LSA、LDA
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text (the distributional hypothesis). A matrix containing word counts per paragraph (rows represent unique words and columns represent each paragraph) is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Words are then compared by taking the cosine of the angle between the two vectors (or the dot product between the normalizations of the two vectors) formed by any two rows. Values close to 1 represent very similar words while values close to 0 represent very dissimilar words.
Occurrence matrix:
LSA can use a term-document matrix which describes the occurrences of terms in documents; it is a sparse matrix whose rows correspond to terms and whose columns correspond to documents. A typical example of the weighting of the elements of the matrix is tf-idf (term frequency–inverse document frequency): the weight of an element of the matrix is proportional to the number of times the terms appear in each document, where rare terms are upweighted to reflect their relative importance.
Rank lowering(矩阵降维):
After the construction of the occurrence matrix, LSA finds a low-rank approximation to the term-document matrix. There could be various reasons for these approximations:
- The original term-document matrix is presumed too large for the computing resources; in this case, the approximated low rank matrix is interpreted as an approximation (a "least and necessary evil").
- The original term-document matrix is presumed noisy: for example, anecdotal instances of terms are to be eliminated. From this point of view, the approximated matrix is interpreted as a de-noisified matrix(a better matrix than the original).
- The original term-document matrix is presumed overly sparse relative to the "true" term-document matrix. That is, the original matrix lists only the words actually in each document, whereas we might be interested in all words related to each document—generally a much larger set due to synonymy.
Derivation
Let $X$ be a matrix where element $ (i,j)$ describes the occurrence of term $ i $ in document $j$ (this can be, for example, the frequency). $X$ will look like this:
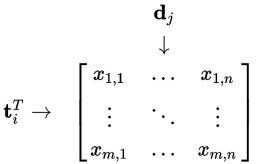
Now a row in this matrix will be a vector corresponding to a term, giving its relation to each document:
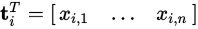
Likewise, a column in this matrix will be a vector corresponding to a document, giving its relation to each term:
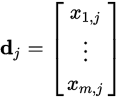
Now, from the theory of linear algebra, there exists a decomposition of $X$ such that $U$ and $ V $ are orthogonal matrices(正交矩阵) and $\Sigma$ is a diagonal matrix(对角矩阵). This is called a singular value decomposition (SVD):
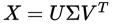

The values  are called the singular values, and
are called the singular values, and  and
and  the left and right singular vectors. Notice the only part of
the left and right singular vectors. Notice the only part of 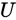 that contributes to
that contributes to 
is the 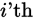 row. Let this row vector be called
row. Let this row vector be called 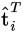 . Likewise, the only part of
. Likewise, the only part of 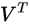 that contributes to
that contributes to  is the
is the 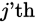 column,
column, . These are not theeigenvectors,but depend on all the eigenvectors.
. These are not theeigenvectors,but depend on all the eigenvectors.
https://en.wikipedia.org/wiki/Latent_semantic_analysis
LSA、LDA的更多相关文章
- 京东商品评论的分类预测与LSA、LDA建模
(一)数据准备 1.爬取京东自营店kindle阅读器的评价数据,对数据进行预处理,使用机器学习算法对评价文本进行舆情分析,预测某用户对本商品的评价是好评还是差评.通过数据分析与模型分析,推测出不同型号 ...
- 文本情感分析(一):基于词袋模型(VSM、LSA、n-gram)的文本表示
现在自然语言处理用深度学习做的比较多,我还没试过用传统的监督学习方法做分类器,比如SVM.Xgboost.随机森林,来训练模型.因此,用Kaggle上经典的电影评论情感分析题,来学习如何用传统机器学习 ...
- 四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
四大机器学习降维算法:PCA.LDA.LLE.Laplacian Eigenmaps 机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映 ...
- 特征向量、特征值以及降维方法(PCA、SVD、LDA)
一.特征向量/特征值 Av = λv 如果把矩阵看作是一个运动,运动的方向叫做特征向量,运动的速度叫做特征值.对于上式,v为A矩阵的特征向量,λ为A矩阵的特征值. 假设:v不是A的速度(方向) 结果如 ...
- 我是这样一步步理解--主题模型(Topic Model)、LDA
1. LDA模型是什么 LDA可以分为以下5个步骤: 一个函数:gamma函数. 四个分布:二项分布.多项分布.beta分布.Dirichlet分布. 一个概念和一个理念:共轭先验和贝叶斯框架. 两个 ...
- 一口气讲完 LSA — PlSA —LDA在自然语言处理中的使用
自然语言处理之LSA LSA(Latent Semantic Analysis), 潜在语义分析.试图利用文档中隐藏的潜在的概念来进行文档分析与检索,能够达到比直接的关键词匹配获得更好的效果. LSA ...
- 【转】四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
最近在找降维的解决方案中,发现了下面的思路,后面可以按照这思路进行尝试下: 链接:http://www.36dsj.com/archives/26723 引言 机器学习领域中所谓的降维就是指采用某种映 ...
- 降维算法整理--- PCA、KPCA、LDA、MDS、LLE 等
转自github: https://github.com/heucoder/dimensionality_reduction_alo_codes 网上关于各种降维算法的资料参差不齐,同时大部分不提供源 ...
- Word Embedding/RNN/LSTM
Word Embedding Word Embedding是一种词的向量表示,比如,对于这样的"A B A C B F G"的一个序列,也许我们最后能得到:A对应的向量为[0.1 ...
随机推荐
- 目录扫描工具DirBuster
DirBuster是用来探测web服务器上的目录和隐藏文件的.因为DirBuster是采用java编写的,所以运行前要安装上java的环境. 来看一下基本的使用: ①:TargetURL下输入要探测网 ...
- 【css】报错,错误代码77,CURLE_SSL_CACERT_BADFILE (77)解决方法
CURLE_SSL_CACERT_BADFILE (77) - 读取 SSL CA 证书时遇到问题(可能是路径错误或访问权限问题) 在微信接口相关开发时容易出现此问题 这一般是因为服务更新了相关的软件 ...
- hashlib模块,hmac模块
6.11自我总结 1.hashlib模块(文件传输中将传输内容用指定算法进行处理) hash是一种算法(Python3.版本里使用hashlib模块代替了md5模块和sha模块,主要提供 SHA1.S ...
- Python9-列表-day4
列表list 列表是python中的基础数据类型之一,其他语言中也有类似于列表的数据类型,比如js中叫数组,他是以[]括起来,每个元素以逗号隔开,而且他里面可以存放各种数据类型比如: li = [‘a ...
- Luogu3195 [HNOI2008]玩具装箱TOY (方程变形 + 斜率优化 )
题意: 给出一个序列 {a[i]} 把其分成若干个区间,每个区间的价值为 W = (j − i + ∑ak(i<=k<=j) - L)2 ,求所有分割方案中价值之和的最小值. 细节: 仔 ...
- adb shell am/pm 常用命令详解与使用
一.adb shell am 使用此命令可以从cmd控制台启动 activity, services:发送 broadcast等等 1.am start <packageName/.classN ...
- skkyk:线段树浅谈
推荐前辈学姐博客文章,写的很细 https://www.cnblogs.com/TheRoadToTheGold/p/6254255.html 学学半,此随笔主要是加深自己对线段树的理解 题目:洛谷P ...
- Hive 导入数据报错,驱动版本过低
Failed with exception Unable to alter table. javax.jdo.JDODataStoreException: You have an error in y ...
- Java web 服务启动时Xss溢出异常处理笔记
本文来自网易云社区 作者:王飞 错误日志 错误日志要仔细看,第一行不一定就是关键点,这个错误出现的时候,比较靠后,其中关键行就是下面这句. Caused by: java.lang.IllegalSt ...
- Leetcode 365.水壶问题
水壶问题 有两个容量分别为 x升和 y升的水壶以及无限多的水.请判断能否通过使用这两个水壶,从而可以得到恰好 z升的水? 如果可以,最后请用以上水壶中的一或两个来盛放取得的 z升 水. 你允许: 装满 ...