Redis分布式集群搭建
Redis集群架构图
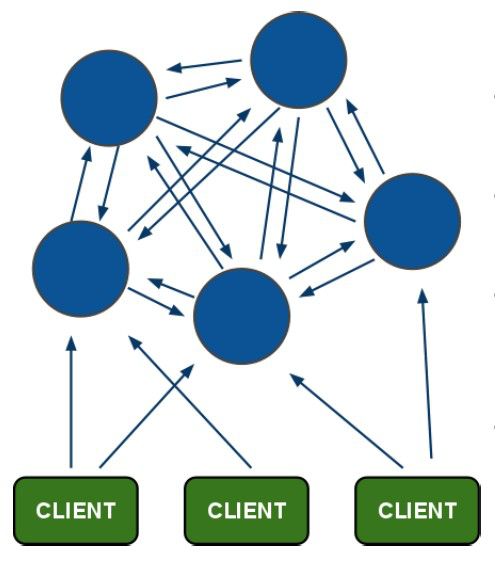
上图蓝色为redis集群的节点。
节点之间通过ping命令来测试连接是否正常,节点之间没有主区分,连接到任何一个节点进行操作时,都可能会转发到其他节点。
1、Redis的容错机制
节点之间会定时的互相发送ping命令,测试节点的健康状态,当节点接受到ping命令后,会返回一个pong字符串。
投票机制:如果一个节点A给节点B发送ping没有得到pong返回,会通知其他节点再次给B发送ping,如果集群中有超过一半的节点收不B节点的pong。那么就认为B节点挂了。一般会为每个节点提供一个备份节点,如果挂掉会切换到备份节点。
2、Redis集群存储原理
Redis对于每个存放的key会进行hash操作,生成一个[0-16384]的hash值(先进行
crc 算法再对16384取余)。
集群的情况下,就是把[0-16384]的区间进行拆分,放到不同的redis中。
3、Redis的持久化
Snapshotting:定时的将Redis内存中的数据保存到硬盘中
AOF:将所有的command操作保存到aof中,AOP的同步频率很高,数据即使丢失,粒度也很小,但会在性能上造成影响。
二、Redis集群准备工作
Redis安装
源码下载
下载地址https://pan.baidu.com/s/1bCcLv4 密码i5k6
解压源码
tar -zxvf redis-3.0.0.tar.gz
进入解压后的目录进行编译
cd /usr/local/redis-3.0.0
make
安装到指定目录,如 /usr/local/redis
cd /usr/local/redis-3.0.0
make PREFIX=/usr/local/redis install
nredis.conf
redis.conf是redis的配置文件,redis.conf在redis源码目录。
注意修改port作为redis进程的端口,port默认6379。
拷贝配置文件到安装目录下
进入源码目录,里面有一份配置文件 redis.conf,然后将其拷贝到安装路径下
cd /usr/local/redis
mkdir conf
cp /usr/local/redis-3.0.0/redis.conf /usr/local/redis/bin
运行:bin/redis-server 将出现下图画面:
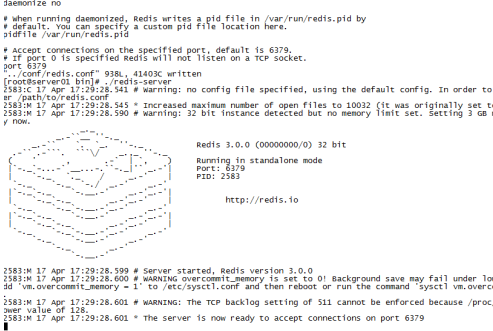
Redis默认是前台运行的,可以修改redis.conf的daemonize yes ,将其变成后台运行。
集群环境搭建
redis集群管理工具redis-trib.rb依赖ruby环境,首先需要安装ruby环境
安装ruby
yum install ruby
yum install rubygems
安装ruby和redis的接口程序
拷贝redis-3.0.0.gem至/usr/local下
执行:
gem install /usr/local/redis-3.0.0.gem
三、创建Redis集群
在一台服务器上,可以用不同端口号来表示不同redis服务器。
Redis集群最少需要三台服务器,而每台服务器有需要备用服务器,所以最少需要6台服务器。端口规划如下:
主服务器:192.168.100.66 :7001 :7002 :7003
从服务器:192.168.100.66 :7004 :7005 :7006
在/usr/local 创建文件夹用来存放服务器程序
mkdir 7001 7002 7003 7004 7005 7006
如果想让redis支持集群需要修改redis.config配置文件的cluster-enabled yes
本例中我们以端口来区别不同的redis服务,所以还需要修改redis.config的port为对应端口
修改完配置文件,将redis安装目录的bin复制到上面每个目录中。
分别进入7001/bin/ 7002/bin .....
启动服务./redis-server ./redis.conf
查看redis进程:ps -aux|grep redis 如下图则说明启动成功

创建集群:
将之前解压的文件夹的redis-3.0.0/src/redis-trib.rb复制到redis-cluster目录
运行
./redis-trib.rb create --replicas 1 192.168.100.66:7001 192.168.100.66:7002 192.168.100.66:7003 192.168.100.66:7004 192.168.100.66:7005 192.168.100.66:7006
如果执行时报如下错误:
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
解决方法是删除生成的配置文件nodes.conf,如果不行则说明现在创建的结点包括了旧集群的结点信息,需要删除redis的持久化文件后再重启redis,比如:appendonly.aof、dump.rdb
如果成功最终输入如下:
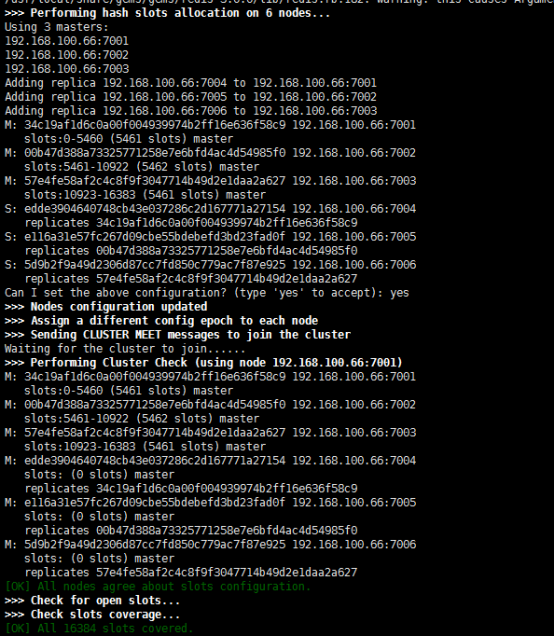
查询集群信息:

说明:
./redis-cli -c -h 192.168.101.3 -p 7001 ,其中-c表示以集群方式连接redis,-h指定ip地址,-p指定端口号
cluster nodes 查询集群结点信息
cluster info 查询集群状态信息

hash槽重新分配
第一步:连接上集群
./redis-trib.rb reshard 192.168.101.3:7001(连接集群中任意一个可用结点都行)
第二步:输入要分配的槽数量
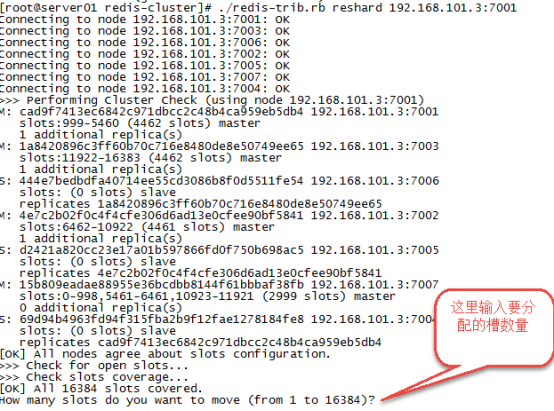
输入 500表示要分配500个槽
第三步:输入接收槽的结点id

这里准备给7007分配槽,通过cluster nodes查看7007结点id为15b809eadae88955e36bcdbb8144f61bbbaf38fb
输入:15b809eadae88955e36bcdbb8144f61bbbaf38fb
第四步:输入源结点id

这里输入all
第五步:输入yes开始移动槽到目标结点id

添加从节点
集群创建成功后可以向集群中添加节点,下面是添加一个slave从节点。
添加7008从结点,将7008作为7007的从结点。
./redis-trib.rb add-node --slave --master-id 主节点id 添加节点的ip和端口 集群中已存在节点ip和端口
执行如下命令:
./redis-trib.rb add-node --slave --master-id cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 192.168.101.3:7008 192.168.101.3:7001
cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 是7007结点的id,可通过cluster nodes查看。
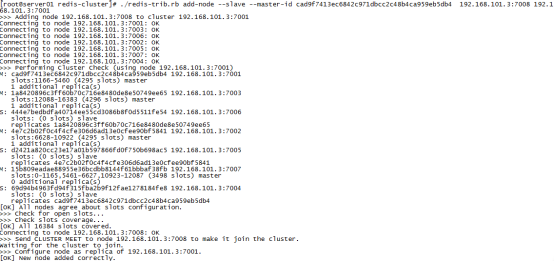
注意:如果原来该结点在集群中的配置信息已经生成cluster-config-file指定的配置文件中(如果cluster-config-file没有指定则默认为nodes.conf),这时可能会报错:
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
解决方法是删除生成的配置文件nodes.conf,删除后再执行./redis-trib.rb add-node指令
查看集群中的结点,刚添加的7008为7007的从节点:

1.1. 删除结点:
./redis-trib.rb del-node 127.0.0.1:7005 4b45eb75c8b428fbd77ab979b85080146a9bc017
删除已经占有hash槽的结点会失败,报错如下:
[ERR] Node 127.0.0.1:7005 is not empty! Reshard data away and try again.
需要将该结点占用的hash槽分配出去(参考hash槽重新分配章节)。
测试:
Maven:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework/spring-test -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.3.10.RELEASE</version>
<scope>test</scope>
</dependency>
</dependencies>
普通测试:
@Test
public void redisClusterTest1(){
JedisPoolConfig config=new JedisPoolConfig();
config.setMaxTotal(30);
config.setMaxIdle(2);
Set<HostAndPort> jedisNode=new HashSet<HostAndPort>();
jedisNode.add(new HostAndPort("192.168.100.66",7001));
jedisNode.add(new HostAndPort("192.168.100.66",7002));
jedisNode.add(new HostAndPort("192.168.100.66",7003));
jedisNode.add(new HostAndPort("192.168.100.66",7004));
jedisNode.add(new HostAndPort("192.168.100.66",7005));
jedisNode.add(new HostAndPort("192.168.100.66",7006));
JedisCluster jc=new JedisCluster(jedisNode,config);
jc.set("name","老王");
String value=jc.get("name");
System.out.println(value);
}
Spring测试:
配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 连接池配置 -->
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大连接数 -->
<property name="maxTotal" value="30" />
<!-- 最大空闲连接数 -->
<property name="maxIdle" value="10" />
<!-- 每次释放连接的最大数目 -->
<property name="numTestsPerEvictionRun" value="1024" />
<!-- 释放连接的扫描间隔(毫秒) -->
<property name="timeBetweenEvictionRunsMillis" value="30000" />
<!-- 连接最小空闲时间 -->
<property name="minEvictableIdleTimeMillis" value="1800000" />
<!-- 连接空闲多久后释放, 当空闲时间>该值 且 空闲连接>最大空闲连接数 时直接释放 -->
<property name="softMinEvictableIdleTimeMillis" value="10000" />
<!-- 获取连接时的最大等待毫秒数,小于零:阻塞不确定的时间,默认-1 -->
<property name="maxWaitMillis" value="1500" />
<!-- 在获取连接的时候检查有效性, 默认false -->
<property name="testOnBorrow" value="true" />
<!-- 在空闲时检查有效性, 默认false -->
<property name="testWhileIdle" value="true" />
<!-- 连接耗尽时是否阻塞, false报异常,ture阻塞直到超时, 默认true -->
<property name="blockWhenExhausted" value="false" />
</bean>
<!-- redis集群 -->
<bean id="jedisCluster" class="redis.clients.jedis.JedisCluster">
<constructor-arg index="0">
<set>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.100.66"></constructor-arg>
<constructor-arg index="1" value="7001"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.100.66"></constructor-arg>
<constructor-arg index="1" value="7002"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.100.66"></constructor-arg>
<constructor-arg index="1" value="7003"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.100.66"></constructor-arg>
<constructor-arg index="1" value="7004"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.100.66"></constructor-arg>
<constructor-arg index="1" value="7005"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.100.66"></constructor-arg>
<constructor-arg index="1" value="7006"></constructor-arg>
</bean>
</set>
</constructor-arg>
<constructor-arg index="1" ref="jedisPoolConfig"></constructor-arg>
</bean>
</beans>
测试类:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration({"classpath:spring-config.xml"})
public class RedisClusterTest {
@Autowired
private JedisCluster jedisCluster;
@Test
public void redisClusterTest2(){
jedisCluster.set("username","小明啦啦");
String name=jedisCluster.get("username");
System.out.println(name);
}
}
Redis分布式集群搭建的更多相关文章
- 10.Redis分布式集群
10.Redis分布式集群10.1 数据分布10.1.1 数据分布理论10.1.2 Redis数据分区10.1.3 集群功能限制10.2 搭建集群10.2.1 准备节点10.2.2 节点握手10.2. ...
- 5000+字硬核干货!Redis 分布式集群部署实战
原理: Redis集群采用一致性哈希槽的方式将集群中每个主节点都分配一定的哈希槽,对写入的数据进行哈希后分配到某个主节点进行存储. 集群使用公式(CRC16 key)& 16384计算键key ...
- redis的集群搭建(很详细很详细)
说在前面的话 之前有一节说了redis单机版的搭建和使用jedis管理redis单机版和集群版, 本节主要讲一下redis的集群搭建. 跳转到jedis管理redis的使用 认识redis集群 首先我 ...
- Redis分布式集群几点说道
原文地址:http://www.cnblogs.com/verrion/p/redis_structure_type_selection.html Redis分布式集群几点说道 Redis数据量日益 ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
- java高级精讲之高并发抢红包~揭开Redis分布式集群与Lua神秘面纱
java高级精讲之高并发抢红包~揭开Redis分布式集群与Lua神秘面纱 redis数据库 Redis企业集群高级应用精品教程[图灵学院] Redis权威指南 利用redis + lua解决抢红包高并 ...
随机推荐
- spring bean的创建过程
spring的核心容器包括:core.beans.context.express language四个模块.所以对于一个简单的spring工程,最基本的就是依赖以下三个jar包即可: <depe ...
- 理解HTTP幂等性(转)
基于HTTP协议的Web API是时下最为流行的一种分布式服务提供方式.无论是在大型互联网应用还是企业级架构中,我们都见到了越来越多的SOA或RESTful的Web API.为什么Web API如此流 ...
- 对java多线程里Synchronized的思考
Synchronized这个关键字在多线程里经常会出现,哪怕做到架构师级别了,在考虑并发分流时,也经常会用到它.在本文里,将通过一些代码实验来验证它究竟是"锁"什么. 在启动多个线 ...
- 永中DCS再添喜讯:顺利签约海信集团
近日,永中DCS与海信集团一起携手,共创文档在线预览新篇章.出于对永中DCS文档在线预览产品的品质与服务的信赖,海信集团选择永中DCS为其提供文档在线预览技术支持,助力移动化办公(EHR系统)发展,提 ...
- win7及以上系统打开chm空白或显示"无法打开"的2个解决方案
1:在文件上右键单击属性.选择解锁. 2:确保文件路径中没有特殊字符.比如"#".如果路径中存在特殊字符,chm文件可能找不到路径而无法显示.如 d:\资料\c#\***.chm. ...
- TCP/IP 协议 ----- 协议栈
文章是作者对tcp/ip协议族的一些看法,借鉴TCP/IP详解卷一的内容,进行总结归纳,并阐述自己的一些看法. TCP/IP协议栈· : 整个协议栈被分为了四层,每一层协议负责不同的功能: 链路层:负 ...
- 调用支付宝第三方接口(沙箱环境) SpringMVC+Maven
一.蚂蚁金服开放平台的操作 网址:https://open.alipay.com/platform/home.htm 支付宝扫码登陆
- BFS求最短路 Abbottt's Revenge UVa 816
本题的题意是输入起点,朝向和终点,求一条最短路径(多解时任意输出一个即可) 本题的主要代码是bfs求解,就是以下代码中的slove的主要部分,通过起点按照路径的长度来寻找最短路径,输出最先到终点的一系 ...
- java傻瓜简单100%一定看的懂新手安装教程
1.java官网 最新的不是很稳定 http://www.oracle.com/technetwork/java/javase/downloads/index.html 一直点下一步就可以,但别忘 ...
- 如何在BIOS里设置定时关机?
如何在BIOS里设置定时关机? 通过CMOS设置实现定时开机的设置过程如下: 首先进入"CMOS SETUP"程序(大多数主板是在计算机启动时按DEL键进入): 然后将光条移到&q ...