mysql续
接上篇博客,写完以后看了看,还是觉的写的太简单,就算是自己复习都不够,所以再补充一些
1.创建多表关联
需求:图书管理系统,创建几张表,包含书籍,出版社,作者,作者详细信息等内容
分析:
(1)图书只有一个出版社,出版社可以出版很多书,多对一关系
(2)图书可以有多个作者,一个作者也可以写多本书,多对多关系
(3)作者的详细信息表,与作者一对一关系
(4)多对一关系,用外键;一对一关系,在外键上加唯一约束;多对多关系,用第三张表存储关系
(5)需要建立五张表,书籍,出版社,作者,作者详细信息,图书与作者关系表
代码贴到这,用pycharm书写,推荐mysql命令大写
create database book_manage_system character set utf8; --创建出版社表,字段有id,name,city
create table publish(id int primary key auto_increment,
name varchar(20),
city varchar(20)); --创建书籍表,书籍表是出版社表的子表,字段有id,name,price,publish_id
create table book (id int primary key auto_increment,
name varchar(20),
price double(6,2),
publish_id int,
foreign key (publish_id) references publish(id)
--增加外键,与出版社表和作者表建立关系
); --创建作者详细信息表,字段有ID,name,age,city,phone_num,email
create table auth_detail (id int primary key auto_increment,
name varchar(20),
age int,
city varchar(20),
phone_num varchar(11),
email varchar(30)); --创建作者表,为作者详细信息表的子表,字段有ID,name,auth_detail_id
create table author(id int primary key auto_increment,
name varchar(20),
auth_detail_id int unique,
foreign key (auth_detail_id) references auth_detail(id)
--增加外键,与作者详细信息表建立联系,一对一关系,唯一性约束
); --创建作者与书籍的关系表,字段有auth_id,book_id
create table book_to_auth(id int primary key auto_increment,
auth_id int,
foreign key (auth_id) references author(id),
book_id int,
foreign key (book_id) references book(id));
--创建外键,作者信息与书籍信息联系
2.用pycharm来编写mysql语句
虽然mysql的命令我们都应该熟记于心,但是当我们已经记住后,从开发效率方面考虑,我们就可以使用一些文本编辑器来帮助我们写这些语句了,下面说一下配置pycharm的流程
(1)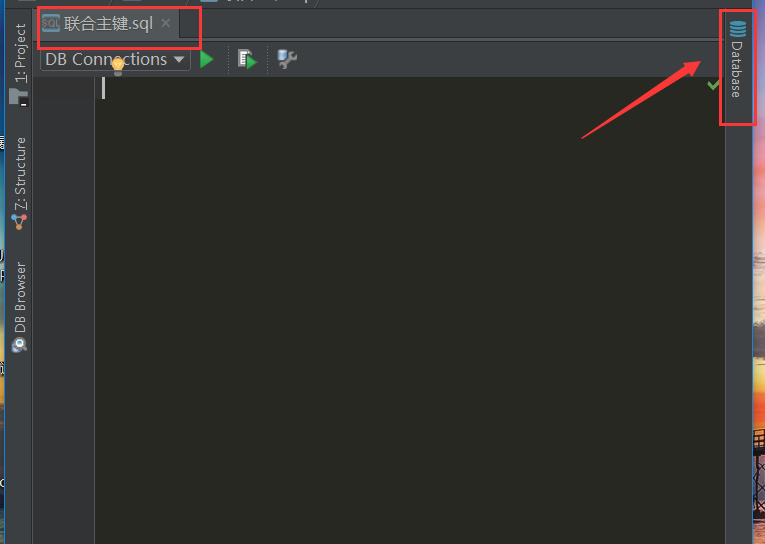 新建一个sql文件,打开pycharm右边的database
新建一个sql文件,打开pycharm右边的database
(2)
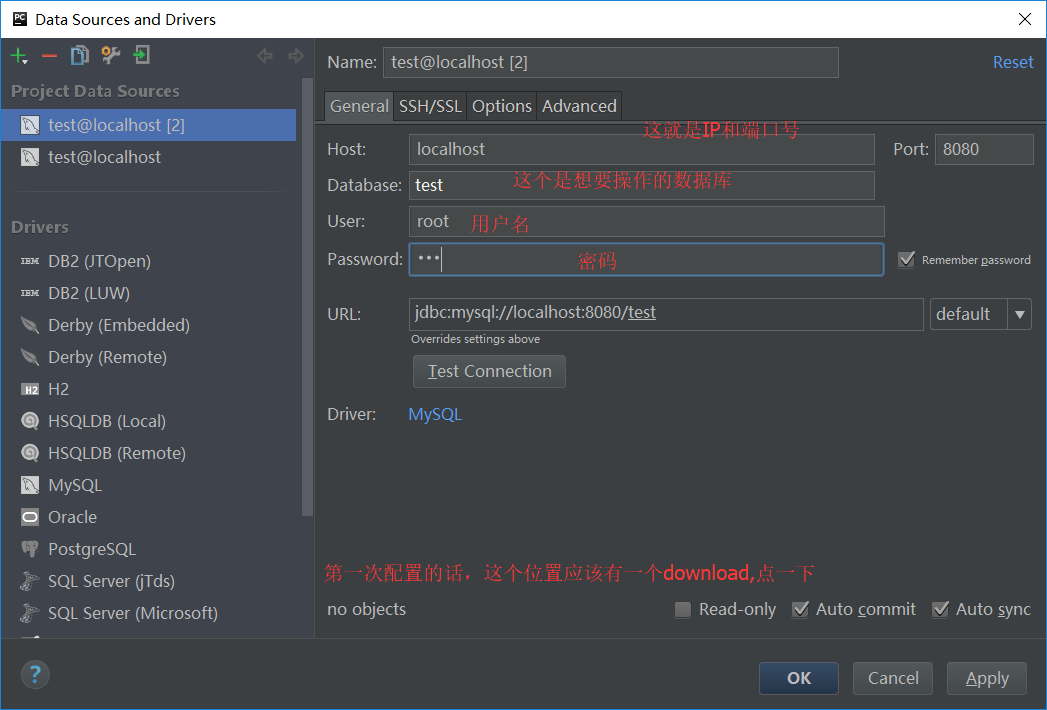
(3)
(4)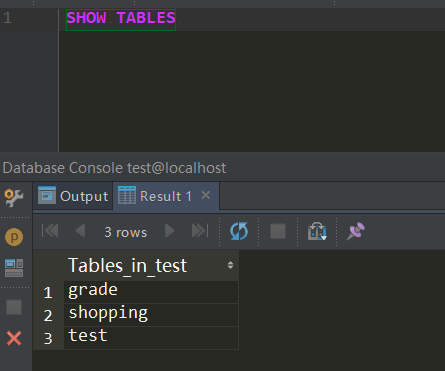
ok,这就可以了,妈妈再也不用担心我忘记大写了,效率也是提升了不知多少倍
但是需要注意,这只能操作一个数据库,想切换数据库的话,要重新走一遍刚才的流程,把想要操作的数据库添加进来就行了
3.联合主键
上一篇博客写了设置主键可以用primary key,也可以用not null unique
这里要详细说一下,
- 如果表中只有一个非空且唯一约束,自动就会识别为主键
- 非空且唯一约束并非只能设置一次,但是第一个设置这个约束的被识别为主键
- 每张表只能有一个主键,但是主键并不一定在一个字段上,即联合主键
CREATE TABLE union_primary_key (id int,
name VARCHAR(20),
age int,
PRIMARY KEY (id,name))
看一下表结构,

看到没,两个主键了,这就叫联合主键。
应用的话,可以参照我们最开始设计的那个图书管理系统,在我们创建图书和作者关系的表的时候,图书id和作者id理论上都应该是必须同时有值且不能重复,就可以把他俩设置成联合主键
4.存储引擎
不知你有没有注意过,当我们用create命令查看表的创建信息时,会得到类似这样一些数据
| book | CREATE TABLE `book` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`price` double(6,2) DEFAULT NULL,
`publish_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `publish_id` (`publish_id`),
CONSTRAINT `book_ibfk_1` FOREIGN KEY (`publish_id`) REFERENCES `publish` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
最下边有一个 ENGINE=InnoDB
这就是存储引擎,存储引擎的作用是存储数据,为数据建立索引,查询数据
在MySQL中提供了多种存储引擎,有innodb,memory,blackhole等
innodb是我们最常用的,memory是基于内存的存储机制,不会长久保存,而blackhole叫黑洞引擎,所有丢到里面的数据都会消失,我至今也没理解是干什么用的,据说是为了测试。而我们最关心 的应该是innodb。外键这个东西就是innodb独有的。
我们可以通过命令SHOW ENGINES查看引擎(tips:在命令提示行中是显示不全的,可以在命令后面加一个\G,就可以正常显示了)
以innodb 创建一个表之后,就会有分别以opt,frm,ibd为后缀的三个文件创建,不同的引擎,创建的文件也不一样
5.索引(index或key)
索引在mysql中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。当表中的数据量很大时,索引能轻易的将查询性能提高好几个数量级。虽然在创建索引时很费时间,但是一旦创建好,就能大大提高查询速度。
创建索引的方式:
(1)创建普通索引
CREATE TABLE student(
id INT,
name VARCHAR(20),
INDEX index_name(name)
);
(2)创建唯一索引
CREATE TABLE student(
id INT,
name VARCHAR(20),
UNIQUE INDEX index_name(name)
);
(3)创建全文索引
CREATE TABLE student(
id INT,
name VARCHAR(20),
FULLTEXT INDEX index_name(name)
);
(4)创建多列索引
CREATE TABLE student(
id INT,
name VARCHAR(20),
INDEX index_name(name,id)
);
(5)在已存在的表上创建索引
# 1.create方法
CREATE INDEX 索引名
ON 表名 (字段名 ) # 2.alter方法
ALTER TABLE 表名 ADD INDEX
索引名 (字段名)
删除索引:
DROP INDEX 索引名 on 表名
6.还有pymsql和orm,下次写数据库的时候一块说
mysql续的更多相关文章
- 数据库(MSSQLServer,Oracle,DB2,MySql)常见语句以及问题(续1之拼接字符串)
上一篇文章http://www.cnblogs.com/valiant1882331/p/4056403.html写的太长了,所以就换了一篇,链接上一节继续 字符串的拼接 MySql中可以使用&quo ...
- 在Node.js使用Promise的方式操作Mysql(续)
在之后的开发中,为了做一些事务开发,我把mysql的连接代码从之前的query函数中分离出来了,直接使用原生的方法进行操作,但发现还是有点问题 原因是原生的node-mysql采用了回调函数的方式,同 ...
- MySql的基本架构续
[数据拆分后引入的问题] 数据水平拆分引入的问题主要是只能通过sharding key来读写操作,例如以userid为sharding key的切分例子,读userid的详细信息时,一定需要先知道us ...
- mysql索引优化续
(1)索引类型: Btree索引:抽象的可以理解为“排好序的”快速查找结构myisam,innodb中默认使用Btree索引 hash索引:hash索引计算速度非常的快,但数据是随机放置的,无法对范围 ...
- mysql学习笔记1---mysql ERROR 1045 (28000): 错误解决办法(续:深入分析)
在命令行输入mysql -u root –p,输入密码,或通过工具连接数据库时,经常出现下面的错误信息,详细该错误信息很多人在使用MySQL时都遇到过. ERROR 1045 (28000): Acc ...
- MySQL高可用之MGR安装测试(续)
Preface I've implemented the Group Replication with three servers yesterday,What a shame it ...
- MySQL高可用之PXC安装部署(续)
Preface Yesterday I implemented a three-nodes PXC,but there were some errors when proceeding ...
- mysql操作篇续
# ### part1. 数据类型 - 时间date YYYY-MM-DD 年月日 (纪念日)time HH:MM:SS 时分秒 (体育竞赛)year YYYY 年份值 (酒的年份,82年拉菲)dat ...
- MySQL运维中的Tips--持续更新
1.into outfile 生成sql:一般都是生成文本或者其他形式的文件,现在需要生成sql形式的文件.配置文件加secure_file_priv=''select concat('insert ...
随机推荐
- 分布式锁----浅析redis实现
引言大概两个月前小伙伴问我有没有基于redis实现过分布式锁,之前看redis的时候知道有一个RedLock算法可以实现分布式锁,我接触的分布式项目要么是github上开源学习的,要么是小伙伴们公司项 ...
- 在vue组件库中不能使用v-for
没事的,有点时候编辑器报错,但运行不一定出错, 在vue组件中注意template标签
- 基于Python的Web应用开发实战——2 程序的基本结构
2.1 初始化 所有Flaks程序都必须创建一个程序实例. Web服务器使用一种名为Web服务器网关接口(Web Server Gateway Interface,WSGI)的协议,把接收自客户端的所 ...
- java web.xml被文件加载过程及加载顺序小结
web.xml加载过程(步骤): 1.启动WEB项目的时候,容器(如:Tomcat)会去读它的配置文件web.xml.读两个节点: <listener></listener> ...
- CPP-基础:关于内存分配
1:c中的malloc和c++中的new有什么区别 (1)new.delete 是操作符,可以重载,只能在C++中使用.(2)malloc.free是函数,可以覆盖,C.C++中都可以使用.(3)ne ...
- iOS开发遇见的坑之二:工程文件中插件和自身工程命名冲突
在升级cocoapod后,我重新管理了一下工程,其实也就是把各个类分类进行管理 类似于这样 然后编译就发现不能运行 1.其中一个错误是工程文件缺失,根据提示添加进来进行 2.有一个是pch的相对路径变 ...
- SVN的使用二
一,打开SCM 在xcode中,点击菜单: File -> Source Control –> Repositories 二,连接SVN服务器 1, 2,配置SVN服务器地址(http:/ ...
- ios多线程NSThread
1.简介: 1.1 iOS有三种多线程编程的技术,分别是: 1..NSThread 2.Cocoa NSOperation (iOS多线程编程之NSOperation和NSOperationQueue ...
- 删除链表的倒数第N个节点(三种方法实现)
删除链表的倒数第N个节点 给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点. 示例: 给定一个链表: 1->2->3->4->5, 和 n = 2. 当删除了倒 ...
- bzoj3545 [ONTAK2010]Peaks、bzoj3551 [ONTAK2010]Peaks加强版
题目描述: bzoj3545,luogu bzoj3551 题解: 重构树+线段树合并. 可以算是板子了吧. 代码(非强制在线): #include<cstdio> #include< ...