机器学习_决策树Python代码详解
决策树优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据;
决策树缺点:可能会产生过度匹配问题。
决策树的一般步骤:
(1)代码中def 1,计算给定数据集的香农熵:
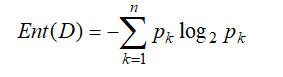
其中n为类别数,D为数据集,每行为一个样本,pk 表示当前样本集合D中第k类样本所占的比例,Ent(D)越小,D的纯度越高,即表示D中样本大部分属于同一类;反之,D的纯度越低,即数据集D中的类别数比较多。
(2)代码中def 2,选择最好的数据集划分方式,即选择信息增益最大的属性:
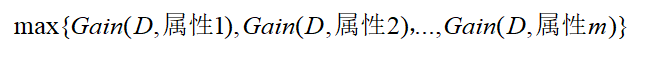
其中
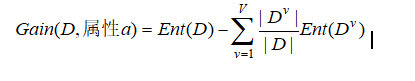
这里V表示属性a的可能的取值数,Dv表示属性a上取值为av的样本。
(3)代码中 def 3,按照给定特征划分数据集:选取最优属性后,再从属性的各个取值中选取最优的属性,以此类推。
(4)代码中def 5,递归构造树,数的结束标志为:a、类别完全相同则停止划分;b、代码中def 4,如果数据集已经处理了所有属性,但是类标签依然不是唯一的,此时采用多数表决法,即遍历完所有特征时返回出现次数最多的类别。
from math import log # 计算数据集的信息熵,熵越小,说明数据集的纯度越高
def calcShannonEnt(dataset): # def 1
numEntries = len(dataset) # 样本数,这里的dataSet是列表
labelCounts = {} #定义一个字典,key为类别,值为类别数
for featVec in dataset: # 统计各个类别的个数
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0 # 信息熵
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt # 信息熵 # 选出最好的数据集划分方式,即找出具有最大信息增益的特征
def chooseBestFeatureToSplit(dataSet): #def 2
numFeatures = len(dataSet[0])-1 # 特征数
baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet] #第i列特征的所有特征的取值
uniqueVals = set(featList) # 去掉重复的特征,每个特征值都是唯一的
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy # 表示属性为value的信息增益
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature # 具有最大信息增益的特征 # 按照给定特征维数划分数据集,数据集中一行为一个样本
# def 3
def splitDataSet(dataSet,axis,value): # axis可表示数据集的列,也就是特征为数,value表示特征的取值
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] # 在数据集中去掉axis这一列
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet # 表示去掉在axis中特征值为value的样本后而得到的数据集 # 当处理了所有属性,但是类标签依然不是唯一的,此时采用多数表决法决定该叶子节点的分类
def majorityCnt(classList): # def 4
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount += 1
sortedClassCount = sorted(classCount.items(),key=lambda classCount: classCount[1],reverse = True)
return sortedClassCount[0][0] # 创建树
def createTree(dataSet,labels): # def 5
classList = [example[-1] for example in dataSet] #类别列表
if classList.count(classList[0]) == len(classList): # 如果类别完全相同就停止划分
return classList[0]
if (len(dataSet[0]) == 1):
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) # 选出最好的特征,也就是信息增益最大的特征
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat]) # 每划分一层,特征数目就会较少
featValues = [example[bestFeat] for example in dataSet] # 最好的特征的特征值
uniqueVals = set(featValues) #去掉重复的特征
for value in uniqueVals:
subLabels = labels[:] # 减少后的特征名
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree def createDateSet():
dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
labels = ['no surfacing','flippers'] #属性名
return dataSet,labels myData,myLabel = createDateSet()
createTree(myData,myLabel)
print(createTree(myData,myLabel))
#print(chooseBestFeatureToSplit(myData))
# print(splitDataSet(myData,0,1))
# print(splitDataSet(myData,0,0))
机器学习_决策树Python代码详解的更多相关文章
- 机器学习_K近邻Python代码详解
k近邻优点:精度高.对异常值不敏感.无数据输入假定:k近邻缺点:计算复杂度高.空间复杂度高 import numpy as npimport operatorfrom os import listdi ...
- 520表白小程序设计Python代码详解(PyQt5界面,B站动漫风)
摘要:介绍一个动漫风的表白小程序,界面使用Python以及PyQt实现,界面样式经过多次美化调整,使得整体清新美观.本文详细介绍代码设计和实现过程,不仅是居家表白必备,而且适合新入门的朋友学习界面设计 ...
- python golang中grpc 使用示例代码详解
python 1.使用前准备,安装这三个库 pip install grpcio pip install protobuf pip install grpcio_tools 2.建立一个proto文件 ...
- 第7.24节 Python案例详解:使用property函数定义属性简化属性访问代码实现
第7.24节 Python案例详解:使用property函数定义属性简化属性访问代码实现 一. 案例说明 本节将通过一个案例介绍怎么使用property定义快捷的属性访问.案例中使用Rectan ...
- SQL Server 表的管理_关于完整性约束的详解(案例代码)
SQL Server 表的管理之_关于完整性约束的详解 一.概述: ●约束是SQL Server提供的自动保持数据库完整性的一种方法, 它通过限制字段中数据.记录中数据和表之间的数据来保证数据的完整性 ...
- 迅为4412开发板Linux驱动教程——总线_设备_驱动注册流程详解
本文转自:http://www.topeetboard.com 视频下载地址: 驱动注册:http://pan.baidu.com/s/1i34HcDB 设备注册:http://pan.baidu.c ...
- Python闭包详解
Python闭包详解 1 快速预览 以下是一段简单的闭包代码示例: def foo(): m=3 n=5 def bar(): a=4 return m+n+a return bar >> ...
- 代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
来源商业新知网,原标题:代码详解:TensorFlow Core带你探索深度神经网络“黑匣子” 想学TensorFlow?先从低阶API开始吧~某种程度而言,它能够帮助我们更好地理解Tensorflo ...
- [转] Python Traceback详解
追莫名其妙的bugs利器-mark- 转自:https://www.jianshu.com/p/a8cb5375171a Python Traceback详解 刚接触Python的时候,简单的 ...
随机推荐
- 强类型DataSet (2011-12-30 23:16:59)转载▼ 标签: 杂谈 分类: Asp.Net练习笔记 http://blog.sina.com.cn/s/blog_9d90c4140101214w.html
强类型DataSet (2011-12-30 23:16:59) 转载▼ 标签: 杂谈 分类: Asp.Net练习笔记 using System; using System.Collections.G ...
- 黑客常用WinAPI函数整理
之前的博客写了很多关于Windows编程的内容,在Windows环境下的黑客必须熟练掌握底层API编程.为了使读者对黑客常用的Windows API有个更全面的了解以及方便日后使用API方法的查询,特 ...
- pssh 批量管理执行
pssh 是一个python写的批量执行工具,非常适合30台服务器以内的一些重复性的操作 安装很简单,只要python版本2.4 以上的都行 用这个工作最好把机器做做好ssh信任关系,不然很麻烦 每次 ...
- 使用maven新建类目录是,报错The folder is already a source folder.的解决办法
转自:https://www.cnblogs.com/loger1995/p/6539139.html 我们有时候新建一个webapp的maven项目时,生成的目录结构是这样子的: 缺少maven规范 ...
- 解决weblogic页面和控制台乱码问题
转自:https://blog.csdn.net/u010995831/article/details/53283746 之前一直有碰到weblogic各种乱码问题,要不就是页面乱码,要不就是控制台乱 ...
- 2-17 numpy模块使用
#CURD import numpy as np data1 = np.array([1,2,3,4,5]) print(data1) data2 = np.array([[1,2], [3,4]]) ...
- RelativeLayout和layout_weight的异曲同工之妙(转载)
转自:http://ericbaner.iteye.com/blog/1161751 Android应用UI开发,对以上布局,可以使用RelativeLayout, 即: Xml代码 <Rela ...
- HDU3092:Least common multiple(素数筛选+完全背包)
题意 给出\(n\)和\(m\),将\(n\)拆成任意个数,求它们的最大的\(lcm\) 分析 1.可以证明\(n=p1^{s1}*p2^{s2}*...*pn^{sn}\)时\(lcm\)最大(其中 ...
- 第二篇(那些JAVA程序BUG中的常见单词)
Cannot instantiate the type xxx 无法实例化类型xxx instantiate 实例化
- centos 7 添加普通用户
adduser username username 是你要创建的用户名 passwd username 创建密码,输入个稍微复杂的 usermod -a -G wheel username 将用户加入 ...