav ...
- 【Spark2.0源码学习】-10.Task执行与回馈
通过上一节内容,DriverEndpoint最终生成多个可执行的TaskDescription对象,并向各个ExecutorEndpoint发送LaunchTask指令,本节内容将关注Exe ...
- 【Spark2.0源码学习】-7.Driver与DriverRunner
承接上一节内容,Client向Master发起RequestSubmitDriver请求,Master将DriverInfo添加待调度列表中(waitingDrivers),下面针对于Dri ...
随机推荐
- kindeditor扩展粘贴图片功能&修改图片上传路径并通过webapi上传图片到图片服务器
前言 kindeditor是一个非常好用的富文本编辑器,它的简单使用我就不再介绍了. 而kindeditor却对图片的处理不够理想. 本篇博文需要解决的问题有两个: kindeditor扩展粘贴图片功 ...
- MySQL之数据类型(常用)
MySQL-data_type数据类型 1.查看数据类型 mysql> help data type //通过help对数据进行查看,以及使用的方法 2.MySQL常见的数据类型 整数in ...
- css3 新属性
一 选择器1 兄弟选择器 0 以第一个选择器开始,往后找满足条件的兄弟节点 class~class() <-- lorem+数字 -tab --> 可以输出默认文字2 属性选择器 标签[a ...
- 跨语言学习的基本思路及python的基础学习
笔者是C#出身,大学四年主修C#,工作三年也是C#语言开发.但在学校里其他的语言也有相应的课程,eg:Java,Php,C++都学过,当然只是学了皮毛(大学嘛,你懂得),严格来说未必入门,但这些语言的 ...
- 2017-4-24 WinForm开发基础、窗体的属性CenterScreen
WinForm中文名称: Windows窗体,是·Net开发平台中对Windows Form的一种称谓. 客户端应用程序:C/S 客户端很重要的特点:可以操作用户电脑上的文件 窗体属性:窗体种类: + ...
- 读书笔记之JavaScript中的数据类型(1)
JavaScript严格意义上分为ECMAScript.DOM.BOM.ECMAScript是一门真正意义上的语言,独立于浏览器,浏览器只是它的一个宿主环境.DOM(文档对象模型),为ECMAScri ...
- 使用HTML5地理位置定位到城市的方法及注意事项
介绍 本文将简述一下如何通过HTML5和百度地图开放平台提供的API来实现对浏览器的定位.实现效果为显示出用户所在的省市,即: XXX省 XXX市. 实现思路 利用HTML5 提供的API获取到用户的 ...
- APP反编译第一课《如何找到核心代码》
相信很多人都应该会去接触APP反编译,本小七给大家带来入门级别套路,自己也在慢慢摸索学习,一起成长吧.第一步,反编译需要的工具有:一.java环境,其实这里你只要安装了burp就不用管这个的二.apk ...
- hdu4185二分图匹配
Thanks to a certain "green" resources company, there is a new profitable industry of oil s ...
- hdu2819二分图匹配
Given an N*N matrix with each entry equal to 0 or 1. You can swap any two rows or any two columns. C ...