机器学习 —— 类不平衡问题与SMOTE过采样算法
在前段时间做本科毕业设计的时候,遇到了各个类别的样本量分布不均的问题——某些类别的样本数量极多,而有些类别的样本数量极少,也就是所谓的类不平衡(class-imbalance)问题。
本篇简述了以下内容:
什么是类不平衡问题
为什么类不平衡是不好的
几种解决方案
SMOTE过采样算法
进一步阅读
什么是类不平衡问题
类不平衡(class-imbalance)是指在训练分类器中所使用的训练集的类别分布不均。比如说一个二分类问题,1000个训练样本,比较理想的情况是正类、负类样本的数量相差不多;而如果正类样本有995个、负类样本仅5个,就意味着存在类不平衡。
在后文中,把样本数量过少的类别称为“少数类”。
但实际上,数据集上的类不平衡到底有没有达到需要特殊处理的程度,还要看不处理时训练出来的模型在验证集上的效果。有些时候是没必要处理的。
为什么类不平衡是不好的
从模型的训练过程来看
从训练模型的角度来说,如果某类的样本数量很少,那么这个类别所提供的“信息”就太少。
使用经验风险(模型在训练集上的平均损失)最小化作为模型的学习准则。设损失函数为0-1 loss(这是一种典型的均等代价的损失函数),那么优化目标就等价于错误率最小化(也就是accuracy最大化)。考虑极端情况:1000个训练样本中,正类样本999个,负类样本1个。训练过程中在某次迭代结束后,模型把所有的样本都分为正类,虽然分错了这个负类,但是所带来的损失实在微不足道,accuracy已经是99.9%,于是满足停机条件或者达到最大迭代次数之后自然没必要再优化下去,ok,到此为止,训练结束!于是这个模型……
模型没有学习到如何去判别出少数类。
从模型的预测过程来看
考虑二项Logistic回归模型。输入一个样本 $\textbf x$ ,模型输出的是其属于正类的概率 $\hat y$ 。当 $\hat y>0.5$ 时,模型判定该样本属于正类,否则就是属于反类。
为什么是0.5呢?可以认为模型是出于最大后验概率决策的角度考虑的,选择了0.5意味着当模型估计的样本属于正类的后验概率要大于样本属于负类的后验概率时就将样本判为正类。但实际上,这个后验概率的估计值是否准确呢?
从几率(odds)的角度考虑:几率表达的是样本属于正类的可能性与属于负类的可能性的比值。模型对于样本的预测几率为 $\dfrac{\hat y}{1-\hat y}$ 。
模型在做出决策时,当然希望能够遵循真实样本总体的正负类样本分布:设 $\theta$ 等于正类样本数除以全部样本数,那么样本的真实几率为 $\dfrac{\theta}{1-\theta}$ 。当观测几率大于真实几率时,也就是 $\hat y>\theta$ 时,那么就判定这个样本属于正类。
虽然我们无法获悉真实样本总体,但之于训练集,存在这样一个假设:训练集是真实样本总体的无偏采样。正是因为这个假设,所以认为训练集的观测几率 $\dfrac{\hat\theta}{1-\hat\theta}$ 就代表了真实几率 $\dfrac{\theta}{1-\theta}$ 。
所以,在这个假设下,当一个样本的预测几率大于观测几率时,就应该将样本判断为正类。
几种解决方案
目前主要有三种办法:
1. 调整 $\theta$ 值
根据训练集的正负样本比例,调整 $\theta$ 值。
这样做的依据是上面所述的对训练集的假设。但在给定任务中,这个假设是否成立,还有待讨论。
2. 过采样
对训练集里面样本数量较少的类别(少数类)进行过采样,合成新的样本来缓解类不平衡。
下面将介绍一种经典的过采样算法:SMOTE。
3. 欠采样
对训练集里面样本数量较多的类别(多数类)进行欠采样,抛弃一些样本来缓解类不平衡。
SMOTE过采样算法
JAIR'2002的文章《SMOTE: Synthetic Minority Over-sampling Technique》提出了一种过采样算法SMOTE。概括来说,本算法基于“插值”来为少数类合成新的样本。下面介绍如何合成新的样本。
设训练集的一个少数类的样本数为 $T$ ,那么SMOTE算法将为这个少数类合成 $NT$ 个新样本。这里要求 $N$ 必须是正整数,如果给定的 $N<1$ 那么算法将“认为”少数类的样本数 $T=NT$ ,并将强制 $N=1$ 。
考虑该少数类的一个样本 $i$ ,其特征向量为 $\boldsymbol x_i,i\in\{1,...,T\}$ :
1. 首先从该少数类的全部 $T$ 个样本中找到样本 $\boldsymbol x_i$ 的 $k$ 个近邻(例如用欧氏距离),记为 $\boldsymbol x_{i(near)},near\in\{1,...,k\}$ ;
2. 然后从这 $k$ 个近邻中随机选择一个样本 $\boldsymbol x_{i(nn)}$ ,再生成一个 $0$ 到 $1$ 之间的随机数 $\zeta_1$ ,从而合成一个新样本 $\boldsymbol x_{i1}$ :
$$\boldsymbol x_{i1}=\boldsymbol x_i+\zeta_1\cdot (\boldsymbol x_{i(nn)}−\boldsymbol x_i)$$
3. 将步骤2重复进行 $N$ 次,从而可以合成 $N$ 个新样本:$\boldsymbol x_{inew},new\in{1,...,N}$。
那么,对全部的 $T$ 个少数类样本进行上述操作,便可为该少数类合成 $NT$ 个新样本。
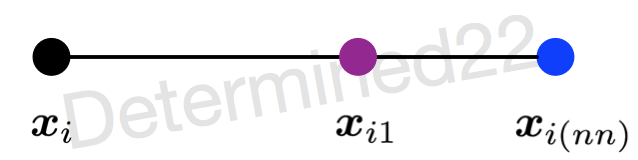
如果样本的特征维数是 $2$ 维,那么每个样本都可以用二维平面上的一个点来表示。SMOTE算法所合成出的一个新样本 $\boldsymbol x_{i1}$ 相当于是表示样本 $\boldsymbol x_i$ 的点和表示样本 $\boldsymbol x_{i(nn)}$ 的点之间所连线段上的一个点。所以说该算法是基于“插值”来合成新样本。
进一步阅读
有两篇翻译自国外博客的文章:
可以先读中文的了解一下说了哪些事情,如果感兴趣的话就去看英文原文来深入学习。
参考:
《机器学习》,周志华
SMOTE: Synthetic Minority Over-sampling Technique,JAIR'2002
机器学习 —— 类不平衡问题与SMOTE过采样算法的更多相关文章
- [转]类不平衡问题与SMOTE过采样算法
在前段时间做本科毕业设计的时候,遇到了各个类别的样本量分布不均的问题——某些类别的样本数量极多,而有些类别的样本数量极少,也就是所谓的类不平衡(class-imbalance)问题. 本篇简述了以下内 ...
- 机器学习:不平衡信息有序平均加权最近邻算法IFROWANN
一 背景介绍 不平衡信息,特点是少数信息更珍贵,多数信息没有代表性.所以一般的分类算法会被多数信息影响,而忽略少数信息的重要性. 解决策略: 1.数据级别 (1)上采样:增加稀有类成本数 (2)下采样 ...
- 类别不平衡问题之SMOTE算法(Python imblearn极简实现)
类别不平衡问题类别不平衡问题,顾名思义,即数据集中存在某一类样本,其数量远多于或远少于其他类样本,从而导致一些机器学习模型失效的问题.例如逻辑回归即不适合处理类别不平衡问题,例如逻辑回归在欺诈检测问题 ...
- spark实现smote近邻采样
一.smote相关理论 (1). SMOTE是一种对普通过采样(oversampling)的一个改良.普通的过采样会使得训练集中有很多重复的样本. SMOTE的全称是Synthetic Minorit ...
- 过采样算法之SMOTE
SMOTE(Synthetic Minority Oversampling Technique),合成少数类过采样技术.它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加 ...
- 机器学习---K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法 1.K最近邻(k-Nearest Neighbour,KNN) K最近邻(k-Nearest Neighbour,KNN)分类算法, ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- WebRTC 音频采样算法 附完整C++示例代码
之前有大概介绍了音频采样相关的思路,详情见<简洁明了的插值音频重采样算法例子 (附完整C代码)>. 音频方面的开源项目很多很多. 最知名的莫过于谷歌开源的WebRTC, 其中的音频模块就包 ...
- MCMC等采样算法
一.直接采样 直接采样的思想是,通过对均匀分布采样,实现对任意分布的采样.因为均匀分布采样好猜,我们想要的分布采样不好采,那就采取一定的策略通过简单采取求复杂采样. 假设y服从某项分布p(y),其累积 ...
随机推荐
- 常见类——Object
1.在Java类继承结构中Java.lang.Object类位于顶端 2.如果定义一个Object类没有使用extends关键字声明其父类,则其父类为Java.lang.Object类 3.O ...
- 两个HTML,CSS布局实例
今天首先仿照某公司页面只做了一个几乎一模一样,连距离都相同的页面. <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional/ ...
- Java基础——封装
最近学习Java面向对象方面的知识点,一直没时间更新博客,因为这块的知识点真的蛮绕的.一个知识点一个知识点的往外冒,而且对于我这个初学者来说区分构造器和方法就花费了一整天的时间.现在准备再重新过一遍知 ...
- matplotlib.pyplot.hist
**n, bins, patches = plt.hist(datasets, bins, normed=False, facecolor=None, alpha=None)** ## 函数说明 用于 ...
- Ubuntu发行版升级
从UK 13.10升级到UK 14.10 方法一: 1.sudo apt-get update 2.sudo update-manager -c -d 3.选择upgrade(升级) 方法二 ...
- [译]WPF MVVM 架构 Step By Step(5)(添加actions和INotifyPropertyChanged接口)
应用不只是包含textboxs和labels,还包含actions,如按钮和鼠标事件等.接下来我们加上一些像按钮这样的UI元素来看MVVM类怎么演变的.与之前的UI相比,这次我们加上一个"C ...
- Tomcat、JBOSS、WebSphere、WebLogic、Apache等技术概述
Tomcat:应用也算非常广泛的web服务器,支持部分j2ee,免费,出自apache基金组织 JBoss:开源的应用服务器,比较受人喜爱,免费(文档要收费) Weblogic:应该说算是业界 ...
- Normalize.css源码注释翻译&浏览器css兼容问题的理解
版本v5.0.0源码地址: https://necolas.github.io/normalize.css/5.0.0/normalize.css 翻译版: /*! normalize.css v5. ...
- img如果没有图片显示默认图片效果
img如果没有图片显示默认图片效果<img src="本来要显示的图片URL" onerror="this.src='图片挂了的话要显示的默认图片URL'" ...
- 在React中使用Redux
这是Webpack+React系列配置过程记录的第六篇.其他内容请参考: 第一篇:使用webpack.babel.react.antdesign配置单页面应用开发环境 第二篇:使用react-rout ...