11scrapy
一. Scrapy基础概念
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。Scrapy 使用了 Twisted异步网络框架,可以加快我们的下载速度。
二. 操作
1. 基本操作
1)创建一个scrapy项目
scrapy startproject mySpider
2)生成一个爬虫
scrapy genspider itcast "itcast.cn”
3)提取数据
完善spider,使用xpath等方法
4)保存数据
pipeline中保存数据
2. 完善spdier


3. spdier数据传到pipeline


4. 使用·pipeline

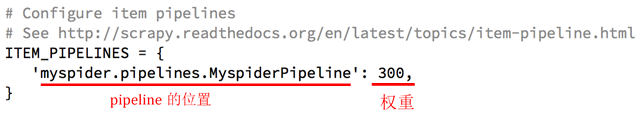
5. 设置log
为了让我们自己希望输出到终端的内容能容易看一些:
我们可以在setting中设置log级别
在setting中添加一行(全部大写):LOG_LEVEL = "WARNING”
默认终端显示的是debug级别的log信息
三. 实行翻页操作
1. 获取地址,使用scrapy.Request方法

需要传递数据时,可以在方法中传递meta:
yield scrapy.Request(next_page_url,callback=self.parse,meta=…)
dont_filter:让scrapy不会过滤当前url
四. 定义Item
1. 方法

2. 实例


3. 在不同的解析函数中传递参数
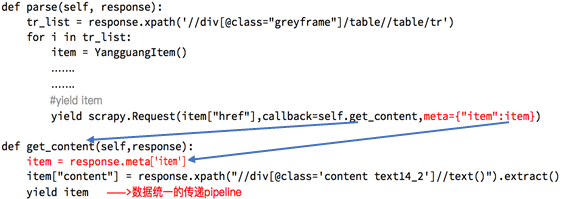
五. 深入pipeline

可以将一些需要初始化的数值添加在open_spider方法中
而close_spider可以做一些收尾工作
六. CrawlSpider
1. 功能
1)我们把满足某个条件的url地址传给rules,同时能够指定callback函数。不需要手动去找下一页的url地址,达到简化代码的目的
2)生成CrawlSpider的命令
scrapy genspider –t crawl 项目名 “域名”
2. 实例
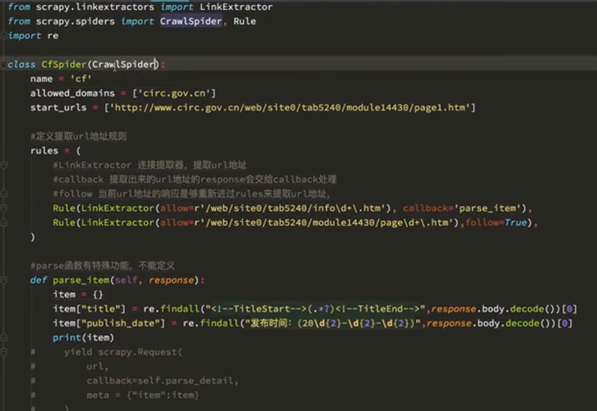
rules内的几个参数:
1) LinkExtractor 连接提取器,提取url地址
2) callback 提取出来的url地址的response会交给callback来处理
3) follow 当前url地址的响应是否重新进rules来提取url地址
3. 注意点

七. Scrapy模拟登录
1. 携带cookie登录
1)直接携带cookie,在浏览器登录之后获取检查里边cookies的值
2)找到发送post请求的url地址,带上信息,发送请求
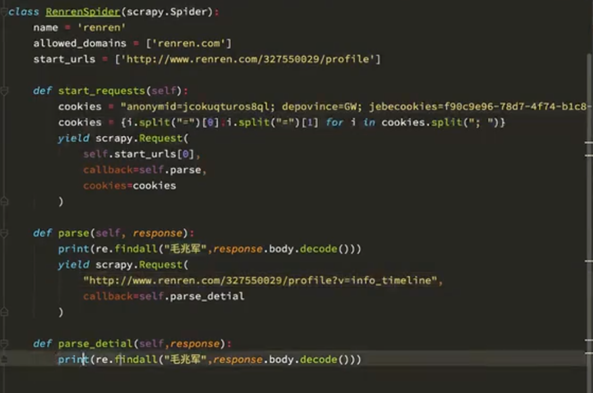
可以在settings里边添加参数【COOKIES_DEBUG=True】观察cookies的传递过程。
不能把cookies放在headers中
2. 使用FormRequest
1) scrapy.FormRequest(url,formdata={},callback) formdata请求体
2) formdata里边的数据,可以试着在浏览器输入用户名和密码之后,在session的Headers里边找到formdata,接着在Elements中查找对应的组件

3)示例

3. 自动寻找Form表单中action的url
1) scrapy.FormRequest.from_response(response,formdata={},callback)
2) 示例

八. 案例分析
1. 贴吧爬虫
1.1 补充不完整的链接
注意:需要导入import urllib
通过urljoin方法自动把链接补全
1.2 对图片解码以及翻页时处理内容覆盖的问题
1) 图片解码:需要import requests
item["img_list"] = [requests.utils.unquote(i).split("src=")[-1] for i in item["img_list"]]
2) 翻页使用extend()来处理
item["img_list"].extend(response.xpath("//img[@class='BDE_Image']/@src").extract())
1.3 spider下的tb.py完整代码
import scrapy
import urllib
import requests
class TbSpider(scrapy.Spider):
name = 'tb'
allowed_domains = ['tieba.baidu.com']
start_urls = ['http://tieba.baidu.com/mo/q----,sz@320_240-1-3---2/m?kw=%E6%9D%8E%E6%AF%85&lp=9001']
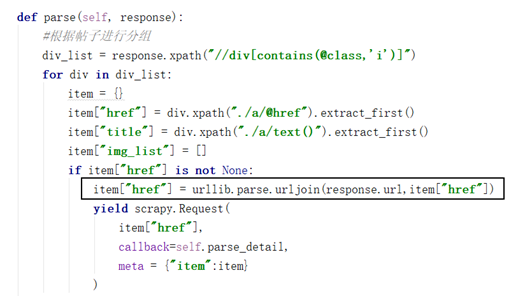
def parse(self, response):
#根据帖子进行分组
div_list = response.xpath("//div[contains(@class,'i')]")
for div in div_list:
item = {}
item["href"] = div.xpath("./a/@href").extract_first()
item["title"] = div.xpath("./a/text()").extract_first()
item["img_list"] = []
if item["href"] is not None:
item["href"] = urllib.parse.urljoin(response.url,item["href"])
yield scrapy.Request(
item["href"],
callback=self.parse_detail,
meta = {"item":item}
)
#列表页的翻页
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url is not None:
next_url = urllib.parse.urljoin(response.url,next_url)
yield scrapy.Request(
next_url,
callback=self.parse,
)
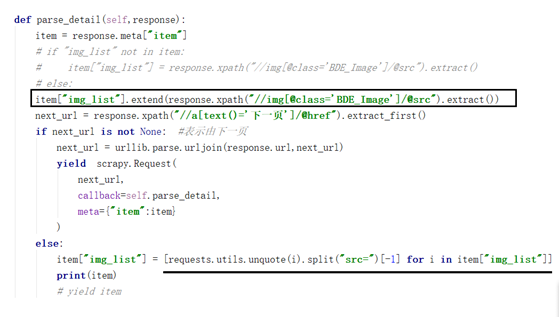
def parse_detail(self,response):
item = response.meta["item"]
# if "img_list" not in item:
#item["img_list"] = response.xpath("//img[@class='BDE_Image']/@src").extract()
# else:
item["img_list"].extend(response.xpath("//img[@class='BDE_Image']/@src").extract())
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url is not None: #表示由下一页
next_url = urllib.parse.urljoin(response.url,next_url)
yield scrapy.Request(
next_url,
callback=self.parse_detail,
meta={"item":item}
)
else:
item["img_list"] = [requests.utils.unquote(i).split("src=")[-1] for i in item["img_list"]]
print(item)
# yield item
11scrapy的更多相关文章
- 11-scrapy(递归解析,post请求,日志等级,请求传参)
一.递归解析: 需求:将投诉_阳光热线问政平台中的投诉标题和状态网友以及时间爬取下来永久储存在数据库中 url:http://wz.sun0769.com/index.php/question/que ...
随机推荐
- ASP.NET Core 依赖注入(DI)
ASP.NET Core的底层设计支持和使用依赖注入.ASP.NET Core 应用程序可以利用内置的框架服务将服务注入到启动类的方法中,并且应用程序服务也可以配置注入.由ASP.NET Core 提 ...
- Codeforces - 1114B - Yet Another Array Partitioning Task - 构造 - 排序
https://codeforces.com/contest/1114/problem/B 一开始叫我做,我是不会做的,我没发现这个性质. 其实应该很好想才对,至少要选m个元素,其中m个作为最大值,从 ...
- Codeforces 2 A. Winner
哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈....... 先让我笑完................ 就是一道撒比题啊,一开始是题目看错= =.是,但是后面还是自己不仔细错的.....不存在题目坑这种情况 ...
- poj2389 普通的大数乘法
= =.每次这种题目说只有40位 然而要开到100位,心里总是一万匹草泥马在奔腾: #include <iostream> #include <stdio.h> #includ ...
- bzoj 4551: [Tjoi2016&Heoi2016]树【并查集】
看起来像是并查集,但是是拆集合,考虑时间倒流,先把标记都打上,然后把并查集做出来 每次到一个修改点就把这个点的计数s[u]--,当这个s为0时就把这个点和他的父亲合并(因为可能有多次标记) #incl ...
- mysqldump 工具使用详解——参数选项
mysqldump 简介 mysqldump 是一种用于逻辑备份的客户端工具,它会产生一套能够重新构建数据库或表的SQL语句.所谓逻辑备份:是利用SQL语言从数据库中抽取数据并存于二进制文件的过程.逻 ...
- git 命令参考手册
你的本地仓库由 git 维护的三棵“树”组成.第一个是你的 工作目录,它持有实际文件:第二个是 缓存区(Index),它像个缓存区域,临时保存你的改动:最后是 HEAD,指向你最近一次提交后的结果. ...
- TensorFlow图像处理函数
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 图像编码处理+图像大小调整+图像翻转+图像色彩调整+处理标注框 #!/usr/bin/env python # - ...
- python实现选择排序
list_1 = [] #先建一个空链表 print('输入排序个数:') n = int(input()) #接收输入个数 for i in range(n): a = input() list_1 ...
- 洛谷p2922[USACO08DEC]秘密消息Secret Message
题目: 题目链接:[USACO08DEC]秘密消息Secret Message 题意: 给定n条01信息和m条01密码,对于每一条密码A,求所有信息中包含它的信息条数和被它包含的信息条数的和. 分析: ...