Python获取股票历史、实时数据与更新到数据库
要做量化投资,数据是基础,正所谓“巧妇难为无米之炊”
在免费数据方面,各大网站的财经板块其实已提供相应的api,如新浪、雅虎、搜狐。。。可以通过urlopen相应格式的网址获取数据
而TuShare正是这么一个免费、开源的python财经数据接口包,已将各类数据整理为dataframe类型供我们使用。
主要用到的函数:
1.实时行情获取
tushare.get_today_all()
一次性获取当前交易所有股票的行情数据(如果是节假日,即为上一交易日,结果显示速度取决于网速)
2.历史数据获取
tushare.get_hist_data(code, start, end,ktype, retry_count,pause)
参数说明:
- code:股票代码,即6位数字代码,或者指数代码(sh=上证指数 sz=深圳成指 hs300=沪深300指数 sz50=上证50 zxb=中小板 cyb=创业板)
- start:开始日期,格式YYYY-MM-DD
- end:结束日期,格式YYYY-MM-DD
- ktype:数据类型,D=日k线 W=周 M=月 5=5分钟 15=15分钟 30=30分钟 60=60分钟,默认为D
- retry_count:当网络异常后重试次数,默认为3
- pause:重试时停顿秒数,默认为0
具体可参考官网http://tushare.org/index.html
而如果要进行完备详细的回测,每次在线获取数据无疑效率偏低,因此还需要入库
下面是数据库设计部分
表1:stocks
股票表,第一列为股票代码,第二列为名称,如果get_today_all()中存在的股票stocks表中没有,则插入之。
表2:hdata_date
日线表,由于分钟线只能获取一周内的数据,我们先对日线进行研究。
字段和get_hist_data返回值基本一致,多了stock_code列,并将record_date列本来是dataframe的index
stock_code,record_date, //主键
open,high,close,low, //开盘,最高,收盘,最低
volume, //成交量
price_change,p_change, //价差,涨幅
ma5,ma10,ma20 //k日收盘均价
v_ma5,v_ma10,v_ma20, //(k日volume均值)
turnover //换手率
python工程目前有3个文件,main.py(主程序),Stocks.py(“股票们”类)以及Hdata.py(历史数据类)
main.py
import psycopg2 #使用的是PostgreSQL数据库
import tushare as ts
from Stocks import*
from HData import*
import datetime stocks=Stocks("postgres","")
hdata=HData("postgres","") # stocks.db_stocks_create()#如果还没有表则需要创建
#print(stocks.db_stocks_update())#根据todayall的情况更新stocks表 #hdata.db_hdata_date_create() nowdate=datetime.datetime.now().date() codestock_local=stocks.get_codestock_local() hdata.db_connect()#由于每次连接数据库都要耗时0.0几秒,故获取历史数据时统一连接
for i in range(0,len(codestock_local)):
nowcode=codestock_local[i][0] #print(hdata.get_all_hdata_of_stock(nowcode)) print(i,nowcode,codestock_local[i][1]) maxdate=hdata.db_get_maxdate_of_stock(nowcode)
print(maxdate, nowdate)
if(maxdate):
if(maxdate>=nowdate):#maxdate小的时候说明还有最新的数据没放进去
continue
hist_data=ts.get_hist_data(nowcode, str(maxdate+datetime.timedelta(1)),str(nowdate), 'D', 3, 0.001)
hdata.insert_perstock_hdatadate(nowcode, hist_data)
else:#说明从未获取过这只股票的历史数据
hist_data = ts.get_hist_data(nowcode, None, str(nowdate), 'D', 3, 0.001)
hdata.insert_perstock_hdatadate(nowcode, hist_data) hdata.db_disconnect()
Stocks.py
import tushare as ts
import psycopg2
class Stocks(object):#这个类表示"股票们"的整体(不是单元)
def get_today_all(self):
self.todayall=ts.get_today_all() def get_codestock_local(self):#从本地获取所有股票代号和名称
conn = psycopg2.connect(database="wzj_quant", user=self.user, password=self.password, host="127.0.0.1",
port="")
cur = conn.cursor()
# 创建stocks表
cur.execute('''
select * from stocks;
''')
rows =cur.fetchall()
conn.commit()
conn.close() return rows
pass
def __init__(self,user,password):
# self.aaa = aaa
self.todayall=[]
self.user=user
self.password=password def db_perstock_insertsql(self,stock_code,cns_name):#返回的是插入语句
sql_temp="insert into stocks values("
sql_temp+="\'"+stock_code+"\'"+","+"\'"+cns_name+"\'"
sql_temp +=");"
return sql_temp
pass def db_stocks_update(self):# 根据gettodayall的情况插入原表中没的。。gettodayall中有的源表没的保留不删除#返回新增行数
ans=0
conn = psycopg2.connect(database="wzj_quant", user=self.user, password=self.password, host="127.0.0.1", port="")
cur = conn.cursor()
self.get_today_all() for i in range(0,len(self.todayall)):
sql_temp='''select * from stocks where stock_code='''
sql_temp+="\'"+self.todayall["code"][i]+"\';"
cur.execute(sql_temp)
rows=cur.fetchall()
if(len(rows)==0):
#如果股票代码没找到就插
ans+=1
cur.execute(self.db_perstock_insertsql(self.todayall["code"][i],self.todayall["name"][i]))
pass
conn.commit()
conn.close()
print("db_stocks_update finish")
return ans def db_stocks_create(self):
conn = psycopg2.connect(database="wzj_quant", user=self.user, password=self.password, host="127.0.0.1", port="")
cur = conn.cursor()
# 创建stocks表
cur.execute('''
drop table if exists stocks;
create table stocks(stock_code varchar primary key,cns_name varchar);
''')
conn.commit()
conn.close()
print("db_stocks_create finish")
pass
HData.py
import psycopg2
import tushare as ts
import pandas as pd
from time import clock class HData(object):
def __init__(self,user,password):
# self.aaa = aaa
self.hdata_date=[]
self.user=user
self.password=password self.conn=None
self.cur=None def db_connect(self):
self.conn = psycopg2.connect(database="wzj_quant", user=self.user, password=self.password, host="127.0.0.1",
port="")
self.cur = self.conn.cursor() def db_disconnect(self): self.conn.close() def db_hdata_date_create(self):
conn = psycopg2.connect(database="wzj_quant", user=self.user, password=self.password, host="127.0.0.1",
port="")
cur = conn.cursor()
# 创建stocks表
cur.execute('''
drop table if exists hdata_date;
create table hdata_date(stock_code varchar,record_date date,
open float,high float,close float,low float,
volume float,
price_change float,p_change float,
ma5 float,ma10 float,ma20 float,
v_ma5 float,v_ma10 float,v_ma20 float,
turnover float
);
alter table hdata_date add primary key(stock_code,record_date);
''')
conn.commit()
conn.close()
print("db_hdata_date_create finish")
pass def db_get_maxdate_of_stock(self,stock_code):#获取某支股票的最晚日期
self.cur.execute("select max(record_date) from hdata_date where stock_code="+"\'"+stock_code+"\'"+";")
ans=self.cur.fetchall()
if(len(ans)==0):
return None
return ans[0][0]
self.conn.commit()
pass def insert_perstock_hdatadate(self,stock_code,data):#插入一支股票的所有历史数据到数据库#如果有code和index相同的不重复插入
t1=clock() for i in range(0,len(data)):
str_temp="" str_temp+="\'"+stock_code+"\'"+","
str_temp+="\'"+data.index[i]+"\'" for j in range(0,data.shape[1]):
str_temp+=","+"\'"+str(data.iloc[i,j])+"\'"
sql_temp="values"+"("+str_temp+")"
self.cur.execute("insert into hdata_date "+sql_temp+";")
self.conn.commit() print(clock()-t1) print(stock_code+" insert_perstock_hdatadate finish") def get_all_hdata_of_stock(self,stock_code):#将数据库中的数据读取并转为dataframe格式返回
conn = psycopg2.connect(database="wzj_quant", user=self.user, password=self.password, host="127.0.0.1",
port="")
cur = conn.cursor() sql_temp="select * from hdata_date where stock_code="+"\'"+stock_code+"\';"
cur.execute(sql_temp)
rows = cur.fetchall() conn.commit()
conn.close() dataframe_cols=[tuple[0] for tuple in cur.description]#列名和数据库列一致
df = pd.DataFrame(rows, columns=dataframe_cols)
return df
pass
main.py的控制台输出示例:
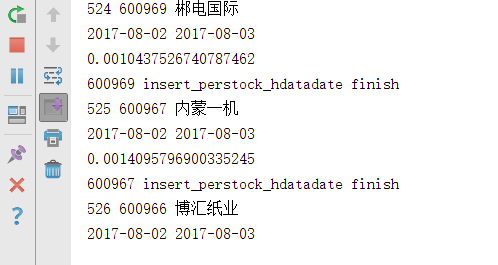
HData中的函数get_all_hdata_of_stock结果示例:
stock_code record_date open high close low volume \
0 603999 2015-12-10 14.07 14.07 14.07 14.07 337.00
1 603999 2015-12-11 15.48 15.48 15.48 15.48 119.00
2 603999 2015-12-14 17.03 17.03 17.03 17.03 267.00
3 603999 2015-12-15 18.73 18.73 18.73 18.73 244.00
.. ... ... ... ... ... ... ...
397 603999 2017-08-01 9.62 9.97 9.79 9.61 36337.80
398 603999 2017-08-02 9.80 9.85 9.61 9.59 32135.60
price_change p_change ma5 ma10 ma20 v_ma5 v_ma10 \
0 4.30 44.01 14.070 14.070 14.070 337.00 337.00
1 1.41 10.02 14.775 14.775 14.775 228.00 228.00
2 1.55 10.01 15.527 15.527 15.527 241.00 241.00
3 1.70 9.98 16.328 16.328 16.328 241.75 241.75
.. ... ... ... ... ... ... ...
397 0.16 1.66 9.680 9.709 9.924 36754.46 49436.88
398 -0.18 -1.84 9.698 9.741 9.863 36513.38 49998.51
v_ma20 turnover
0 337.00 0.06
1 228.00 0.02
2 241.00 0.04
3 241.75 0.04
.. ... ...
397 42602.09 1.58
398 42114.31 1.39
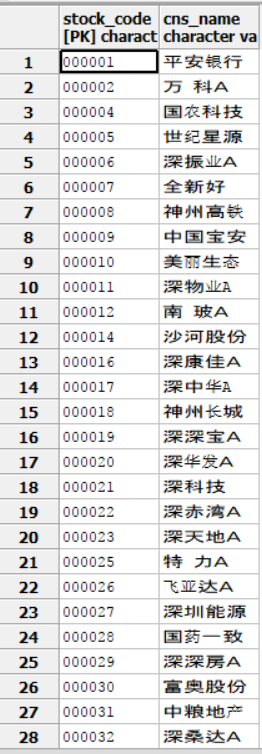
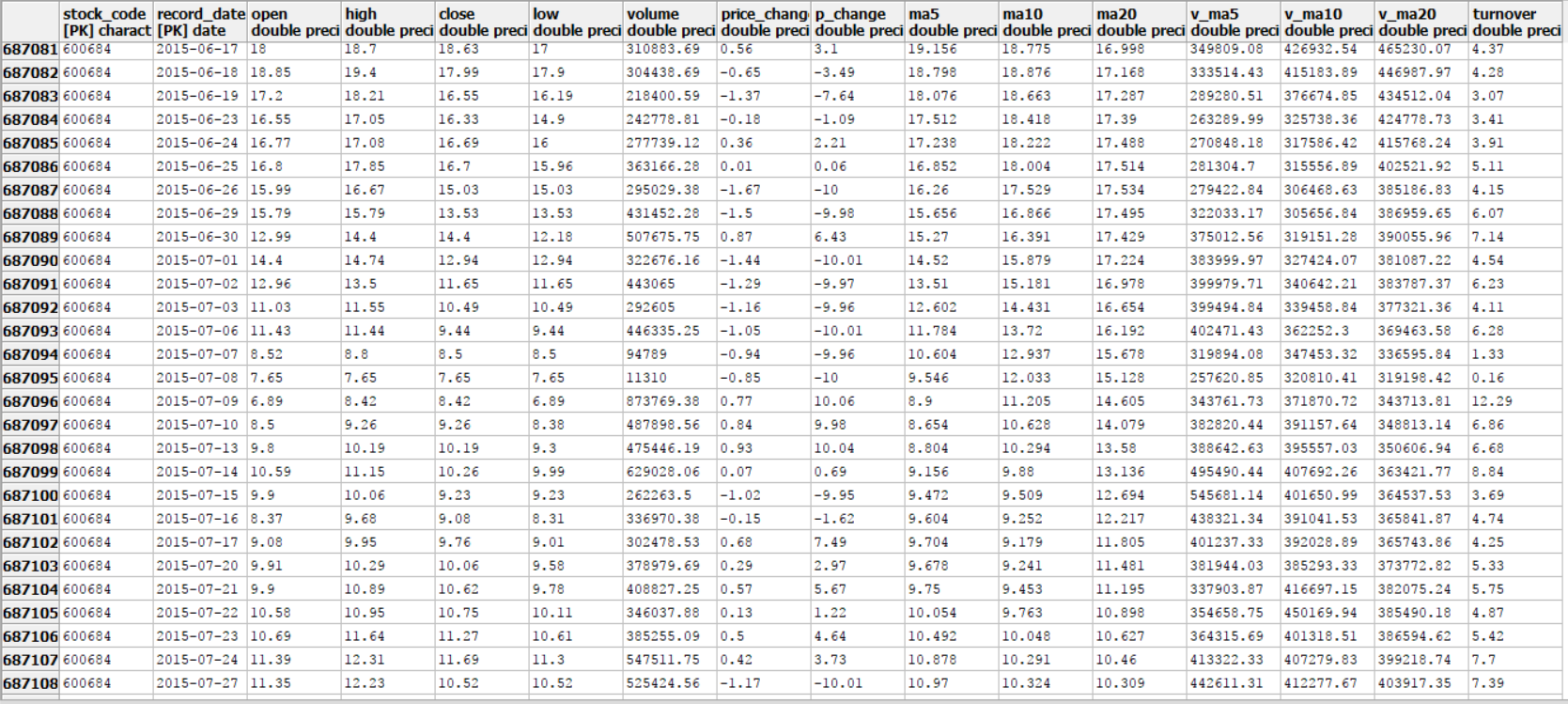
数据库中的数据示例
stocks表
hdata_date表
Python获取股票历史、实时数据与更新到数据库的更多相关文章
- Python获取时光网电影数据
Python获取时光网电影数据 一.前言 有时候觉得电影真是人类有史以来最伟大的发明,我喜欢看电影,看电影可以让我们增长见闻,学习知识.从某种角度上而言,电影凭借自身独有的魅力大大延长了人类的&quo ...
- 金融量化分析-python量化分析系列之---使用python获取股票历史数据和实时分笔数据
财经数据接口包tushare的使用(一) Tushare是一款开源免费的金融数据接口包,可以用于获取股票的历史数据.年度季度报表数据.实时分笔数据.历史分笔数据,本文对tushare的用法,已经存在的 ...
- python调用tushare获取股票日线实时行情数据
接口:daily 数据说明:交易日每天15点-16点之间.本接口是未复权行情,停牌期间不提供数据. 调取说明:基础积分每分钟内最多调取200次,每次4000条数据,相当于超过18年历史,具体请参阅本文 ...
- 一个采用python获取股票数据的开源库,相当全,及一些量化投资策略库
tushare: http://tushare.waditu.com/index.html 为什么是Python? 就跟javascript在web领域无可撼动的地位一样,Python也已经在金融量化 ...
- python调用tushare获取股票月线数据
接口:monthly 描述:获取A股月线数据 限量:单次最大3700,总量不限制 积分:用户需要至少300积分才可以调取,具体请参阅本文最下方积分获取办法 注:tushare库下载和初始化教程,请查阅 ...
- 关于Python获取图片文件二进制数据的问题(获取为空)
在搭建fastdfs文件系统的时候遇到了点问题,在测试上传文件数据流的时候,需要Python来获取本地文件的二进制流 from fdfs_client.client import Fdfs_clien ...
- 通过fsockopen()方法从中国福彩网获取双色球历史中奖数据
# 以下代码基于 CI 框架 # public function history_draw($page = 0) { set_time_limit(0); $page++; $up2now = dat ...
- python获取list列表随机数据
第一种方法(推荐)适用于随机取一个值, 返回一个值import randomlist1 = ['佛山', '南宁', '北海', '杭州', '南昌', '厦门', '温州']a = random.c ...
- WebXml.com.cn 中国股票行情数据 WEB 服务(支持深圳和上海股市的全部基金、债券和股票),数据即时更新
http://www.webxml.com.cn/WebServices/ChinaStockWebService.asmx
随机推荐
- spring boot + mybatis + druid
因为在用到spring boot + mybatis的项目时候,经常发生访问接口卡,服务器项目用了几天就很卡的甚至不能访问的情况,而我们的项目和数据库都是好了,考虑到可能时数据库连接的问题,所以我打算 ...
- 集成python双版本详解
最近要准备学习Python,由于版本上的差异,不知道要学哪个,现在好多东西都是基于python2基础的,但是python2在2020年左右就可能停止了,所以干脆决定两个都装上吧! 首先上官网上下载 ...
- eclipse中Build Path 导入的包和复制到 lib 包的区别
Java Build Path是我们编译需要的包,在比如在import ***.***.***时如果没用Java Build Path导入包的话类里面就有红叉,说不识别这个类,build path只是 ...
- 一张图搞定Java设计模式——工厂模式! 就问你要不要学!
小编今天分享的内容是Java设计模式之工厂模式. 收藏之前,务必点个赞,这对小编能否在头条继续给大家分享Java的知识很重要,谢谢!文末有投票,你想了解Java的哪一部分内容,请反馈给我. 获取学习资 ...
- [leetcode-532-K-diff Pairs in an Array]
Given an array of integers and an integer k, you need to find the number of unique k-diff pairs in t ...
- container_of 的用法
1.问题:如何通过结构中的某个变量获取结构本身的指针???关于container_of见kernel.h中:/*** container_of - cast a member of a structu ...
- eclipse更改maven的本地路径和外部仓库地址
背景 当前使用eclipse自带的maven碰到两个蛋疼的问题: maven在国内使用如果不进行FQ则会痛苦不堪如便秘. maven下载大量jar包导致某盘不够用,需要换大的分区. 因此为了解决这个问 ...
- 关于在eclipse上部署Tomcat时出现8080等端口被占用问题的解决方法
问题描述: 在eclipse中部署Tomcat时,出现如下错误. 解决方法如下: 方法一: 1.开始->cmd->输入命令netstat -ano出现下图所示(注意下边显示有些错位,最后一 ...
- 8位基本定时器(TIM4)
简介:该定时器由一个带可编程预分频器的8位自动重载的向上计数器所组成,它可以用来作为时基发生器,具有溢出中断功能. 主要功能: (1)8位向上计数的自动重载计数器: (2)3位可编程的预分配器(可在运 ...
- RecyclerView-------之GridView模式加载更多
随着RecyclerView的出现,Listview.GridView的使用率相对有些减少,废话不多说,先看一下效果: 代码如下: 1.自定义的RecyclerView(根据自己的需要) public ...